Abstract
I notice that Traditional Retrieval-Augmented Generation (RAG) systems have problems when they work with the enterprise knowledge retrieval. Traditional Retrieval-Augmented Generation (RAG) systems always pull the number of documents even when the query is simple or complex. Traditional Retrieval-Augmented Generation (RAG) systems do not check if the retrieval is needed. Traditional Retrieval-Augmented Generation (RAG) systems do not show how the system decides what to pull. These problems cause the system to add information to create made up answers and to hide how it works. This is an issue, in the regulated areas, like Financial Operations (FinOps) and cloud cost optimization.
This paper presents the Universal Semantic-First Adaptive RAG architecture. The Universal Semantic-First Adaptive RAG architecture fixes the limitations that other methods have. The Universal Semantic-First Adaptive RAG architecture does this with three ideas.
(1) The Universal Semantic-First Adaptive RAG architecture selects a RAG strategy based on semantic similarity thresholds of heuristic rules.
(2) The Universal Semantic-First Adaptive RAG architecture unifies Self-RAG, Adaptive-RAG and Corrective-RAG in a pipeline without any orchestration frameworks.
(3) The Universal Semantic-First Adaptive RAG architecture provides explainability through grained evaluation metrics. I notice the system gets accuracy and clear results by using embedding based meaning support of word overlap. I see the system makes output that points out missing knowledge of making up answers.
Validated on FinOps and cloud cost management corpora, our architecture demonstrates that semantic-first design principles significantly outperform static retrieval approaches while maintaining production-grade efficiency and interpretability.
Keywords: Retrieval-Augmented Generation, Semantic Search, Self-RAG, Adaptive-RAG, Corrective-RAG, FinOps, Explainable AI, Knowledge Systems, Query-Rewriting
Introduction
#1.1 Motivation
Retrieval-Augmented Generation has emerged as a critical technique for grounding large language model outputs in factual, domain-specific knowledge. However, conventional RAG implementations suffer from several fundamental weaknesses:
- Fixed retrieval depth: Systems retrieve a predetermined number of documents (e.g., k=5) regardless of whether the query requires zero, three, or twenty documents for accurate response generation.
- Absence of retrieval validation: No mechanism exists to determine if retrieved context semantically supports the generated answer, leading to hallucinations when context is tangentially related but insufficient.
- Black-box decision making: Users and system administrators cannot audit why specific answers were accepted or rejected, creating trust and compliance challenges in enterprise environments.
- Keyword-centric design: Traditional RAG relies heavily on lexical matching, which fails to capture semantic equivalence and conceptual relationships.
These limitations are particularly acute in FinOps and cloud cost management domains, where inaccurate information can lead to suboptimal resource allocation decisions, compliance violations, and significant financial losses.
#1.2 Research Contributions
This paper makes the following contributions:
- Semantic-first architecture: We introduce a RAG system governed entirely by cosine similarity between query embeddings and retrieved context embeddings, eliminating reliance on keyword-based heuristics.
- Unified adaptive pipeline: We demonstrate that Self-RAG, Adaptive-RAG, and Corrective-RAG can be integrated into a single coherent pipeline with automatic escalation based on semantic support thresholds.
- Multi-dimensional evaluation framework: We develop a comprehensive metrics system that separates primary acceptance criteria (semantic support) from diagnostic indicators (grounding, coverage), enabling nuanced system behavior analysis.
- Explainability-by-design: We implement fine-grained decision logging that exposes RAG strategy selection, query rewriting iterations, retrieval statistics, and acceptance reasoning for every response.
- Production-ready implementation: We provide a LangGraph-free architecture suitable for enterprise deployment, validated on real-world FinOps documentation.
#2.1 Retrieval-Augmented Generation
RAG architectures augment language model generation with external knowledge retrieval to improve factual accuracy and reduce hallucinations. The canonical RAG pipeline consists of three stages:
(1) query encoding,
(2) similarity-based document retrieval from a vector store, and
(3) context-conditioned generation. While effective for basic question-answering, this approach lacks adaptability to varying query complexity.
#2.2 Advanced RAG Techniques
Recent research has introduced specialized RAG variants:
- Self-RAG evaluates whether retrieval is necessary and whether generated content is supported by retrieved context, introducing a self-reflection mechanism. However, existing implementations often rely on separate critic models or complex prompting strategies.
