Reinforcement learning (RL) has emerged as a powerful method for training AI agents to make decisions in dynamic environments. The Gym LunarLander-v2 environment serves as a problem where an agent must control a lander’s thrusters to land safely. This project explores Deep Q-Learning, an extension of Q-learning that uses deep neural networks to calculate Q-values, allowing the agent to generalize better over continuous state spaces.
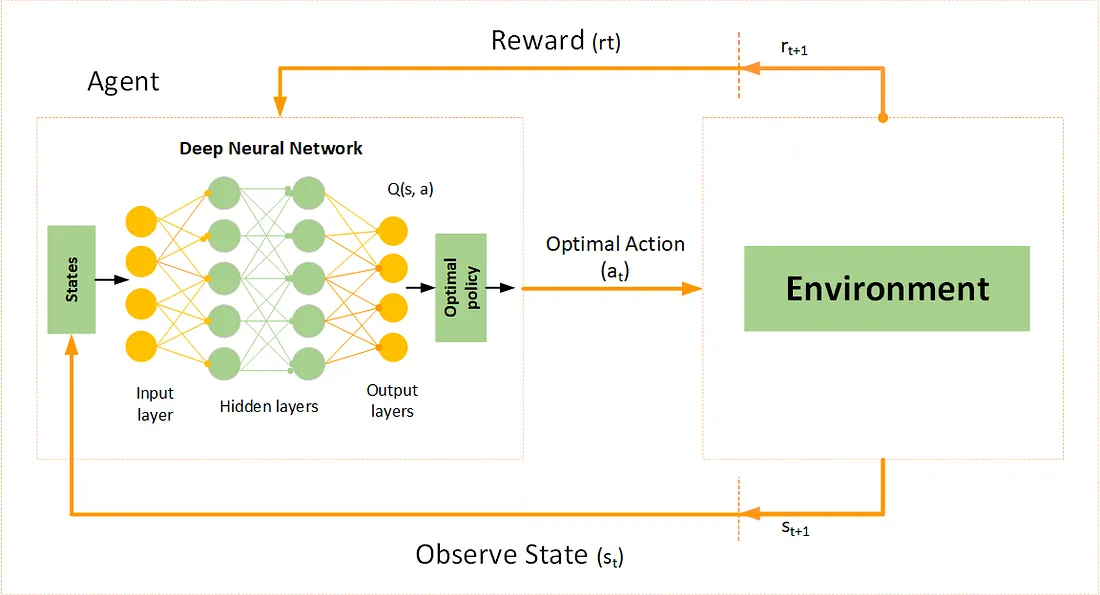
For more information on deep q-learning view this website: https://medium.com/@samina.amin/deep-q-learning-dqn-71c109586bae
For more information on traditional reinforcement learning view this website: https://www.geeksforgeeks.org/what-is-reinforcement-learning/
Configuring the environment in Python:
import gym class Environment(): """ The Environment class provides a simple interface for interacting with OpenAI Gym environments. It provides information about the state shape, state size, and the number of available actions in the environment. Attributes: env (gym.Env): An instance of the 'LunarLander-v2' environment created using OpenAI Gym. state_shape (tuple): The shape of the state space in the environment. state_size (int): The size of the state space in the environment. number_actions (int): The number of available actions in the environment. Methods: __init__(): Constructor method for initializing the Environment instance. Example: # Create an instance of the Environment class env_instance = Environment() """ def __init__(self, env : str) -> None: """ Initializes the Environment instance with the specified OpenAI Gym environment and extracts information about the state shape, state size, and number of actions. Parameters: env (str, optional): The ID of the OpenAI Gym environment to initialize. Defaults to 'LunarLander-v2'. Example: # Create an instance of the Environment class with a custom environment ID env_instance = Environment(env='LunarLander-v2') """ self.env : gym.Env = gym.make(id=env) self.state_shape : tuple[int, ...] | None = self.env.observation_space.shape self.state_size : int = self.state_shape[0] #type: ignore self.number_actions : int = self.env.action_space.n #type: ignore print(f'State Shape: {self.state_shape}\nState Size: {self.state_size}\nNumber of Actions: {self.number_actions}') def reset(self) -> tuple: """ Resets the environment to its initial state and returns the initial observation. Returns: observation: The initial observation/state of the environment. Example: # Reset the environment and get the initial observation initial_observation = env_instance.reset() """ return self.env.reset() def step(self, action) -> tuple: """ Takes an action in the environment and returns the next observation, reward, and done flag. Parameters: action: The action to be taken in the environment. Returns: observation: The next observation/state of the environment. reward: The reward received from the environment. done: A flag indicating whether the episode is done. Example: # Take an action in the environment and get the next observation, reward, and done flag next_observation, reward, done = env_instance.step(selected_action) """ return self.env.step(action)
For more information on the lunar lander environment, of if you want to try it yourself visit this website: https://www.gymlibrary.dev/environments/box2d/lunar_lander/
Deep Q-Learning is an extension of traditional Q-learning that employs a neural network to approximate the Q-values for different state-action pairs. In this implementation, a feedforward neural network is used to estimate the Q-function, mapping the observed state space to expected future rewards. The network is trained using a mean squared error loss function, minimizing the difference between predicted Q-values and target Q-values derived from the Bellman equation.
