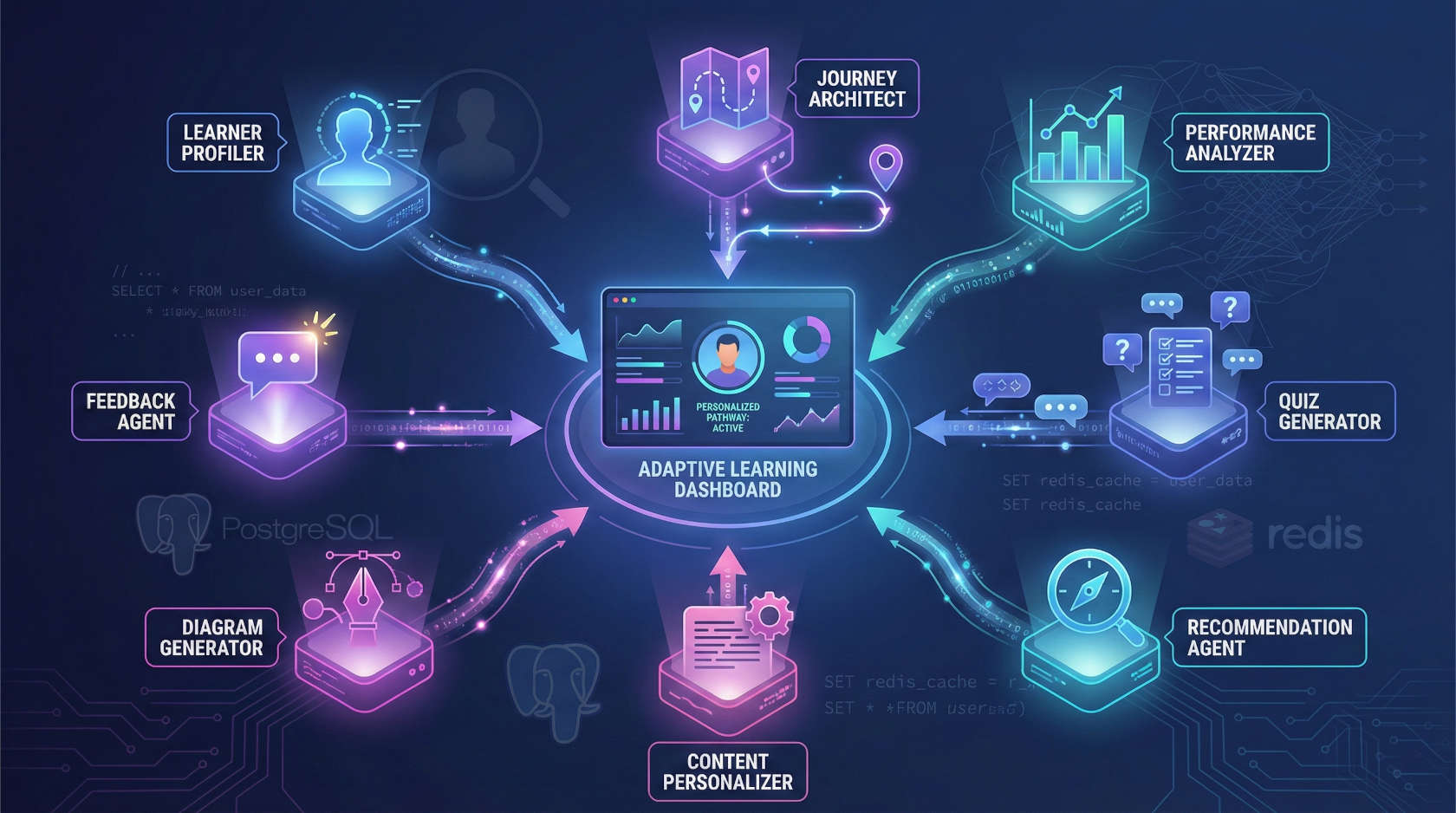
The AlkenaCode Adaptive Learning Platform is a production-grade, multi-agent system built for true personalization in education. Instead of fixed rules, eight AI agents reason together to adapt lessons, quizzes, and recommendations to each learner. Powered by FastAPI, Next.js, PostgreSQL, and Redis, the platform continuously evolves based on student performance and preferences.
