
Project Introduction 🛡️
Abstract
In today’s digital landscape, hate speech is an escalating concern, often fueling division and unrest across communities. DweshaMukt is an Advanced Multilingual and Multimodal Hate Speech Detection System designed to counteract this issue by harnessing the power of Bidirectional Encoder Representations from Transformers (BERT) alongside cutting-edge Deep Learning and Natural Language Processing (NLP) techniques.
Our system tackles a unique challenge: detecting hate speech within Hinglish—a dynamic blend of Hindi and English—while also supporting Hindi and English languages individually. DweshaMukt leverages a pre-trained BERT model, specially optimized for real-time scenarios, offering robust analysis across a range of media. Its Multilingual and Multimodal architecture enables Hate Speech Detection across diverse content types: Text, Audios, Images, Videos, GIFs, and YouTube Comments.
With an accuracy of 88%, DweshaMukt stands as a promising solution for real-world hate speech detection applications, bridging language and media barriers to ensure safer, more inclusive online spaces.
Index Terms: Hate Speech Detection, BERT, Deep Learning, Natural Language Processing, Multilingual, Multimodal, Hinglish, Real-Time Analysis
Project Timeline
- Start Date: 15th February 2023
- End Date: 12th December 2024
- Total Time Required: 1 Year, 9 Months, and 28 Days
Team Members
| Team Members | GitHub Profile | LinkedIn Profile |
|---|---|---|
| Yash Suhas Shukla | GitHub | |
| Tanmay Dnyaneshwar Nigade | GitHub | |
| Suyash Vikas Khodade | GitHub | |
| Prathamesh Dilip Pimpalkar | GitHub |
Project Guide
| Guide | Gmail |
|---|---|
| Prof. Rajkumar Panchal | rajkumar.panchal@vpkbiet.org |
Completing this project was indeed a challenging task, and we deeply appreciate Prof. Rajkumar Panchal Sir for being our mentor. He guided us through every phase of the project, and his support was invaluable.
Related Work ⚒️
Hate speech detection has become a critical area of research in recent years, driven by the proliferation of social media platforms where users frequently engage in discussions that transcend linguistic boundaries. This has created unique challenges, particularly in detecting hate speech within code-switched and multilingual contexts. Numerous studies have tackled this issue by employing advanced machine learning and deep learning techniques, striving to enhance the accuracy and robustness of hate speech classifiers. This section highlights significant contributions in this field, with a focus on methodologies and outcomes that address the complexities of hate speech detection in mixed-language data.
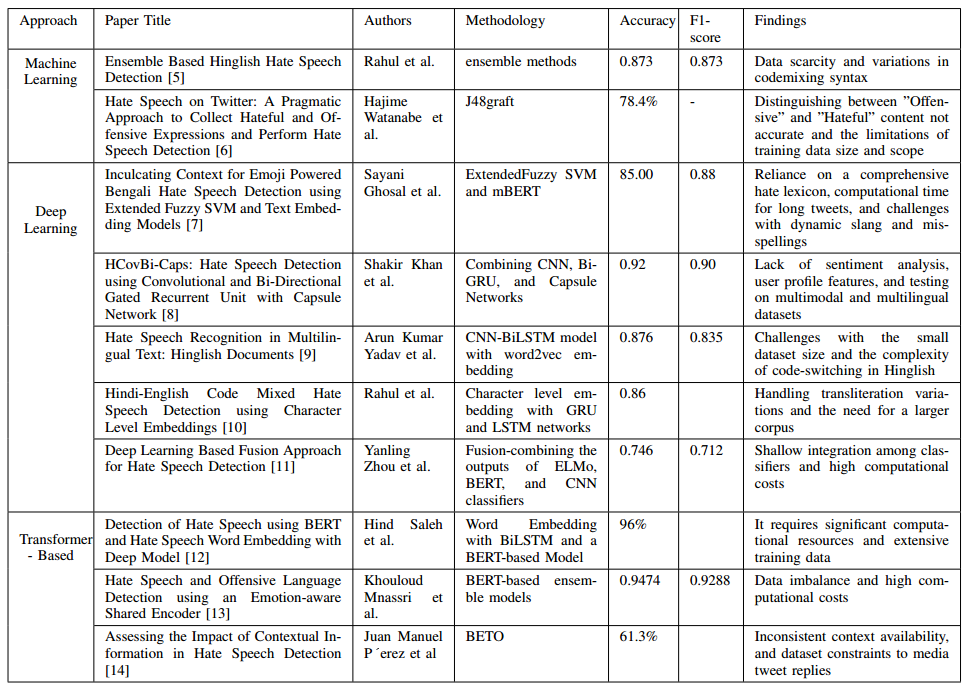
Methodology ✨
Input:
Our model processes multiple media types for hate speech detection:
- Text: Hinglish (Hindi + English) comments, reviews, and posts.
