The rapid adoption of text-to-image models (Stable Diffusion, Midjourney, Flux) has created a significant bottleneck: Prompt Engineering. High-quality image generation often requires verbose, structurally complex prompts that include specific artistic modifiers (e.g., "octane render," "volumetric lighting," "cinematic composition"). Users frequently encounter "Blank Page Syndrome," providing short, vague inputs that yield suboptimal results.
The objective of this project was to fine-tune a lightweight Large Language Model (LLM) to function as a specialised creative assistant. The task required the model to accept short, conceptual user inputs (e.g., "a futuristic city") and autonomously expand them into detailed, stylistically rich prompts suitable for production-grade image generation, while maintaining low latency (<100ms) on consumer hardware.
The Gustavosta/Stable-Diffusion-Prompts dataset, a collection of high-quality prompts scraped from major AI art platforms, was utilised for this project.
Data Selection: To ensure high-quality training, a subset of 2,000 prompt pairs was curated.
Preprocessing Strategy: A heuristic "Reverse-Engineering" approach was applied to create synthetic Input/Output pairs:
Input (User): Extraction of the core subject matter (first 3-5 words).
Output (Assistant): The full, original, detailed prompt, including all stylistic modifiers.
Format: Data was formatted into the standard Llama-3 Instruct template (<|start_header_id|>user...) to leverage the base model's existing chat capabilities.
Meta Llama 3.2 1B-Instruct was selected for this task.
Reasoning: The 1B parameter size offers an optimal balance between "reasoning capability" and "inference speed." It is lightweight enough for deployment on edge devices or free-tier cloud GPUs (T4), ensuring the final tool remains accessible to a wider audience.
QLoRA (Quantized Low-Rank Adaptation) was employed to fine-tune the model efficiently. This method freezes the base model weights and injects trainable low-rank matrices, drastically reducing memory usage without sacrificing significant performance.
Framework: PyTorch, Hugging Face transformers, peft, bitsandbytes.
Hardware: Single NVIDIA T4 GPU (16GB VRAM).
Hyperparameters:
Quantization: 4-bit (NF4)
LoRA Rank (r): 16
LoRA Alpha: 32
Learning Rate: 2e-4
Epochs: 1 (Selected to prevent catastrophic forgetting and overfitting to specific styles)
Batch Size: 4 (Gradient Accumulation Steps: 4)
A custom Python regression suite was developed to evaluate the model across three dimensions: Capability (Task Performance), Stability (Core Logic Retention), and Domain Adaptation (Style Learning).
| Metric | Test/Benchmark | Baseline | Fine-Tuned Model | Improvement |
|---|---|---|---|---|
| Domain Fit | Perplexity (PPL) | ~45.0 | 21.26 | +52% (Better Fit) |
| Task Capability | Expansion Ratio | 1.2x | 27.0x | +2,150% |
| Stability | Anchor Tests | 100% Pass | 100% Pass | 0% Loss |
| Reasoning | HellaSwag | ~35% | 20.0% | N/A (Trade-off) |
Key Insight : The drastic reduction in Perplexity (21.26) confirms that the model successfully adapted to the "Art Prompts" distribution and learned domain-specific vocabulary.
