Introduction
Speech is the most direct form of communication, and in the context of the Holy Qur'ān, speech-to-speech recognition systems hold immense potential to ensure accurate recitation. These systems aim to validate recitation while adhering to Tajweed rules, overcoming challenges like phonetic precision, grammar compliance, and real-time error correction.
Project Domain
This project focuses on developing a real-time Qur'ānic recitation recognition system. It emphasizes the Hafs from A’asim narration and ensures accurate pronunciation based on Tajweed rules. The system will provide corrective feedback, promoting recitation accuracy.
Problem Identification
Key challenges include:
Limited Dataset: Insufficient data diversity affects generalization.
Error Detection: Lack of systems addressing pronunciation and grammatical errors.
Bias: Predominantly male reciters in datasets limit performance for other demographics.
Generalization: Inadequate adaptability across various Surahs and reciters.
Real-Time Feedback: Absence of systems offering immediate error correction.
Speech-to-Speech Gap: Most systems focus on speech-to-text, neglecting direct speech-to-speech correction.
Goals and Objectives
Speech-to-Speech Recognition: Focus on Tajweed compliance and error correction.
Dataset Diversity: Include diverse voices (gender, age) for improved performance.
Real-Time Feedback: Provide instant pronunciation corrections.
Inclusivity: Address gender and age biases with diverse datasets.
Comprehensive Feedback: Detect and correct clear errors (لحن جَليّ) effectively.
Scope of Study
Develop a robust, AI-powered system that recognizes and corrects Qur'ānic recitation errors in real-time. Using deep learning, particularly LSTM models, the system will adapt to diverse voices, provide instant feedback, and ensure compliance with Tajweed rules. The project promotes inclusivity by supporting reciters of all demographics.
Process Model
LSTM is used for its strengths in:
Capturing speech sequences for accurate recitation feedback.
Learning complex phonetic patterns of Tajweed rules.
Adapting to diverse accents and recitation styles.
Providing real-time error detection and correction.
Methodology
This section outlines the plan to achieve speech-to-speech recognition for the Holy Qur'ān using deep learning, focusing on data preparation and LSTM model implementation.
Data Collection
A representative dataset was established as input for the LSTM model, ensuring diversity and adherence to Qur'ānic recitation standards.
We used purposive sampling to create a dataset of Quranic recitations from 60 reciters (50 scholars, 125 males, 125 females). The dataset included five Surahs, each recited in different styles (Tadweer, Hadr, Tahqiq), totaling 300 recordings. These included both correct and incorrect recitations, with clear pronunciation errors (Lahn e Jali).
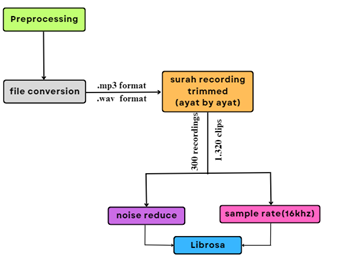
Preprocessing
The audio files were converted from .mp3 to .wav, trimmed into 1,320 clips, and standardized to a 16,000Hz sample rate. Noise reduction was applied using Librosa, and the data was organized into CSV files for analysis.
Data Training and Feature Extraction
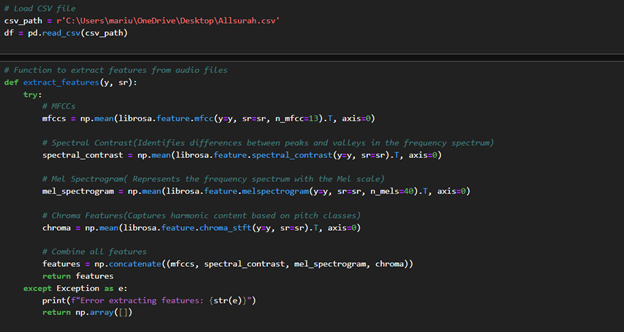
For model training, we extracted several features from the audio data:
MFCCs: 13 features (12 coefficients + 1 energy feature).
Spectral Contrast: 8 features measuring amplitude differences in the spectrum.
Mel Spectrogram: 40 features representing short-term power.
Chroma Features: 12 features capturing pitch class energy.
These features (totaling 73) were used as inputs for the speech recognition model to enhance audio signal representation and analysis.