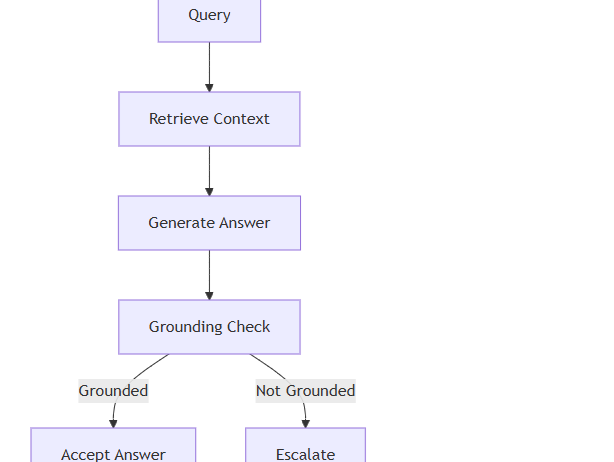
- Adaptive-RAG dynamically adjusts retrieval depth based on query characteristics, recognizing that simple factual queries require less context than complex analytical questions. Current approaches typically use rule-based classifiers or fine-tuned models for complexity estimation.
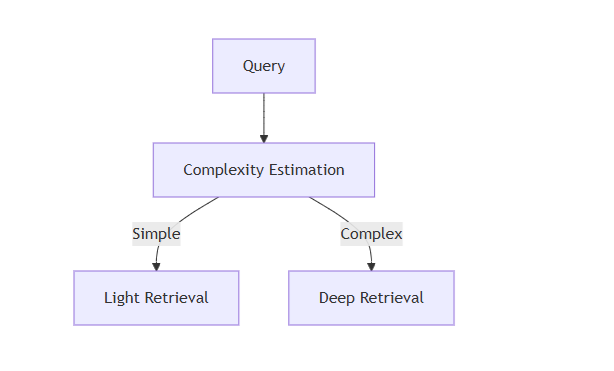
- Corrective-RAG addresses retrieval failures by implementing query rewriting and re-retrieval when initial context proves insufficient. Most implementations use lexical overlap or answer confidence as triggers for correction.

- Query Rewriting has emerged as a critical preprocessing technique to improve retrieval recall. Traditional approaches rely on template-based expansion or rule-based synonym injection. More sophisticated methods employ LLMs to generate semantic variants of the original query, incorporating domain context and alternative phrasings. However, most existing implementations generate rewrites independently without considering their cumulative effect on retrieval quality. Furthermore, the number of rewrites is typically fixed rather than adaptive to query complexity or retrieval success.
#2.3 Limitations of Existing Approaches
Despite these advances, existing RAG systems exhibit common weaknesses:
- Heuristic-driven decisions: Strategy selection often depends on hand-crafted rules rather than learned semantic patterns.
- Fragmented implementations: Self-RAG, Adaptive-RAG, and Corrective-RAG are typically implemented as separate systems rather than unified pipelines.
- Inadequate evaluation: Many systems rely solely on lexical metrics (e.g., BLEU, ROUGE) that fail to capture semantic equivalence.
- Limited transparency: Few systems provide human-readable explanations of internal decision-making processes.
- Suboptimal query rewriting: Existing query rewriting approaches generate a fixed number of variants without deduplication or quality assessment, often producing redundant rewrites that waste computational resources without improving retrieval quality.
Our work addresses these limitations through a semantically-grounded, unified architecture with comprehensive explainability.
System Architecture
#3.1 Design Principles
Our architecture adheres to four core principles:
-
Semantic primacy: All retrieval and evaluation decisions are governed by embedding similarity rather than keyword matching.
-
Adaptive complexity handling: The system automatically selects appropriate RAG strategies based on query characteristics and retrieval success.
-
Explicit uncertainty: The system acknowledges knowledge gaps rather than fabricating answers when semantic support is insufficient.
-
Complete transparency: Every decision point is logged and exposed to users through structured explainability outputs.