- Emoticons: Graphical icons indicating sentiments or hate speech.
- Images/GIFs: Detected hate symbols using Google Vision API for OCR.
- Audio/Video: Transcriptions analyzed using Google Video Intelligence API.
- YouTube Comments: Both live and non-live comments analyzed.
Text Preprocessing:
- Data Loading: Read CSV datasets into a pandas DataFrame.
- Data Splitting: 70-30 split for training and testing.
- Label Encoding: Convert labels to numerical values.
- Handle Missing Values: Fill or remove null entries.
- Text Normalization: Convert text to lowercase for consistency.
Text Tokenization with BERT:
- Tokenization: Break text into subwords using BERT tokenizer.
- Special Tokens: Add [CLS] and [SEP] tokens.
- Padding/Truncation: Adjust sequences to 128 tokens.
- Attention Masks: Mark actual vs. padded tokens.
Deep Learning Classifier: BERT Model
- Embedding Layer: Converts tokens into dense vectors.
- Encoder Layers: Includes 12 transformer blocks with:
- Multi-head Self-Attention.
- Feed-Forward Networks.
- Layer Normalization & Residual Connections.
- Output Layer: Processes [CLS] token for final logits.
Output:
- Predicted Label: Class with the highest logit selected.
- Evaluation Metrics: Metrics like accuracy, precision, recall, and F1-score are computed.
Conclusion:
This pipeline integrates NLP and DL techniques for detecting hate speech in Hinglish, leveraging BERT for multilingual and code-mixed processing with robust performance across diverse media types.
Backend Preparation 🔧
Mark Models Index
The backend development was an intricate journey, involving months of rigorous research, experimentation, and iterative coding. Each phase contributed to refining the system’s ability to detect hate speech across various input types and languages.
Our Mark Model Index Document provides a comprehensive overview of this journey, showcasing each model’s evolution, from early concepts to the final optimized versions. Dive into the document to see how each model was crafted, tested, and fine-tuned to tackle the challenges of multilingual, multimodal hate speech detection.
Project Backend 🖥️
The backend architecture of DweshaMukt enables the system to classify various forms of input text, audio, video, images, GIFs, and live YouTube comments by first converting each to text before applying the hate speech detection model. Here are the main scenarios handled by the system:
- Text Input: Processes user-entered text directly.
- Audio Input: Converts audio to text using
Google Speech to Text API, then classifies it. - Image Input: Extracts text from images via
Google Cloud Vision API. - GIF Input: Analyzes GIFs using
Google Video Intelligence APIfor text extraction. - Video Input: Extracts audio from videos, transcribes it, and classifies it.
- Live YouTube Video: Fetches live comments using
pytchatlibrary, then classifies them.
The combined code integrates all these scenarios into a unified detection system, including added emoticon-based classification for enhanced accuracy.
Project Dataset 📊
Dataset Overview
The DweshaMukt Dataset is a curated collection of comments carefully selected to support research on hate speech detection. This dataset includes multilingual data in Hinglish, Hindi, and English, capturing various instances of hate and non-hate speech. It is a valuable resource for researchers and developers working on projects aimed at building safer online communities.
Dataset Composition
- Datasets Used: CONSTRAINT 2021 and Hindi Hate Speech Detection (HHSD)
- Total Comments: 22,977
- Hate Comments: 9,705
- Non-Hate Comments: 13,272
Access the Dataset
To ensure responsible and secure usage, access to the DweshaMukt dataset is granted upon request. Please complete the form below to submit your application. We review each request to verify alignment with our project’s objectives.
Note: Approved requests will receive an email with download instructions within 2-3 business days.
Dataset Terms of Use
By requesting access to this dataset, you agree to the following:
- The dataset is strictly for non-commercial, research, or educational purposes.