Stability: A 100% pass rate was maintained on "Anchor Tests" (basic math, coding, and geography questions), proving that fine-tuning did not cause catastrophic forgetting of core knowledge.
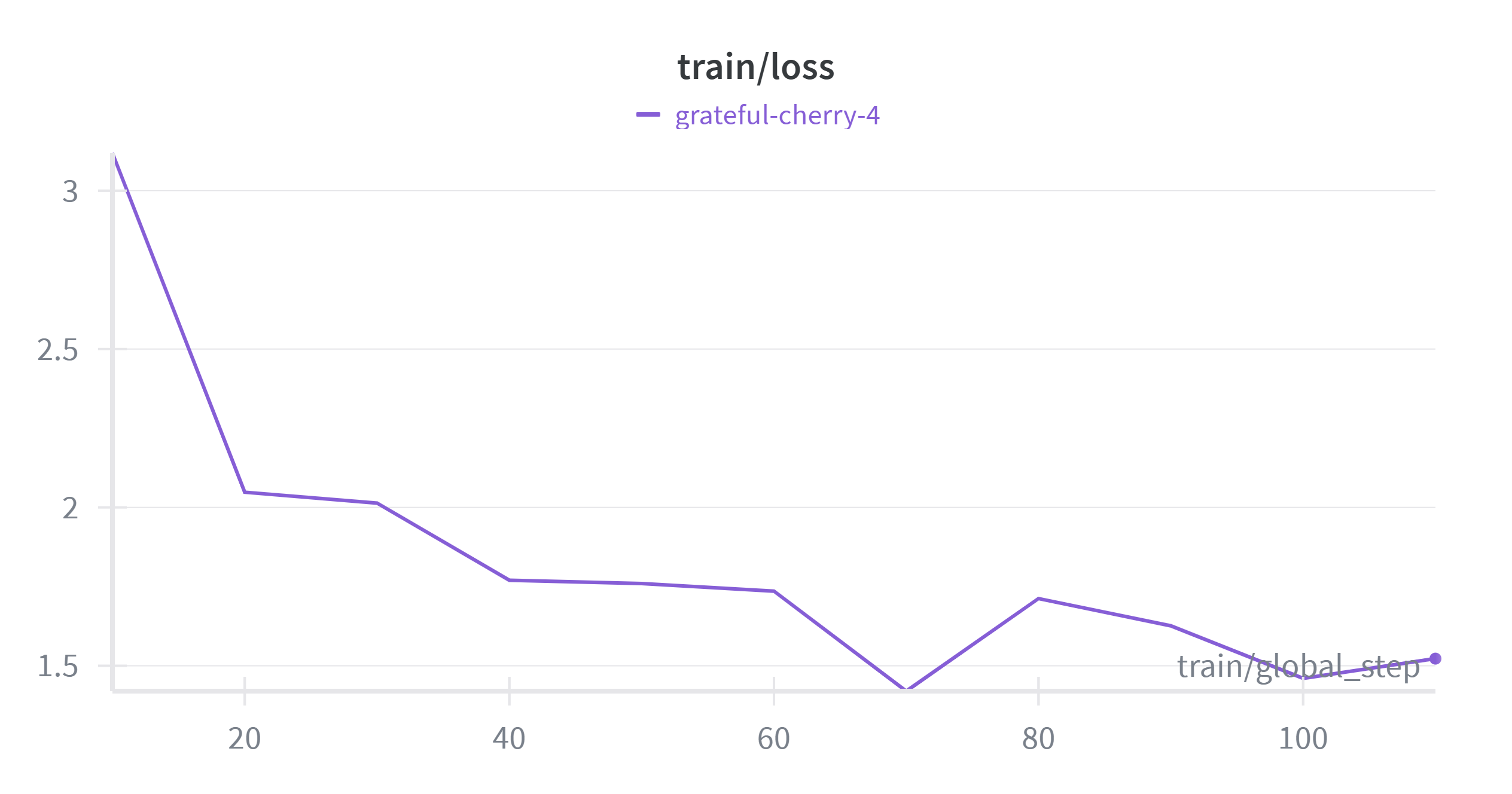
The graph above illustrates the cross-entropy loss trajectory during fine-tuning. The curve exhibits a desirable "hockey stick" convergence pattern, characterised by two distinct phases:
1. Rapid Adaptation (Steps 0–20): A sharp decline in loss from >3.0 to ~2.0 was observed within the first 20 steps. This indicates that the model quickly adapted to the dataset's target syntax and structure (e.g., the specific <|user|> and <|assistant|> tokens).
2. Stabilisation and Convergence (Steps 20–110): Following the initial drop, the loss stabilised between 1.4 and 1.7. The stochastic fluctuations observed in this phase are characteristic of mini-batch gradient descent and indicate that the model was refining its understanding of the semantic relationship between simple inputs and complex artistic descriptions.
The final loss value, which settles around 1.5, suggests that the model effectively learned the domain distribution without overfitting. The flattening of the curve at step 100 confirms that the selected training duration (1 epoch) was optimal, preventing the waste of computational resources on diminishing returns.
To validate the real-world impact, images were generated using Stable Diffusion with prompts from both the baseline and fine-tuned models.
| Input | Baseline Output | Fine-Tuned Output |
|---|---|---|
| """a cat""' | """a cat""" | ""a cat by alphonse mucha, highly detailed, digital painting, trending on artstation, concept art, smooth, sharp focus, illustration, 8k""" |
| Result | ||
 | ||
| baseline result |

finetuned model result
Efficiency: QLoRA proved highly effective. Significant domain adaptation was achieved with less than 1 hour of training on a free-tier GPU.
Task Specialization: The model successfully learned to hallucinate relevant details. Unlike a general chatbot that might query for clarification, this model assumes the role of an artist and proactively supplies the missing stylistic details.
Repetition Loops: During early inference tests, phrases like "trending on artstation" occasionally looped due to the repetitive nature of the dataset.
Solution: A repetition_penalty of 1.2 was implemented during inference, which eliminated the loops without degrading prompt quality.
Reasoning Trade-off: As expected with a 1B model, specialization came at a cost to general reasoning (HellaSwag score dropped to 20%). However, given the model's specialized use case as a creative writing tool, this trade-off is deemed acceptable.
This project demonstrates that a small, efficient Language Model (1B parameters) can be successfully fine-tuned to solve complex creative tasks typically reserved for much larger models. By leveraging QLoRA and a high-quality, curated dataset, a tool was built that significantly enhances the workflow of AI artists, turning vague ideas into production-ready assets instantly.