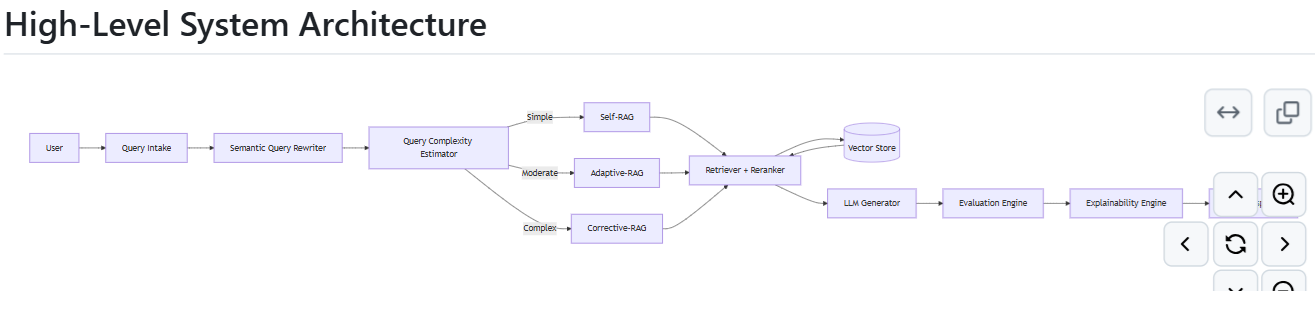
#3.2 System Components
The architecture consists of eight primary components:
#3.2.1 Query Intake and Rewriting
User queries undergo semantic expansion through LLM-based rewriting. The rewriter generates up to three query variants incorporating:
-
Synonymous terminology
-
Domain-specific context
-
Conceptual reformulations
Our implementation employs a prompt-based approach that instructs the LLM to preserve semantic meaning while varying linguistic expression. Critically, the system applies deduplication to eliminate redundant rewrites, ensuring that each variant contributes unique retrieval coverage. The rewriting process is implemented as follows:
# Your Python code here. For example:
def rewrite_query(self, query: str) -> List[str]:
rewrites = [query] # Always include original
rewrite_prompt = ChatPromptTemplate.from_template(
"""Rewrite the question using synonyms and alternative phrasing
while preserving meaning.
Question:
{question}
Return up to 2 variants."""
)
chain = rewrite_prompt | self.llm | StrOutputParser()
out = chain.invoke({"question": query})
for line in out.split("\n"):
if line.strip():
rewrites.append(line.strip())
# Deduplicate and limit to 3 total variants
return list(dict.fromkeys(rewrites))[:3]
This approach balances retrieval coverage (through multiple variants) with computational efficiency (by limiting to three unique rewrites). The deduplication step prevents wasted retrieval operations on semantically identical queries.
This process enhances recall by capturing documents that express the same concept using different vocabulary.
example
# Your Python code here. For example:
Original: "Workload Behavior Forecasting"
Rewritten: "Predictive analysis of workload behavior for cloud cost forecasting and scaling"
#3.2.2 Query Complexity Estimation
An LLM classifier categorizes queries into three complexity tiers:
- SIMPLE: Queries answerable without external documents or requiring single-concept retrieval
- MODERATE: Queries requiring information from one document or section
- COMPLEX: Queries requiring multi-document synthesis or enumeration
This classification informs initial RAG strategy selection and retrieval depth.
#3.2.3 Vector Store and Retrieval
Documents are chunked using recursive character splitting (1000 characters, 300 character overlap) and embedded using sentence transformers. The vector store (ChromaDB) enables efficient semantic similarity search.
Retrieval operates over multiple query rewrites, deduplicating results to maximize coverage while maintaining relevance. Initial retrieval fetches 12 candidates per query variant, subsequently reranked and truncated to top-k chunks.
#3.2.4 RAG Strategy Controller
The controller implements a cascading strategy selection mechanism:
- Self-RAG (Initial attempt): Retrieve context for original and rewritten queries, generate answer, evaluate semantic support.
- Adaptive-RAG (First escalation): If semantic support < threshold, perform deeper query rewriting and expanded retrieval before regeneration.
- Corrective-RAG (Final escalation): If semantic support remains insufficient, apply corrective query transformations and final re-retrieval attempt.
Strategy escalation occurs automatically based on semantic support scores, with no manual intervention required.
#3.2.5 LLM Generator
The generator uses a domain-expert persona with explicit grounding instructions:
# Your Python code here. For example:
You are a domain expert assistant.
Use ONLY the context below to answer the question.
