
Standard AI assistants are designed to reduce friction. However, in deep learning and strategic decision-making, friction is a requirement. This publication introduces the Cognitive Challenge Agent Prototype (CCA-Prototype), a system that intentionally creates intellectual resistance. By integrating state-based orchestration (LangGraph) with semantic mirroring (ChromaDB), the CCA forces users to undergo "Cognitive Restructuring", the process of revising existing mental models through adversarial inquiry and lateral expansion.
Most LLMs suffer from "User Alignment Bias", where the model agrees with the user to provide a pleasant experience.
Learning Mechanism: For the user, this creates a "Fluency Illusion" – the mistaken belief that they understand a topic because an AI is confirming their thoughts. The CCA breaks this by adopting an Adversarial Stance, forcing the user into Active Recall and Logical Defense.
The CCA is not a simple chatbot; it is a State Machine. I utilized LangGraph because it allows for "Cycles" – enabling the agent to search its memory, reflect on the user's past statements, and fact-check itself before responding.
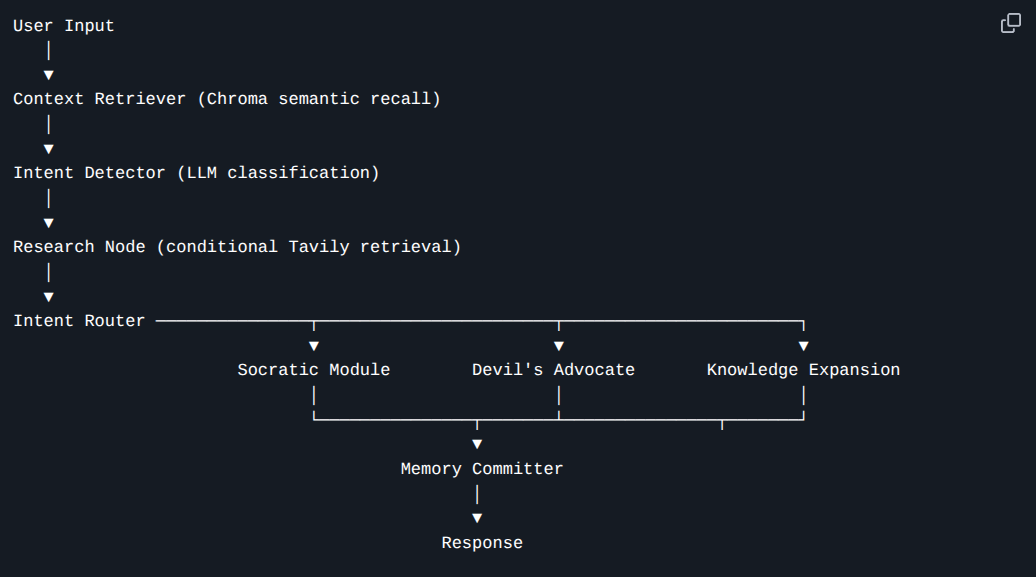
System Architecture Diagram showing the flow from Intent Detection to Memory Retrieval to Cognitive Modules
To maximize the learning effect, the system routes user input through three distinct cognitive engines:
Instead of answering questions, this module identifies "Load-Bearing Assumptions."


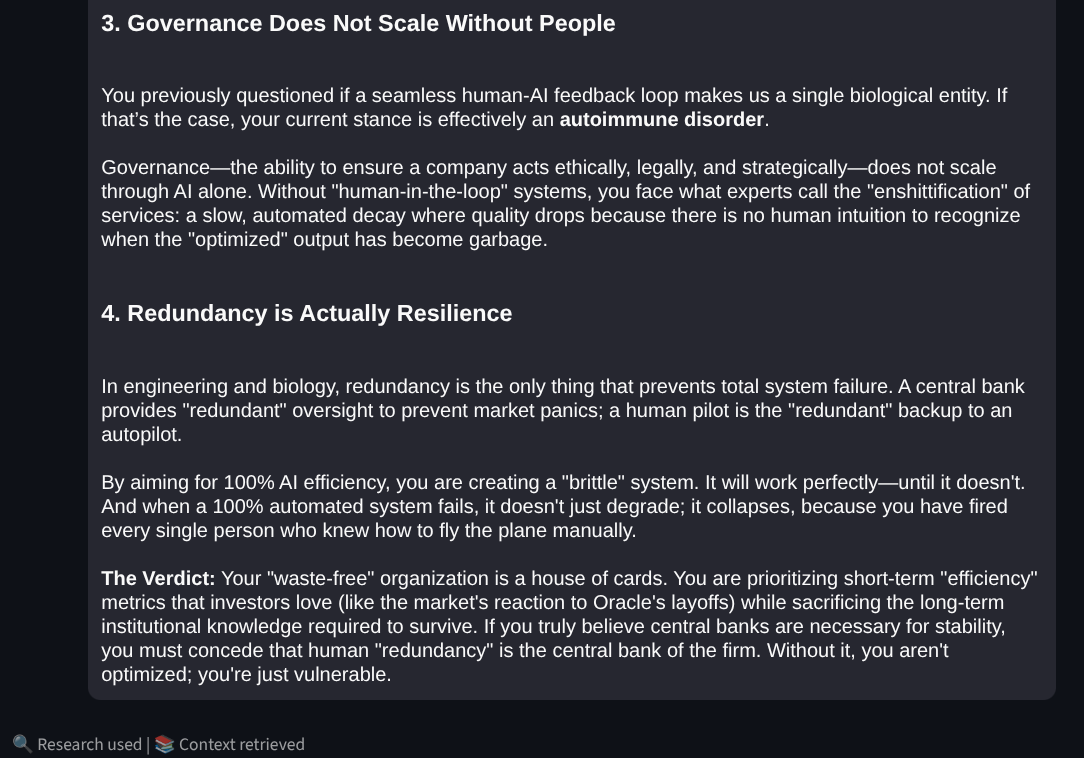
The Socratic Reasoner identifies the 'Load-Bearing Assumption' of a user's efficiency model, forcing a shift from linear optimization to systemic resilience thinking.