Eight specialized agents coordinate through LangGraph, combining profiling, reasoning, and adaptive feedback. Sessions persist with cookies, and caching boosts response speed by over 70%.
flowchart LR subgraph Frontend["Frontend (Next.js)"] A[Dashboard] --> B[Session Manager] B --> C[Cookie Storage] end subgraph Backend["Backend (FastAPI + LangGraph)"] D[API Endpoints] --> E[Orchestrator] E --> F[Learner Profiler] E --> G[Journey Architect] E --> H[Quiz Generator] E --> I[Performance Analyzer] E --> J[Content Personalizer] end subgraph Infra["Infrastructure"] K[(PostgreSQL)] L[(Redis Cache)] M[LLM APIs] end Frontend --> D Backend --> K Backend --> L E --> M
Each agent focuses on a specific layer of personalization; from understanding users to generating adaptive content.
Purpose: Analyzes onboarding data to create comprehensive, multi-dimensional learner profiles.
How it works: The Learner Profiler uses a 4-node LangGraph workflow combined with DuckDuckGo API for topic discovery and Wikipedia API for authoritative content enrichment:
def create_learner_profile(onboarding_data: Dict) -> Dict: """ 4-node workflow: 1. interest_analyzer - Categorizes interests (e.g., "Python" → "Programming") 2. skill_assessor - Evaluates skill level per interest area 3. learning_style_analyzer - Determines optimal content formats 4. profile_synthesizer - Combines insights into unified profile """ workflow = StateGraph(ProfilerState) workflow.add_node("interest_analyzer", interest_analyzer_node) workflow.add_node("skill_assessor", skill_assessor_node) workflow.add_node("learning_style_analyzer", learning_style_node) workflow.add_node("profile_synthesizer", profile_synthesizer_node) workflow.set_entry_point("interest_analyzer") workflow.add_edge("interest_analyzer", "skill_assessor") workflow.add_edge("skill_assessor", "learning_style_analyzer") workflow.add_edge("learning_style_analyzer", "profile_synthesizer") workflow.add_edge("profile_synthesizer", END) return workflow.compile().invoke({"onboarding_data": onboarding_data})