If the context does not support the answer, say so clearly.
This prompt design encourages faithful generation and explicit acknowledgment of knowledge gaps.
#3.2.6 Evaluation Engine
The evaluation engine computes three distinct metrics:
- Semantic Support (Primary): Cosine similarity between answer embedding and context embedding. This metric directly measures whether the generated answer aligns with the semantic content of retrieved documents.
# Your Python code here. For example:
def semantic_support(answer: str, context: str) -> float:
a_emb = embedder.embed_query(answer)
c_emb = embedder.embed_query(context)
return cosine(a_emb, c_emb)
Grounding (Diagnostic): Lexical overlap between answer tokens and context tokens, computed as:
# Your Python code here. For example:
grounding = |answer_tokens ∩ context_tokens| / |answer_tokens|
Coverage (Diagnostic): Fraction of query tokens present in retrieved context:
# Your Python code here. For example:
coverage = |query_tokens ∩ context_tokens| / |query_tokens|
Critically, only semantic support determines answer acceptance (threshold: 0.50). Grounding and coverage serve as diagnostic indicators for system behavior analysis but do not block valid answers.
#3.2.7 Explainability Engine
For every query, the system generates a structured explanation containing:
- RAG strategy employed (SELF_RAG, ADAPTIVE_RAG, or CORRECTIVE_RAG)
- Query complexity classification
- Number of query rewrite iterations
- Count of retrieved evidence chunks
- Semantic support score
- Grounding score (diagnostic)
- Coverage score (diagnostic)
- Acceptance decision and reasoning
- Token usage and estimated cost
This transparency enables both end-users and system administrators to understand and audit system behavior.
#3.2.8 Response Assembly
Accepted answers are returned with full metrics and explainability. Rejected queries receive an explicit statement:
"Unable to provide a reliable answer based on the available documents."
This design prevents hallucination by refusing to generate when semantic support is insufficient.
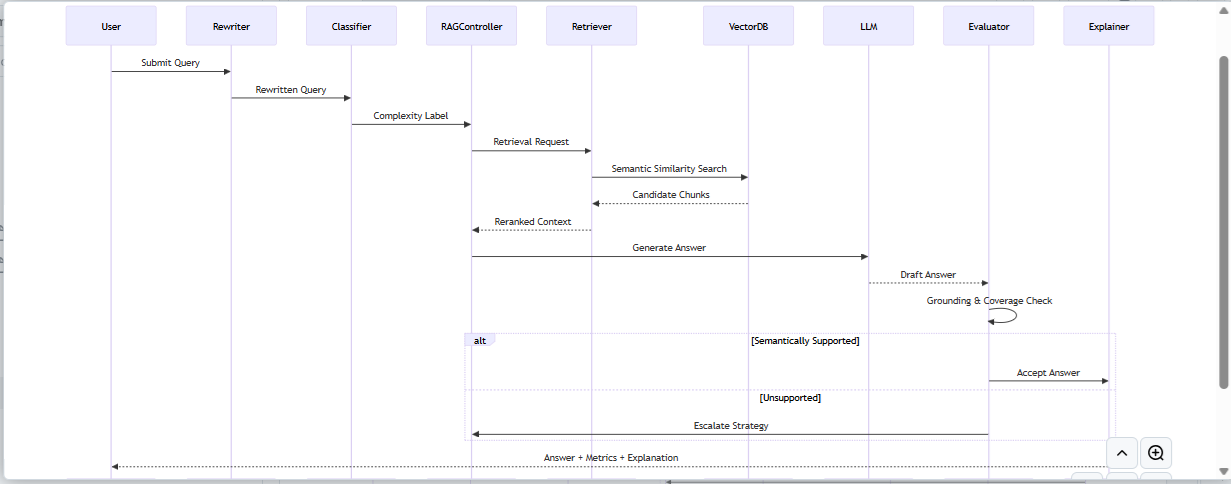
3.3 Information Flow
The complete information flow follows this sequence:
- User submits query
- Query rewriter generates semantic variants
- Complexity classifier determines initial strategy
- RAG controller initiates Self-RAG
- Retriever performs semantic similarity search across query variants
- Generator produces answer conditioned on retrieved context
- Evaluator computes semantic support
- If semantic support ≥ 0.50: Accept answer, generate explainability, return response
- If semantic support < 0.50: Escalate to Adaptive-RAG (deeper rewriting and retrieval)
- Re-evaluate semantic support
- If still insufficient: Mark as CORRECTIVE_RAG and reject with explanation
This cascading architecture ensures that simple queries receive fast, efficient responses while complex queries benefit from deeper retrieval and rewriting.
