A lightweight Retrieval-Augmented Generation (RAG) application that answers questions about Ethiopian history using a local text corpus, a persistent Chroma vector database, and a Groq-hosted LLM. It includes a Streamlit UI and an optional CLI.
.txt sources from data/, chunk and embed with sentence-transformers/all-MiniLM-L6-v2.chroma_db/) for fast reloads.langchain_groq.ChatGroq authenticated by GROQ_API_KEY.code/app.py: Streamlit UI for querying and displaying answers.code/vectordb_and_ingestion.py: VectorDBManager (chunking, embedding, persistence, retrieval).code/prompt_builder.py: Builds compact prompts from retrieved chunks.code/retrieval_and_response.py: CLI pipeline (load/ingest → retrieve → prompt → answer).code/logger.py: Minimal console logger used across modules.wiki_fetcher.py: Fetches Wikipedia pages into data/ as .txt.# 1) Create and activate a virtual environment (recommended) python3 -m venv venv source venv/bin/activate # Windows: venv\Scripts\activate # 2) Install dependencies pip install -r requirements.txt # 3) Configure environment # Create .env and set GROQ_API_KEY printf "GROQ_API_KEY=your_key_here\n" > .env # 4) (Optional) Seed/expand the corpus with Wikipedia content python -c "from wiki_fetcher import fetch_and_save_page; fetch_and_save_page('Axum Empire')" # 5) Run the Streamlit app streamlit run code/app.py
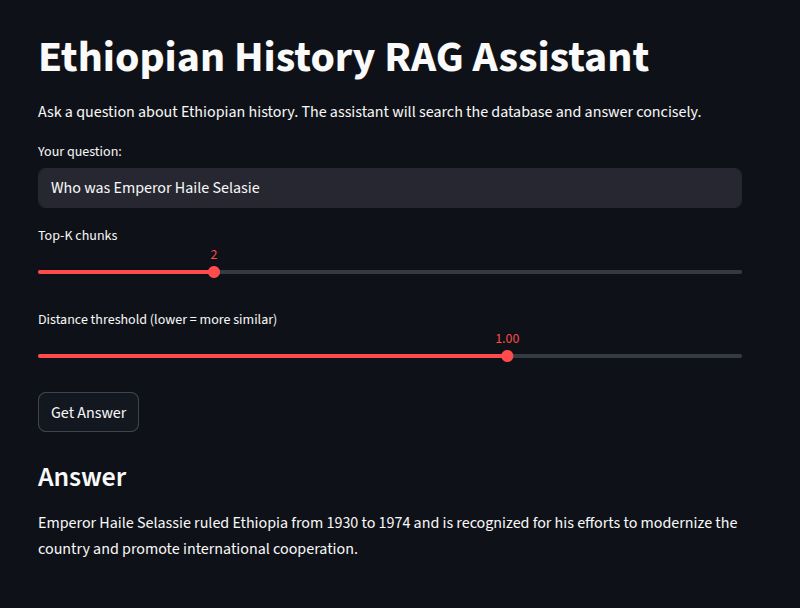
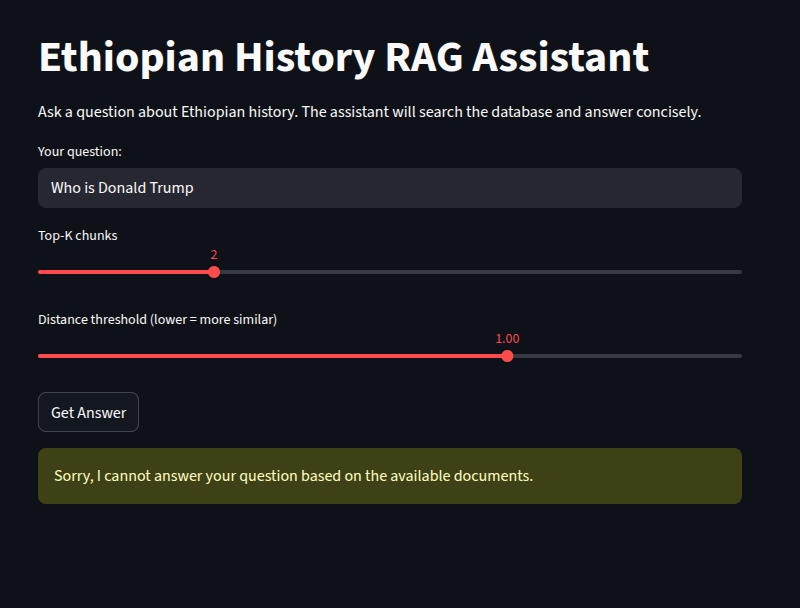
python -m code.retrieval_and_response "Who was Menelik II?" --top_k 2 --threshold 1.0
GROQ_API_KEY: Your Groq API key for langchain_groq.ChatGroq.Example .env:
GROQ_API_KEY=your_key_here
.txt sources in data/.chroma_db/.VectorDBManager.prompt_builder.build_prompt.langchain_groq.ChatGroq and display/return it.rag-history-agent/ ├─ code/ │ ├─ app.py # Streamlit UI │ ├─ retrieval_and_response.py # CLI entry │ ├─ vectordb_and_ingestion.py # VectorDBManager (chunk/embed/persist) │ ├─ prompt_builder.py # Prompt assembly │ ├─ logger.py # Shared logger │ └─ rag_assistant/ # Utilities (optional) ├─ wiki_fetcher.py # Wikipedia ingestion utility ├─ data/ # Text corpus (.txt files) ├─ chroma_db/ # Chroma persistence (ignored by git) ├─ assets/screenshots/ # Images embedded in README/publication ├─ requirements.txt # Python dependencies ├─ .gitignore └─ README.md
.env exists, includes GROQ_API_KEY, and python-dotenv is installed.data/.requirements.txt.If requirements.txt isn’t populated, include:
streamlit python-dotenv langchain langchain-community langchain-groq sentence-transformers chromadb requests beautifulsoup4
# code/retrieval_and_response.py results = vector_db.similarity_search_with_score(query, k=top_k * 5) results = sorted(results, key=lambda x: (x[1] is None, x[1])) # deterministic unique_contexts, seen = [], set() for doc, score in results: if score is not None and score > similarity_threshold: continue if doc.page_content not in seen: seen.add(doc.page_content) unique_contexts.append((doc, score)) if len(unique_contexts) >= top_k: break
# code/prompt_builder.py prompt = ( "Answer ONLY using the context below.\n" "- If the context clearly contains the answer, state it concisely.\n" "- If the context does not contain the answer, reply exactly: I don't know\n\n" f"Context:\n{context}\n\n" f"Question: {query}\n" "Answer:" )
from langchain_groq import ChatGroq llm = ChatGroq( api_key=os.getenv("GROQ_API_KEY"), model="llama-3.1-8b-instant", temperature=0 ) response = llm.invoke(prompt)
https://streamlit.io/https://python.langchain.com/https://www.trychroma.com/https://www.sbert.net/https://groq.com/Provided as-is for educational purposes. For public release, consider the MIT License.
Contact me : aman.atalay-ug@aau.edu.et