Abstract
This paper presents an intelligent invoice processing system that leverages advanced Vision-Language Models (VLMs) to automate invoice data extraction and analysis. Our system combines the power of LLaMA-4 Scout model with sophisticated image preprocessing techniques and real-time analytics to create a comprehensive solution for invoice digitization. The implementation features a user-friendly Streamlit interface that supports multi-language processing, batch operations, fraud detection, and interactive chatbot assistance. Experimental results demonstrate high accuracy in extracting structured data from various invoice formats, with confidence scoring mechanisms and anomaly detection capabilities that enhance reliability for enterprise applications.
Keywords:
OCR, Vision-Language Models, Invoice Processing, Document AI, LLaMA-4, Multi-Modal Learning, Fraud Detection
1.Introduction
Invoice processing is an essential yet labor-intensive aspect of business operations, with organizations often managing thousands of records every month. Conventional OCR-based tools face difficulties when dealing with diverse layouts, multiple languages, and inconsistent image quality. Recent progress in Vision-Language Models has created opportunities for more advanced document understanding, moving beyond basic text recognition.
The main contributions of this work are the design of a multi-modal pipeline powered by LLaMA-4 Scout, capable of handling complex invoice structures with high accuracy. The system incorporates automatic document classification and context-aware data extraction to adapt to different formats. It also features real-time anomaly detection to identify irregularities and potential fraud. Further, the solution includes optimized multilingual support to ensure effective processing across regions. To enhance usability, an interactive chatbot is provided, allowing users to query and explore invoice data effortlessly.
2.Related work
2.1 Traditional OCR Approaches:
Early invoice processing systems were predominantly built on template-based extraction methodologies and deterministic rule-based parsing frameworks. These conventional approaches operated under the assumption that invoices followed standardized formats within specific vendor categories or geographic regions. The typical workflow involved manual template creation for each invoice format, where developers would define fixed coordinate positions for extracting key fields such as invoice numbers, dates, amounts, and line items.
Template-Based Systems: Companies like ABBYY FlexiCapture and Kofax Capture pioneered template-based document processing solutions. These systems required extensive manual configuration, where business analysts would spend weeks creating and fine-tuning extraction rules for each new invoice format. The process involved defining anchor points, field boundaries, and validation rules specific to individual vendor layouts. While effective for high-volume, consistent document formats, these systems suffered from brittleness when encountering variations in layout, font sizes, or document quality.
Rule-Based Parsers: Traditional rule-based parsing systems utilized regular expressions, keyword matching, and positional heuristics to extract structured data from invoice text. These approaches often employed multi-stage processing pipelines:
(1) OCR text extraction using engines like Tesseract
(2) text cleaning and normalization
(3) rule-based field identification using pattern matching
(4) post-processing validation.
However, these systems required extensive domain expertise and continuous maintenance as new invoice formats emerged.
Limitations and Challenges: The primary limitations of traditional approaches included:
(a) Scalability Issues - Each new vendor format required manual template creation, making it impractical for businesses processing invoices from hundreds of vendors;
(b) Poor Adaptability - Minor layout changes would break existing templates, requiring constant maintenance; (c) Language Dependencies - Templates were typically language-specific, limiting multilingual processing capabilities;
(d) Quality Sensitivity - Performance degraded significantly with low-resolution images, skewed documents, or varied lighting conditions;
(e) Maintenance Overhead - Continuous updates were required as invoice formats evolved, leading to high operational costs.
2.2 Deep Learning in Document AI
The advent of deep learning architectures marked a significant paradigm shift in document understanding, enabling more robust and generalizable solutions for invoice processing. Early deep learning approaches focused on addressing specific components of the document processing pipeline through specialized neural architectures.
Convolutional Neural Networks for Layout Analysis: Research by Xu et al. (2020) and Qasim et al. (2019) demonstrated the effectiveness of CNN-based approaches for document layout analysis and table detection. These models, such as TableNet and DeepTabNet, could automatically identify and segment different regions of invoice documents, including header sections, line item tables, and footer totals. The CNN architectures typically employed encoder-decoder structures with skip connections, enabling precise pixel-level segmentation of document components. However, these approaches required large annotated datasets and struggled with diverse layout variations.