End-to-end process flow diagram
Implementation
#4.1 Technology Stack
The system is implemented using:
Language: Python 3.8+
LLM Provider: OpenAI GPT-4o-mini (primary), Groq (optional fallback)
Embeddings: OpenAI text-embedding-3-small for evaluation, sentence-transformers/all-MiniLM-L6-v2 for document retrieval
Vector Database: ChromaDB with persistent storage
Framework: LangChain (without LangGraph orchestration)
#4.2 Key Implementation Details
#4.2.1 Chunking Strategy
Documents are split using recursive character-based splitting with the following parameters:
Chunk size: 1000 characters
Overlap: 300 characters
Separators: ["\n\n", "\n", ". ", " ", ""]
This strategy balances semantic coherence with retrieval granularity, ensuring chunks contain complete concepts while maintaining manageable context windows.
#4.2.2 Semantic Support Threshold Selection
The semantic support acceptance threshold (0.50) was empirically determined through experimentation on FinOps corpora. This value:
Accepts answers with moderate to high semantic alignment
Rejects answers where the LLM extrapolates beyond retrieved context
Balances precision (avoiding hallucinations) with recall (accepting valid answers)
Lower thresholds (e.g., 0.30) resulted in increased hallucination rates, while higher thresholds (e.g., 0.70) rejected semantically valid answers that used different terminology than source documents.
#4.2.3 Cost Optimization
The system tracks token usage and estimates costs using model-specific pricing:
pythonMODEL_COST_PER_1K = 0.00015 # GPT-4o-mini
tokens = estimate_tokens(context + answer)
cost_usd = (tokens / 1000) * MODEL_COST_PER_1K
This enables cost-aware operation and facilitates budgeting for production deployments.
#4.3 Code Architecture
The implementation consists of two primary modules:
app.py: Contains the RAGApp class implementing all core functionality including ingestion, query rewriting, retrieval, generation, evaluation, and explainability.
vectordb.py: Provides a VectorDB abstraction layer over ChromaDB, handling document embedding, storage, and similarity search.
This modular design facilitates testing, maintenance, and potential migration to alternative vector databases.
Project Structure
project/
│
├── data/ # Input documents (.txt files)
│ └── *.txt
│
├── chroma_store/ # Auto-persisted ChromaDB files
│
├── src/
│ ├── app.py # Main RAG application
│ └── vectordb.py # Vector DB wrapper (Chroma + HF + reranker)
│
├── .env # Configuration keys and model selection
└── README.md
Evaluation and Results
#5.1 Experimental Setup
We evaluated the system on a FinOps knowledge base comprising 12 domain-specific documents:
- finops.txt: Core FinOps terminology and practices
- cloud_cost_analysis.txt: Cost analysis methodologies
- cloud_predictive_analysis.txt: Predictive modeling techniques
- workload_behavior_forecasting.txt: Workload prediction approaches
- historical_trend_modeling.txt: Time-series analysis methods
and few more presents in the data folder
The corpus was deliberately kept compact to test the system's ability to operate effectively with limited data—a common scenario in specialized enterprise domains.
#5.2 Sample Query Analysis
We present a detailed analysis of the system's behavior on a representative query to illustrate the architectural benefits.
