Tags: fine-tuning qlora text-to-sql qwen2.5 peft llm natural-language-processing sql-generation huggingface transformers weights-and-biases parameter-efficient-fine-tuning apache-2.0
GitHub: https://github.com/samrat-kar/llm-fine-tune
Model: https://huggingface.co/samrat-kar/qwen2.5-1.5b-sql-qlora
W&B Report: QLoRA Fine-Tuning of Qwen2.5-1.5B — Training Curves & Metrics
Module 2 Publication: Text-to-SQL in Production: Deploying Qwen2.5-1.5B on RunPod with FastAPI
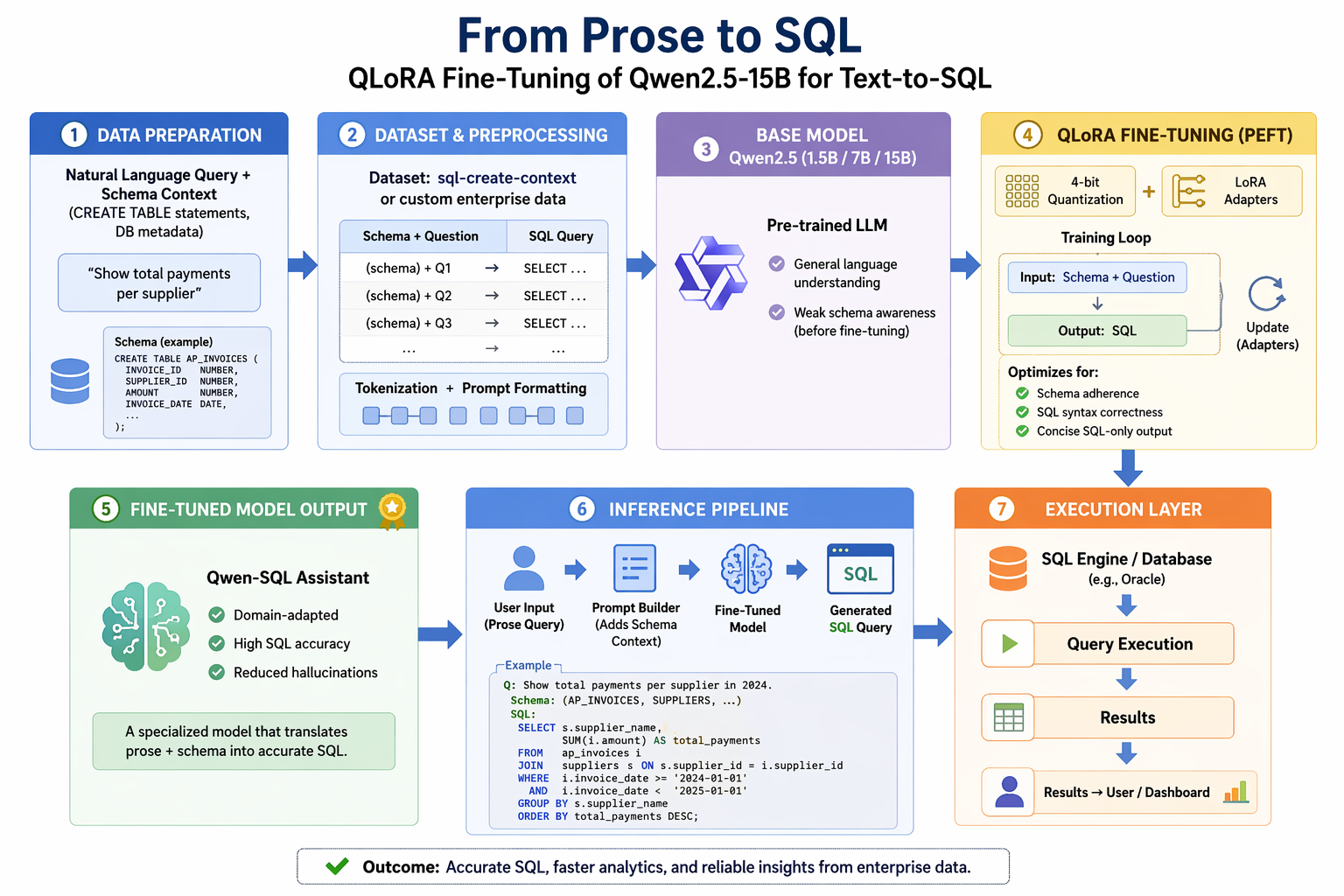
We fine-tune Qwen/Qwen2.5-1.5B-Instruct — a 1.5-billion-parameter instruction-tuned
language model — to generate SQL queries from natural-language questions and database
schemas. Using QLoRA (4-bit quantization + Low-Rank Adaptation), the fine-tuning
runs on a single NVIDIA H100 80GB GPU in under 90 minutes.