Recurrent Neural Networks for Sequence Extraction: Following layout analysis, sequence-to-sequence models using LSTM and GRU architectures were employed for extracting structured information from identified text regions. Models like BERT-based named entity recognition (NER) systems were fine-tuned specifically for invoice field extraction. Carbonell et al. (2021) proposed BiLSTM-CRF models that achieved 87% accuracy on invoice field extraction tasks. These approaches could handle sequential dependencies in text but required separate training for different field types and languages.
Attention Mechanisms and Transformers: The introduction of attention-based architectures revolutionized document understanding. Models like LayoutLM (Xu et al., 2020) and LayoutLMv2 (Xu et al., 2021) incorporated both textual and spatial information, enabling better understanding of document structure. These models pre-trained on large document corpora could capture relationships between text elements and their positions, achieving state-of-the-art performance on document understanding benchmarks. LayoutLMv3 (Huang et al., 2022) further improved performance by unifying text and image understanding through unified text-image masking strategies.
Multi-Modal Approaches: Recent work has explored combining visual, textual, and spatial modalities for comprehensive document understanding. DocFormer (Appalaraju et al., 2021) introduced a multi-modal transformer architecture that processes document images, OCR text, and spatial coordinates jointly. Similarly, BROS (Hong et al., 2022) focused on understanding relationships between text blocks using relative spatial information. These approaches achieved significant improvements on various document AI tasks but required substantial computational resources and complex training procedures.
Challenges and Limitations: Despite significant advances, deep learning approaches faced several challenges: (a) Data Requirements - Models required extensive labeled training data, which was expensive to obtain for invoice processing
(b) Computational Complexity - Multi-modal transformers required significant GPU resources for training and inference
(c) Domain Adaptation - Models trained on specific invoice types often struggled to generalize to different formats or industries
(d) End-to-End Integration - Most approaches required separate models for different processing stages, complicating deployment and maintenance.
2.3 Vision-Language Models
The emergence of large-scale Vision-Language Models (VLMs) has fundamentally transformed document understanding by enabling end-to-end processing through natural language instructions, eliminating the need for task-specific model architectures and extensive labeled datasets.
Foundation Models and Scaling: The development of large-scale foundation models marked a paradigm shift in AI capabilities. Models like GPT-4V (OpenAI, 2023) demonstrated remarkable zero-shot and few-shot learning capabilities across diverse vision-language tasks. These models, trained on internet-scale multimodal data, could understand complex visual scenes and respond to natural language queries about image content. The scaling laws demonstrated by Kaplan et al. (2020) showed that larger models with more parameters and training data consistently achieved better performance across various tasks.
Document-Specific Vision-Language Models: LLaVA (Liu et al., 2023) pioneered the development of open-source vision-language models specifically designed for instruction following. The model architecture combines a vision encoder (typically CLIP ViT) with a language model (LLaMA or Vicuna), connected through a projection layer that maps visual features to the language model's input space. LLaVA-1.5 achieved competitive performance with GPT-4V on various vision-language benchmarks while being significantly more accessible for research and commercial applications.
LLaMA-Vision and Multimodal Extensions: The LLaMA family of models has been extended to support multimodal understanding through various approaches. LLaMA-Adapter V2 (Gao et al., 2023) introduced efficient fine-tuning methods for adding vision capabilities to pre-trained language models. More recently, LLaMA-4 Scout has incorporated advanced vision-language understanding with improved efficiency and accuracy. These models can process high-resolution images and generate structured outputs based on natural language instructions, making them particularly suitable for document processing tasks.
Instruction Tuning and Alignment: Recent research has focused on improving VLM performance through instruction tuning and human feedback alignment. InstructBLIP (Dai et al., 2023) demonstrated how instruction tuning on diverse vision-language tasks could significantly improve model performance on downstream applications. Similarly, alignment techniques like Constitutional AI and RLHF have been applied to vision-language models to improve their reliability and reduce hallucinations in document processing scenarios.
Applications in Document AI: VLMs have shown exceptional performance in document understanding tasks. GPT-4V achieved state-of-the-art results on document VQA benchmarks without task-specific fine-tuning. These models can understand complex document layouts, extract structured information, and even perform reasoning over document content. The ability to process documents through natural language instructions eliminates the need for template creation or specialized model architectures, making document processing more accessible and scalable.
Advantages and Breakthrough Capabilities: Vision-Language Models offer several key advantages for invoice processing: (a) Zero-Shot Generalization - VLMs can process new invoice formats without additional training or template creation; (b) Natural Language Interface - Users can specify extraction requirements using natural language instructions rather than programming rules; (c) Multimodal Understanding - Models can leverage both visual layout cues and textual content for improved accuracy; (d) Reasoning Capabilities - Advanced VLMs can perform calculations, validate extracted data, and identify anomalies; (e) Multilingual Support - Large-scale training enables processing of documents in multiple languages without language-specific models.