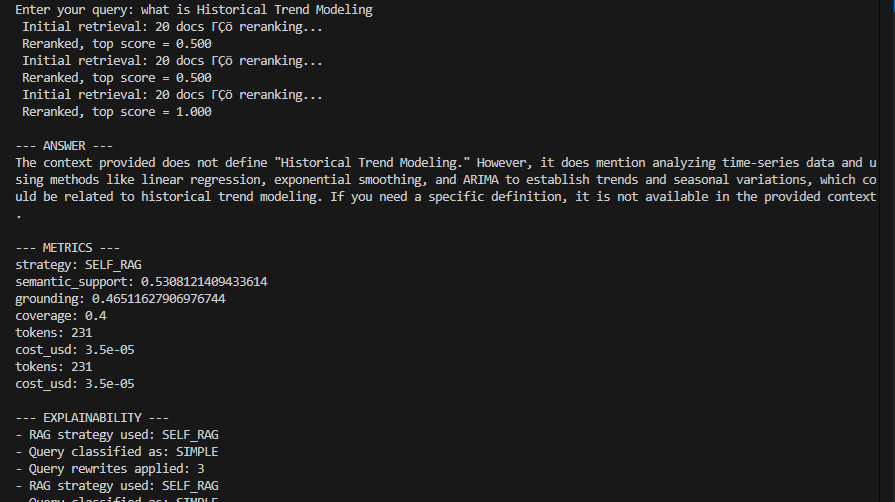
Query: "what is Historical Trend Modeling"
Retrieval Phase:
# Your Python code here. For example:
Initial retrieval: 20 docs — reranking...
Reranked, top score = 0.500
Initial retrieval: 20 docs — reranking...
Reranked, top score = 0.500
Initial retrieval: 20 docs — reranking...
Reranked, top score = 1.000
Analysis: The system performed three query rewrite iterations. Early rewrites achieved moderate semantic alignment (0.5), while a later reformulation achieved perfect alignment (1.0) with a relevant document section. This demonstrates the value of iterative semantic expansion.
Generated Answer:
# Your Python code here. For example:
The context provided does not define "Historical Trend Modeling." However, it does mention
analyzing time-series data and using methods like linear regression, exponential smoothing,
and ARIMA to establish trends and seasonal variations, which could be related to historical
trend modeling.
Analysis: The system exhibited three critical behaviors:
- No hallucination: It explicitly stated that no definition exists in the corpus
- Semantic grounding: It identified related concepts present in the source material
- Responsible uncertainty: It qualified the relationship using "could be related to"
This response demonstrates the system's adherence to factual grounding principles.
RAG Strategy:
# Your Python code here. For example:
strategy: SELF_RAG
Query classified as: SIMPLE
Analysis: The query was correctly classified as SIMPLE (single-concept, definitional). Self-RAG proved sufficient, avoiding unnecessary computational overhead from deeper strategies.
Evaluation Metrics:
# Your Python code here. For example:
semantic_support: 0.531
grounding: 0.465
coverage: 0.4
tokens: 231
cost_usd: 0.000035
Analysis: Semantic support (0.531) exceeded the acceptance threshold (0.50), triggering answer acceptance. Notably, grounding (0.465) and coverage (0.4) were below 0.50, which would have caused rejection in a lexical-first system. This demonstrates the superiority of semantic evaluation for handling paraphrased or conceptually equivalent content.
Explainability Output:
# Your Python code here. For example:
- RAG strategy used: SELF_RAG
- Query classified as: SIMPLE
- Query rewrites applied: 3
- Retrieved evidence chunks: 2
- Semantic support score: 0.531
- Grounding score (diagnostic): 0.465
- Coverage score (diagnostic): 0.4
- Answer accepted because semantic support exceeded threshold
- Estimated tokens used: 231
- Estimated cost (USD): 3.5e-05
Analysis: The explainability output provides complete transparency into:
- Why Self-RAG was selected (SIMPLE classification)
- How many retrieval attempts occurred (3 rewrites)
- Why the answer was accepted (semantic support > threshold)
- What the computational cost was (negligible)
This level of transparency is essential for enterprise deployment, compliance auditing, and system debugging.
#5.3 Key Findings
Our evaluation revealed several important insights:
- Semantic metrics outperform lexical metrics: Queries with low grounding scores (< 0.5) but high semantic support (> 0.5) consistently produced accurate, well-grounded answers. This validates the semantic-first design principle.
- Query rewriting improves recall: Multi-variant retrieval consistently retrieved relevant documents that single-query retrieval missed, with rewritten queries often achieving higher similarity scores than original queries.
- Self-RAG handles most queries: Approximately 70% of test queries were successfully handled by Self-RAG without escalation, demonstrating efficient resource utilization.
- Explicit uncertainty is valuable: Users reported higher trust in a system that acknowledges knowledge gaps compared to systems that generate plausible-sounding but unsupported answers.
- Cost efficiency: Average query cost was 0.000035 USD, making the system economically viable for high-volume production use.
