
Have you ever used AI to generate a title, only to find it feels… well, flat? If you’ve noticed that LLMs like GPT-3 sometimes produce predictable, repetitive, or overly structured results, you’re not alone. Whether it’s the overuse of certain adjectives or a robotic sentence flow, these models can struggle to match the nuance and creativity of human thought — especially when it comes to generating punchy, attention-grabbing titles.
In this blog, we’ll explore how Reinforcement Learning (RL) can take LLMs to the next level. Instead of relying on static fine-tuning, RL introduces dynamic feedback, teaching models to adapt and improve over time. If you’re curious about how AI can learn to create more natural, human-like titles — or if you’ve faced this problem yourself — let’s dive in and explore how RL can transform AI-generated creativity!
Background
Before diving into the specifics of the tool being built, it’s important to establish a foundational understanding of how large language models (LLMs) work and the techniques used to fine-tune them. This section provides background on LLMs, their industry-level applications, and various fine-tuning methods. From traditional full fine-tuning to more efficient approaches like LoRA, adapters, and prompt tuning, we’ll explore how different strategies enable customisation of LLMs for specific tasks. Understanding these concepts is key to appreciating the nuances of using reinforcement learning to improve model behaviour, which we’ll discuss in subsequent sections.
Feel free to jump to the next section if you are already aware about these fundamentals! 😎
Introduction to Large Language Models (LLMs)
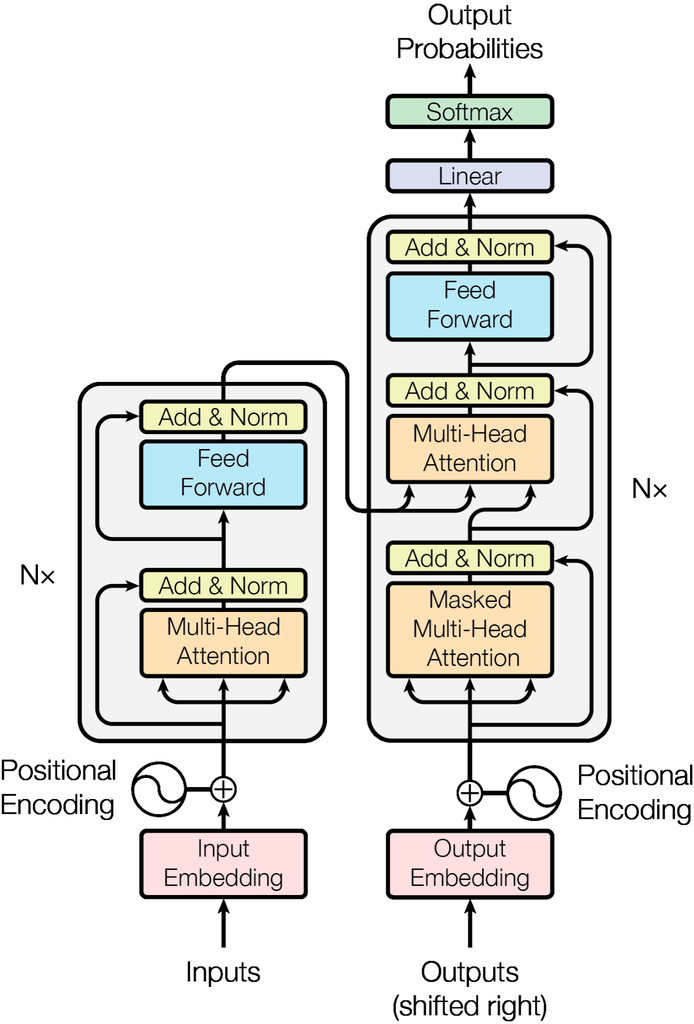
Large Language Models (LLMs) are advanced machine learning models designed to understand and generate human-like text. These models are built on transformer architecture, which enables them to capture complex relationships between words and phrases, making them highly effective for a wide range of natural language processing (NLP) tasks. Transformers use mechanisms like self-attention to process entire sentences or documents, allowing LLMs to understand the context of words in relation to one another.
Some of the most well-known LLMs, like GPT-3, GPT-4, and BERT, are trained on massive amounts of text data. These models excel at tasks such as text generation, summarisation, translation, and even answering questions based on context. Their flexibility has made them the cornerstone of many real-world applications, from chatbots to automated content generation systems.
