This project presents a robust multi-class classification pipeline to predict the marketing category of FDA-listed pharmaceutical products. Leveraging a blend of classical ML models and deep learning, the pipeline handles structured metadata to categorize each product into NDA, ANDA, OTC, BLA, or UNAPPROVED.
The dataset includes text, categorical, and numeric fields. Preprocessing included:
LabelEncoder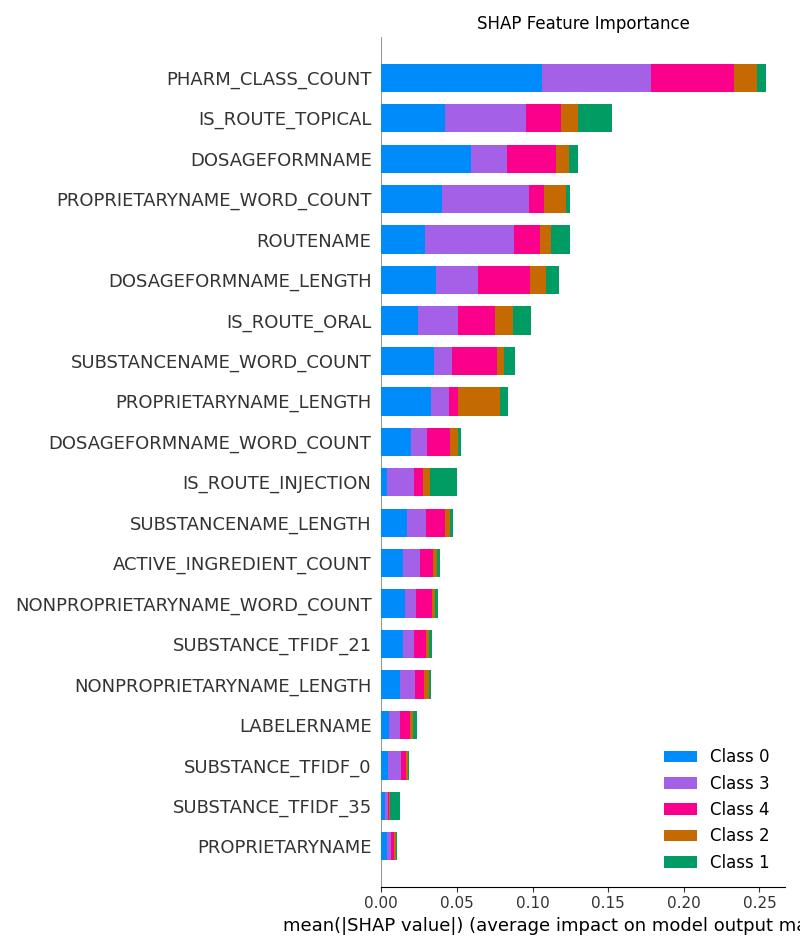
