
Onboarding merchants with a bank is a crucial step in providing them with the financial infrastructure necessary to run their businesses efficiently. Banks offer a wide range of integrated payment solutions, including POS systems, payment gateways, and digital banking services, that streamline transaction processing, reduce operational costs and improve cash flow management. Additionally, partnering with a bank provides merchants enhanced fraud protection, customer support, and opportunities to scale their business with financing and growth tools.
But merchant onboarding at banks is a critical yet time-consuming process. Currently, this involves merchants manually filling out paper forms at bank branches. These forms are then scanned and sent to central processing centres located at 4 locations. At these locations, the forms are printed, and staff manually enter the data into the bank’s system. This method results in a turnaround time of 4-5 days before the data even begins verification, impacting the bank’s efficiency. Moreover, the volume of manual data entry increases the chances of errors, making data quality an ongoing challenge.
Our project aims to revolutionise the merchant onboarding process by developing an automated pipeline that eliminates manual data entry. By digitising handwritten text from scanned onboarding forms and structuring the data for direct input into the bank’s system, we aim to reduce the turnaround time from 4-5 days to just a few minutes. The goal is to achieve efficiency while improving data accuracy and consistency, streamlining the entire process.
The data for this project is collected by scanning onboarding forms filled out at bank branches. These scanned forms are saved in zip files, each of which contains multiple folders. Each folder represents a single onboarding session, containing 15-17 images in .tif format. However, only 3 of these images are relevant to the onboarding form, while the remaining images include irrelevant documents such as internal bank guidelines and supporting materials submitted by the merchant.
Given the nature of scanned documents, preprocessing is crucial for enhancing image quality. The pre-processing steps include:
Denoising - Gaussian Blurring and median filtering are applied to remove noise and imperfections from the image.
Enhancing Contrast - Histogram equalization and contrast stretching are used to improve text clarity by adjusting brightness and contrast, making the text more readable.
Resolution Standardization - Image resizing is performed using interpolation techniques ensuring a consistent resolution across all images.
