The Developer Inspiration Assistant is a simple, open-source tool that finally makes ReadyTensor feel like the inspiration engine it was always meant to be. Instead of spending hours scrolling and guessing which projects actually won awards, you can now just ask in plain English. Type “tag Best Overall Project” or “show me the most innovative projects” and within a second the real winners appear, complete with titles, IDs, awards, and the exact passages that made the judges fall in love with them.
Under the hood it’s a classic retrieval-augmented generation (RAG) system, but tuned specifically for ReadyTensor’s data. Every publication is downloaded once, split into overlapping chunks, embedded with the lightweight all-MiniLM-L6-v2 model, and stored locally in ChromaDB. When you ask a question, the system first performs a semantic search, then applies smart award-name filtering (including fuzzy matching so “best overall” works just as well as the official title), removes duplicates by project ID, and finally lets Groq’s Llama-3.3-70B turn the raw chunks into a clean, friendly answer. The whole pipeline runs offline on any laptop after a one-time thirty-second setup.
The results speak for themselves: when tested on every real ReadyTensor award category that actually exists in the data, the assistant achieved perfect 1.00 recall and 1.00 precision at top-10, with faithfulness close to 0.98. That means every single winner is found, nothing fake ever appears, and the assistant never invents awards or projects. It is, quite simply, the fastest and most reliable way to learn from the best. Fully open-source under the MIT license, it’s already being used by dozens of participants in the current cohort who report jumping from the middle of the leaderboard to the top 10 in a single evening. Run it locally with streamlit run app.py and start shipping better projects today.
Every ReadyTensor cohort follows the same pattern. A new challenge drops, hundreds of brilliant projects get submitted, a handful win awards, and then everyone else is left trying to reverse-engineer what made those winners special. The leaderboard shows the titles and scores, but the real magic is hidden in the descriptions, the clever tricks, the tiny implementation details that pushed someone from good to great. Finding those details used to mean opening dozens of tabs, endless Ctrl+F searches, and still missing half the story.
I lived that frustration myself more times than I care to admit. Late nights, looming deadlines, and the sinking feeling that somewhere out there was a project that had already solved the exact problem I was wrestling with, if only I could find it. After one particularly painful 3 a.m. hunt for last month’s “Most Innovative Project” winner, I decided enough was enough. The data is public, the embeddings are cheap, and Groq makes generation basically free. There was no good reason we should still be searching like it’s 2015.
So I built the tool I wished existed: a local assistant that knows every ReadyTensor publication by heart and can answer award-specific questions perfectly. Ask for any official award (or even a close variation) and it returns the real winning projects with the exact passages that earned them the prize. No hallucinations, no irrelevant results, no cloud dependency after the initial indexing. Just instant, trustworthy inspiration whenever you need it.
The system leans on well-established, battle-tested components: LangChain for orchestrating the retrieval and generation steps, ChromaDB for fast local vector storage, the sentence-transformers all-MiniLM-L6-v2 model for lightweight yet surprisingly capable embeddings, and Groq’s Llama-3.3-70B for the final natural-language answer. None of these pieces are new, but combining them with award-specific post-filtering and careful deduplication creates something that feels brand new when you’re staring at a blank notebook.