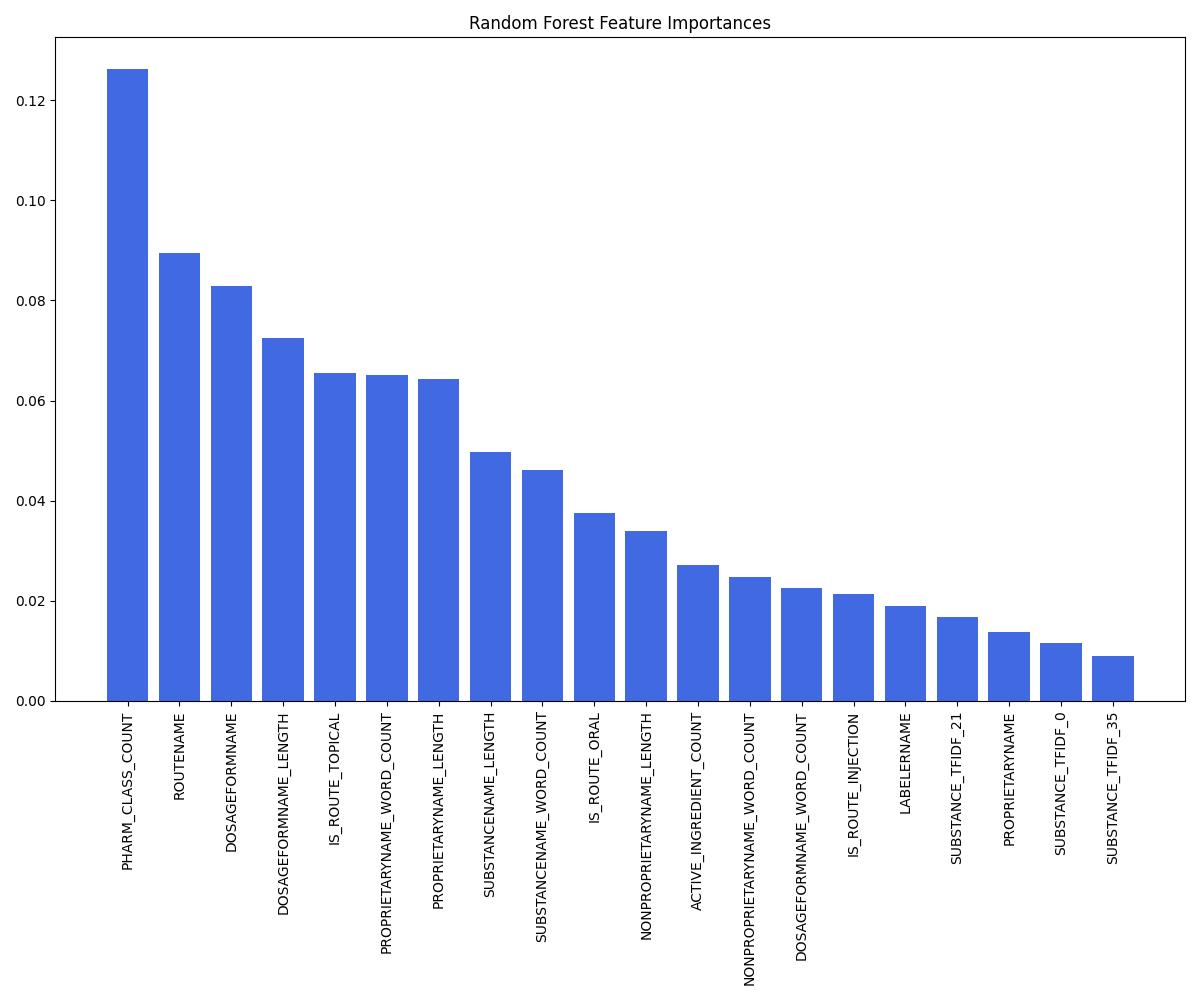
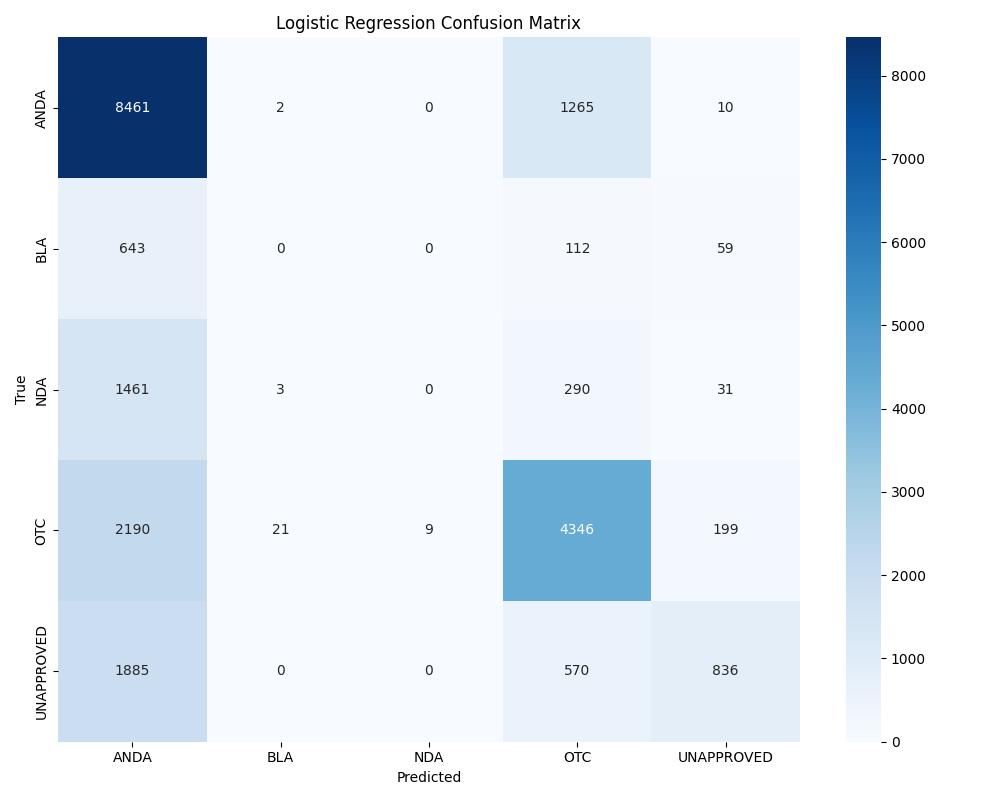
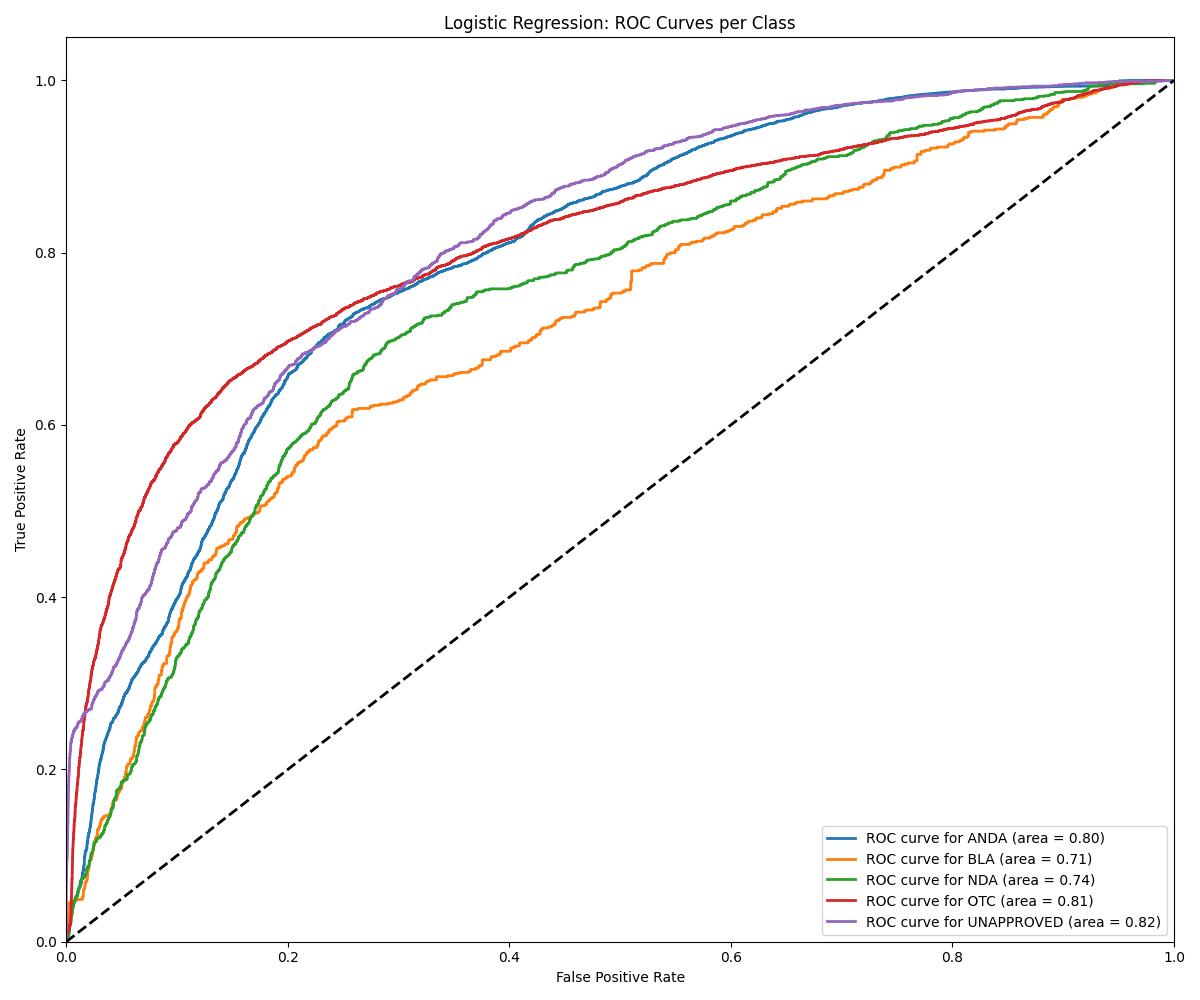
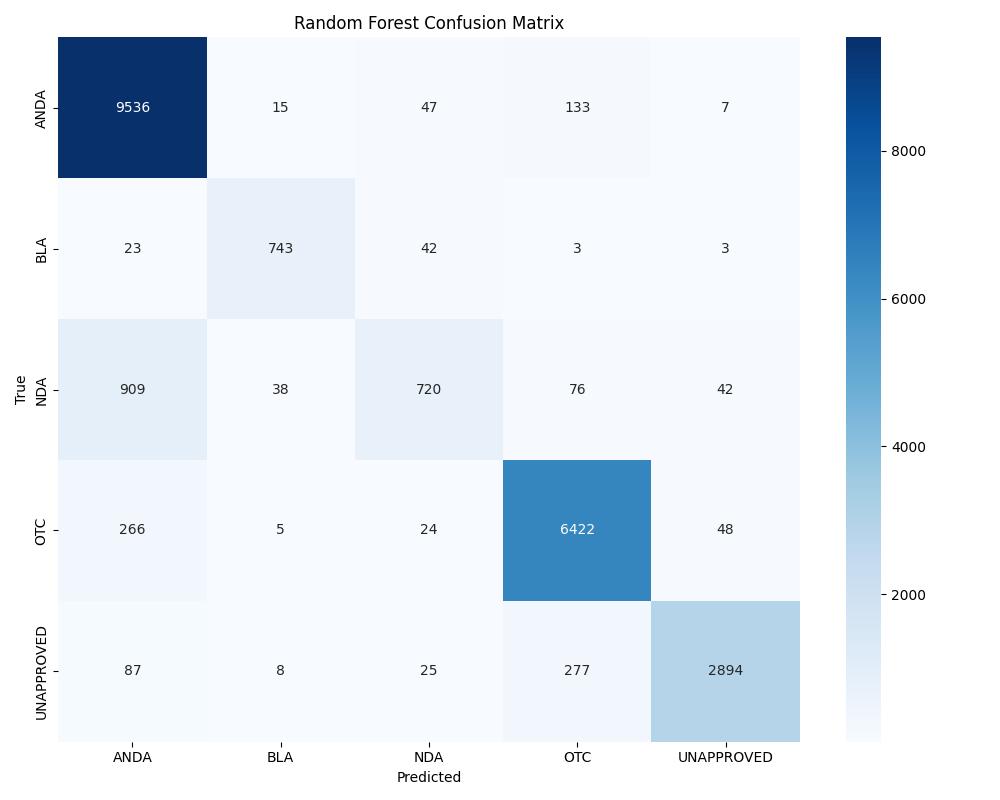
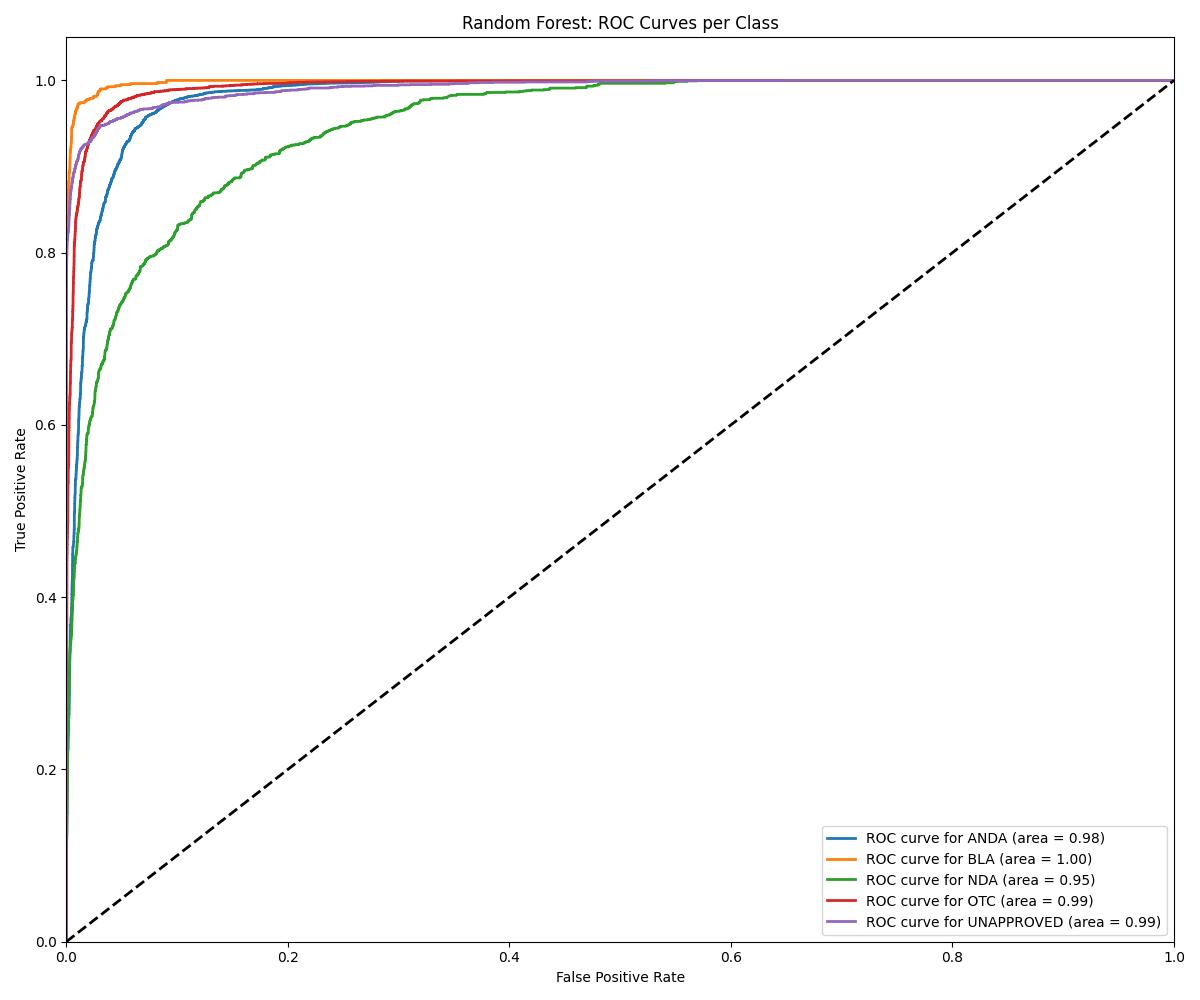