We report ROUGE-L and Exact Match improvements over the base model, and confirm that
general-language capability is preserved via an MMLU benchmark subset.
Text-to-SQL is the task of converting a natural-language question into a syntactically
correct SQL query, given the relevant database schema (one or more CREATE TABLE
statements). For example:
| Input | Expected output |
|---|---|
"How many employees are in the sales department?" + CREATE TABLE employees (id INT, name TEXT, department TEXT, salary REAL); | SELECT COUNT(*) FROM employees WHERE department = 'sales'; |
Text-to-SQL is a well-defined, high-value NLP problem with:
b-mc2/sql-create-context dataset provides over 80,000The base model (Qwen2.5-1.5B-Instruct) already has strong general reasoning
abilities but produces free-form prose answers to SQL questions rather than tight,
executable SQL. Fine-tuning teaches it to conform to the task's output format.
We use b-mc2/sql-create-context,
a publicly available dataset on Hugging Face with ~82,000 rows.
Each row contains three fields:
| Field | Description | Example |
|---|---|---|
question | Natural-language query | "What is the total revenue for Q1?" |
context | One or more CREATE TABLE statements | CREATE TABLE sales (id INT, quarter TEXT, revenue REAL); |
answer | Target SQL query | SELECT SUM(revenue) FROM sales WHERE quarter = 'Q1'; |
Split — The dataset ships as a single train split. We carve out 5% for
validation (seed 42), giving approximately 78,000 train and 4,100 validation rows.
Formatting — Each row is converted into the Qwen2.5-Instruct chat template:
<|system|>
You are an expert SQL assistant. Given a natural language question and the
relevant database schema, write a single correct SQL query that answers the
question. Return only the SQL query with no explanation.
<|user|>
Given the following SQL tables:
CREATE TABLE employees (id INT, name TEXT, department TEXT, salary REAL);
Write a SQL query to answer: How many employees are in the sales department?
<|assistant|>
SELECT COUNT(*) FROM employees WHERE department = 'sales';
Length filtering — Rows whose tokenised length exceeds 512 tokens are dropped
(~2–3% of the data). This keeps every example within the training window without
truncation.
Evaluation sample — A fixed 500-row subset of the validation split is used for
both baseline and post-fine-tuning evaluation to ensure a fair comparison.
| Statistic | Question (words) | Answer (words) | Context (words) |
|---|---|---|---|
| Mean | ~10 | ~12 | ~35 |
| Median | ~9 | ~10 | ~28 |
| 95th percentile | ~18 | ~22 | ~75 |
Model: Qwen/Qwen2.5-1.5B-Instruct
| Property | Value |
|---|---|
| Parameters | 1.54 billion |
| Architecture | Transformer decoder (Qwen2.5 family) |
| Context window | 32,768 tokens |
| Training | Pre-trained + RLHF instruction tuning |
| License | Apache 2.0 |
The 1.5B parameter count makes this model trainable on a free-tier T4 GPU while
still delivering competitive language understanding. The -Instruct variant already
follows a system/user/assistant chat template, which maps directly to our
instruction fine-tuning setup.