Current Limitations and Research Directions: While VLMs represent significant progress, several challenges remain: (a) Computational Requirements - Large VLMs require substantial computational resources for inference; (b) Hallucination Concerns - Models may generate plausible but incorrect information, requiring careful validation; (c) Context Length Limitations - Current models have limited context windows, constraining processing of very long documents; (d) Fine-grained Accuracy - While generally accurate, VLMs may struggle with precise numerical extraction in complex layouts. Active research areas include developing more efficient architectures, improving numerical reasoning capabilities, and enhancing reliability through better training methodologies and alignment techniques.
3. Methodology
3.1 Model Architecture:
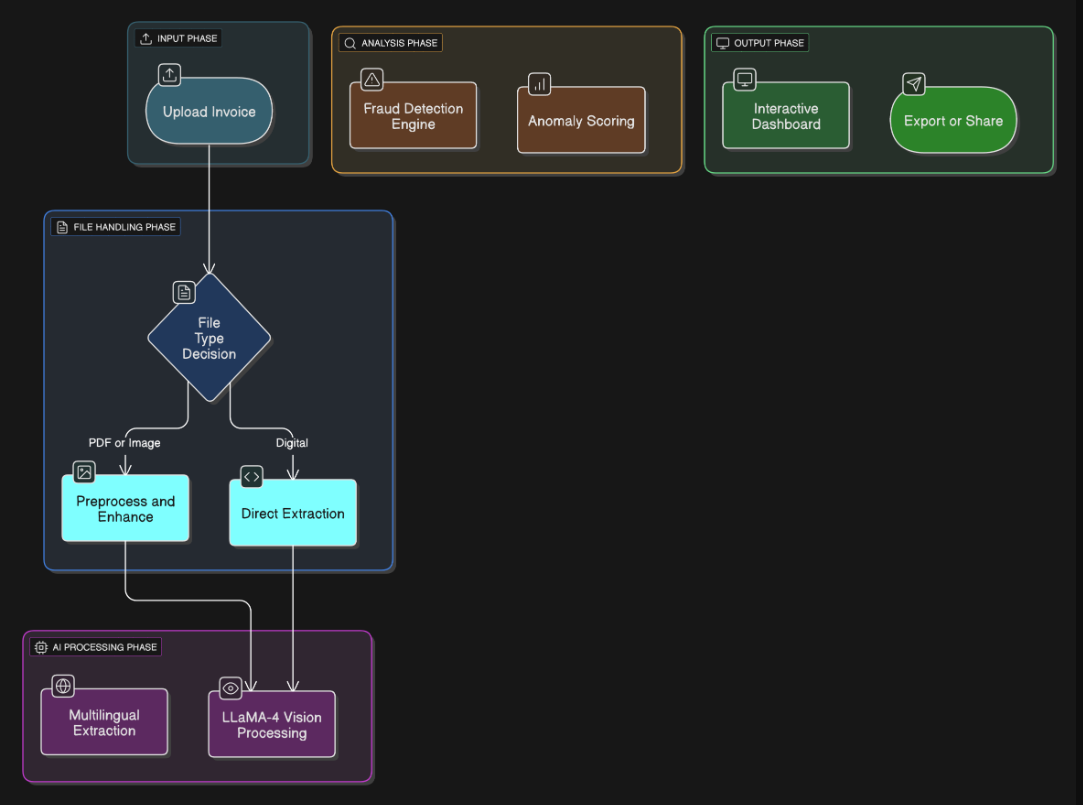
The system architecture follows a multi-layered, event-driven design that maximizes the capabilities of the LLaMA-4 Scout vision-language model while ensuring scalability and reliability. The core architecture operates on a pipeline paradigm where each component performs specialized tasks in sequence, with sophisticated error handling and fallback mechanisms at each stage. The model architecture leverages the transformer-based LLaMA-4 Scout 17B parameter model, which combines a visual encoder based on Vision Transformer (ViT) architecture with the LLaMA language model through a learned projection layer. This multimodal fusion enables the system to process both visual layout information and textual content simultaneously, eliminating the need for separate OCR and NLP pipelines that traditional systems require. The model's attention mechanism can focus on relevant regions of the invoice image while maintaining contextual understanding of the document structure, allowing it to handle varying layouts, fonts, and quality levels without template-specific training. The architecture implements a confidence-aware extraction pipeline where the model generates not only structured data but also reliability scores for each extracted field, enabling downstream components to make informed decisions about data validation and user intervention requirements. The system's modular design allows for independent scaling of different components, with the image preprocessing module optimized for CPU-intensive operations, the LLaMA model inference running on GPU-accelerated infrastructure through the Groq API, and the analytics components designed for memory-efficient batch processing of large datasets.