Building the neural network in Python:
from torch.nn import functional as F from torch import nn import torch class NeuralNetwork(nn.Module): """ The NeuralNetwork class defines a simple feedforward neural network architecture for a given reinforcement learning task. Attributes: state_size (int): The size of the input state space. action_size (int): The size of the output action space. seed (int): A seed for random number generation. Default is 42. Methods: __init__(state_size, action_size, seed): Constructor method for initializing the NeuralNetwork instance with the specified state size, action size, and seed. forward(state): Defines the forward pass of the neural network. Example: # Create an instance of the NeuralNetwork class neural_net = NeuralNetwork(state_size=8, action_size=4) """ def __init__(self, state_size : int, action_size : int, seed : int = 42) -> None: """ Initializes the NeuralNetwork instance with the specified state size, action size, and seed. Parameters: state_size (int): The size of the input state space. action_size (int): The size of the output action space. seed (int, optional): A seed for random number generation. Default is 42. Example: # Create an instance of the NeuralNetwork class with specific state and action sizes neural_net = NeuralNetwork(state_size=8, action_size=4) """ super(NeuralNetwork, self).__init__() self.state_size : int= state_size self.seed : torch.Generator = torch.manual_seed(seed) self.fc1 : nn.Linear = nn.Linear(in_features=state_size, out_features=64) self.fc2 : nn.Linear = nn.Linear(in_features=self.fc1.out_features, out_features=64) self.fc3 : nn.Linear = nn.Linear(in_features=self.fc2.out_features, out_features=action_size) def forward(self, state): """ Defines the forward pass of the neural network. Parameters: state (torch.Tensor): The input state tensor. Returns: torch.Tensor: The output tensor representing the Q-values for each action. Example: # Forward pass with a given state tensor output = neural_net.forward(torch.tensor([1.0, 2.0, 3.0])) """ x : torch.Tensor = self.fc1(state.view(-1, self.state_size)) x = F.relu(input=x) x = self.fc2(x) x = F.relu(input=x) return self.fc3(x)
To enhance stability and prevent divergence in training, two key techniques are incorporated: experience replay and target networks. Experience replay involves storing past experiences in a replay buffer and randomly sampling them during training. This reduces correlations between consecutive experiences and leads to more stable learning. The target network, a separate copy of the Q-network, is updated less frequently to provide consistent Q-value targets, further improving stability.