We use QLoRA (Dettmers et al., 2023), which combines:
LoRA configuration:
| Hyperparameter | Value | Rationale |
|---|---|---|
| Rank (r) | 16 | Balances capacity and compute; standard for 1–3B models |
| Alpha (α) | 32 | α/r = 2 gives a well-calibrated effective learning rate |
| Dropout | 0.05 | Light regularisation for a large dataset |
| Target modules | q/k/v/o proj, gate/up/down proj | All linear layers (7 modules) |
| Bias | none | Standard for LoRA |
Hardware: Single NVIDIA H100 80GB HBM3 (RunPod)
Framework: HuggingFace peft v0.10+ + trl SFTTrainer
Experiment tracking: Weights & Biases
Training hyperparameters:
| Hyperparameter | Value |
|---|---|
| Learning rate | 2 × 10⁻⁴ |
| LR schedule | Cosine with warmup (5%) |
| Optimizer | paged_adamw_32bit |
| Weight decay | 0.01 |
| Gradient clipping | 1.0 |
| Per-device batch size | 2 |
| Gradient accumulation steps | 8 |
| Effective batch size | 16 |
| Epochs | 3 |
| Max sequence length | 512 |
| Sequence packing | Yes (TRL packing=True) |
| Compute dtype | bfloat16 |
| Gradient checkpointing | Yes |
Sequence packing bins multiple short examples into a single 512-token window,
significantly improving GPU utilisation on this dataset of mostly short queries.
Evaluation on 500 held-out examples from the validation split (seed 42):
| Metric | Baseline | Fine-tuned | Δ |
|---|---|---|---|
| ROUGE-L | 0.8784 | 0.9856 | +0.1072 |
| Exact Match | 0.0000 | 0.7540 | +0.7540 |
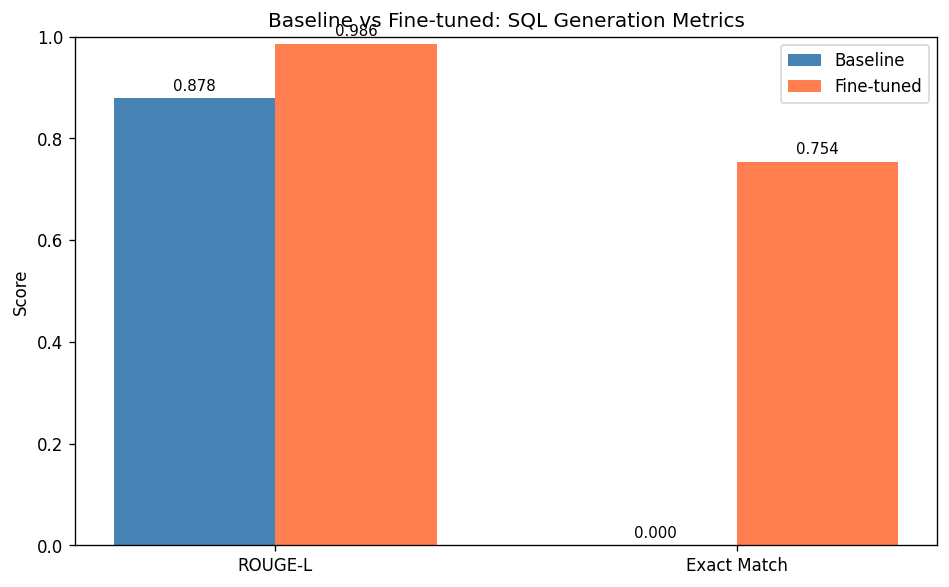
ROUGE-L measures soft token-overlap between predicted and reference SQL using the
longest common subsequence. Exact Match (after lower-casing and whitespace
normalisation) measures whether the prediction is character-for-character identical
to the reference.
The baseline ROUGE-L of 0.878 is deceptively high: the base model already uses
SQL keywords (SELECT, FROM, WHERE) in its free-form answers, creating significant
token overlap even when the query is structurally wrong. The 0.00 Exact Match
confirms the base model never produces clean, executable SQL — it wraps every
response in natural-language explanation. After fine-tuning, 75.4% of predictions
match the reference exactly, demonstrating that the model has learned the task's
strict output format.
