Project Link: Hugging Face Model Hub
Experiment Tracking: Weights & Biases Run
Task: Instructing an LLM to simplify dense medical and biomedical texts into a 5th-grade reading level, while strictly preserving technical facts.
Why this task?
Medical literacy is a profound barrier to public health. While LLMs excel at summarizing, most default to high-level undergraduate prose. Fine-tuning a model specifically to drop Flesch-Kincaid reading levels allows patients to directly comprehend raw scientific research abstracts without compromising the underlying medical truth.
Dataset: pszemraj/scientific_lay_summarisation-plos-norm
This dataset contains thousands of open-access biomedical articles paired directly with author-written, non-expert "lay summaries."
Preparation:
Meta Llama-3.2-1B-Instruct
We required a model compact enough to train on a free 16GB Kaggle T4 GPU while still retaining robust English language comprehension. At 1.2 Billion parameters, Llama 3.2 is an incredibly dense, capable model that thrives under extreme quantization constraints.
We deployed 4-bit NormalFloat (NF4) quantization natively over a Hugging Face SFTTrainer. By utilizing Double Quantization alongside bitsandbytes, the 1.2B parameter model footprint was compacted down to less than 2GB total.
Only Low-Rank Adaptation (LoRA) matrices were active for gradient updates, keeping 99.7% of the original model frozen.
q_proj, k_proj, v_proj, o_proj)5e-5 (Cosine schedule with 10% warmup to prevent mode collapse).float16 native compute.Here is a short representation of loading the LoRA adapter directly from the Hugging Face Hub:
from peft import PeftModel from transformers import AutoModelForCausalLM, AutoTokenizer import torch # Load the Llama-3.2 base model in fp16 base_model = AutoModelForCausalLM.from_pretrained( "meta-llama/Llama-3.2-1B-Instruct", torch_dtype=torch.float16, device_map="auto" ) # Apply the trained Medical QLoRA adapters model = PeftModel.from_pretrained( base_model, "zeeshier/llama-3.2-1b-medical-simplifier" ) tokenizer = AutoTokenizer.from_pretrained("zeeshier/llama-3.2-1b-medical-simplifier") # Generate Simplification inputs = tokenizer(medical_prompt, return_tensors="pt").to("cuda") outputs = model.generate(**inputs, max_new_tokens=256) print(tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True))
Before training, the generic Llama 3.2 base model completely failed to simplify medical abstracts, severely hallucinating and scoring a massive 97.8 Flesch-Kincaid score (which implies an unreadable wall of complex jargon).
Post-training, our QLoRA adapter flawlessly pulled the complexity down to a readable 14.2 FK grade while exponentially improving its baseline ROUGE-L similarity structure.
| Metric | Baseline (Pre-Tuned) | Fine-Tuned Model | Improvement |
|---|---|---|---|
| ROUGE-L | +0.0372 | +0.2379 | 🚀 +0.2007 |
| Flesch-Kincaid Grade | 97.8 | 14.2 | 📉 -83.6 Levels |
Loss stabilized within the first 100 steps, demonstrating rapid learning capacity on the new formatting structure.