Orientation Correction - Contouring and edge detection are employed to identify skewed or misaligned text, followed by rotation or transformation, ensuring all images are aligned properly for further processing.
Once the images have been pre-processed, the next step is to identify the 3 relevant onboarding form images. Since these 3 images can appear anywhere within a set of 15-17 images, a classification model is necessary to streamline the identification process.
Initially, a manually labelled dataset was created from 6,000 images. Each image was tagged according to whether it represented Page 1, Page 2, Page 3, or other irrelevant documents.
Using MobileNetV2 model, a pre-trained convolutional neural network (CNN), to classify these images. The same was chosen for its lightweight architecture, containing fewer parameters and 53 layers. Compared to other CNN models like ResNet and VGG,
MobileNetV2 delivers higher processing speeds, reduced inference time, and lower computational complexity, making it ideal for this project.
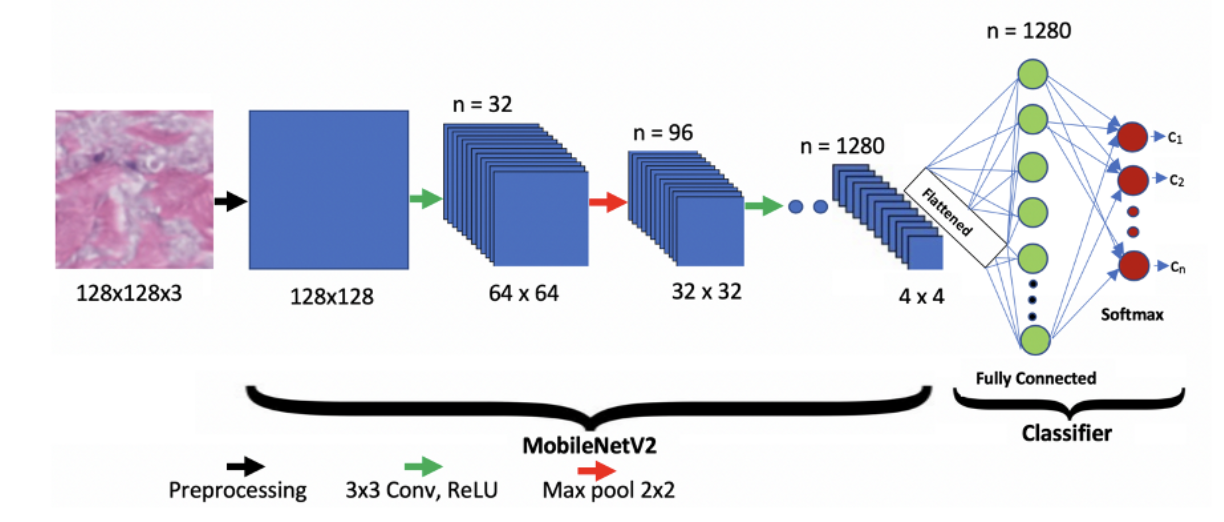
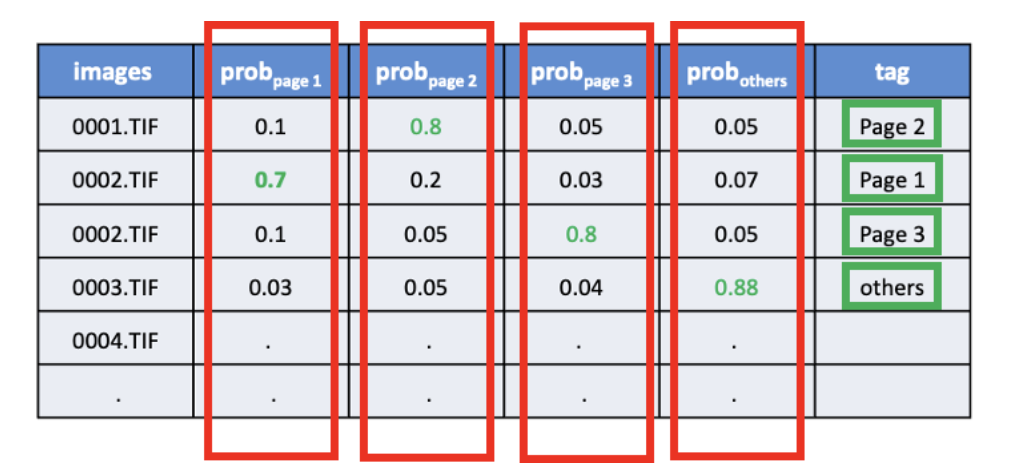
Once trained, the model processes each folder of images and assigns a probability score for each class (Page 1, Page 2, Page 3, or Other). The image with the highest probability in each category is then tagged accordingly, ensuring only the relevant forms are identified and used in the automated pipeline.
Transformers, usually known for their exceptional handling of sequential data and attention mechanisms, proves highly effective for OCR tasks. So, a pipeline was built to prepare scanned images for the model. This included denoising, improving contrast, converting images to grayscale, and applying adaptive thresholding to separate text form noisy backgrounds. Techniques like dilation and contouring helped isolate text regions, while pixel averaging, and fixed pixel approaches ensured accurate text detection.
Despite this, a significant challenge arose in mapping the extracted text to its correct fields due to inconsistent layouts of the forms and obstructive stamps. To address this, we integrated Azure Document Intelligence, a cloud-based solution that excelled in analysing document layouts and accurately mapping field values, significantly enhancing the overall process.
In Azure Document Intelligence, once the relevant form images are processed, the extracted data is initially saved in structured JSON format. This includes both field names and their corresponding values.