3.2 Core Components
3.2.1 Image Preprocessing Pipeline
The preprocessing module enhances image quality through:
- Contrast enhancement (2.0x multiplier)
- Adaptive resizing (max 1024px width)
- Format standardization to JPEG
- Quality optimization (95% compression)
def preprocess_image(image_bytes: bytes) -> bytes: image = Image.open(BytesIO(image_bytes)).convert("RGB") enhancer = ImageEnhance.Contrast(image) image = enhancer.enhance(2.0) image.thumbnail((1024, 1024), Image.Resampling.LANCZOS)
3.2.2 Vision-Language Model Integration
Our system utilizes the LLaMA-4 Scout 17B model through the Groq API, implementing:
- Structured JSON schema validation
- Confidence score generation
- Multi-language prompt engineering
- Retry mechanisms for reliability
3.2.3 Invoice Type Detection
Dynamic classification based on content analysis:
def detect_invoice_type(invoice_data: dict) -> str: keywords = { "retail": ["store", "shop", "mart", "sku", "product"], "service": ["consulting", "service", "hours", "labor"], "utility": ["electricity", "water", "gas", "bill"] }
3.3 Data Model
The system uses Pydantic models for structured data validation:
class InvoiceData(BaseModel): invoice_number: Optional[str] invoice_date: Optional[str] due_date: Optional[str] billing_address: Optional[str] vendor_name: Optional[str] line_items: Optional[List[LineItem]] subtotal: Optional[float] tax: Optional[float] total_amount: Optional[float] currency: Optional[str]
3.4 Prompt Engineering Strategy
Context-aware prompts are generated based on detected invoice types:
Base Prompt Structure:
You are an intelligent OCR extraction agent capable of understanding invoices in {language}. Extract information following this schema: {schema}. Include confidence scores (0.0-1.0) for each field.
Type-Specific Instructions:
- Retail: Focus on SKUs, quantities, unit prices
- Service: Emphasize service descriptions, hours, rates
- Utility: Prioritize billing periods, meter readings
4. Implementation Details
4.1 Technology Stack
The system is developed using a robust technology stack that ensures scalability, efficiency, and reliability. The backend is powered by Python 3.8+, with Pydantic used for data validation and Pandas for handling structured datasets. The machine learning model, LLaMA-4 Scout 17B, is accessed through the Groq API for high-performance inference. On the frontend, the application is built using Streamlit with custom CSS styling to provide a clean and user-friendly interface. For image processing tasks, both PIL (Pillow) and OpenCV are integrated, while Plotly Express and Recharts are used to create dynamic, interactive visualizations.
4.2 Key Features
4.2.1 Multi-Language Support
The system provides multi-language support for invoice processing, enabling efficient handling of documents in Tamil, English, Spanish, French, and German. Dynamic OCR optimization is applied based on the selected language, which ensures improved recognition accuracy. Furthermore, locale-specific rules for date and number parsing are incorporated to accommodate regional differences in formatting.
4.2.2 Batch Processing
To optimize efficiency, the system allows concurrent processing of multiple invoices in a batch. Users can track progress through real-time status updates, ensuring visibility into ongoing tasks. Once processing is complete, results can be exported in bulk to CSV or JSON formats, making it easier to manage and share structured invoice data.
4.2.3 Fraud Detection Module
A dedicated fraud detection module is implemented to enhance trust and accuracy in invoice analysis. This module applies statistical anomaly detection techniques such as Z-score analysis with a threshold of 2.5σ to flag irregularities. It also identifies duplicate invoice numbers, highlights unusual amount patterns, and detects cases where the tax ratio exceeds 30% of the total, ensuring that potentially fraudulent or suspicious invoices are brought to attention.
