The Financial RAG Assistant is a Retrieval-Augmented Generation (RAG) system designed to extract actionable insights from company financial reports. By combining ChromaDB for vector search and Groq-hosted LLMs for reasoning, the system allows users to upload PDF reports and interactively query them through either a command-line interface or a Streamlit-based web frontend. It efficiently bridges unstructured financial documents and structured insights, supporting analysts, investors, and researchers in rapid, context-aware decision-making.
Financial reports are among the most information-dense and technical documents, often containing hundreds of pages of detailed financial statements, footnotes, and market analysis. Extracting insights from these reports typically requires extensive domain expertise and time.
This project presents the Financial RAG Assistant, a Retrieval-Augmented Generation (RAG)-powered conversational system that can understand, retrieve, and explain key insights from company financial reports. Using a combination of ChromaDB for vector search, Groq-hosted LLMs for reasoning, and a dual-interface approach (CLI and web frontend), the assistant allows users to upload their financial reports and engage in a context-aware dialogue.
Our approach bridges the gap between unstructured PDF reports and actionable insights, enabling analysts, investors, and researchers to quickly and accurately navigate large financial datasets.
Annual and quarterly reports are crucial for informed decision-making, yet analysts often face challenges due to the volume, complexity, and time constraints associated with them. Generic AI chatbots often hallucinate or fail to reference the correct context. This project aims to create an AI assistant capable of understanding the structure and terminology of financial reports, retrieving relevant context with high precision, and delivering grounded, explainable responses.
The Financial RAG Assistant ingests PDF-based financial reports, builds a persistent vector store for semantic search, and supports conversational Q&A. It offers both command-line and Streamlit-based web usage, integrating Groq LLMs for low-latency reasoning and Hugging Face embeddings for semantic retrieval.
The architecture is divided into four main layers:
PDFs are loaded using PyPDFLoader, split into overlapping chunks for efficient LLM context handling, embedded with sentence-transformers/all-MiniLM-L6-v2, and stored in ChromaDB for persistent semantic search.
User queries are embedded in the same vector space, and top-k relevant chunks are retrieved via cosine similarity.
The retrieved context and query are passed to a Groq-hosted LLaMA 3 model, generating answers grounded in the original report.