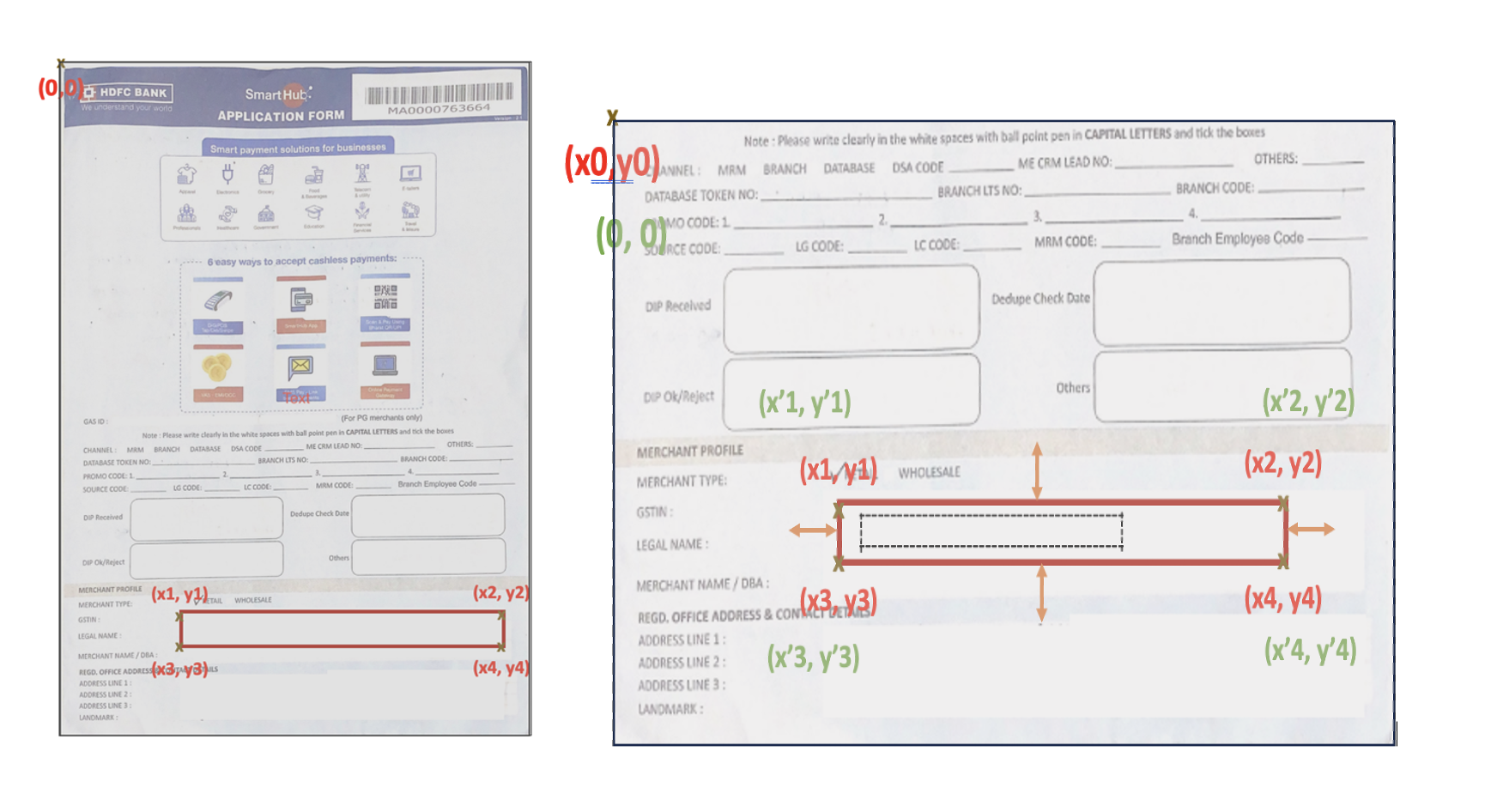
To further refine field extraction and tackle inconsistencies in field-value mapping, a dynamic origin shift logic is implemented where instead of relying on top-left corner of the form as starting point (which can often cause issues due to form misalignment or partial screening), we strategically placed a new origin point with the form, closer to where the relevant data begins. Additionally, a margin of error was introduced around the calculated pixel locations for each field, allowing some flexibility. This prevents overly rigid conditions and ensures that even if the form is slightly misaligned, the model can still correctly identify and extract the necessary fields.
Once the data is extracted and text is prepared, validating and setting rules for each field becomes crucial to ensure accuracy. With more than 70 fields being processed, each field is assigned specific validation criteria.
For example, the PAN Card field is required to exactly have 10 characters: the first five alphabet, next four numeric and last one alphabetic. If any of the fields fails to meet the designated rule, it gets automatically highlighted in the output, making it easy to identify and correct errors quickly.
Our solution drastically reduced the turnaround time for form processing. Tasks that previously took 8-10 minutes per form are now completed in just 20-30 seconds resulting in over a 95% reduction in processing time. This efficiency ensures that forms are processed and entered the system on the same day.
The model, with an 84% accuracy, has greatly enhanced data entry reliability. Rule based validation has ensured consistency and prepared the extracted data for analysis, enabling the bank to offer tailored services to merchants based on accurate onboarding information.
By eliminating manual intervention, bank has achieved more systematic and scalable onboarding with high quality data entry, leading to improved service, business growth and higher customer satisfaction.