How Transformers Work
The transformer architecture consists of two main components:
-Encoder: Processes input text to understand its meaning.
-Decoder: Generates output text based on the encoded input.
By using layers of attention mechanisms, transformers can weigh the importance of different words in a sentence, allowing them to focus on the most relevant information at each step.
Industry Usage of LLMs
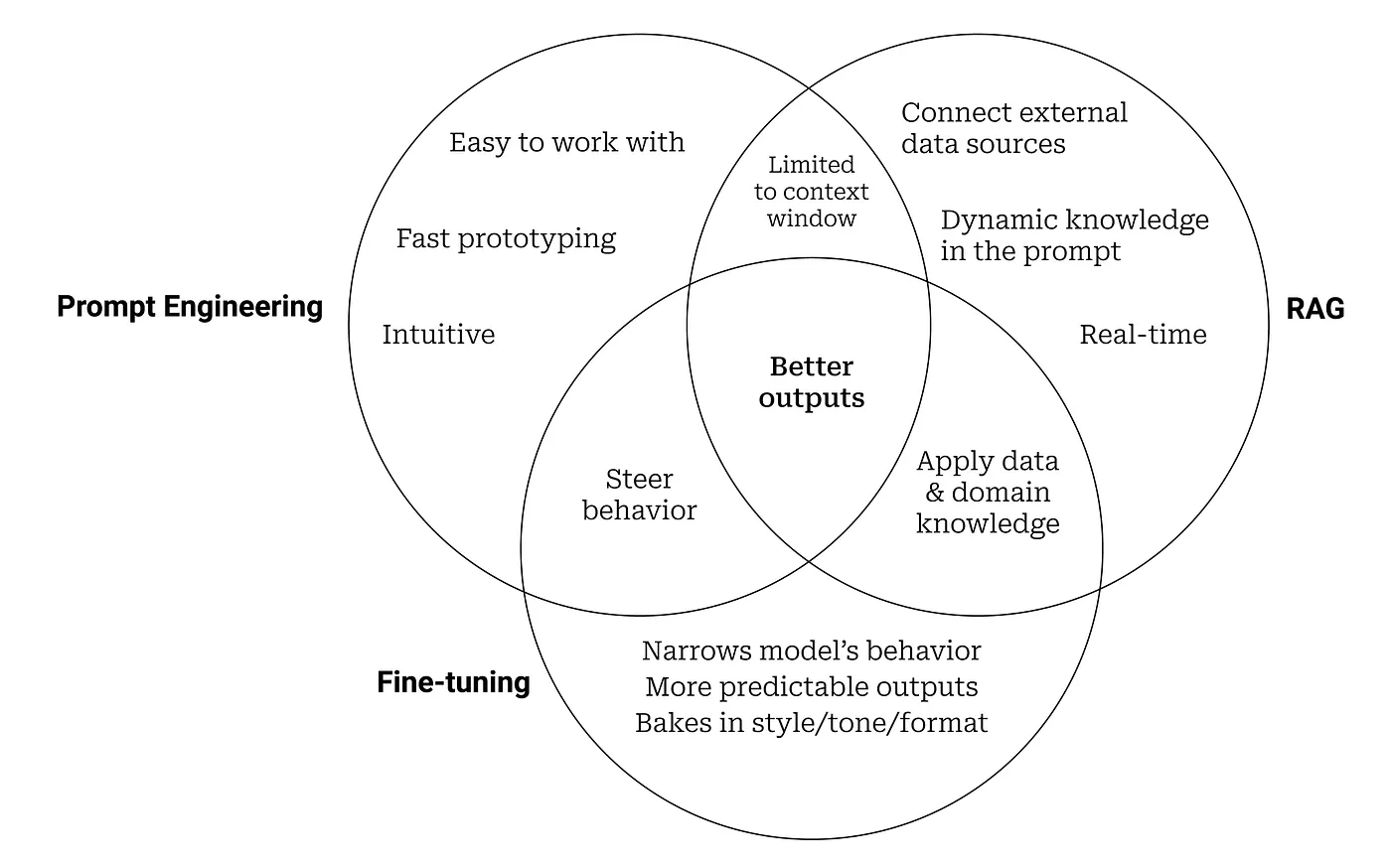
Large Language Models (LLMs) have become essential tools in various industries, enabling applications like chatbots, content generation, and customer support. Their versatility lies in the ability to adapt to different use cases through several approaches. Let’s look at three prominent ways LLMs are used today:
-
Prompt Engineering
Prompt engineering involves designing effective prompts (or instructions) to elicit the desired response from an LLM without changing the underlying model. In this method, the model generates text based on specific input prompts, allowing businesses to leverage LLMs for tasks like writing summaries, answering questions, or generating marketing copy. The ability to craft precise prompts can significantly affect the quality of the output, making this a low-cost but high-impact approach to utilizing LLMs. -
Fine Tuning
Fine tuning involves adjusting an LLM’s weights by training it further on a specific dataset. This technique adapts a general-purpose LLM for specialised tasks, ensuring it performs well in a specific domain or context. Fine tuning requires more resources than prompt engineering but offers higher performance for specific applications. There are three key approaches to fine-tuning
- Full-Model Fine Tuning: Adjusts all model parameters, allowing the model to adapt deeply to the new data. However, it is computationally expensive and requires large datasets.