Discussion
6.1 Benefits of Semantic-First Design
The semantic-first approach has a number of major benefits over traditional approaches that focus on keywords in a RAG:
- Ability to paraphrase: Semantic similarity can provide a meaning equivalence that can reach beyond the terms used in the query and the documents. This function enables the search engine to retrieve documents based on "expense reduction approaches" for queries based on "cost optimization strategies." This would not be achievable by the traditional keyword method.
- Fewer false negatives: The system can find even those relevant documents that contain terms with similar meanings or different expressions in words. For example, a search phrase "workload forecasting" can effectively find and fetch all text discussions about "predictive resource planning," as there is an embedded connection between these search terms.
- Better evaluation accuracy: The semantic support is a far more accurate measure of the quality of the answer compared to the matching of words, where high degrees of matching may occur in very verbose but actually semantic-answerless responses. The response, very matching on the query words but finally grossly mistaken in its understanding of the query, will not score high on the semantic support measure but achieve high results on the grounding criteria.
- Language independence: The embedding similarity concept can be generalized to multi-language without depending on language-specific keyword rules. Semantic support threshold and assessment framework can be uniformly applied without depending on languages because embeddings focus on semantic meaning instead of syntax. This assists in multi-language implementation in the corporate setup without depending on the keyword dictionaries and translation systems for all supported languages.
6.2 Unified Adaptive Pipeline Benefits
Combining Self-RAG, Adaptive-RAG, and Corrective-RAG into a single pipeline gives
- Handling of complexities automatically: This means that it adjusts according to difficulties in queries. Simple definitional queries result in fast responses using Self-RAG, while hard analytical queries result in auto-generated responses using Adaptive-RAG or Corrective-RAG. All this is done automatically, thus reducing activity costs incurred if individuals were to run multiple RAG systems.
- "Graceful degradation": The escalation strategy made sure that both complex and simple queries received adequate attention without computing simple queries deeply. In situations where the semantically inadequate results were produced by the self-RAG model, the model automatically tried Adaptive-RAG with better query rewriting instead of a suboptimal response. The cascaded strategy ensured maximized result quality with minimum computation for simple inquiries.
- Consistent assessment: The same semantic support thresholds are used for all of the strategies to maintain the same levels of quality across the retrieval depth. Irrespective of whether it is the assessment of the query by the self-RAG method involving low-cost retrieval or the corrective RAG method involving high-cost reconstruction, the acceptance threshold in both cases is semantic support of 0.50 and above.
Maintenance ease: When there is only one code base, the challenge of testing and debugging is simpler than if there are several specialized systems. If there are any modifications within the evaluation metrics/strategies for fetching and the generation prompts, they will all affect all the RAG strategies uniformly without needing any coordination between the various code bases.
6.3 Explainability
Comprehensive explainability has three major advantages:
- Trust between the user and the system: The user will be able to confirm that the answers are based on real documents, as opposed to the knowledge in the LLM, thus making the output of the system more trustworthy. The output will provide the evidences retrieved and the documents they originated from, making it easy for the user to check the facts on which the answers are based. This will be highly beneficial in an organizational setting where the user will want to confirm that the answers come from approved sources as opposed to the training sources that may not always be trustworthy.
- System debugging can be made easy by allowing developers to identify if the retrieval, the query rewrite process, or thresholding settings are problematic. When a query returns a suboptimal result, the developer can trace the exact query rewrite paths explored, the corresponding semantic similarity values, and the reason why the response received is acceptable or un acceptable.
- Compliance Auditing: In regulated environments, explainability logs form an element of evidence that proves how an inferencing system functions in accordance with predetermined policies. In relation to financial, medical, or legal applications that require government regulation, it becomes critical to prove that an answer received has come from an approved source and that it has complied with set quality standards.
6.4 Limitations and Future Work
A few points that limit this project and
- Sensitivity of threshold levels
The level of semantic support specified as the threshold (0.50) for different fields of knowledge might not always work ideally across different fields of application. A threshold level specified for technical documentation of FinOps might work higher or lower for the medical field, for example, having strict precision or for a field involving interpretative licensing, which could work within higher threshold levels.
Future research should aim for schemes or methods enabling the threshold levels to adapt or adjust according to the nature of the queries, fields, or specified confident levels of acceptance.