| Component | Technology Used |
|---|---|
| LLM Inference | LLaMA 3 via Groq API |
| Embeddings | Hugging Face all-MiniLM-L6-v2 |
| Vector Store | ChromaDB |
| PDF Loading | PyPDFLoader |
| Chunking | LangChain Text Splitter |
| Frontend | Streamlit |
| Backend | Python CLI |
Full repository with ingestion and query pipelines: GitHub Repo Link
Sample financial report PDFs: /data/reports directory in the repository

Users can operate the system via CLI:
python src/ingest.py --file "data/reports/Standard Chartered Bank.pdf"
python src/query.py --query "Revenue of the company?"
streamlit run streamlit_financial_rag_assistant.py
The Financial RAG Assistant now features a Streamlit-powered frontend that makes it easy to ingest financial reports and query them interactively — no command-line knowledge required.
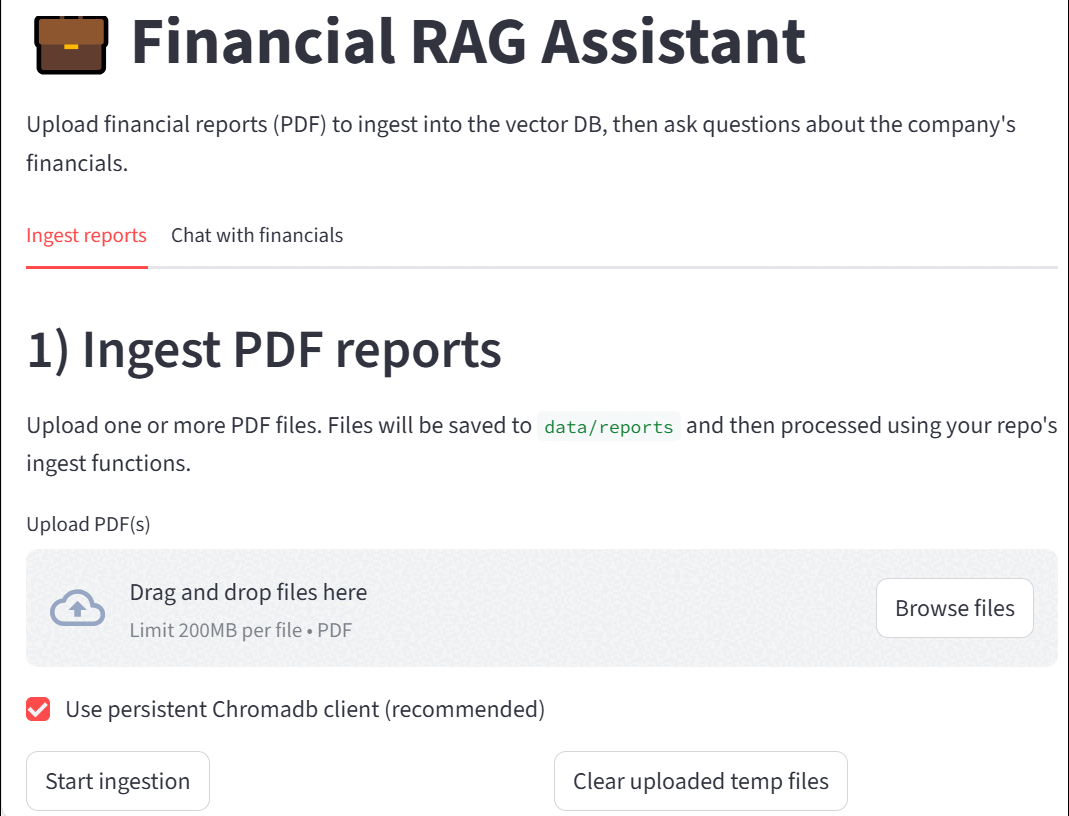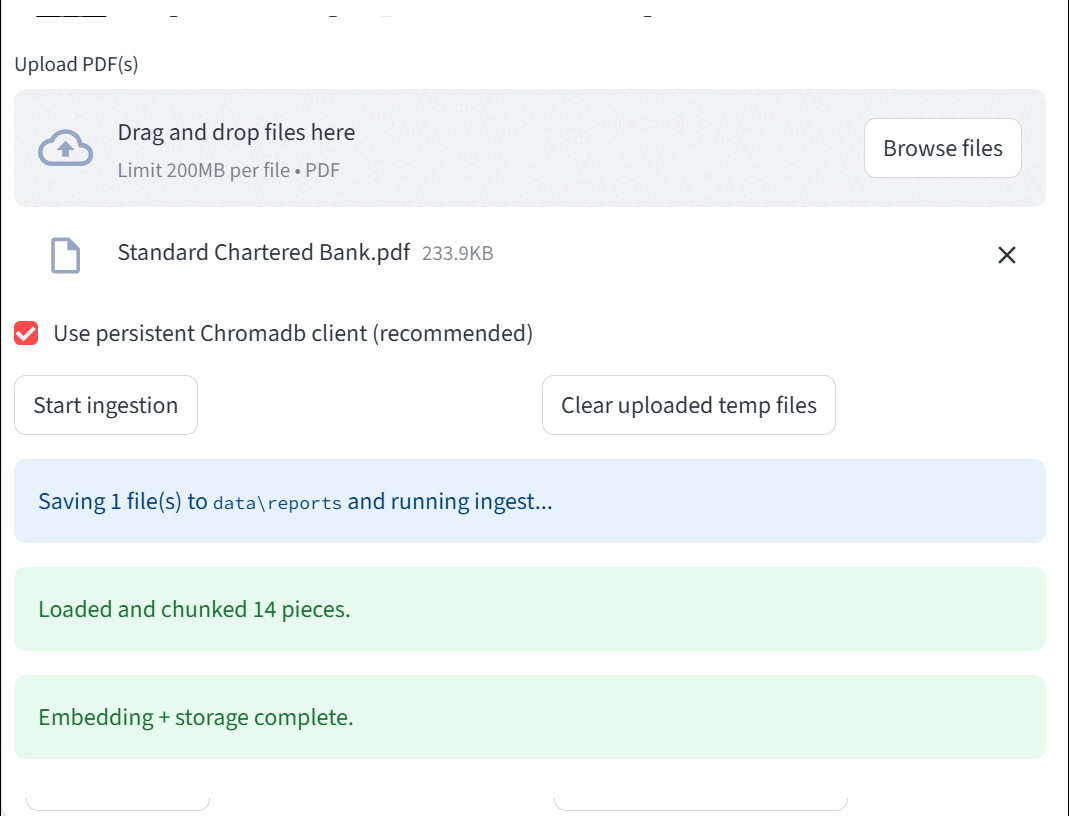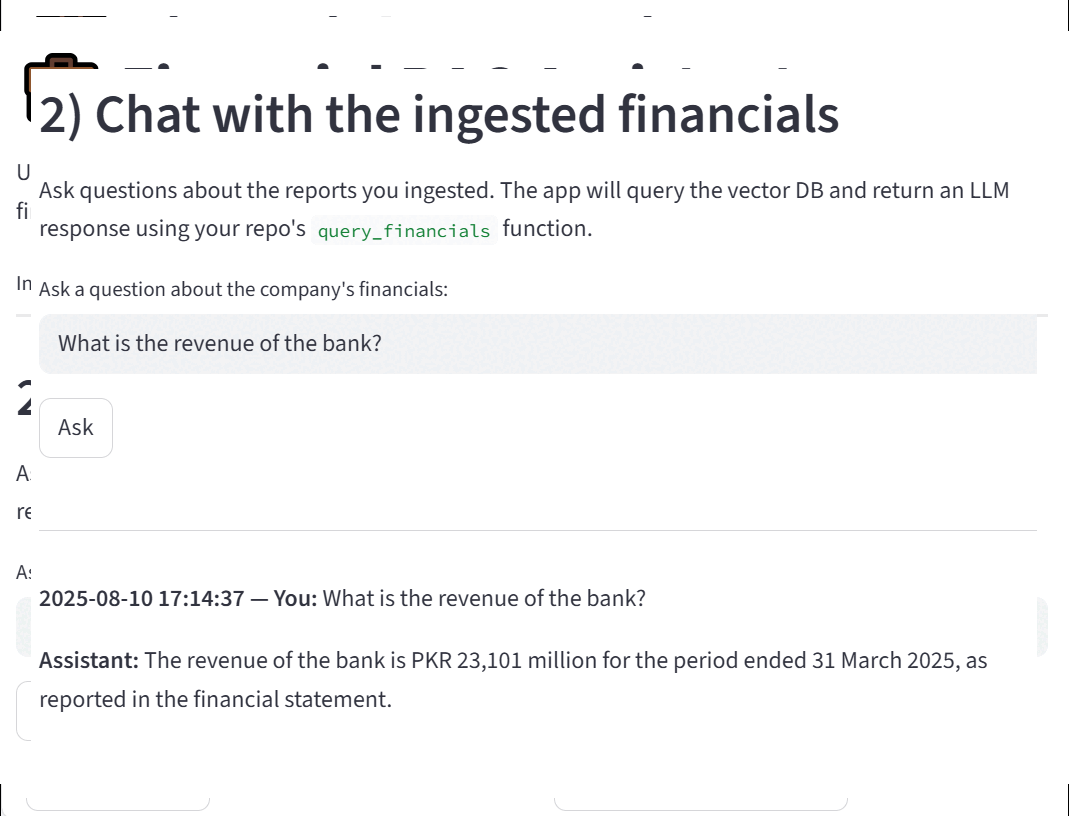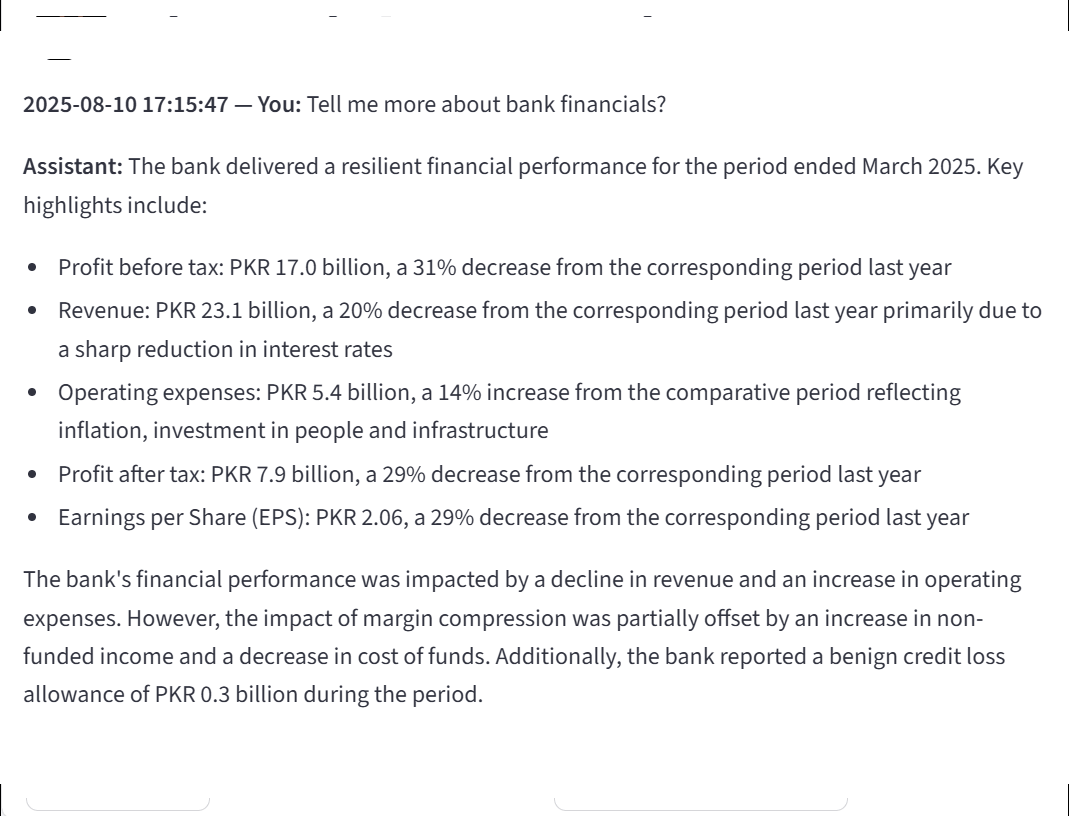
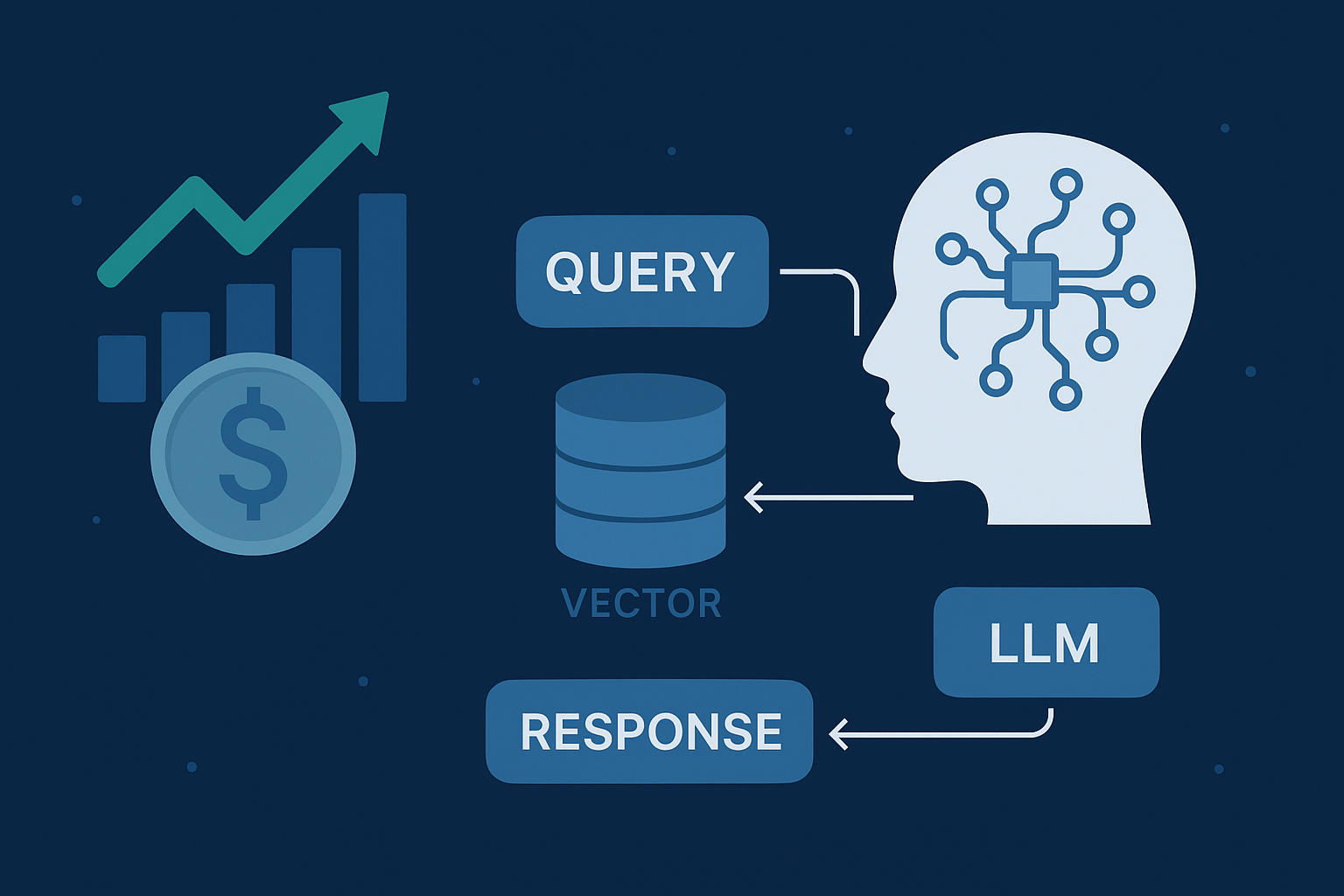
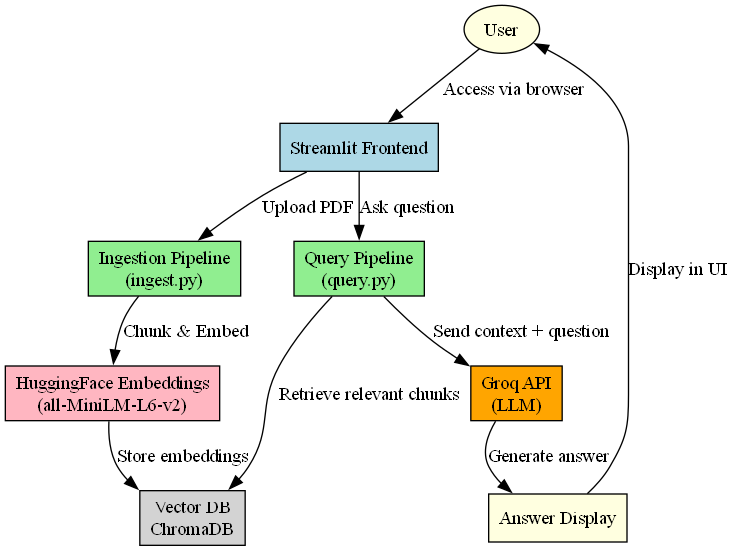
The following diagram provides a high-level overview of the Financial RAG Assistant system. It illustrates the flow of data from the user uploading financial reports through the ingestion and embedding pipelines, storage in the vector database, and finally querying via the language model with responses delivered back through the