Output: The profiler generates a comprehensive profile including overall skill level (beginner/intermediate/advanced), interest categories with priority rankings, learning style preferences (visual/reading/interactive/mixed), estimated learning pace, and a confidence score (typically 85-95%) indicating assessment certainty.
Example:
{ "overall_skill_level": "beginner", "category": "Programming", "priority_topics": ["Variables", "Functions", "OOP"], "learning_style": "visual", "learning_pace": "moderate", "confidence": 0.95 }
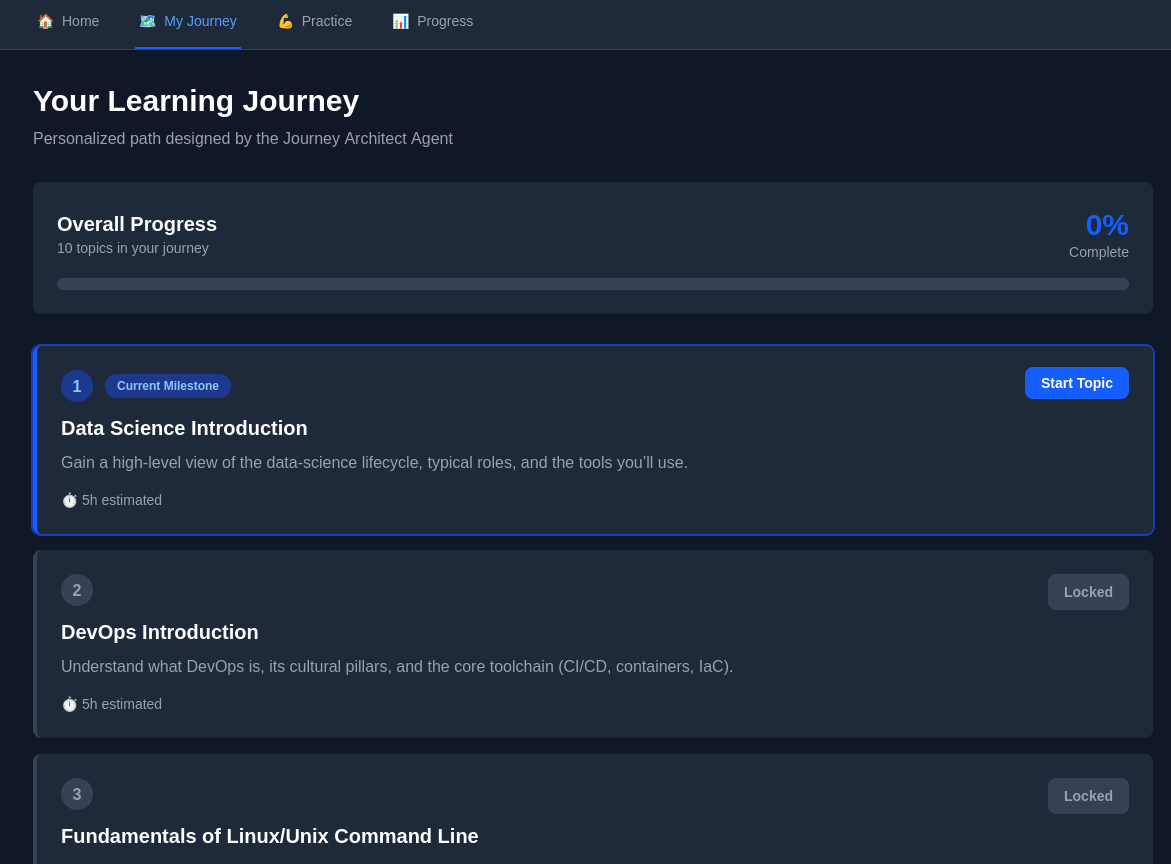
Purpose: Designs personalized learning paths with intelligent prerequisite mapping and topic sequencing.
How it works: Uses a 4-node LangGraph workflow combined with DuckDuckGo API for topic discovery:
def create_learning_journey(profile: Dict) -> List[Dict]: """ 4-node workflow: 1. topic_expander - Discovers topics via DuckDuckGo Instant Answer API 2. prerequisite_mapper - Maps dependencies between topics using LLM reasoning 3. journey_sequencer - Orders topics for optimal learning progression 4. journey_finalizer - Adds milestones, unlock conditions, time estimates """ workflow = StateGraph(ArchitectState) workflow.add_node("topic_expander", topic_expander_node) workflow.add_node("prerequisite_mapper", prerequisite_mapper_node) workflow.add_node("journey_sequencer", journey_sequencer_node) workflow.add_node("journey_finalizer", journey_finalizer_node) # Connect nodes workflow.set_entry_point("topic_expander") workflow.add_edge("topic_expander", "prerequisite_mapper") workflow.add_edge("prerequisite_mapper", "journey_sequencer") workflow.add_edge("journey_sequencer", "journey_finalizer") workflow.add_edge("journey_finalizer", END) return workflow.compile().invoke({"profile": profile})
Key Features: Dynamic topic discovery via DuckDuckGo API and Wikipedia API ensures current, authoritative content. LLM-powered prerequisite reasoning maps dependencies (e.g., "Functions" before "OOP"). Every 5th topic marks a milestone checkpoint. Topics unlock only after achieving ≥60% mastery of prerequisites. Time estimates (2-15 hours per topic) help learners plan effectively.
Output: Ordered journey with 9-50 topics tailored to user interests and skill level.