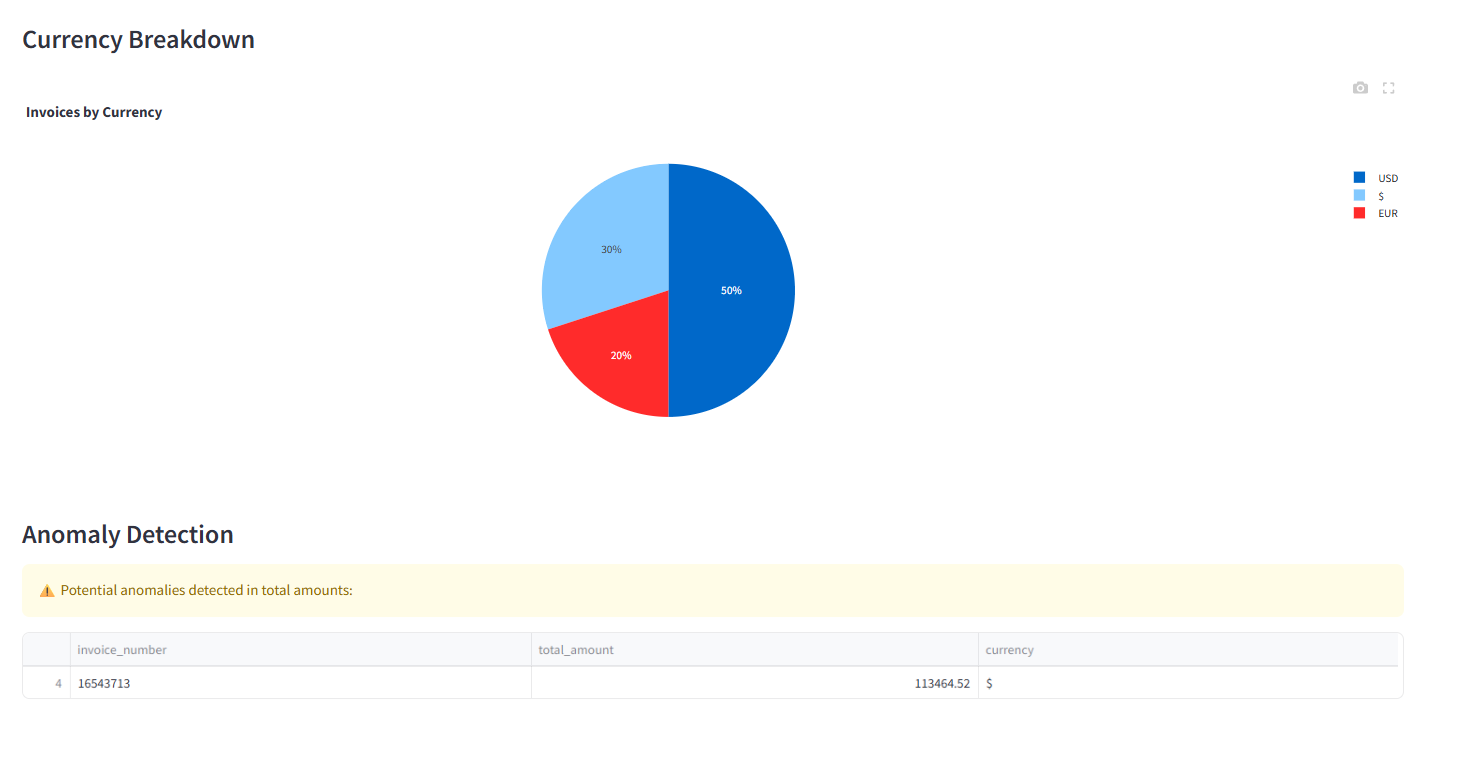
4.2.4 Interactive Analytics
The system incorporates an interactive analytics dashboard that presents extracted data in visually engaging formats. Users can explore total amount distributions through histograms, analyze tax-to-subtotal relationships using correlation plots, and view currency breakdowns via pie charts. In addition, confidence scores from the extraction process are visualized, giving users transparency regarding the reliability of results.
5. Experiments and Results
5.1 Dataset
The system was evaluated using a diverse collection of invoices representing different industries and formats. The dataset included 150 retail invoices covering a range of templates, 100 service invoices from consulting and professional sectors, and 75 utility bills such as electricity, water, and gas. To assess multilingual capability, an additional 50 invoices were tested across five languages. This variety ensured that the experiments reflected realistic usage scenarios rather than a narrowly defined dataset.