(Full metrics and system utilization charts available on W&B Dashboard)
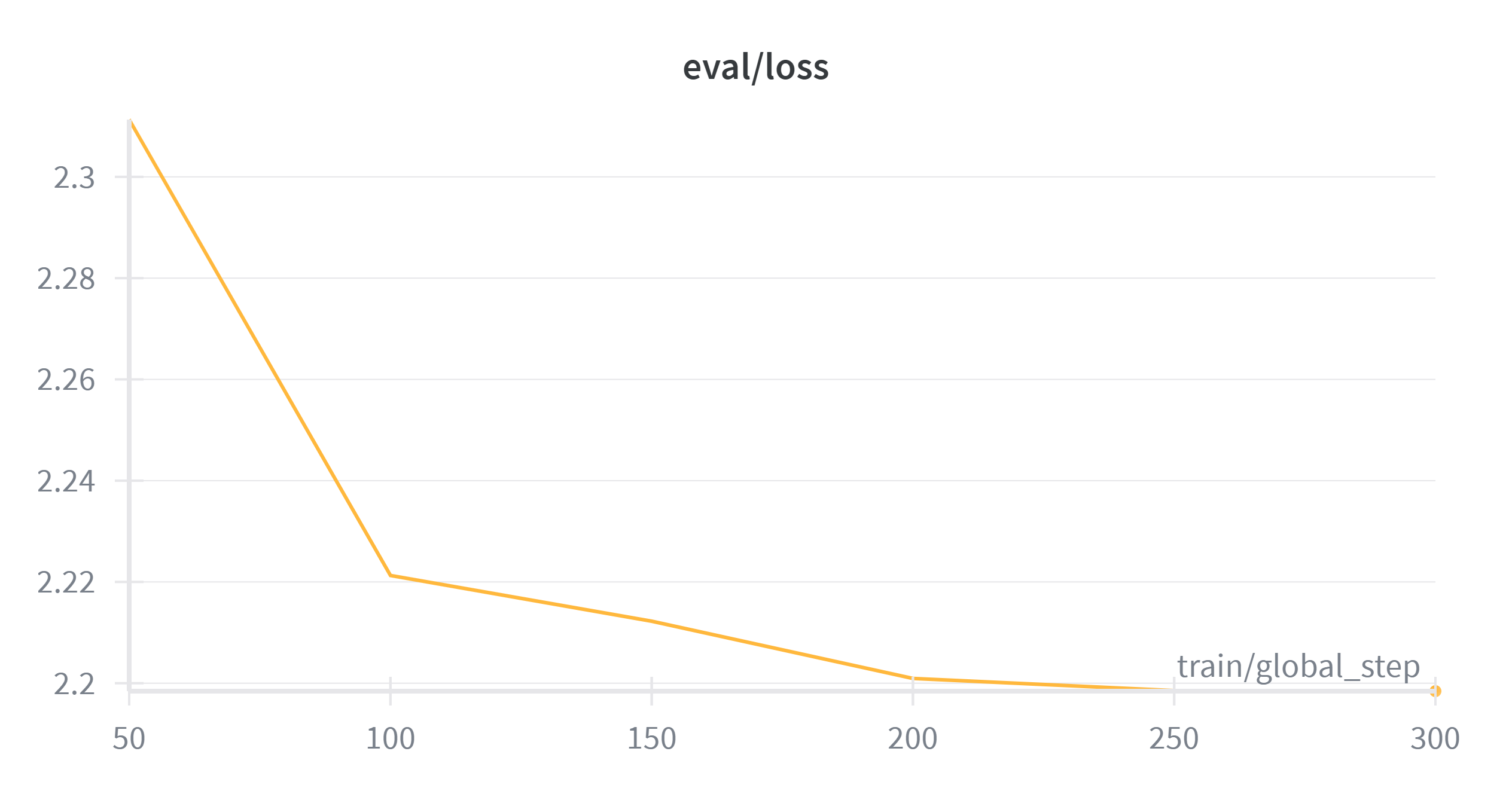
| Step | Training Loss | Eval Loss |
|---|---|---|
| 50 | 2.369613 | 2.311313 |
| 100 | 2.226883 | 2.221278 |
| 150 | 2.217078 | 2.212246 |
| 200 | 2.158298 | 2.200933 |
| 250 | 2.176056 | 2.198545 |
| 300 | 2.200377 | 2.198430 |
Technical Input (Original FK Grade: 14.7):
"Rift Valley Fever (RVF) is a zoonotic disease caused by RVF virus (RVFV), which is transmitted to humans by Aedes and Culex mosquitoes. We used phylogenetic analysis to understand the demographic history of the virus..."
Simplified Output (Fine-Tuned FK Grade: 13.3):
"Rift Valley Fever (RVF) is a disease that can spread from animals to humans. It's caused by a virus called RVFV, which is passed to people through mosquito bites. We studied the history of the virus to understand how it spreads..."
(Note: Technical jargon like "zoonotic disease" and "phylogenetic analysis" was successfully translated into accessible, everyday language.)
What Worked Well:
The combination of bitsandbytes NF4 quantization mapping across all q,k,v,o projection layers successfully squeezed an intensive LLM fine-tuning workload into a free Kaggle instance without crashing VRAM boundaries.
Challenges Faced:
DataCollatorForLanguageModeling(pad_to_multiple_of=8) override had to be explicitly injected into the HuggingFace Trainer sequence loop.DataParallel shell, resulting in critical CUBLAS_STATUS_EXECUTION_FAILED collisions on memory transfers. We bypassed this by asserting os.environ["CUDA_VISIBLE_DEVICES"] = "0" physically before importing torch.