Example:
[ { "topic": "Python Installation and Setup", "position": 1, "status": "available", "prerequisites": [], "estimated_hours": 2, "description": "Set up Python environment and tools" }, { "topic": "Basic Syntax and Variables", "position": 2, "status": "locked", "prerequisites": ["Python Installation and Setup"], "estimated_hours": 5, "unlock_conditions": {"mastery_required": {"Python Installation": 60}} }, { "topic": "Object-Oriented Programming Basics", "position": 5, "status": "locked", "prerequisites": ["Functions and Scope"], "estimated_hours": 10, "is_milestone": True # Milestone marker } ]
Processes quiz history and updates mastery levels:
def analyze_performance(quiz_data): mastery = {} for topic, scores in quiz_data.items(): mastery[topic] = sum(scores[-3:]) / len(scores[-3:]) return mastery
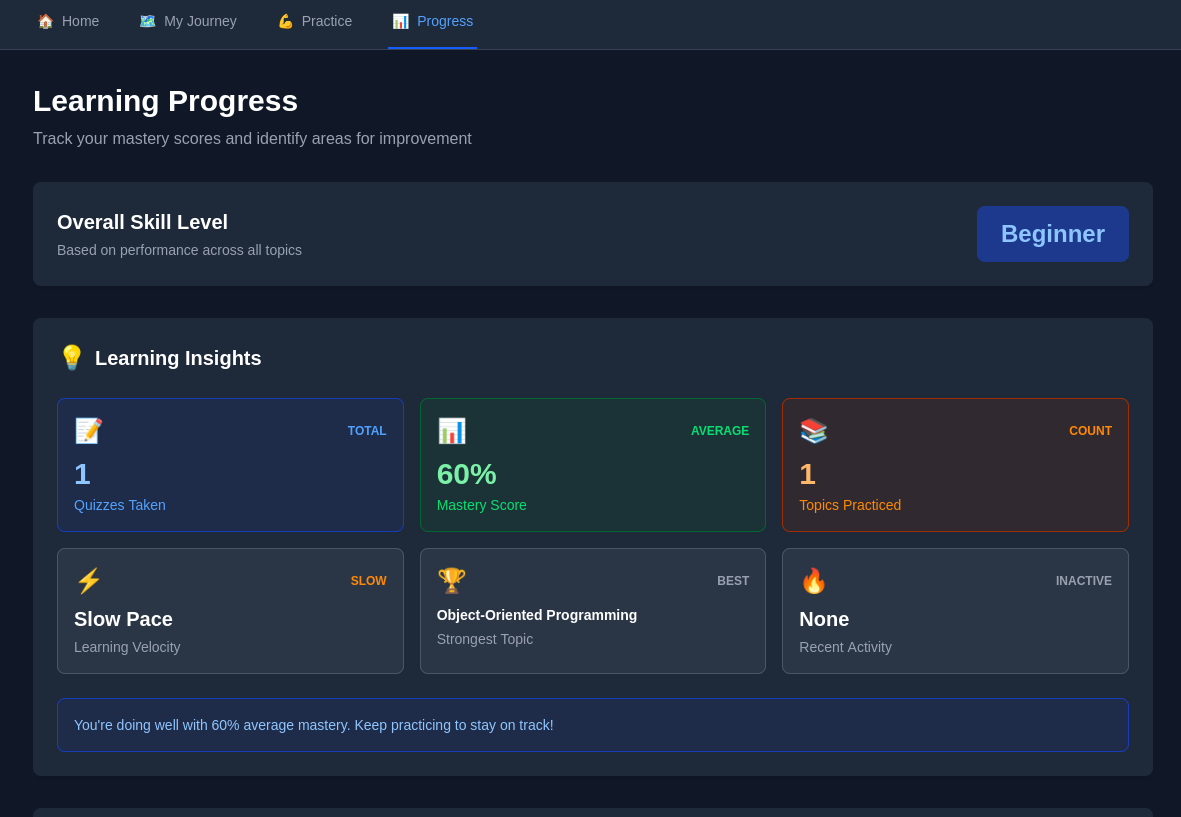
Output: Comprehensive analysis including topic mastery scores (0-100 scale), skill level classifications per topic, knowledge gaps, strengths, learning velocity metrics, difficulty recommendations for Quiz Generator, and content complexity adjustments for Content Personalizer.