- You will cite the DweshaMukt project in any publications or presentations that use this dataset.
- Redistribution or sharing of the dataset with unauthorized parties is strictly prohibited.
Project Frontend 🌐
The frontend for this project is built as a Streamlit application, allowing users to interact seamlessly with our hate speech detection models across various input formats. This interface makes it easy to submit and analyze text, audio, video, images, GIFs, and YouTube comments.
Key Features
- Multi-format Detection: Supports text, audio, video, images, GIFs, and YouTube comments.
- Real-time Analysis: Provides immediate feedback on uploaded content.
- User-friendly Interface: Simple navigation with clear instructions and dynamic visual feedback.
- Emoji Detection: Enhanced detection with emoticon analysis.
Main Dashboard
Experiments 🧪
Datasets
We utilized the following datasets:
- CONSTRAINT 2021: Contains labels like non-hostile, fake, defamation, and offensive, which were converted into "hate" (label 0) and "non-hate" (label 1).
- HHSD: Created by Prashant Kapil, focused on hate speech in Hinglish.
Combined Dataset Summary:
- Total Comments: 22,977
- Label Distribution:
- Hate (0): 9,705
- Non-Hate (1): 13,272
Experimental Setting
- Training Environment: Google Colab with T4 GPU.
- Testing Environment: Ubuntu with 16GB RAM and 16GB GPU.
- Framework: TensorFlow.
Hyperparameter Configuration
- Learning Rate: 3e-5
- Epochs: 16
- Batch Size: 64
- Max Sequence Length: 128
- Optimizer: Adam
- Loss Function: Sparse Categorical Crossentropy (logits=True)
- Evaluation Metric: Sparse Categorical Accuracy
Tokenizer and Model Configuration
- BERT Tokenizer:
do_lower_case=True - BERT Model:
num_labels set to the number of unique dataset labels.
This setup enabled efficient training and testing of the hate speech detection model with a focus on robust performance in identifying hate and non-hate content.
Experiment Results ♟️
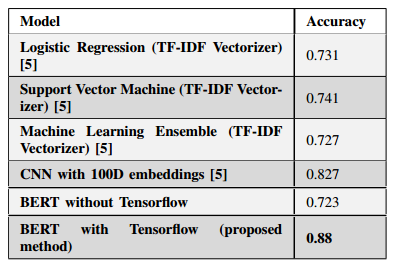
The performance of our model on the test set is summarized in the table below:
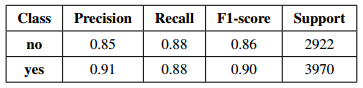
The overall accuracy of our model is 0.88, with a macro average of 0.59 and a weighted average of 0.88.
Experiment Discussion 🗣️
Model Performance
Precision and Recall:
- Hate (Yes): Precision = 0.85, Recall = 0.88
- Non-Hate (No): Precision = 0.91, Recall = 0.88
These results demonstrate the model’s robustness in identifying hate speech, making it highly effective for monitoring social media.
Experiment Conclusion 🦾
This study introduces a multimodal and multilingual hate speech detection model leveraging BERT and advanced NLP techniques. By integrating textual and non-textual data—including images, videos, emoticons, memes, and YouTube comments—the model significantly enhances hate speech detection across diverse contexts. Key highlights include:
- Scalability: Demonstrated effectiveness in real-time environments.
- Advancement: Addresses challenges of multilingual and multimodal inputs, contributing to the mitigation of harmful online content.
Project Telegram Bots 🤖
The DweshaMukt project is integrated with Telegram through a series of specialized bots, each designed to handle a different type of input. This allows users to classify text, audio, images, GIFs, video, and YouTube comments directly within the Telegram platform.
| Bot Name | Description | Watch in Action |
|---|---|---|
| Haspe Text | Processes text input. | |
| Haspe Audio | Processes audio input. | |
| Haspe Image | Processes image input. | |
| Haspe GIF | Processes GIF input. | |
| Haspe Video | Processes video input. | |
| Haspe YouTube | Processes YouTube live comments. |
Each bot seamlessly interacts with the backend, delivering real-time classification results to users. Whether you're analyzing text, multimedia, or live YouTube comments, these bots ensure a versatile and accessible experience for hate speech detection.