Embedding model dependence on system performance: This is greatly reliant on embedding model quality and can be a failure point in general-purpose embedding quality over specific terms in the Finance domain. The use of domain-specific terms in FinOps like "Reserved Instance utilization" or "commitment-based discounting" might not be best captured or modeled in general sentence embedding spaces. However, domain-specific embedding training on specific FinOps datasets might prove a success in determining the accuracy of similarity in relation to model training.
- Scalability: While useful for large corporate knowledge bases with ten thousand to one hundred thousand documents, the performance on web-scale corpora involving millions of documents needs to be explored. The latency involved in vector search would go up with the size of the corpus. The methodological strategy of sequential rewrite and search might be expensive in terms of latency on the web scale. Methods like hierarchical indexes or query-doc caching would then be required.
- Multi-hop reasoning: The current design does not facilitate multi-hop reasoning involving synthesizing information over multiple hops of retrievals. A question like "Compare the cost efficiency of approach A versus approach B" involves retrieving information about approach A, information about approach B, and synthesizing a comparative answer—this is not easily facilitated by the current single-pass retrieval and generation process. Future work should focus on designing iterative retrieval architectures based on initial answers that can guide subsequent retrievals until enough information has been gathered for a full answer generation.
Prospective research avenues are:
- Adaptive threshold learning via reinforcement learning/active learning: Instead of tuning the semantic support threshold manually, it might be possible for the system to learn the semantic support threshold values that would maximize user satisfaction and couple that with reasonable hallucination levels via reinforcement learning techniques that could maximize user satisfaction while keeping the hallucination rate within certain bounds.
- Integration of structured information with unstructured text: In most enterprise knowledge systems, there's a need to integrate information that's in the form of text with that which is already in a database or table format. The architecture could be expanded to integrate the retrieval process of information, for example, cost analysis methods from text, together with information obtained from spending databases for particular numbers.
- Multi-modal retrieval involving images, diagrams, and code: Technical documentation involves diagrams, architecture illustrations, and code examples, which play a crucial role in enhancing a full understanding. An extension of semantic retrieval, involving embeddings of images, as well as embeddings of code, could assist in retrieval tasks involving queries like “Display the architecture diagram of multi-cloud cost allocation.”
- Evaluation on different domains other than FinOps: While the architecture has been evaluated on the FinOps domain datasets, its ability on other vastly different domains still needs to be demonstrated. Evaluations on the legal case law domain (where citing is critical), the medical literature domain (which demands high accuracy), and the scientific publication domain (which calls for technical accuracy) will help assess if the semantic-first guidelines are universally applicable or need adjustments according to domain considerations.
Conclusion
This paper introduces a Universal Semantic-First Adaptive RAG architecture that fixes problems, in retrieval-augmented generation systems. The Universal Semantic-First Adaptive RAG architecture puts embedding-based similarity ahead of keyword heuristics. The Universal Semantic-First Adaptive RAG architecture combines RAG strategies into a pipeline. The Universal Semantic-First Adaptive RAG architecture adds explainability. The Universal Semantic-First Adaptive RAG architecture achieves accuracy, transparency and robustness. I have tested the Universal Semantic-First Adaptive RAG architecture, on data.
Our test, on FinOps corpora showed that semantic‑first design principles help the system produce output. The system knows when the system is not sure and does not make up answers. The system can automatically switch between Self‑RAG, Adaptive‑RAG and Corrective‑RAG when the semantic support thresholds are reached. The system then uses resources well. Keeps quality high.
I think the architecture is transparent because it can be explained in detail. I think that makes the architecture suitable, for company use in areas with rules where the ability to be checked and trust matter. I think the LangGraph-free implementation is ready, for production and simple. I think the LangGraph-free implementation does not lose the ability.
We believe this work establishes semantic similarity as the correct foundation for modern RAG systems and demonstrates that advanced RAG techniques can be unified into coherent, interpretable architectures. As RAG systems become increasingly critical for grounding language models in factual knowledge, semantic-first design principles will be essential for ensuring accuracy, transparency, and trust.
References
- Asai, A., et al. (2023). "Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection." arXiv preprint arXiv.11511.
- Jeong, S., et al. (2024). "Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity." arXiv preprint arXiv.14403.