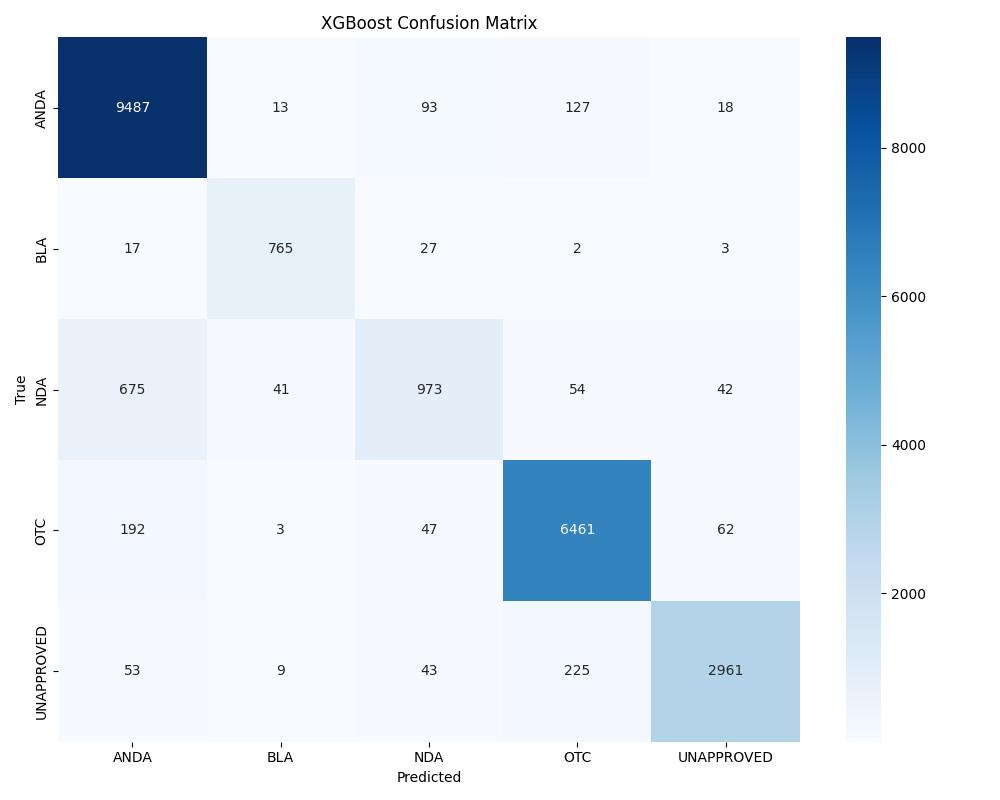
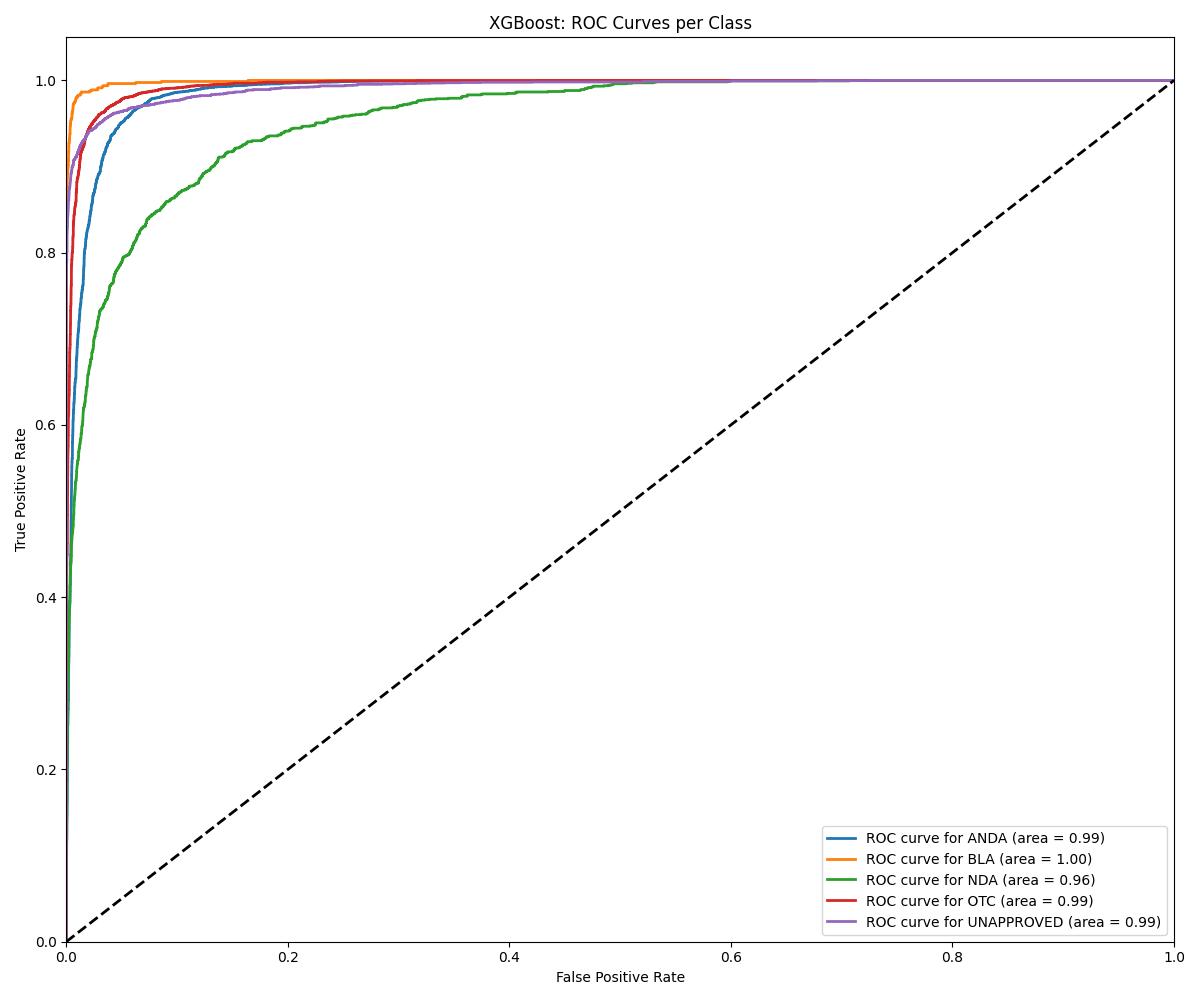
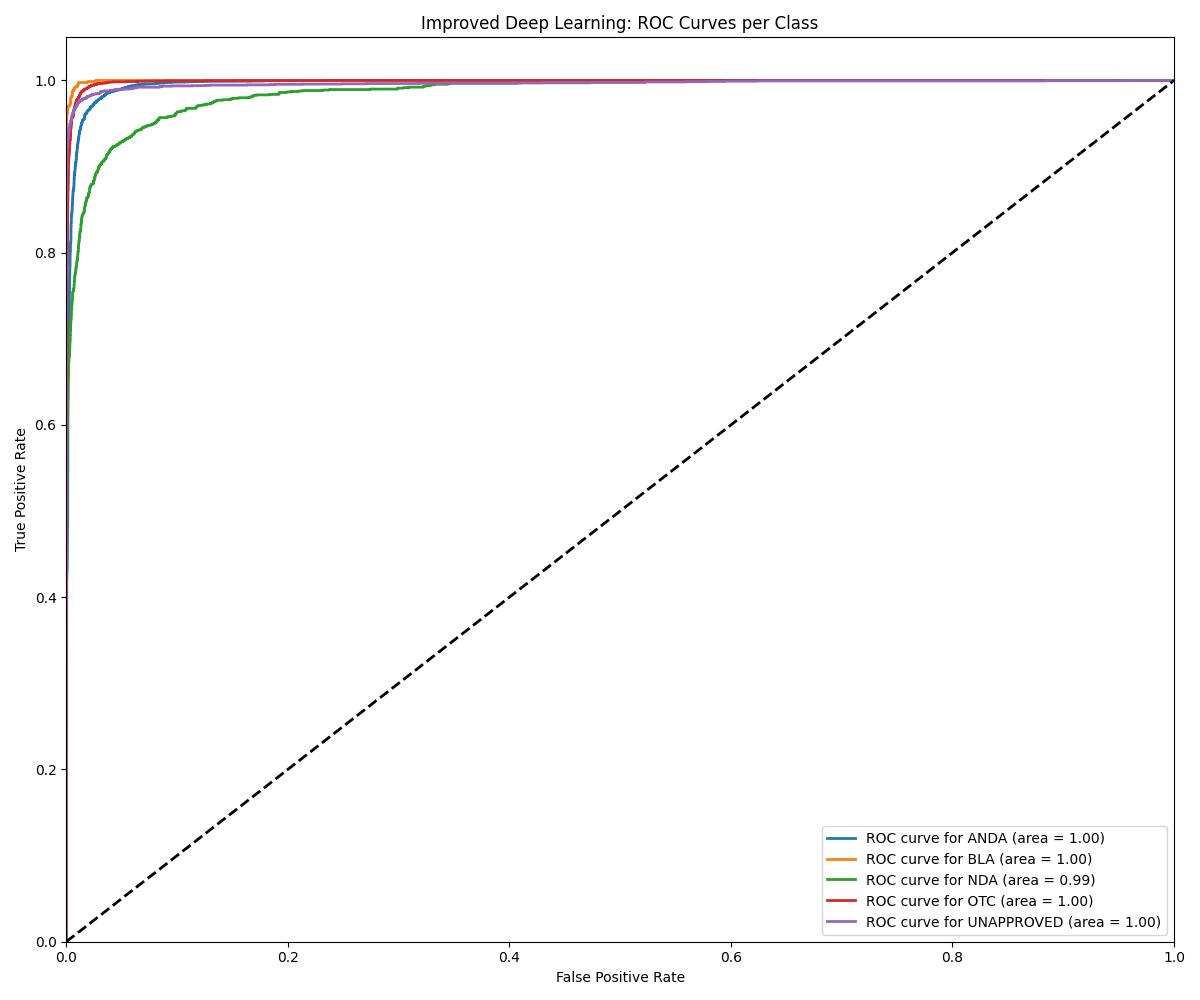
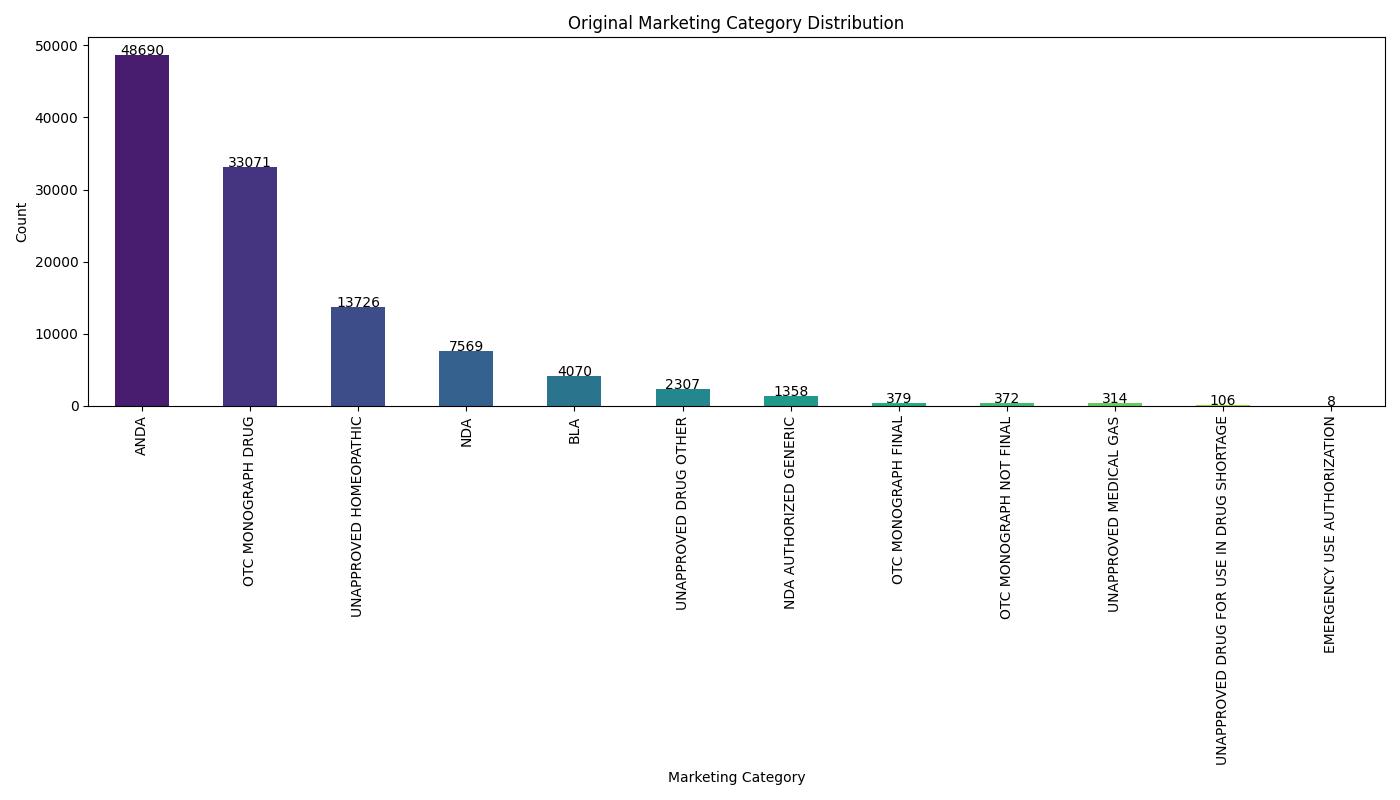
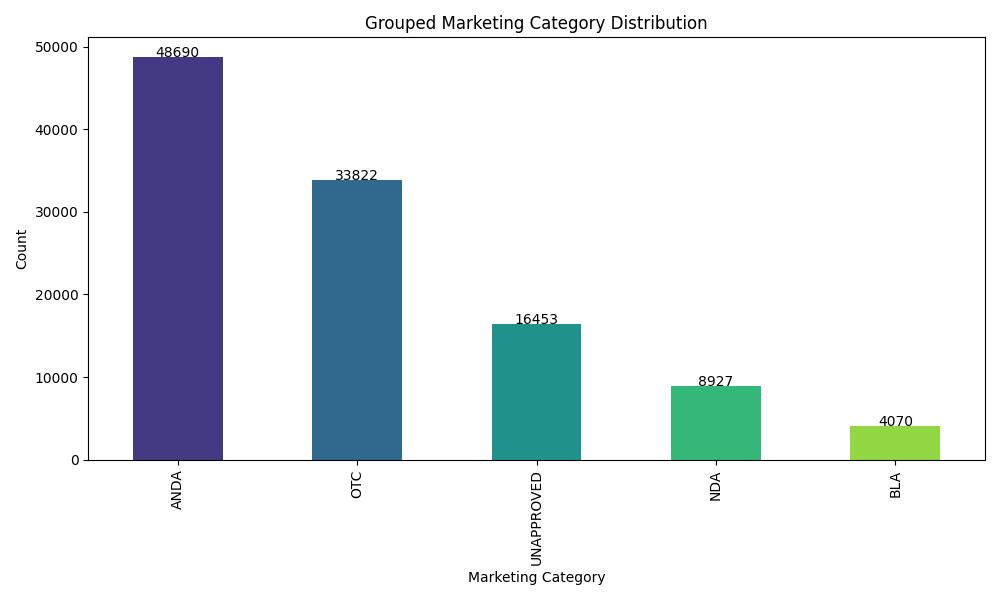
