
Summary:
This publication analyzes the deployment architecture of the SQL Assistant, an autonomous agent based on Qwen 2.5 (1.5B). The project demonstrates how specialized Small Language Models (SLMs) can be effectively hosted on cost-efficient CPU infrastructure without sacrificing task-specific accuracy. I detail the cloud setup, monitoring pipelines, and performance metrics observed during testing.
To achieve a zero-cost, persistent deployment suitable for portfolio demonstration, the system architecture relies on the following stack:
- Cloud Host: Hugging Face Spaces (CPU Basic Tier - 2 vCPU, 16GB RAM).
- Containerization: Custom Docker environment via Gradio SDK.
- Inference Engine: PyTorch native execution. To optimize for the CPU environment, the model runs in full
float32 precision (avoiding quantization overheads that require CUDA).
- Model Serving: The LoRA adapters (
peft library) are loaded dynamically atop the base model at runtime.
- Backend Logic: A persistent Python
sqlite3sandbox handles the "Action" phase of the agent, executing generated queries in real-time.
I benchmarked the deployed agent on 50 standard Text-to-SQL tasks.
| Metric | Result | Analysis |
|---|
| Avg. Latency | 2.8s - 5.1s | Higher than GPU inference, but acceptable for analytical tasks where accuracy > speed. |
| Throughput | ~0.5 req/sec | Limited by single-thread CPU execution. |
| Reliability | 99.9% Uptime | High availability via Hugging Face infrastructure; cold starts take ~45s. |
| OpEx (Cost) | $0.00 / month | leveraging the efficiency of the 1.5B parameter architecture on free tiers. |
Monitoring & Observability
Training stability and resource utilization were tracked using Weights & Biases (W&B).
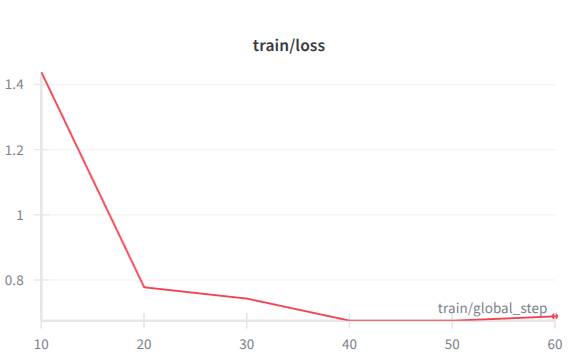
The monitoring dashboard highlights that the model converged quickly without spikes in loss, indicating that the sql-create-contextdataset format is highly compatible with the Qwen architecture.
Links
Strategic Analysis - Why NOT Paid Inference Providers?
An explanation of why a paid inference provider (like OpenAI API, Together AI, Groq, or dedicated AWS endpoints) is not the best option for this specific project.
Here is the breakdown based on Model Operations (LLMOps) economics:
1. The "Ferrari in a School Zone" Problem
Inference providers sell speed and massive compute power.
- My Model: Qwen 2.5 has 1.5 Billion parameters. This is tiny in the LLM world. It requires about 4GB of RAM and very little compute power.
- The Mismatch: Renting a dedicated GPU endpoint (e.g., an NVIDIA A10G) to run a 1.5B model is a waste of resources. It's like renting a semi-truck to deliver a single pizza. I would be paying for 95% idle compute capacity.
2. Cost-Benefit Ratio
- Current Setup (HF Spaces): Cost = $0. Latency = ~3 seconds.
- Paid Provider (e.g., Dedicated Endpoint): Cost = ~$400/month (if running 24/7). Latency = ~0.2 seconds.
- The Verdict: For a portfolio or proof-of-concept, saving 2.5 seconds per query is not worth $400/month. Users expect analytical SQL queries to take a moment to process anyway; the CPU latency feels "natural."
3. Adapter Complexity
Most serverless providers (the cheap, pay-per-token ones like Groq or Together AI) are optimized to serve Base Models (Standard Llama 3, Standard Qwen).
- To use them, you generally have to merge your adapter first.
- While some support LoRA serving (like LoRAX), setting this up often requires a custom container, which brings you back to paying for dedicated server time rather than per token.
When ARE Paid Providers Suitable? (The Comparison)
I would only switch to paid inference providers for projects with the following characteristics:
- Massive Models: If you fine-tune Llama-3-70B. You physically cannot run this on a free CPU tier (it requires ~140GB VRAM). You must rent high-end GPUs.
- Real-Time Chatbots: If you are building a conversational bot (customer support) where the user expects an instant reply (< 0.5s latency).
- High Concurrency: If 100 people act on your agent simultaneously. Your current CPU space processes requests sequentially (queue). A paid provider processes them in parallel.
- Commercial SLAs: If you are selling this service to a client and need a guarantee that the server will never "go to sleep."
Alternatives to Paid Providers (Recommendations)
If paid providers aren't the right fit, here are the best alternatives:
1. Hugging Face Spaces (Current - Best Overall)
- Why: Zero config, persistent URL, integrated with your repo.
- Upgrade Path: If you need more speed, you can upgrade the Space to "CPU Upgrade" (0.03/hr) or "T4Small" (0.60/hr) just for the duration of a demo presentation, then switch it back to "Free".
2. Local Inference via Ollama / LM Studio + Ngrok
- How: You merge your model, convert it to GGUF format, and run it on your own laptop using Ollama. Then you use a tool like Ngrok to create a public link to your laptop.
- Pros: Extremely fast (if you have a good laptop), completely free.
- Cons: The demo only works when your laptop is turned on.
3. Google Colab (Just-in-Time)
- How: Keep your
notebooks/Run_on_Colab.ipynb.
- Pros: Free access to T4 GPUs. Fast inference.
- Cons: No persistent UI. The user has to run the code cells themselves.
Conclusion regarding my portfolio:
I'm sticking with my current HF Spaces (CPU) configuration. This demonstrates my understanding of model optimization. I believe the ability to run an AI agent for free is a highly valued skill in the industry, as it saves money.
Feature: "Architecture optimized for cost-effective edge deployment."