Project Representation 🎉
The DweshaMukt project was proudly showcased at the Nexus 1.0 State Level Project Competition on 15th April 2024. Held at the Army Institute of Technology, Pune, this prestigious event was organized by the Department of Information Technology and Computer Engineering under the AIT ACM Student Chapter.
Representing this project at Nexus 1.0 allowed our team to not only share our research and technical achievements but also to raise awareness about the importance of addressing hate speech in today’s digital world. Competitions like these offer valuable platforms for knowledge exchange, constructive feedback, and networking with other innovators, researchers, and industry experts.
Participation Certificates
Below are the participation certificates awarded to our team members for presenting DweshaMukt at Nexus 1.0.
Project Conference 📑
Presenting this project at an international platform has been a milestone achievement for our team. Our research was showcased at the CVMI-2024 IEEE International Conference on Computer Vision and Machine Intelligence, hosted by IIIT Allahabad, Prayagraj on 19th and 20th October 2024. The conference offered a valuable opportunity for knowledge exchange with global experts and researchers, fostering discussions on the latest advancements in computer vision and machine learning.
Key Highlights
- Research Paper Submission: Our research paper on this project was successfully submitted to IEEE.
- Conference Attendance: Represented by Yash Shukla and Prof. Rajkumar Panchal, the conference participation strengthened our network and insights within the academic community.
Conference Report:
The conference report details our experiences and learnings from the event, including keynote sessions and other relevant presentations on emerging research trends. To read the Conference Report, press the button below.
To view the entire official IEEE Research Paper Copy downloaded from IEEE Website, press the button below.
Project Research Paper:
To read our Research Paper on IEEE Website, press the button below.
To view the entire official IEEE Research Paper Copy downloaded from IEEE Website, press the button below.
Conference Participation Certificates
The following certificate was awarded for my participation and representation at CVMI-2024:

Project Copyright ©️
Securing copyright for this project marked an important milestone in safeguarding our innovation and intellectual property. Copyrighting our project not only protects the unique aspects of our hate speech detection system but also reinforces our commitment to responsible AI research. By copyrighting this idea, we ensure that the methods, models, and technological advances developed through this project remain attributed to our team.
Copyright Publication Date: 25th October 2024
Certificate of Copyright

Above Copyright certificate has been slightly edited to hide the personal details of the authors involved in the Copyright.
Project Funding 💸
This project was generously funded by Vidya Pratishthan's Kamalnayan Bajaj Institute of Engineering and Technology College, whose support played a pivotal role in enabling our team to bring this ambitious vision to life. This funding allowed us to access essential resources, collaborate with experts, and ensure high-quality development across every phase of the project.
Funding Breakdown
| Sr No | Demand Reason | Demand Cost |
|---|---|---|
| 1 | Google Colab Pro | 1025 |
| 2 | Online Courses | 2684 |
| 3 | Project Presentation Competition | 500 |
| 4 | Stationary Cost | 500 |
| Total | 4709 |
Funding Certificate

The above provided certificate is custom designed and not officially presented by the college itself. We extend our heartfelt gratitude to VPKBIET College for their trust and support. Their investment in this project has been invaluable in pushing the boundaries of AI-driven hate speech detection.
Future Scope 🔮
- Dataset Expansion: Broaden the dataset to include more languages and cultural contexts for improved generalizability.
- Feature Enhancement: Incorporate sentiment analysis and user profile features to boost accuracy.
- Real-Time Integration: Develop more transformer-based models for real-time detection systems to ensure timely and effective hate speech mitigation.
Acknowledgements 🔖
- I am thankful to ChatGPT for insights, suggestions and provision of resources. It helped in refining ideas and aiding research throughout this work.
- I am thankful to Vidya Pratishthan's Kamalnayan Bajaj Institute of Engineering and Technology Baramati (VPKBIET) College for providing funding for this project.
Project Report 📔
This project report is extremely detailed in terms of all the progress made till date in the project.
The project report can be viewed by pressing the button below.
References 📃
-
[1] https://library.fiveable.me/key-terms/ap-gov/hate-speech
-
[2] Bansod, Pranjali Prakash, ”Hate Speech Detection in Hindi” (2023).