Suggests new topics based on strengths and gaps:
def recommend_topics(profile, mastery): return [ {"topic": "Data Structures", "reason": "Fill knowledge gap"}, {"topic": "Advanced Functions", "reason": "Build on strengths"} ]
Generates adaptive materials with multi-model retries:
def generate_content(topic, level): for model in MODELS: try: content = model.invoke(topic, level) if validate(content): return content except: continue return fallback_content(topic)
Produces quizzes that match user mastery levels.
def generate_quiz(topic, difficulty): return [{"question": "What is a list comprehension?", "correct": "B"}]
sequenceDiagram User->>Frontend: Complete onboarding Frontend->>API: Send data API->>Profiler: Analyze user Profiler->>Architect: Build learning path Architect->>DB: Save profile & journey API->>Frontend: Return dashboard
flowchart TD A[User takes quiz] --> B[Analyze performance] B --> C[Update mastery] C --> D[Recommend topics] D --> E[Adjust journey]
1. Multi-Model Resilience
3 models × 3 retries per operation achieves 99%+ success rate. System attempts primary model first, then automatically falls back to secondary and tertiary models. Self-correcting prompts analyze errors and adjust for next retry, progressively guiding models toward proper output format. Remains functional during API outages, model bugs, or performance degradation.
2. Explainable Decisions
Every agent decision logged to agent_decisions audit table with: agent name, input data/context, output/recommendations, natural language reasoning, confidence scores (0-1), and timestamps. Enables learners to understand recommendations, educators to audit pedagogy, and developers to debug.
Example audit log:
{ "agent_name": "performance_analyzer", "decision_type": "mastery_update", "reasoning": "User showed consistent improvement across 3 recent quizzes (60%, 80%, 80%). Updated mastery from 65% to 78.5% using weighted algorithm that prioritizes recent performance.", "confidence": 0.92, "input_data": {"quiz_scores": [60, 80, 80], "previous_mastery": 65.0}, "output_data": {"new_mastery": 78.5, "recommendation": "ready_for_advanced"} }
3. Weighted Mastery Tracking
Recent performance carries 2× more influence than historical average. Prevents learners from being trapped by poor early performance; mastery scores climb rapidly with improvement. Balances quick adaptation with stability against volatile single-quiz swings.
# Weighted algorithm new_mastery = (old_mastery * attempts + current_score * 2) / (attempts + 2)
4. Session Persistence
Cookie-based session management with 1-year expiration ensures learners never lose progress. Sessions survive page reloads, browser restarts, different tabs, and network interruptions. Long expiration allows weeks or months of breaks without losing place in personalized journey.
AlkenaCode implements multiple layers of safety to ensure appropriate, educational content:
All AI-generated content passes through validation:
Prevents abuse and ensures fair resource usage:
Quiz and content generation includes safety prompts:
No personal data collected beyond learning preferences; no emails, names, or identifying information required. Anonymous UUIDs as identifiers. Cookie-based sessions stored locally, not server-side. No tracking beyond learning analytics; no third-party scripts, ads, or profiling. GDPR-compliant with data export/deletion functionality.
Actively maintained open-source project. Bug fixes deployed within 24-48 hours. Security patches applied immediately. Feature enhancements driven by community feedback. Documentation updates reflect latest changes. Regular dependency updates maintain compatibility. Current Status: ✅ Production-Ready (v1.0.0).
Official Repository: https://github.com/Kiragu-Maina/ultimate-adaptive-guide
Complete source code (backend + frontend), Docker deployment configuration, comprehensive /docs folder, API reference with examples, troubleshooting guides, and contributing guidelines.
Before deploying AlkenaCode, ensure you have:
Clone the repository:
git clone https://github.com/Kiragu-Maina/ultimate-adaptive-guide cd ultimate-adaptive-guide/multiagential
Configure environment:
cp .env.example .env # Edit .env and add your OPENROUTER_API_KEY
Start the platform:
docker-compose up -d
Access the application:
Check that all services are running:
docker-compose ps
Expected output shows postgres, redis, backend, and frontend services as "Up".
For detailed setup instructions, troubleshooting, and advanced configuration, see:
This project is licensed under the MIT License - see the LICENSE file for details.
You are free to use, modify, and distribute this software for personal or commercial purposes with attribution.