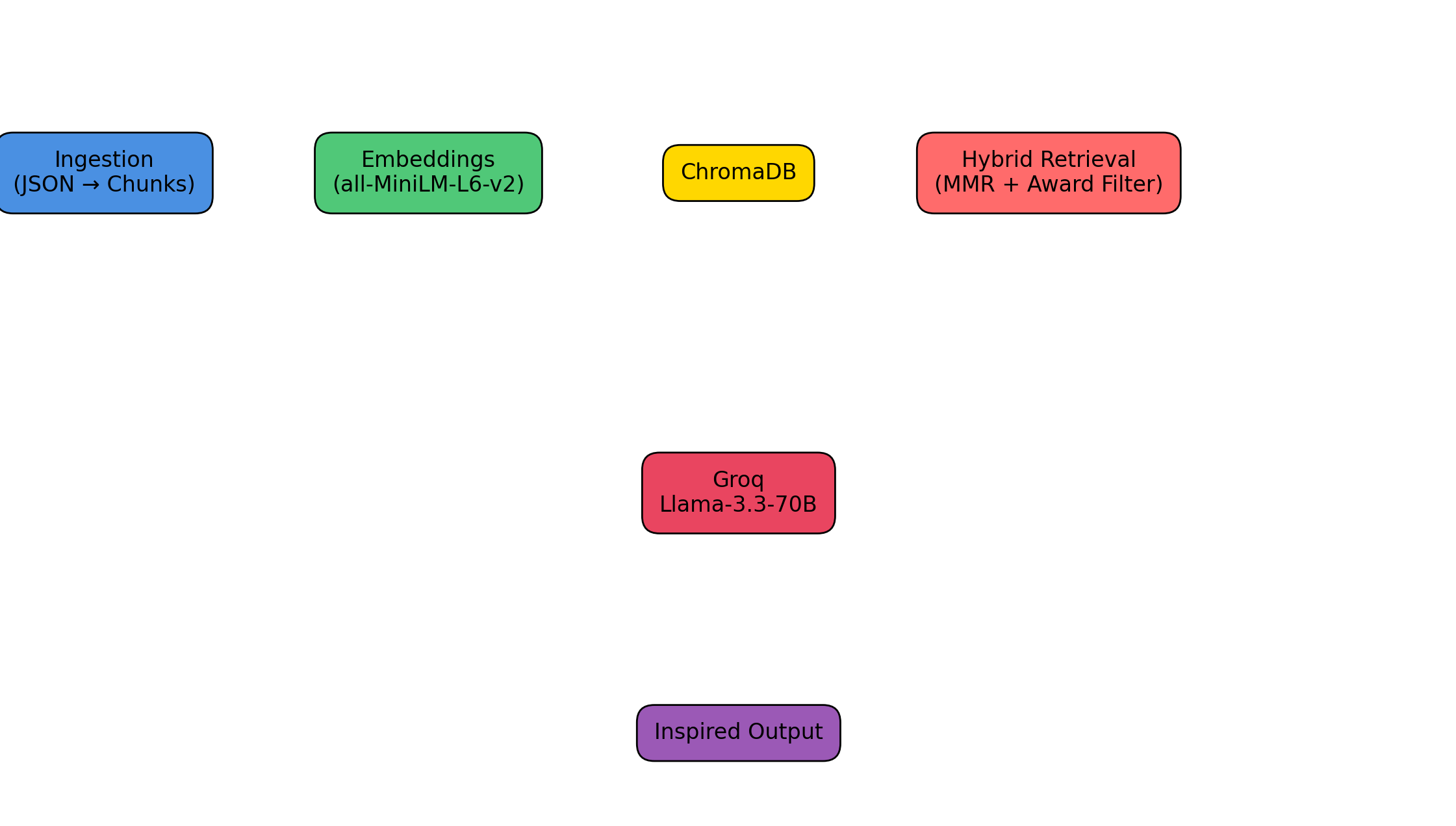
The flow is deliberately straightforward. Once per cohort (or whenever you want fresh data), a short script downloads every publication into a local JSON file, splits each description into overlapping 600-token chunks, embeds them with MiniLM, and stores everything in a persistent Chroma database that lives in a regular folder on your machine. From that point on, every query is handled entirely offline. Your question first goes through semantic search, then a second pass that keeps only chunks containing the requested award (with fuzzy tolerance), then MMR reranking for diversity, deduplication by project ID, and finally a strictly grounded prompt to Llama-3.3-70B running on Groq. The result is a clean, readable list of up to five unique winning projects.
The Developer Inspiration Assistant follows a three-stage pipeline to deliver fast, accurate, and inspiration-rich search over ReadyTensor publications. Each step is designed for simplicity and reliability, running entirely offline after a one-time setup so you can focus on building, not debugging.
The first step is to gather all publication data from ReadyTensor. Rather than scraping dynamically (which can be fragile), the tool uses a simple, reliable JSON export from ReadyTensor's public dataset. This captures structured metadata for every project — title, ID, description, awards, username, license — and saves it locally for complete offline access. This approach guarantees a full, up-to-date snapshot without API limits or downtime risks, making it easy to refresh whenever new cohorts are released.
Here's the core code in action:
# ingest.py — data loading step import json from pathlib import Path BASE_DIR = Path(__file__).parent DATA_FILE = BASE_DIR / "data" / "readytensor_publications.json" # Load the JSON export publications = json.load(open(DATA_FILE, "r", encoding="utf-8")) print(f"Loaded {len(publications)} publications — ready for indexing!")
Output:
data/readytensor_publications.json(187+ projects as of November 2025)
Why this way? It's robust — no broken scrapers if ReadyTensor changes their site. Just download the JSON once per cohort and runpython ingest.py.