Implementing the memory replay in Python:
import random import numpy import torch class ReplayMemory(object): """ The ReplayMemory class represents a replay memory buffer for storing and sampling experiences for reinforcement learning. Attributes: capacity (int): The maximum capacity of the replay memory. device (torch.device): The device on which the memory is stored (CPU or CUDA). memory (list): List to store experiences. Methods: __init__(capacity): Constructor method for initializing the ReplayMemory instance. push(event): Adds an experience tuple to the replay memory. sample(batch_size): Randomly samples a batch of experiences from the replay memory. Example: # Create an instance of the ReplayMemory class with capacity 1000 memory = ReplayMemory(capacity=1000) """ def __init__(self, capacity : int) -> None: """ Initializes the ReplayMemory instance with the specified capacity. Parameters: capacity (int): The maximum capacity of the replay memory. Example: # Create an instance of the ReplayMemory class with capacity 1000 memory = ReplayMemory(capacity=1000) """ self.device : torch.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') self.capacity : int = capacity self.memory : list = [] def push(self, event : tuple) -> None: """ Adds an experience tuple to the replay memory. Parameters: event (tuple): The experience tuple to be added. Example: # Add an experience tuple to the replay memory memory.push((state, action, reward, next_state, done)) """ self.memory.append(event) if len(self.memory) > self.capacity: del self.memory[0] def sample(self, batch_size : int) -> tuple: """ Randomly samples a batch of experiences from the replay memory. Parameters: batch_size (int): The number of experiences to be sampled in a batch. Returns: tuple: A tuple containing PyTorch tensors for states, next_states, actions, rewards, and dones. Example: # Sample a batch of experiences from the replay memory states, next_states, actions, rewards, dones = memory.sample(batch_size=64) """ experiences : list = random.sample(self.memory, k=batch_size) states : torch.Tensor = torch.from_numpy(numpy.vstack([e[0] for e in experiences if e is not None])).float().to(self.device) actions : torch.Tensor = torch.from_numpy(numpy.vstack([e[1] for e in experiences if e is not None])).long().to(self.device) rewards : torch.Tensor = torch.from_numpy(numpy.vstack([e[2] for e in experiences if e is not None])).float().to(self.device) next_states : torch.Tensor = torch.from_numpy(numpy.vstack([e[3] for e in experiences if e is not None])).float().to(self.device) dones : torch.Tensor = torch.from_numpy(numpy.vstack([e[4] for e in experiences if e is not None]).astype(numpy.uint8)).float().to(self.device) return states, next_states, actions, rewards, dones
Exploration-exploitation balance is maintained using an epsilon-greedy strategy, where the agent initially explores by taking random actions and gradually shifts toward exploiting learned policies as training progresses. The reward structure is carefully designed to encourage soft landings while penalizing crashes, inefficient fuel usage, and unstable orientations. Through iterative updates, the agent refines its decision-making process and improves its ability to land safely.
Building the AI agent in Python:
from neural_network import NeuralNetwork from replay_memory import ReplayMemory from hyperparameters import HyperParameters from torch import optim from torch.nn import functional as F from torch import nn import torch import random import numpy parameters = HyperParameters() class Agent: """ Represents a reinforcement learning agent using Deep Q-Networks. Args: - state_size (int): The size of the state space. - action_size (int): The number of possible actions. Attributes: - device (torch.device): The device used for computation (GPU if available, else CPU). - state_size (int): The size of the state space. - action_size (int): The number of possible actions. - local_qnet (NeuralNetwork): The local Q-network for estimating Q-values. - target_qnet (NeuralNetwork): The target Q-network for stable learning. - optimizer (optim.Adam): The Adam optimizer for updating the local Q-network. - memory (ReplayMemory): Replay memory for storing experiences. - time_step (int): Counter for tracking time steps. Methods: - step(state, action, reward, next_state, done): Records a transition in the replay memory and updates the Q-network. - action(state, epsilon): Selects an action using an epsilon-greedy strategy. - learn(experiences, gamma): Performs a Q-learning update using a batch of experiences. - soft_update(local_model, target_model, interpolation_parameter): Updates target model parameters with a soft update. """ def __init__(self, state_size : int, action_size : int) -> None: """ Initializes the Agent with the given state and action sizes. """ self.device : torch.