| Model | Accuracy | ROC AUC | Notes |
|---|---|---|---|
| Logistic Regression | ~0.83 | 0.81 | Baseline |
| Random Forest | ~0.96 | 0.97 | Best for UNAPPROVED/NDA |
| XGBoost | ~0.97 | 0.98 | Consistently strong |
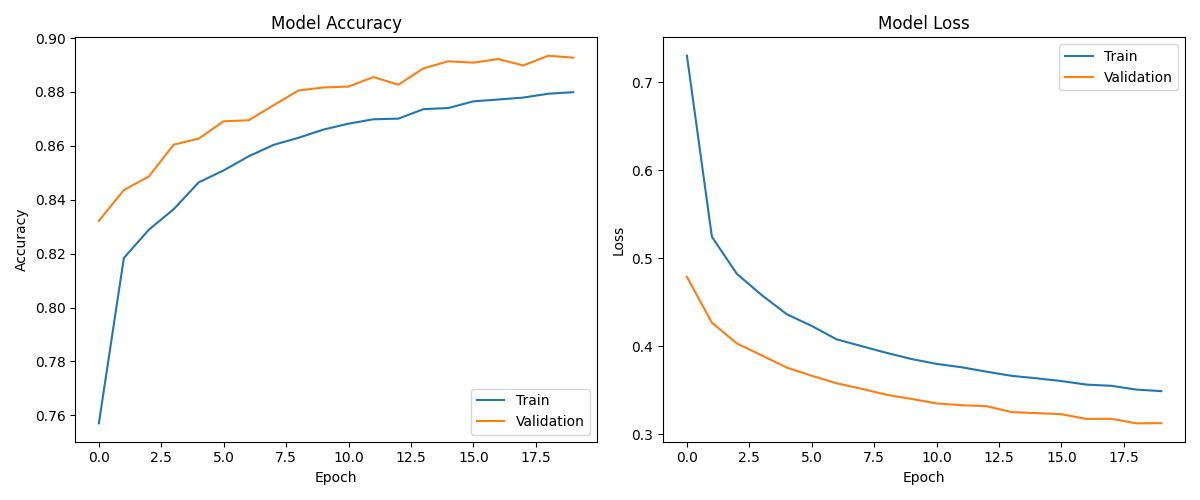
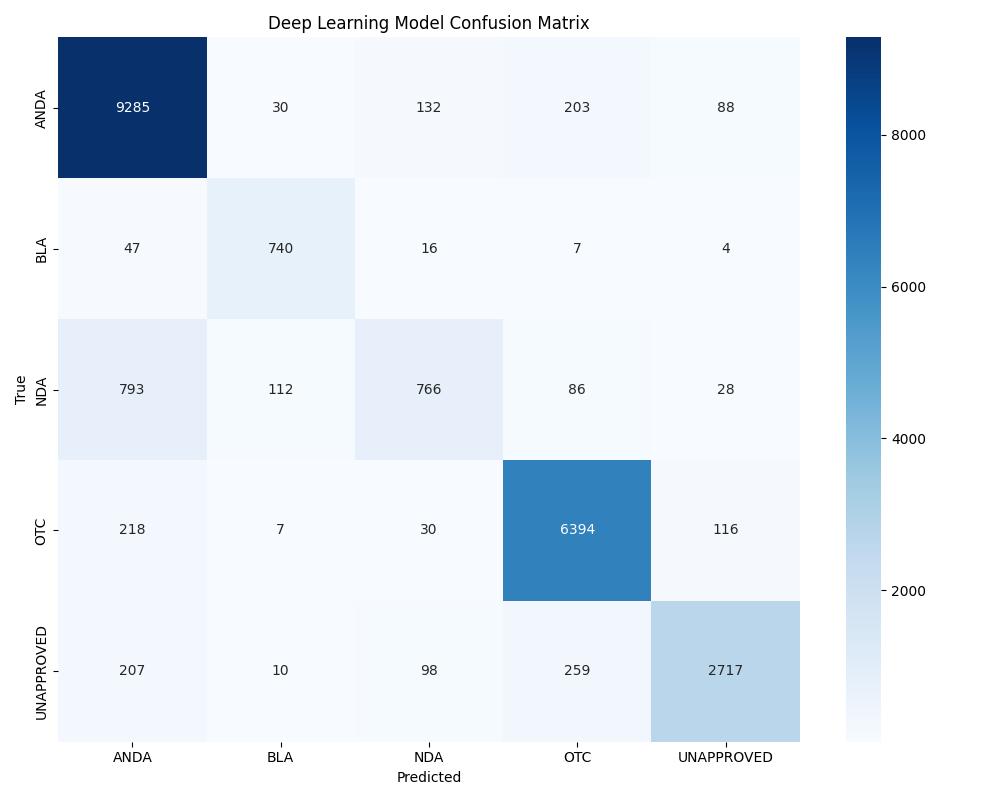
| Deep Learning | ~0.96 | 0.97 | Good with tuning |
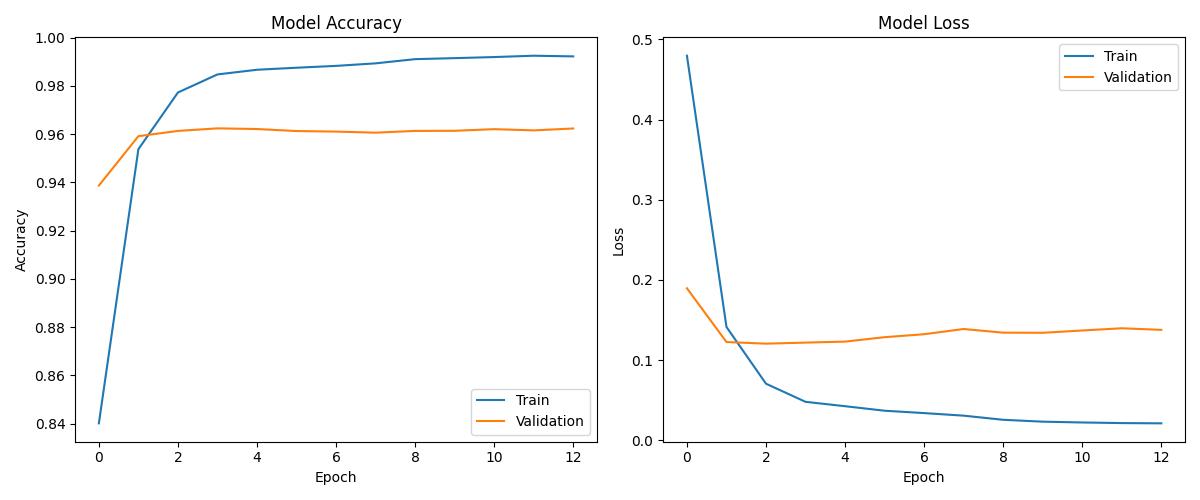
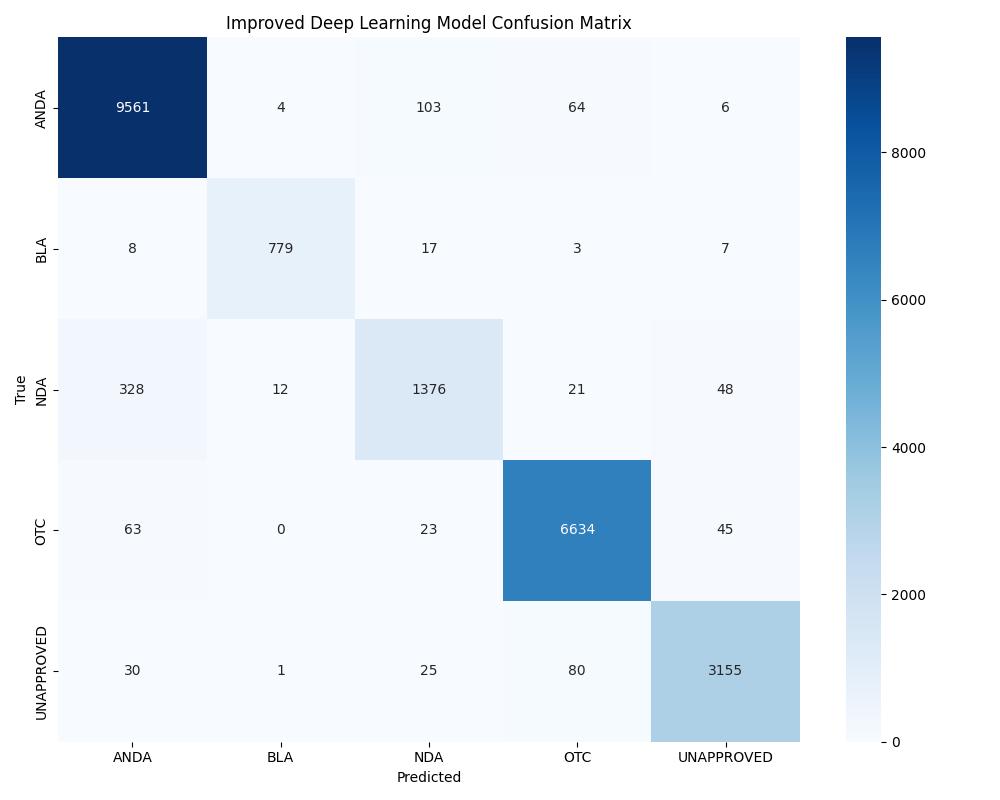
| DL (Improved) | ~0.99+ | 0.99+ | Best overall generalization |
Future Directions:
This project showcases a complete, reproducible pipeline for real-world regulatory data classification using both traditional ML and deep learning. It highlights preprocessing, feature importance, visual evaluation, and production-ready model deployment.
🎯 Deployed models and data are hosted on Hugging Face for public access and further experimentation.