Data Reshaping and Model Preparation
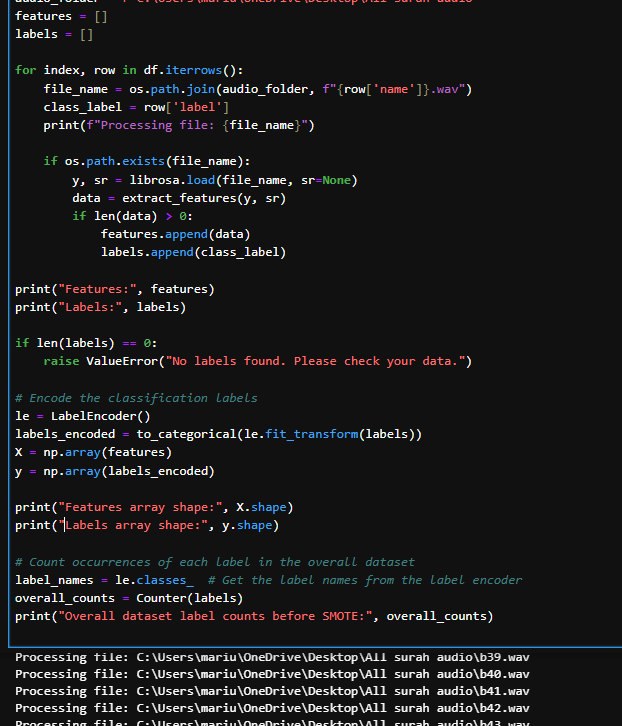
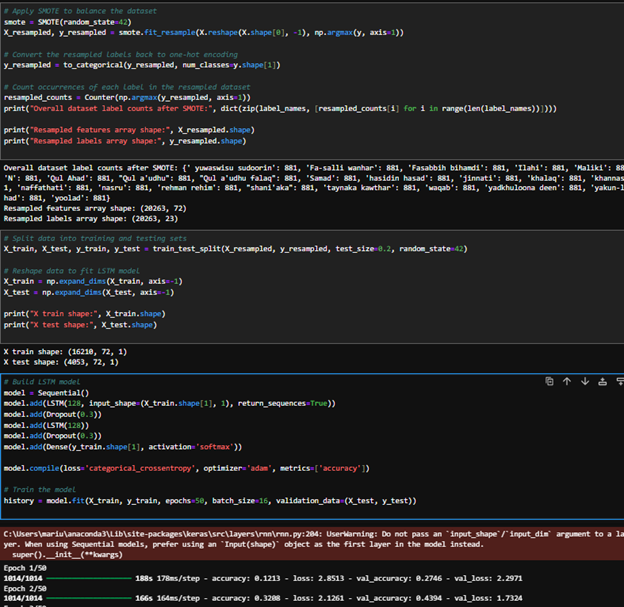
The data was reshaped into a feature vector of 73 attributes, with class labels representing 6 categories: Bismillah and five Surahs. Labels were encoded using Label Encoder and one-hot encoded using to categorical. SMOTE was applied to balance the class distribution and improve model performance. The dataset was split into training (80%) and testing (20%) subsets.
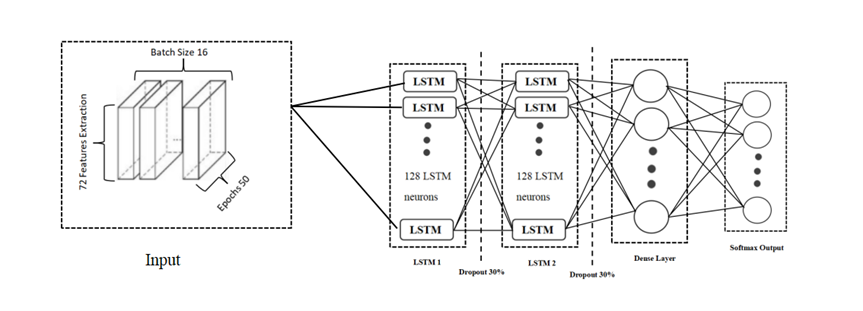
LSTM Model
The LSTM model included:
- First LSTM Layer: 128 units to capture long-term dependencies.
- Dropout Layer: 30% dropout rate to prevent overfitting.
- Second LSTM Layer: 128 units for further sequence processing.
- Second Dropout Layer: 30% dropout.
- Dense Layer: Output size based on the number of classes with softmax activation.
- Output Layer: Softmax activation for classification.
Total neurons: 256 (128 + 128), suited for sequential audio data processing.
Results
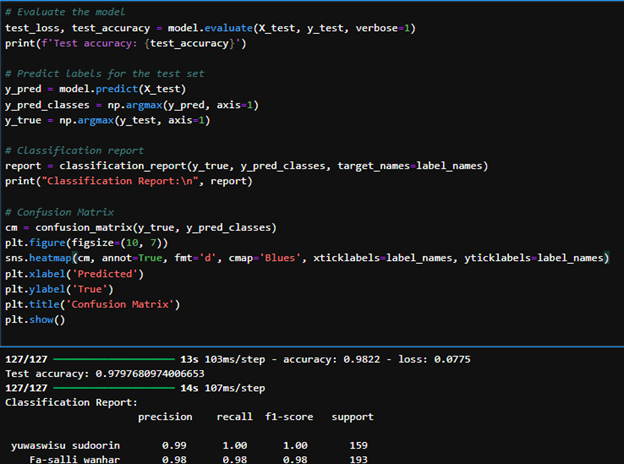
The model achieved remarkable performance, with a test accuracy of 97.6%. Key metrics included:
Precision: 99%
Recall: 93%
F1-Score: 96%
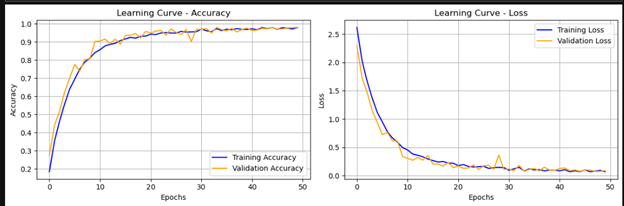
These results highlight the model's strong ability to classify audio samples from various Surahs accurately, confirming its robustness and reliability.
Code Implementation
libraries and modules
Feature Extraction from Audio Files
Data Preparation for Audio Classification
Model Training
Model Evaluation and Visualization
Conclusion & Future Work
The model achieved 97.6% accuracy in classifying Surah audio, with strong precision, recall, and F1-score. SMOTE addressed class imbalance, and LSTM effectively captured audio dependencies. Future work includes detecting minor errors and adding more Surahs to enhance the model's diversity and robustness.