
This publication presents a complete production deployment architecture for DebugLLM — a fine-tuned Phi-3 Mini (3.8B) model that automatically detects and repairs Python bugs. The system is served via vLLM on a GPU-backed endpoint, fronted by a FastAPI backend with authentication, Redis caching, and rate limiting, and monitored through Langfuse and CloudWatch. Two deployment paths are provided: serverless GPU on Modal Labs and a self-hosted Docker Compose stack. A full cost analysis, security architecture, and observability plan are included. All code is available in the GitHub repository.
Python is the dominant language in data science, automation, and education — yet debugging remains a significant productivity drain. Beginners in particular struggle with errors that experienced developers would resolve in seconds: a missing colon, an off-by-one index, an indented block in the wrong place.
DebugLLM is an AI-powered debugging assistant that addresses this problem. It accepts buggy Python code as input and returns the corrected version along with a plain-language explanation of what was wrong.
This publication documents how that model — trained in Module 1 of the LLMED certification using LoRA fine-tuning on Phi-3 Mini — is deployed as a reliable, scalable, production-ready API service.
| User Type | Description | Primary Use |
|---|---|---|
| Beginner Programmers | Students learning Python | Instant feedback on syntax/logic errors |
| Data Scientists | Python workflow automation | Debugging data pipeline scripts |
| Developers | General Python development | Rapid bug triage without context switching |
| Educators | Teaching Python | Automated homework feedback tools |
| IDE Plugin Users | In-editor integration | Real-time code correction suggestions |
Input: A string of Python code containing one or more bugs.
Example 1 — Syntax Error:
Input:
for i in range(5)
print(i)
Output (Fixed Code):
for i in range(5):
print(i)
Explanation:
The for loop statement was missing the required colon ':' that marks
the start of a loop block in Python.
Example 2 — Index Out of Range:
Input:
numbers = [1,2,3,4]
print(numbers[4])
Output (Fixed Code):
numbers = [1,2,3,4]
print(numbers[3])
Explanation:
Python lists are zero-indexed. For a list of 4 elements, valid indices
are 0–3. Index 4 is out of range and raises an IndexError.
Example 3 — Indentation Error:
Input:
def greet(name):
print("Hello, " + name)
Output (Fixed Code):
def greet(name):
print("Hello, " + name)
Explanation:
The print statement must be indented inside the function body.
Python uses indentation to define code blocks.
| Criterion | Target |
|---|---|
| P95 response latency | ≤ 2,000 ms |
| Error rate | < 1% of requests |
| API uptime | ≥ 99.5% monthly |
| Authentication coverage | 100% of endpoints |
| Cost per 1,000 requests | < $1.50 |
| Metric | Estimate |
|---|---|
| Daily requests | 1,000 |
| Peak throughput | 10 requests/second |
| Average input size | 200–500 tokens |
| Average output size | 100–300 tokens |
| Cache hit rate (target) | 20–30% |
| Property | Value |
|---|---|
| Model Name | Sud1212/phi3-debug-llm-lora |
| Base Model | microsoft/Phi-3-mini-4k-instruct |
| Source | HuggingFace Hub |
| Parameter Count | ~3.8B |
| Context Length | 4,096 tokens |
| Adapter Type | LoRA (r=16, alpha=32) |
| Quantization | AWQ INT4 (production) / FP16 (fallback) |
| Max Output Tokens | 512 |
| Task Type | Instruction-following (Causal LM) |
Phi-3 Mini was selected over larger alternatives for this use case due to a combination of capability, efficiency, and deployment practicality:
Capability: Despite its 3.8B parameter count, Phi-3 Mini was trained on high-quality, code-heavy instruction data. It achieves strong performance on Python code generation benchmarks relative to its size, and its instruction-following capability means it responds reliably to the structured bug-fix prompt format used in fine-tuning.
Efficiency: The model fits comfortably within 24GB VRAM in FP16 precision, and within 8GB VRAM with INT4 quantization — enabling deployment on consumer-grade or cost-effective cloud GPUs without sacrificing significant quality.
Context Length: A 4,096-token context window comfortably accommodates Python functions, small scripts, and multi-function modules — the typical scope of debugging requests.
Open Weights: As a fully open-weights model, Phi-3 Mini can be self-hosted, quantized, and fine-tuned without licensing restrictions or API cost dependencies.
For production, AWQ (Activation-aware Weight Quantization) INT4 is applied to the base model before merging the LoRA adapter. This reduces:
Quality impact is minimal for code generation tasks — benchmark studies show < 2% degradation on Python code tasks at INT4 precision versus FP16.