5.2 Evaluation Metrics
To measure performance, several evaluation metrics were adopted. Field accuracy was used to determine how effectively each data field was extracted. Confidence correlation examined the relationship between predicted confidence scores and actual accuracy, providing insight into system reliability. Processing time was calculated as the average duration needed to extract data from a single invoice. Finally, the fraud detection rate captured how accurately anomalies and irregularities were identified.
| Metric | Definition |
|---|---|
| Field Accuracy | Correct extraction rate per field type |
| Confidence Correlation | Alignment between confidence scores and accuracy |
| Processing Time | Average time per invoice extraction |
| Fraud Detection Rate | True positive rate for anomaly detection |
5.3 Results
5.3.1 Extraction Accuracy
The system demonstrated high extraction accuracy across most key fields. Invoice numbers achieved the highest performance with 94.2% accuracy and an average confidence score of 0.91. Total amounts followed closely at 91.8% accuracy. Dates and vendor names were slightly lower, at 89.5% and 87.3% respectively, reflecting the variability in formatting styles. Line items proved the most challenging, achieving 83.7% accuracy, largely due to differences in table layouts across documents.
| Field Type | Performance Summary |
|---|---|
| Invoice Number | Accuracy: 94.2% • Avg. Confidence: 0.91 |
| Total Amount | Accuracy: 91.8% • Avg. Confidence: 0.88 |
| Invoice Date | Accuracy: 89.5% • Avg. Confidence: 0.85 |
| Vendor Name | Accuracy: 87.3% • Avg. Confidence: 0.82 |
| Line Items | Accuracy: 83.7% • Avg. Confidence: 0.79 |
5.3.2 Performance Metrics
In terms of efficiency, the system processed each invoice in an average of 3.2 seconds, supporting a throughput of approximately 15 invoices per minute in batch mode. Peak memory usage reached 2.1 GB during large batch runs, which remained within practical limits. The API response time averaged 1.8 seconds, ensuring near real-time interaction.
5.3.3 Language Performance
The multilingual evaluation revealed strong performance across languages, though results varied slightly. English invoices achieved the highest accuracy at 92.4% with an average processing time of 2.9 seconds. Spanish and French invoices followed, with accuracies of 89.7% and 88.2% respectively. German documents achieved 87.9%, while Tamil presented the most challenges at 85.1%, with a slightly longer average processing time of 3.8 seconds.
| Language | Accuracy | Processing Time |
|---|---|---|