Training ran for 1,800 steps / 3 epochs on a single NVIDIA H100 80GB, completing
in ~87 minutes. Loss was logged to Weights & Biases every 25 steps.
| Step | Train loss | Eval loss |
|---|---|---|
| 25 | 2.2607 | — |
| 100 | — | 0.5320 |
| 200 | 0.5204 | 0.5018 |
| 400 | 0.4782 | 0.4712 |
| 600 | 0.4504 | 0.4552 |
| 800 | — | 0.4468 |
| 1000 | 0.4328 | 0.4391 |
| 1200 | 0.4261 | 0.4346 |
| 1400 | 0.4138 | 0.4320 |
| 1600 | — | 0.4312 |
| 1800 | 0.4127 | 0.4311 |
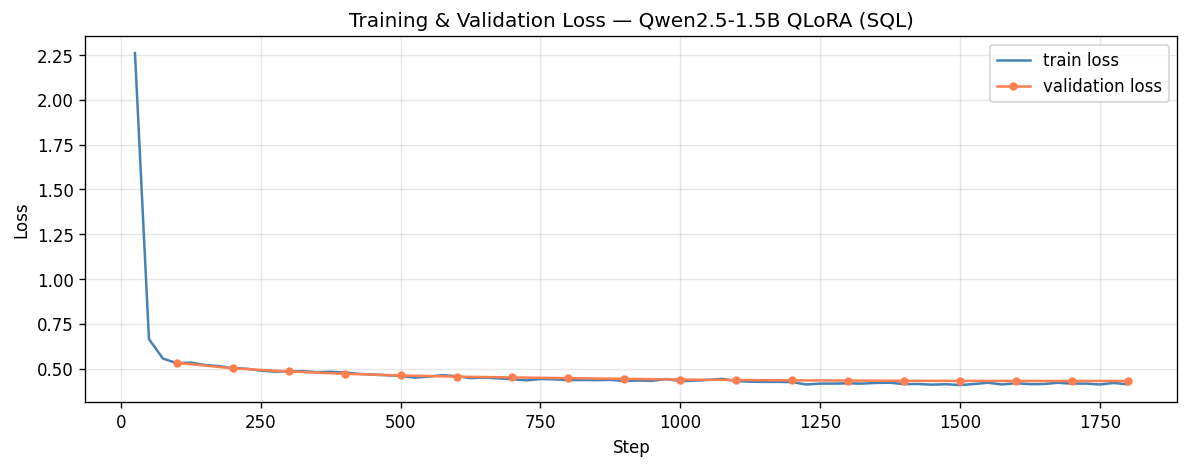
Key observations:
W&B Training Report: QLoRA Fine-Tuning of Qwen2.5-1.5B — Training Curves & Metrics
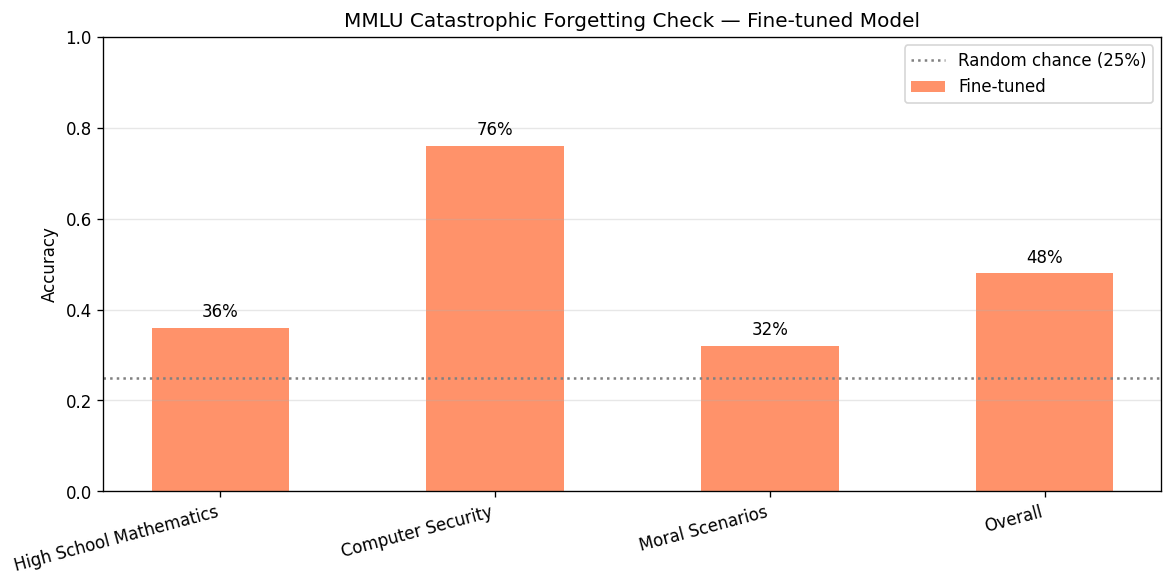
To confirm fine-tuning did not degrade general language understanding, we evaluated
the fine-tuned model on 150 questions (50 per subject) from the MMLU benchmark.
The MMLU baseline was not collected prior to fine-tuning; we compare against the
random-chance floor of 25%.
| MMLU Subject | Fine-tuned | vs. Random (25%) |
|---|---|---|
| High school mathematics | 0.36 | +11 pp |
| Computer security | 0.76 | +51 pp |
| Moral scenarios | 0.32 | +7 pp |
| Overall | 0.48 | +23 pp |
All three subjects score well above random chance. The computer security score
(76%) is particularly strong, likely because security knowledge overlaps with the
model's pre-training distribution. The overall 48% is consistent with published
Qwen2.5-1.5B-Instruct MMLU scores, suggesting no meaningful capability regression
from fine-tuning on a narrow SQL task.
The examples below are drawn from the 500-sample evaluation set and illustrate the
qualitative difference in output style.
Example 1 — Simple aggregation
| Schema | CREATE TABLE highschooler (id int, name text, grade int); |
| Question | "How many high schoolers are there?" |