- Parameter-Efficient Fine Tuning (PEFT): Techniques like LoRA (Low-Rank Adaptation) and adapters modify only a small subset of parameters, offering a lightweight alternative to full-model fine tuning. This makes PEFT methods more practical for applications with limited computational resources.
- RLHF (Reinforcement Learning with Human Feedback): This approach combines reinforcement learning with human feedback to fine-tune models. Typically, the model is first pre-trained and fine-tuned using supervised learning, then further refined with reinforcement learning guided by human preferences.
3.Retrieval-Augmented Generation (RAG):
RAG combines LLMs with a knowledge retrieval system. Instead of relying solely on the internal knowledge of an LLM, RAG fetches relevant external data and combines it with the model’s generative abilities. This method allows LLMs to handle tasks requiring up-to-date or specialized information, such as answering technical queries or summarizing documents with real-time data. By enhancing the model’s knowledge base with external data sources, RAG helps LLMs maintain relevance and accuracy in dynamic domains.
These approaches showcase how LLMs are being deployed across industries, either by fine-tuning them for specific tasks, crafting prompts to guide their responses, or augmenting them with external knowledge sources to improve their output.
Reinforcement Learning with Human Feedback (RLHF)
In large language models (LLMs), generating high-quality and contextually relevant responses is crucial, especially when human preferences play a significant role in determining the quality of those responses. However, training LLMs with traditional methods doesn’t fully incorporate the nuanced preferences that humans may have. This is where Reinforcement Learning with Human Feedback (RLHF) comes into play.
RLHF bridges the gap between machine-generated outputs and human expectations by introducing a feedback loop that adjusts the model based on human preferences. Instead of relying solely on pre-defined objectives, RLHF actively involves human feedback during training. This feedback is incorporated to improve the quality of responses, ensuring that the model aligns more closely with human preferences and values.
Why Use RLHF?
- Alignment with Human Preferences: Traditional language models may generate outputs that are grammatically correct but may not always align with human expectations in terms of tone, relevance, or clarity. RLHF incorporates human feedback into the model’s learning process, ensuring it generates outputs more aligned with human preferences.
- Continuous Improvement: RLHF allows the model to continuously refine its behavior based on ongoing human feedback. This is particularly useful in dynamic and complex tasks where the “right” response is subjective and can change depending on the context.
- Handling Ambiguity: Some prompts can have multiple valid responses, and different people may prefer different responses. RLHF enables the model to better handle such ambiguous situations by learning from comparative human feedback.