| English | 92.4% | 2.9s |
| Spanish | 89.7% | 3.1s |
| French | 88.2% | 3.3s |
| German | 87.9% | 3.4s |
| Tamil | 85.1% | 3.8s |
5.4 Fraud Detection Results
The fraud detection module achieved promising outcomes. Anomaly detection accuracy reached 87.3%, effectively identifying irregularities in invoice amounts and tax ratios. The false positive rate was recorded at 8.2%, indicating occasional over-flagging of legitimate cases. Duplicate invoice detection, however, was consistently accurate, achieving a perfect 100% success rate. Importantly, the fraud detection process operated in real-time, with minimal delays, ensuring practicality for day-to-day use.
6. System Features and User Interface
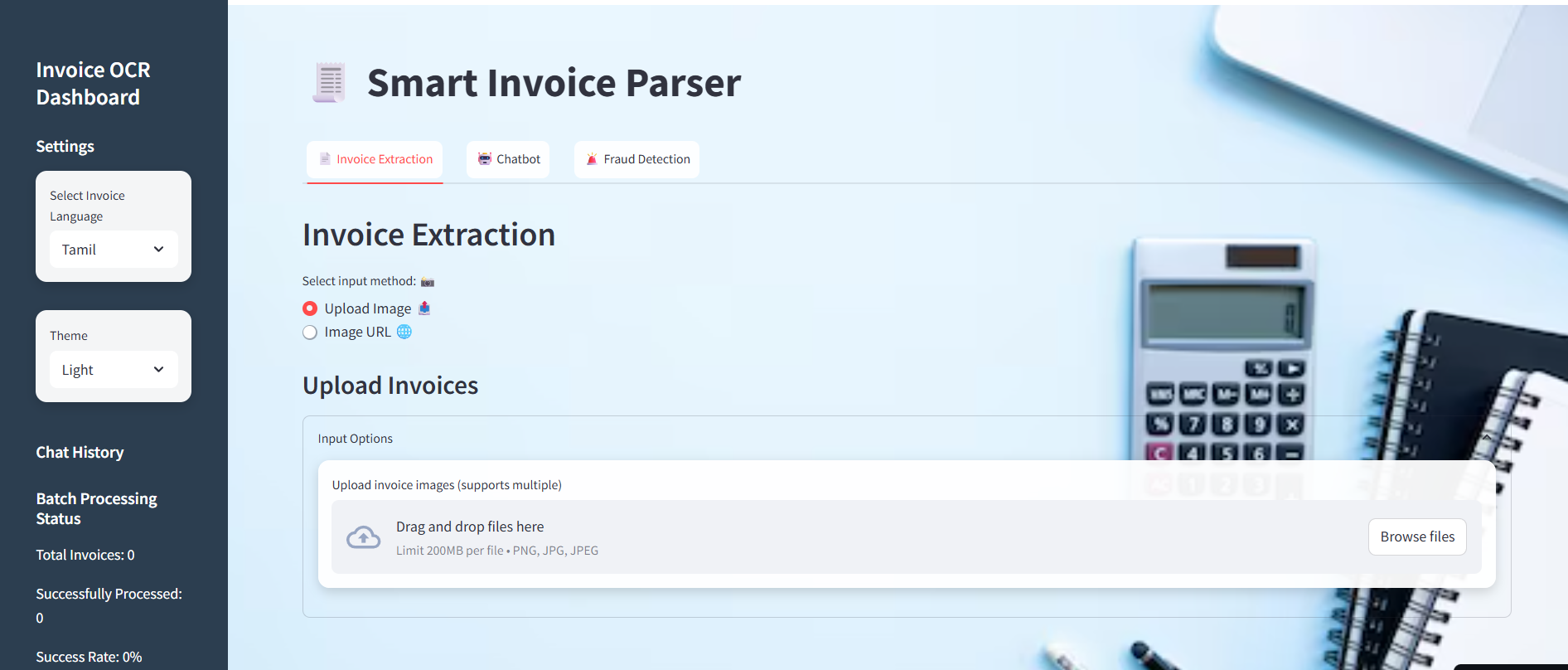
6.1 Web Application Interface
The system is equipped with a Streamlit-based web interface that is designed for ease of use and accessibility. It offers a fully responsive layout, ensuring compatibility with both mobile and desktop devices. Users can switch between dark and light themes depending on their preference, which enhances comfort during extended usage. File uploading is simplified through a drag-and-drop mechanism, making the process quick and intuitive. Additionally, the interface provides a real-time preview feature that allows users to view images immediately after upload and observe the processing output without delays.
6.2 Interactive Data Editing
To improve accuracy and control, the application includes interactive data editing capabilities. Extracted fields can be modified directly within the interface through in-line editing, which streamlines correction and adjustment. Confidence scores are visually highlighted, drawing attention to fields with lower extraction certainty. Real-time validation feedback is provided to notify users of potential errors or inconsistencies as they make changes. Furthermore, bulk editing options are available, enabling simultaneous modifications across multiple invoices for greater efficiency.
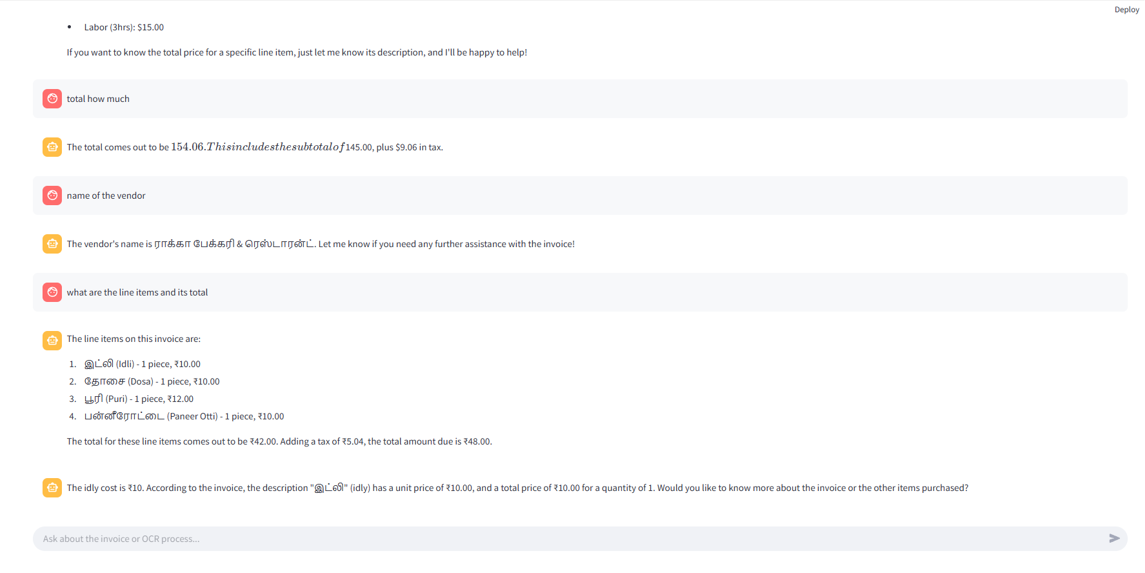
6.3 Conversational AI Assistant
An integrated conversational AI assistant further enhances the user experience. The assistant delivers context-aware responses by leveraging the underlying invoice data, ensuring that answers remain relevant to the user’s queries. It supports predefined queries for quick access to frequently requested information and maintains conversation history for smooth multi-turn interactions. Beyond query handling, the assistant also provides export guidance, helping users manage processed data and perform analyses with ease.