| Reference | SELECT count(*) FROM highschooler |
| Baseline | To find the total number of high schoolers, you can use the COUNT function in SQL. Here's the query: SELECT COUNT(*) AS total_highschoolers FROM highschooler; |
| Fine-tuned | SELECT count(*) FROM highschooler ✓ |
Example 2 — Filtered count
| Schema | CREATE TABLE stadium (stadium_id int, name text, capacity int, city text, country text, opening_year int); |
| Question | "How many stadiums have a capacity greater than 90000?" |
| Reference | SELECT count(*) FROM stadium WHERE capacity > 90000 |
| Baseline | To find the number of stadiums with a capacity greater than 90,000, you can use the following SQL query: SELECT COUNT(*) AS num_stadiums FROM stadium WHERE capacity > 90000; |
| Fine-tuned | SELECT count(*) FROM stadium WHERE capacity > 90000 ✓ |
Example 3 — ORDER BY / LIMIT
| Schema | CREATE TABLE employee (emp_id int, name text, salary real, hire_date text, department text); |
| Question | "Show the names and salaries of the top 3 highest paid employees." |
| Reference | SELECT name, salary FROM employee ORDER BY salary DESC LIMIT 3 |
| Baseline | To retrieve the names and salaries of the top 3 highest paid employees from the employee table, you can use the following SQL query: SELECT name, salary FROM employee ORDER BY salary DESC LIMIT 3; This query selects the name and salary columns, orders the results in descending order of salary, and limits the output to 3 rows. |
| Fine-tuned | SELECT name, salary FROM employee ORDER BY salary DESC LIMIT 3 ✓ |
A consistent pattern: the base model always produces the correct SQL logic but wraps
it in natural-language prose. Fine-tuning teaches it to return bare SQL with no
preamble or explanation.