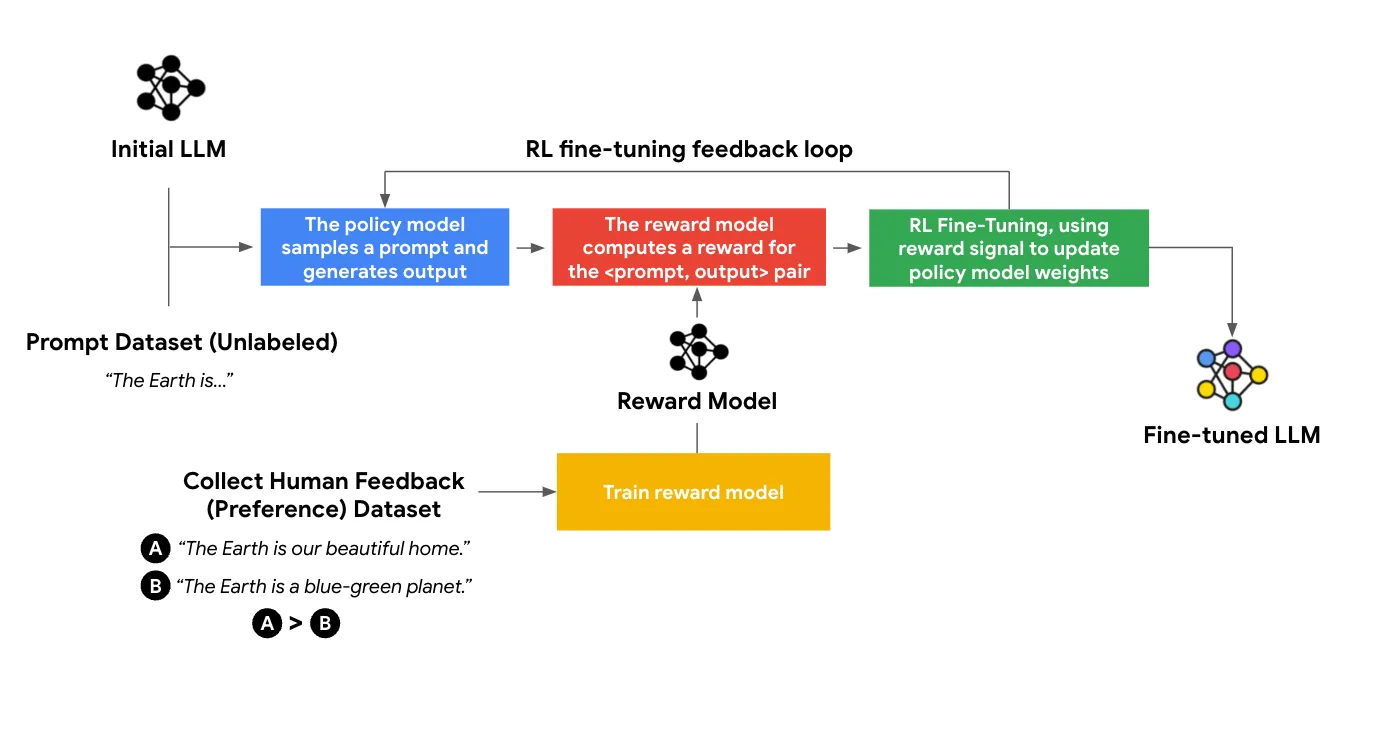
The image illustrates the RLHF process, using the example of a prompt, “The Earth is…”. The key steps involved in RLHF are:
1.Initial LLM Response: The policy model (initial LLM) generates multiple responses for the prompt, such as:
A: The Earth is our beautiful home
B: The Earth is a blue-green planet.
2.Human Feedback: Humans are presented with the generated responses and express their preference, e.g., preferring A over B.
3.Training the Reward Model: Human preferences are used to train a reward model, which assigns a higher reward to the preferred response. In this case, A would receive a higher reward than B.
4.Fine-tuning the LLM: The reward model’s feedback is used in a reinforcement learning loop to fine-tune the policy model (LLM). The policy model is updated to generate responses similar to A, which are preferred by humans, more frequently.
5.Feedback Loop: The updated LLM (policy model) is continually fine-tuned through this RLHF loop, improving its ability to generate responses that align with human preferences over time.
In essence, RLHF helps enhance the performance of large language models by using human preferences to guide their training, ensuring that the outputs generated are not only technically correct but also preferred by users.
Project Outline
In this project, we aim to push the boundaries of title generation by combining Large Language Models (LLMs) with Reinforcement Learning (RL). Traditional fine-tuning approaches for LLMs, like those used in models such as GPT-3 and GPT-4, often result in titles that feel predictable or lack creative nuance. Here, we explore how RL can help LLMs adapt dynamically, learning to generate more engaging and human-like titles through continuous feedback. By using data collected from news APIs, we train the model to recognize and respond to specific themes such as AI, 5G, and COVID-19, creating a smarter, more context-aware title generator.