FP16 is maintained as a fallback configuration for environments where quantization tooling (AutoAWQ) is unavailable.
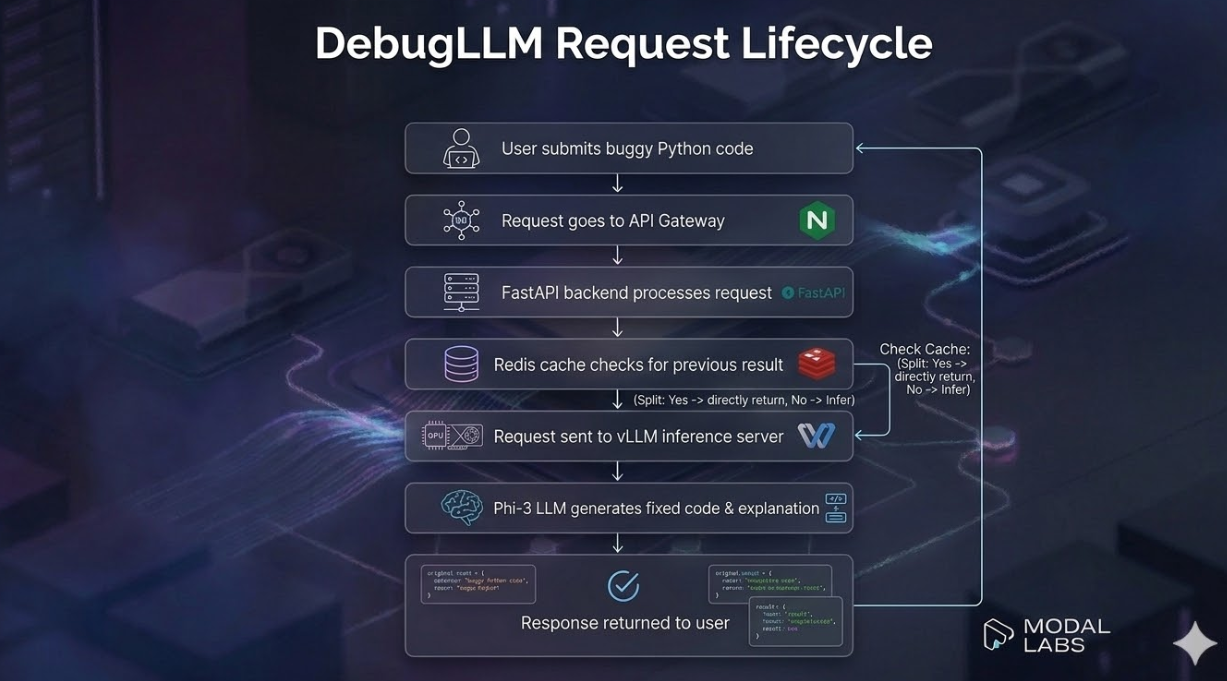
Users (Web / API / IDE)
│
│ HTTPS
▼
┌─────────────────────────────┐
│ Nginx (API Gateway Layer) │
│ · TLS Termination │
│ · Rate Limiting │
│ · Request Filtering │
└─────────────┬───────────────┘
│ HTTP
▼
┌─────────────────────────────┐ ┌───────────────┐
│ FastAPI Backend (Port 8000)│────▶│ Redis Cache │
│ · API Key Authentication │ │ (TTL: 1hr) │
│ · Input Validation │ └───────────────┘
│ · Prompt Formatting │
│ · Langfuse Tracing │
└─────────────┬───────────────┘
│ OpenAI-compat API
▼
┌─────────────────────────────┐
│ vLLM Inference Server │
│ (Port 8001) │
│ · Phi-3 Mini + LoRA │
│ · Continuous batching │
│ · Prefix caching │
└─────────────┬───────────────┘
│
▼
┌─────────────────────────────┐
│ NVIDIA A10G GPU (24GB) │
│ AWS g5.xlarge │
└─────────────────────────────┘
│
▼
┌─────────────────────────────┐
│ Monitoring Stack │
│ Langfuse · CloudWatch │
│ LiteLLM Cost Tracker │
└─────────────────────────────┘
For Easy Visualisation:

Primary: Modal Labs (Serverless GPU)
Modal is selected as the primary deployment platform for the following reasons:
Alternative: Docker Compose (Self-Hosted)
A full Docker Compose configuration is provided for teams with:
| Component | Specification | Rationale |
|---|---|---|
| GPU | NVIDIA A10G | 24GB VRAM — headroom for INT4 Phi-3 + concurrent requests |
| Instance | AWS g5.xlarge | Best price/performance ratio in the A10G family |
| vCPU | 4 | Sufficient for FastAPI + request pre/post-processing |
| RAM | 16 GB | Covers OS + Redis + FastAPI worker overhead |
| Storage | 100 GB SSD | Model weights (~7GB) + logs + cache |
| Traffic Condition | Instance Count | Trigger |
|---|---|---|
| Low traffic (< 2 req/sec) | 1 | Default |
| Normal traffic (2–8 req/sec) | 1–2 | Auto-scale up |
| Peak traffic (> 8 req/sec) | 2–4 | Auto-scale up |
| Scale-down | -1 instance | 5-min cooldown after traffic drops |
vLLM's continuous batching means a single instance can efficiently handle 10–20 concurrent requests without additional instances for most traffic patterns. Horizontal scaling is reserved for true peak load.