Master’s Projects. 1265. DOI: https://doi.org/10.31979/etd.yc74-7qas,
https://scholarworks.sjsu.edu/etd projects/1265 -
[3] Mohit Bhardwaj and Md Shad Akhtar and Asif Ekbal and Amitava
Das and Tanmoy Chakraborty, ”Hostility Detection Dataset in Hindi,”
in arXiv, 2020, eprint-2011.03588. -
[4] P. Kapil, G. Kumari, A. Ekbal, S. Pal, A. Chatterjee and B. N.
Vinutha, ”HHSD: Hindi Hate Speech Detection Leveraging Multi-Task
Learning,” in IEEE Access, vol. 11, pp. 101460-101473, 2023, doi:
10.1109/ACCESS.2023.3312993. -
[5] V. Rahul, V. Gupta, V. Sehra, and Y. R. Vardhan, ”Ensemble Based
Hinglish Hate Speech Detection,” 2021 5th International Conference on
Intelligent Computing and Control Systems (ICICCS), Madurai, India,
2021, pp. 1800 1806, doi: 10.1109/ICICCS51141.2021.9432352. -
[6] H. Watanabe, M. Bouazizi, and T. Ohtsuki, ”Hate Speech on Twitter: A
Pragmatic Approach to Collect Hateful and Offensive Expressions and
Perform Hate Speech Detection,” IEEE Access, vol. 6, pp. 13825-13835,
2018, doi: 10.1109/ACCESS.2018.2806394. -
[7] S. Ghosal, A. Jain, D. K. Tayal, V. G. Menon, and A. Kumar, ”Inculcating
Context for Emoji Powered Bengali Hate Speech Detection using
Extended Fuzzy SVM and Text Embedding Models,” ACM Transactions
on Asian and Low- Resource Language Information Processing,
accepted March 2023, doi: 10.1145/3589001. -
[8] S. Khan et al., ”HCovBi-Caps: Hate Speech Detection Using Convolutional
and Bi-Directional Gated Recurrent Unit With Capsule Network,” IEEE Access,
vol. 10, pp. 7881-7894, 2022, doi: 10.1109/ACCESS.2022.3143799. -
[9] A. K. Yadav, A. Kumar, S. ., K. ., M. Kumar, and D. Yadav,
”Hate Speech Recognition in multilingual text: Hinglish Documents,”
TechRxiv, Preprint, 2022, doi: 10.36227/techrxiv.19690177.v1. -
[10] V. Rahul, V. Gupta, V. Sehra, and Y. R. Vardhan, ”Hindi-English Code
Mixed Hate Speech Detection using Character Level Embeddings,”
2021 5th International Conference on Computing Methodologies and
Communication (ICCMC), Erode, India, 2021, pp. 1112 1118, doi:
10.1109/ICCMC51019.2021.9418261. -
[11] Y. Zhou, Y. Yang, H. Liu, X. Liu, and N. Savage, ”Deep Learning Based
Fusion Approach for Hate Speech Detection,” IEEE Access, vol. 8, pp.
128923-128929, 2020, doi: 10.1109/ACCESS.2020.3009244. -
[12] H. Saleh, A. Alhothali, and K. Moria, ”Detection of Hate Speech
using BERT and Hate Speech Word Embedding with Deep Model,”
Applied Artificial Intelligence, vol. 37, no. 1, pp. 2166719, 2023, doi:
10.1080/08839514.2023.2166719. -
[13] K. Mnassri, P. Rajapaksha, R. Farahbakhsh, and N. Crespi,
.08777
”Hate Speech and Offensive Language Detection using
an Emotion-aware Shared Encoder,” arXiv
[cs.CL],2023.[Online].https://doi.org/10.48550/arXiv.2302.0 8777 -
[14] J. M. Perez, H. Saleh, A. Alhothali, and K. Moria, ”Assessing the Impact ´
of Contextual Information in Hate Speech Detection,” IEEE Access, vol.
11, pp. 30575-30590, 2023, doi: 10.1109/ACCESS.2023.3258973. -
[15] https://chat.openai.com.
License 📄
This project is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
By using this project, you agree to give appropriate credit, not use the material for commercial purposes without permission, and share any adaptations under the same license.
Attribution should be given as:
"DweshaMukt Project by DweshaMukt Team (https://github.com/StudiYash/DweshaMukt)"
Quick Overview regarding the permissions of usage of this project can be found on LICENSE DEED : CC BY-NC-SA 4.0
![]()
Made with ❤️ by DweshaMukt Team