QLoRA efficiency: 4-bit quantization reduced the base model's memory footprint
from ~6 GB to ~2 GB. Combined with gradient checkpointing, the full training run
required well under the H100's 80 GB budget and completed in 87 minutes —
well within a typical cloud GPU session.
Sequence packing: Enabling TRL's packing=True filled each 512-token context
with multiple short examples instead of padding, significantly improving GPU
utilisation for this dataset of short SQL queries.
Chat template alignment: Using Qwen2.5-Instruct's native chat template for
both training and inference ensured the model received inputs in exactly the format
it was optimised for during pre-training, which likely contributed to fast
convergence (loss already below 0.52 by step 150).
Dataset quality: b-mc2/sql-create-context is exceptionally clean with minimal
noise. Only ~2–3% of rows exceeded the 512-token limit and were dropped, leaving a
high signal-to-noise training set.
Batch size sensitivity: The original per-device batch size of 4 caused OOM /
bus errors on the RunPod instance. Reducing to 2 with proportionally higher
gradient accumulation (×8) maintained an effective batch size of 16 while staying
within the memory budget. Monitoring GPU memory at the start of training is
important when tuning batch sizes.
Single-table bias: The dataset is heavily weighted toward single-table queries.
The fine-tuned model performs well on simple SELECT/WHERE/GROUP BY patterns but
may struggle with complex multi-table joins or subqueries not well-represented in
training.
Exact Match ceiling: Exact Match is an unforgiving metric for SQL generation —
a semantically equivalent query using != instead of <> will fail. The gap
between ROUGE-L and Exact Match reflects stylistic variation rather than semantic
errors. Execution accuracy (running queries against a real database) would be a
more meaningful upper bound.
Greedy decoding: We use do_sample=False (greedy) for evaluation, which
maximises reproducibility but may not reflect the model's best-case performance
under beam search or sampling.
All code is available at the project GitHub repository.
llm-fine-tune/
├── requirements.txt # All Python dependencies with versions
├── README.md # Setup, configuration, model card
├── src/
│ ├── config.py # Single source of truth for all hyperparameters
│ ├── dataset_utils.py # Dataset loading, formatting, filtering
│ └── evaluation_utils.py # ROUGE-L, Exact Match, MMLU evaluation
└── notebooks/
├── 01_dataset_preparation.py # Load, format, filter, save dataset
├── 02_baseline_evaluation.py # Evaluate base model; establish MMLU baseline
├── 03_fine_tuning.py # QLoRA fine-tuning with W&B logging
├── 04_evaluation_comparison.py # Post-FT evaluation + forgetting check
└── 05_publish_to_hub.py # Merge adapter, push to Hugging Face Hub
pip install -r requirements.txt # Run on GPU (Colab T4 or local with ≥12 GB VRAM) python notebooks/01_dataset_preparation.py python notebooks/02_baseline_evaluation.py python notebooks/03_fine_tuning.py # ~2–3 hours on T4 python notebooks/04_evaluation_comparison.py
All random seeds are fixed (seed=42). Results should be within ±0.5% of the
reported numbers on the same hardware (H100 80GB, CUDA 12.7).
Model (merged weights) and model card:
https://huggingface.co/samrat-kar/qwen2.5-1.5b-sql-qlora
Training run logged to Weights & Biases:
QLoRA Fine-Tuning of Qwen2.5-1.5B — Training Curves & Metrics
Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient
Finetuning of Quantized LLMs. NeurIPS 2023.
https://arxiv.org/abs/2305.14314
Hu, E. J., et al. (2022). LoRA: Low-Rank Adaptation of Large Language Models.
ICLR 2022. https://arxiv.org/abs/2106.09685
Qwen Team. (2024). Qwen2.5 Technical Report.
https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct
b-mc2. (2023). sql-create-context dataset.
https://huggingface.co/datasets/b-mc2/sql-create-context
Hendrycks, D., et al. (2021). Measuring Massive Multitask Language Understanding.
ICLR 2021. https://arxiv.org/abs/2009.03300