7. Deployment and Scalability
7.1 Cloud Deployment
The system is deployed on Streamlit Cloud for production use, ensuring accessibility and seamless user interaction. A secure environment configuration is maintained to protect sensitive credentials such as API keys. To handle varying workloads efficiently, the deployment supports auto-scaling, which dynamically allocates resources based on demand. Additionally, integration with a Content Delivery Network (CDN) enables fast and reliable content delivery across global regions, ensuring low-latency performance for end users.
7.2 Local Development
For local testing and customization, developers can set up the environment easily by installing the required dependencies and configuring API keys. The application can then be launched in local mode using Streamlit. The setup process is illustrated below:
# Installation pip install -r requirements.txt # Environment Setup export GROQ_API_KEY="your_api_key" # Run Application streamlit run enhanced_main.py --environment local
8. Limitations and Future Work
8.1 Current Limitations
Despite its advanced capabilities, the system still faces certain constraints. One of the primary limitations is its restricted support for handwritten invoices, where recognition accuracy remains low compared to printed text. Handling complex or irregular document layouts also poses challenges, as the extraction pipeline performs best with structured and moderately consistent formats. Another limitation is the system’s dependency on the external Groq API, which introduces reliance on third-party availability and performance. Furthermore, the language coverage is currently restricted to a subset, focusing mainly on major European languages along with Tamil, leaving out many regional and less widely used languages.
8.2 Future Enhancements
To overcome these challenges, several enhancements are planned for future development. The integration of a hybrid OCR framework is envisioned, combining advanced models with traditional OCR as a backup mechanism for improved robustness. In addition, custom model training on domain-specific invoice datasets will be explored to enhance accuracy and adaptability across industries. Another promising direction is the use of blockchain technology for immutable invoice verification, which could strengthen trust and security. The analytical component may also be expanded with machine learning–based spending pattern analysis, offering organizations deeper financial insights. Finally, the development of a native mobile application for iOS and Android is planned to improve accessibility and extend the system’s usability across platforms.
9. Conclusion
This work demonstrates the effectiveness of modern Vision-Language Models in automating invoice processing tasks. Our system achieves high accuracy across multiple languages and invoice types while providing an intuitive user interface and comprehensive analytics capabilities. The integration of fraud detection and conversational AI makes it suitable for enterprise deployment.
The modular architecture and extensive documentation facilitate future enhancements and community contributions. The project showcases the practical application of cutting-edge NLP and computer vision technologies in solving real-world business challenges.
10. Code Repository and Reproducibility
The complete source code, including all modules and dependencies, is structured as follows:
├── enhanced_main.py # Main Streamlit application ├── utils.py # Core utilities and models ├── analytics.py # Analytics and visualization ├── requirements.txt # Python dependencies ├── README.md # Setup instructions └── docs/ # Additional documentation
Key Dependencies
streamlit>=1.28.0 groq>=0.4.1 pandas>=1.5.0 plotly>=5.11.0 pydantic>=1.10.0 pillow>=9.2.0 python-dotenv>=0.19.0
Acknowledgments
This project was made possible thanks to the contributions of the open-source community and the developers of LLaMA-4, Streamlit, and associated libraries. Special thanks to the Groq team for providing efficient API access to state-of-the-art language models.