frontend interface. This architecture highlights how various components—including PDF processing, vector embeddings, ChromaDB, and the Groq-powered LLM—work together seamlessly to enable interactive and accurate financial insights.
Currently, the RAG system achieves 100% generation accuracy but only ~25% retrieval accuracy. This gap highlights that while the language model produces correct answers when given the right context, the retrieval pipeline often fails to bring in the most relevant chunks. Retrieval accuracy is further impacted by the quality of PDF text extraction; scanned or poor OCR-based PDFs may yield incomplete or noisy embeddings. The system also degrades in performance with very long reports or when handling multiple reports in a single session, leading to reduced precision and slower responses. Additionally, current chunking is primarily text-based, which limits accurate interpretation of financial tables and structured data.
Future enhancements will therefore focus on improving retrieval by:
Other planned improvements include support for multi-document conversations, finance-specific summarization prompts, voice-based querying, and further optimization of chunking and embedding strategies to scale with very large documents. Together, these enhancements aim to make the system more robust, reliable, and accurate for real-world financial analysis use cases.
While the system produces grounded responses, current guardrails are limited. Future versions will implement stricter safety protocols, content filtering, and output validation to prevent harmful or misleading outputs. This includes monitoring for biased, inaccurate, or inappropriate LLM responses and ensuring that only verifiable information from the ingested financial reports is delivered.
The Financial RAG Assistant is provided under an MIT License, allowing unrestricted use, modification, and distribution for personal or commercial purposes. Users are responsible for providing their own LLM API keys (Groq) and complying with all licensing terms of third-party components such as Hugging Face embeddings, ChromaDB, and Streamlit. Attribution to the original author (Syeda Sarah Mashhood) is encouraged for derivative works.
The Financial RAG Assistant demonstrates the effective application of RAG techniques in finance, enabling rapid, context-aware, and explainable analysis of large-scale company financial reports. Its hybrid CLI and web interface support both technical users and business analysts, enhancing decision-making by providing reliable insights directly from structured and unstructured financial data.
Here is the link to a little demo:
https://www.loom.com/share/6108a917f93548258a6daaf324f8379a?sid=b39d573a-d6b7-4a74-b05c-13de5330b6a4