| Endpoint | Method | Description |
|---|---|---|
/fix-python-bug | POST | Submit buggy code → receive fix + explanation |
/health | GET | Service health, uptime, dependency status |
/docs | GET | Interactive OpenAPI documentation (Swagger UI) |
All endpoints are versioned under the implicit v1 namespace (enforced via API Gateway routing in production).
Primary: AWS us-east-1 (N. Virginia)
Rationale: Lowest latency to the majority of expected users (North America + Europe). Modal's infrastructure is similarly concentrated in US regions. A secondary deployment in eu-west-1 (Ireland) can be added for European users when traffic warrants it.
Modal charges per second of GPU compute consumed.
| Component | Unit Cost | Monthly Usage | Monthly Cost |
|---|---|---|---|
| A10G GPU (Modal) | ~$0.000306/sec | ~1,000 req/day × 2s avg = 60,000 sec/mo | ~$18.36 |
| Modal container overhead | ~$0.0001/req | 30,000 req/month | ~$3.00 |
| Compute Total | ~$21.36/mo |
| Component | Service | Monthly Cost |
|---|---|---|
| Redis Cache | Redis Cloud Free Tier | $0 (30MB free) |
| Observability | Langfuse Cloud (Hobby) | $0 (up to 50K traces/mo) |
| Secret Management | Modal Secrets | $0 |
| Model Storage | Modal Volume (10GB) | ~$0.50 |
| Infrastructure Total | ~$0.50/mo |
| Traffic Level | Requests/Month | Estimated Cost | Cost per 1K Requests |
|---|---|---|---|
| Low (test) | 5,000 | ~$5 | ~$1.00 |
| Target | 30,000 | ~$22 | ~$0.73 |
| High | 100,000 | ~$65 | ~$0.65 |
Note: Costs are estimates based on Modal's published pricing as of 2024. Actual costs depend on request latency distribution and caching effectiveness.
1. INT4 Quantization
Applying AWQ INT4 reduces per-inference compute time by ~40%, directly cutting GPU seconds consumed per request. Estimated saving: ~40% on compute cost.
2. Redis Response Caching
Identical prompts (same buggy code, same parameters) are served directly from Redis with no GPU invocation. At a 25% cache hit rate, this reduces GPU requests by 25%.
Without cache: 30,000 GPU requests/month
With 25% cache: 22,500 GPU requests/month
Saving: 7,500 GPU requests ≈ $5.50/month
3. vLLM Continuous Batching
vLLM batches multiple concurrent requests together in a single GPU forward pass. This improves GPU utilization and reduces the effective cost per request at moderate traffic levels.
4. Auto-Scaling Down
During low-traffic periods (nights, weekends), Modal automatically scales instances to zero. Unlike reserved EC2 instances, there is no cost when the service is idle.
5. Prompt Prefix Caching
vLLM's prefix caching stores the KV cache for the fixed system prompt portion. Since all requests share the same instruction prefix, this eliminates redundant computation of ~100 tokens per request.