This module uses "Pre-mortem" logic to assume the user's idea has already failed.
This module identifies Structural Isomorphisms, patterns that exist in unrelated fields.





The Knowledge Expansion Engine performing a 'Lateral Leap,' mapping the technical challenges of decentralized AI security onto the biological framework of Somatic Hypermutation.
A "Solid Foundation" requires a system that remembers not just what was said, but how the user's mind is evolving.
I chose ChromaDB for its stability in local-first environments. Every thought is embedded into a 3072-dimensional vector space.
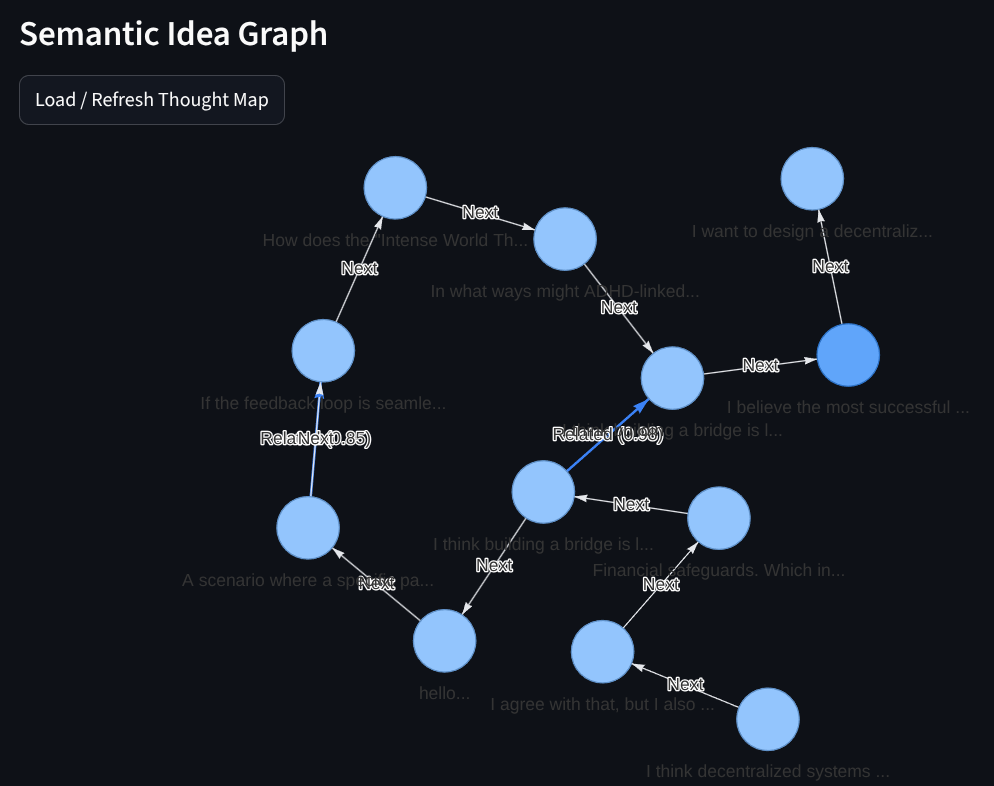
Screenshot of the Streamlit "Thought Map" showing semantic clusters and chronological paths
The "Learning Mechanism" of the CCA Prototype is rooted in Desirable Difficulty. By making the interaction harder, the retention and depth of understanding become higher. I have moved the AI from a "Search Engine" to a "Gymnasium for the Mind".
GitHub Repository:
CCA-Prototype
Developer Notes: Built during a multi-stage "Harness Engineering" sprint to solve for AI sycophancy.
One of the key learning moments during the development of this prototype was the pivot from Qdrant to ChromaDB for the semantic memory layer.
While Qdrant is an excellent enterprise-grade vector database, I found that its 'Local Mode' (disk-based storage) introduced significant API instability and library version conflicts in certain Python environments, specifically regarding the fastembed requirements and AttributeError inconsistencies during high-frequency read/writes.
To ensure a 'Solid Foundation' for local-first users, I switched to ChromaDB. The 'Learning Effect' here is critical: for a cognitive tool designed to be a personal ecosystem, reproducibility and zero-config stability are more important than distributed scaling capabilities. ChromaDB provided a much more robust handling of metadata (which I use to track user intent) and allowed me to focus on the complex Socratic logic rather than troubleshooting the database driver.
If you are building agentic workflows that require persistent local memory, I highly recommend prioritizing 'Environment-Tool Fit' over 'Peak Performance Specs' during the MVP phase.