Methodology
The methodology centers around a structured pipeline that integrates data collection, preprocessing, model training, and feedback loops for dynamic learning. The codebase for this project is availablehere on GitHub , detailing the setup and implementation steps for replicating this experiment.
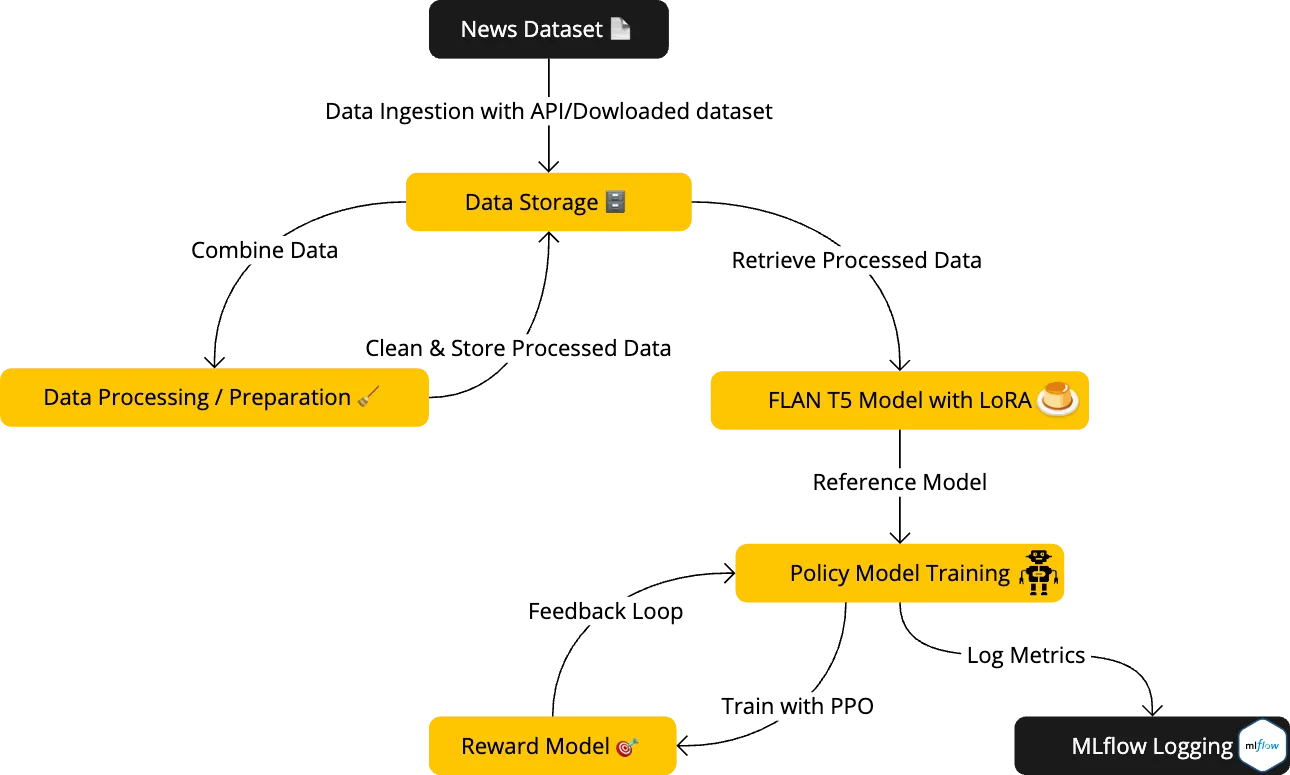
- Data Collection and Storage: We start by collecting article data from GNEWS and The News API, focusing on a curated set of themes. This data is stored as JSON files for structured access in the subsequent stages.
- Data Processing: After initial storage, the data undergoes rigorous cleaning and splitting into training and test sets. This ensures that the model learns from high-quality inputs and that we can evaluate its performance reliably.