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') self.state_size : int = state_size self.action_size : int = action_size self.local_qnet : NeuralNetwork = NeuralNetwork(state_size, action_size).to(self.device) self.target_qnet : NeuralNetwork = NeuralNetwork(state_size, action_size).to(self.device) self.optimizer : optim.Adam = optim.Adam(self.local_qnet.parameters(), lr=parameters.learning_rate) self.memory : ReplayMemory = ReplayMemory(capacity=parameters.replay_buffer_size) self.time_step : int = 0 def step(self, state : numpy.ndarray, action : int, reward : float, next_state : numpy.ndarray, done : bool) -> None: """ Records a transition in the replay memory and updates the Q-network. Args: - state (numpy.ndarray): The current state. - action (int): The taken action. - reward (float): The received reward. - next_state (numpy.ndarray): The next state. - done (bool): Indicates whether the episode is done. """ self.memory.push((state, action, reward, next_state, done)) self.time_step = (self.time_step + 1) % 4 if self.time_step == 0: if len(self.memory.memory) > parameters.minibatch_size: experiences = self.memory.sample(parameters.minibatch_size) self.learn(experiences, parameters.gamma) def action(self, state : numpy.ndarray, epsilon : float = 0.) -> int: """ Selects an action using an epsilon-greedy strategy. Args: - state (numpy.ndarray): The current state. - epsilon (float): Exploration-exploitation trade-off parameter. Returns: - int: The selected action. """ state_tensor : torch.Tensor = torch.from_numpy(state).float().unsqueeze(0).to(self.device) self.local_qnet.eval() with torch.no_grad(): action_values = self.local_qnet(state_tensor) self.local_qnet.train() if random.random() > epsilon: return int(numpy.argmax(action_values.cpu().data.numpy())) else: return int(random.choice(numpy.arange(self.action_size))) def learn(self, experiences : tuple, gamma : float) -> None: """ Performs a Q-learning update using a batch of experiences. Args: - experiences (tuple): A tuple of (states, next_states, actions, rewards, dones). - gamma (float): The discount factor for future rewards. """ states, next_states, actions, rewards, dones = experiences next_q_targets = self.target_qnet(next_states).detach().max(1)[0].unsqueeze(1) q_targets = rewards + (gamma * next_q_targets * (1-dones)) q_expected = self.local_qnet(states).gather(1, actions) loss = F.mse_loss(q_expected, q_targets) self.optimizer.zero_grad() loss.backward() self.optimizer.step() self.soft_update(self.local_qnet, self.target_qnet, parameters.interpolation_parameter) def soft_update(self, local_model : nn.Module, target_model : nn.Module, interpolation_parameter : float) -> None: """ Updates target model parameters with a soft update. Args: - local_model (nn.Module): The source model. - target_model (nn.Module): The target model. - interpolation_parameter (float): The interpolation parameter. """ for target_param, local_param in zip(target_model.parameters(), local_model.parameters()): target_param.data.copy_(interpolation_parameter * local_param.data + (1.0 - interpolation_parameter) * target_param.data)
Training the agent in Python:
from environment import Environment from agent import Agent from collections import deque import numpy import torch env : Environment = Environment(env='LunarLander-v2') agent : Agent = Agent(state_size=env.state_size, action_size=env.number_actions) number_episodes : int = 2500 maximum_timesteps_per_episode : int = 1000 epsilon_starting_value : float = 1. episilon_ending_value : float = 0.01 episilon_decay_value : float = 0.995 epsilon : float = epsilon_starting_value scores_on_100_episodes : deque = deque(maxlen = 100) def train(epsilon : float) -> None: """ Trains the reinforcement learning agent using the specified exploration-exploitation strategy. Args: - epsilon (float): The initial exploration rate (epsilon-greedy strategy). Returns: - None The function runs training episodes, updating the agent's Q-network and monitoring performance. Training stops when the environment is considered solved or the maximum number of episodes is reached. During training, the function prints the episode number and the average score over the last 100 episodes. If the average score surpasses 200, the training is considered successful, and the agent's model is saved. Args: - epsilon (float): The initial exploration rate (epsilon-greedy strategy). Returns: - None Example: train(epsilon=1.0) """ for episodes in range(1, number_episodes + 1): state, _ = env.reset() score = 0 for _ in range(0, maximum_timesteps_per_episode): action = agent.action(state, epsilon) next_state, reward, done, _, _ = env.step(action) agent.step(state, action, reward, next_state, done) state = next_state score += reward if done: break scores_on_100_episodes.append(score) epsilon = max(episilon_ending_value, episilon_decay_value * epsilon) print(f'\rEpisode: {episodes}\tAverage Score: {numpy.mean(scores_on_100_episodes):.2f}',end='') if (episodes % 100 == 0): print(f'\rEpisode: {episodes}\tAverage Score: {numpy.mean(scores_on_100_episodes):.2f}') if numpy.mean(scores_on_100_episodes) >= 200.: #type: ignore print(f'\nEnvironment Solved in {episodes:d} episodes!\tAverage Score: {numpy.mean(scores_on_100_episodes):.2f}') torch.save(agent.local_qnet.state_dict(), 'model.pth') break def main() -> None: """ Main entry point for training a reinforcement learning agent. This function initiates the training process by calling the train function with a specified exploration rate. Args: - None Returns: - None Example: main() """ train(epsilon=epsilon) if __name__ == "__main__": main()