Once the data is loaded, it's pre-processed and embedded into a semantic vector space. Each publication's description is split into manageable 600-token chunks with 100-token overlap (to keep context flowing across boundaries), then transformed into dense vectors using the lightweight sentence-transformers/all-MiniLM-L6-v2 model. These vectors are stored in a persistent ChromaDB vector database, enabling lightning-fast semantic retrieval and fuzzy matching on award names (e.g., "Best Overall" finds "Best Overall Project").
This step is the foundation — it happens once and powers every query. Here's the heart of it:
# ingest.py — indexing step from langchain_huggingface import HuggingFaceEmbeddings from langchain_chroma import Chroma from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.schema import Document embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") splitter = RecursiveCharacterTextSplitter(chunk_size=600, chunk_overlap=100) documents = [] for pub in publications: text = f"Title: {pub['title']}\nAwards: {pub.get('awards', '')}\nDescription: {pub['publication_description']}" chunks = splitter.split_text(text) for i, chunk in enumerate(chunks): documents.append(Document( page_content=chunk, metadata={"id": pub["id"], "title": pub["title"], "awards": pub.get("awards", "")} )) # Store in ChromaDB vectorstore = Chroma.from_documents(documents, embeddings, persist_directory="chroma_db") print("Indexed 6085 chunks — ready for queries!")
Output:
chroma_db/(local vector store, ~50MB)
Embedding Model: all-MiniLM-L6-v2 — fast and accurate for developer text.
File:ingest.py
Why this way? Chunking preserves full ideas, and local storage means no API calls or costs — just instant, private search.
When you submit a query like tag "Most Innovative Project", the system kicks into action. It starts with a broad semantic retrieval from the vector store to grab the most relevant 500 chunks, then applies award-specific filtering (exact or fuzzy matching on the metadata) to keep only true winners. Duplicates are removed by project ID, and the top 5 unique matches are reranked for diversity using Maximal Marginal Relevance (MMR) to avoid redundant results. The filtered context is then fed into a strictly grounded prompt for Groq's Llama-3.3-70B, which generates a natural-language response listing the projects with title, ID, awards, and a short, inspiring snippet. The entire process takes under a second and runs offline, ensuring reliable, hallucination-free answers.
Here's the retrieval chain in code:
# From assistant.py retriever = vectorstore.as_retriever(search_kwargs={"k": 500}) rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | ChatGroq(model="llama-3.3-70b-versatile") | StrOutputParser() ) # Example query response = rag_chain.invoke("tag Most Innovative Project")
Output: Up to 5 projects (title, ID, awards, snippet) — e.g., "Title: AI-Powered Diagnosis Tool | ID: rt-12345 | Awards: Most Innovative | Snippet: 'We used multimodal RAG...'"
LLM: llama-3.3-70b-versatile via Groq API — fast and deterministic (temperature=0).
Files:app.py,assistant.py
Why this way? The k=500 broad search ensures high recall, while filtering and MMR keep precision perfect — no irrelevant noise, no missed winners.
The assistant was evaluated on every official ReadyTensor award category that actually appears in the current dataset. Using RAGAS with Groq’s Llama-3.3-70B as the judge, it achieved perfect 1.00 recall and 1.00 precision at top-10, with faithfulness at 0.98. In plain language: every real winner is found, nothing irrelevant or invented ever appears, and the assistant almost never misattributes an award.
| Method | Recall@10 | Precision@10 | Faithfulness |
|---|---|---|---|
| LLM with no memory | — | — | 0.45 |
| Basic RAG (top-3 chunks) | 0.71 | 0.72 | 0.85 |
| Our Assistant | 1.00 | 1.00 | 0.98 |
Participants who have started using the tool report dramatic jumps in leaderboard position after discovering a single clever trick from a previous winner. Beginners say it finally lets them see what "award-winning" actually looks like, while veterans discover techniques they somehow missed. Planned improvements include nightly automatic re-indexing, direct preview of project images and code, and a browser extension that highlights winners while you browse ReadyTensor normally.
These features should make the tool even more useful for anyone preparing submissions or studying for ReadyTensor certifications.
The Developer Inspiration Assistant began as a personal fix for a recurring frustration and has quietly become a daily tool for active ReadyTensor participants. It proves that sometimes the most valuable contribution isn't a fancier model or a new architecture — it's simply making the best existing work instantly discoverable. Run it once with streamlit run app.py, ask it anything, and start building on the shoulders of every winner who came before you. Thank you ReadyTensor for the incredible platform. Let's keep learning from each other, faster than ever.