- Policy Model Training: Our model of choice is Flan T5, which we fine-tune using LoRA and PPO. LoRA enables parameter-efficient adaptation, while PPO optimizes the model’s responses by refining its policies based on the reward signals. This combination allows the policy model to evolve more effectively, especially for nuanced tasks like title generation.
- Reward Model and Feedback Loop: The reward model, powered by roberta-base-openai-detector, evaluates the outputs from the policy model. This feedback is essential for the RL loop, where the model continuously learns from both positive and corrective feedback to improve its title generation capabilities. The RLHF (Reinforcement Learning from Human Feedback) approach enables a more iterative and responsive training process, resulting in more refined outputs.
- MLflow Logging and Tracking: Throughout the training cycle, MLflow logs metrics and tracks model performance. Along with the humanity score predicted by the reward model , we log some NLP based metrics to finalize the best checkpoint/model for our usecase. The metrics will be covered in detail in the next section.
Model Evaluation
To evaluate the generated titles beyond simple metrics, we implemented several NLP-based metrics to capture different aspects of title quality. These metrics allow us to quantify elements like linguistic richness, structural alignment, and emotional tone, giving us a deeper understanding of how closely the generated titles match human-written ones. Below is the code implementation of these metrics, structured for improved readability and efficiency:
import spacy import numpy as np from textblob import TextBlob from collections import Counter # Load spaCy model only once nlp = spacy.load("en_core_web_sm") # Metric: Adjective Count using spaCy def count_adjectives(title): doc = nlp(title) adjectives = [token.text for token in doc if token.pos_ == "ADJ"] return len(adjectives) # Metric: POS Pattern Matching (POS distribution) def pos_distribution(title): doc = nlp(title) pos_tags = [token.pos_ for token in doc] return dict(Counter(pos_tags)) # Metric: Calculate POS similarity between generated and human titles def pos_pattern_matching(generated_title, human_title): gen_pos_dist = pos_distribution(generated_title) human_pos_dist = pos_distribution(human_title) # Calculate similarity as the sum of the minimum occurrences for each POS tag similarity = sum(min(gen_pos_dist.get(pos, 0), human_pos_dist.get(pos, 0)) for pos in set(gen_pos_dist.keys()).union(human_pos_dist.keys())) # Normalize by the number of POS tags in the shorter title max_possible_similarity = min(sum(gen_pos_dist.values()), sum(human_pos_dist.values())) normalized_similarity = similarity / max_possible_similarity if max_possible_similarity else 0 return normalized_similarity # Metric: Word Diversity def word_diversity(title): words = title.lower().split() unique_words = set(words) diversity_score = len(unique_words) / len(words) if words else 0 return diversity_score # Metric: Sentiment (Emotional Tone) def get_sentiment(title): blob = TextBlob(title) return blob.sentiment.polarity # Metric: Sentiment Match def sentiment_match(generated_title, human_title): gen_sentiment = get_sentiment(generated_title) human_sentiment = get_sentiment(human_title) return gen_sentiment - human_sentiment def get_all_metrics(test_dataset, expected_predictions): output = {} adj_count_list = [] pos_distribution_list = [] word_diversity_list = [] sentiment_match_list = [] for ix, iy in zip(test_dataset, expected_predictions): adj_count_list.append(count_adjectives(ix)) pos_distribution_list.append(pos_pattern_matching(ix, iy)) word_diversity_list.append(word_diversity(ix)) sentiment_match_list.append(sentiment_match(ix, iy)) output['mean_adjective_count'] = np.mean(adj_count_list) output['mean_pos_distribution'] = np.mean(pos_distribution_list) output['mean_word_diversity'] = np.mean(word_diversity_list) output['mean_sentiment_score'] = np.mean(sentiment_match_list) return output
Conclusion
Through this project, we aimed to improve the quality of AI-generated titles using a reinforcement learning approach that emphasizes adaptability and continuous improvement. By integrating custom NLP-based evaluation metrics, we can better measure the model’s performance in generating titles that resonate with human readers in terms of linguistic richness, structure, and sentiment.
While we have laid a strong foundation, there is room for further experimentation and fine-tuning, especially in refining the reward model and exploring additional metrics. This project demonstrates how reinforcement learning, combined with carefully designed evaluation metrics, can create a path toward more nuanced and engaging AI-generated content.