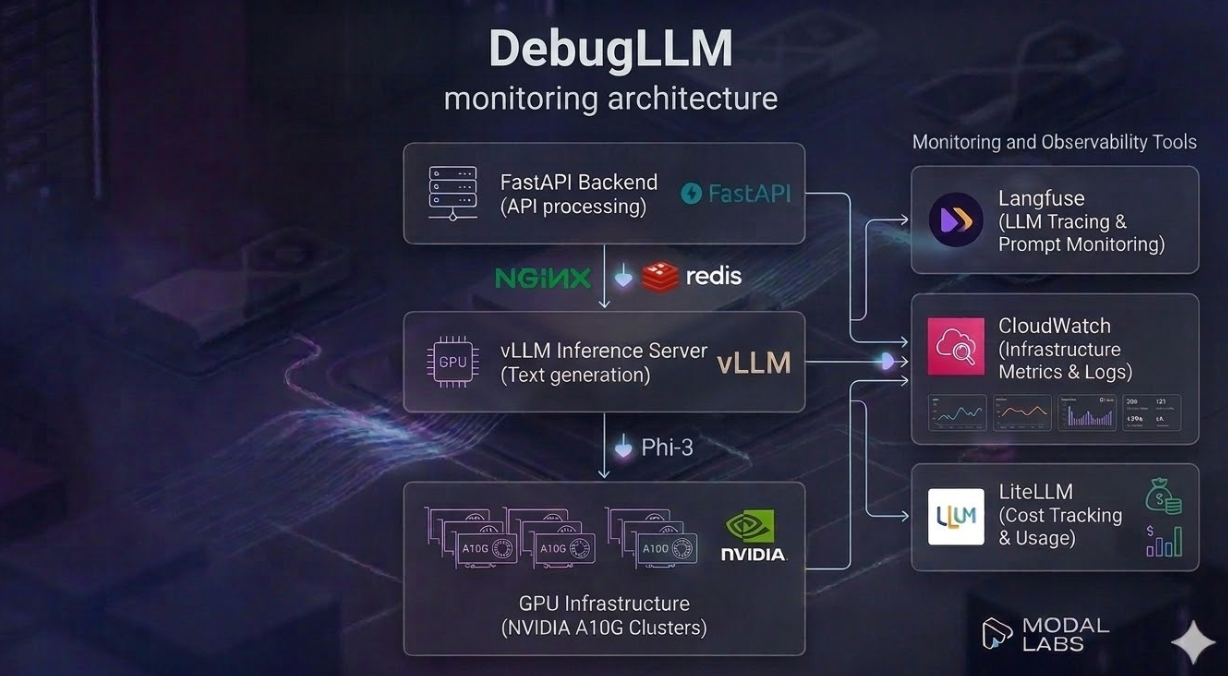
A production LLM deployment requires monitoring at three distinct layers:
Each layer requires different tooling.
Tool: Langfuse (open-source LLM observability platform)
What it tracks:
| Metric | Description | Alert Threshold |
|---|---|---|
| Input prompt | Full prompt sent to the model | — |
| Output text | Raw model response | — |
| Latency | Time from API call to response | > 3,000 ms |
| Token count | Input + output tokens per request | > 800 tokens |
| Session grouping | Tracing multi-turn interactions | — |
| Error events | Failed inference calls | Any occurrence |
Why Langfuse: It is open-source (can be self-hosted for compliance), provides first-class support for prompt versioning and A/B testing, and integrates natively with Python via a two-line instrumentation call.
Tool: AWS CloudWatch (or Datadog for multi-cloud environments)
Key Metrics Tracked:
| Metric | Unit | Alert Threshold |
|---|---|---|
| GPU Utilisation | % | < 5% for > 10 min (scale down) |
| VRAM Usage | GB | > 22 GB (approaching limit) |
| CPU Utilisation | % | > 90% sustained |
| Request Throughput | req/sec | > 8 (trigger scale-up) |
| HTTP Error Rate | % of requests | > 2% in 5-min window |
| Container Restarts | count | > 2 in 10 minutes |
| P95 Response Latency | ms | > 2,500 ms |
Dashboard: A CloudWatch dashboard is configured to show all metrics in a single view, with SNS alert notifications for threshold breaches.
Tool: LiteLLM proxy layer for unified cost tracking
LiteLLM wraps all model calls and provides:
All application-layer logs are structured JSON, capturing:
{ "timestamp": "2024-11-15T14:32:10Z", "level": "INFO", "event": "inference_complete", "latency_ms": 820.4, "tokens_used": 48, "cache_hit": false, "session_id": "user-abc123", "status_code": 200 }
Logs are shipped to CloudWatch Logs with a 30-day retention policy and indexed for search via CloudWatch Log Insights.
| Condition | Severity | Channel |
|---|---|---|
| Error rate > 2% (5-min) | High | PagerDuty / Slack |
| P95 latency > 2.5s | Medium | Slack |
| Daily cost > $50 | Medium | |
| Container restart loop | High | PagerDuty |
| GPU VRAM > 22GB | Low | Slack |
All endpoints (except /health) require a Bearer token in the Authorization header.
Authorization: Bearer sk-debugllm-xxxxx
Tokens are validated against the API_SECRET_KEY environment variable stored as a Modal Secret (or Docker secret), never in application code or environment files checked into version control.
API keys follow a rotation policy of every 90 days.
Rate limiting is enforced at two layers:
| Layer | Tool | Limit |
|---|---|---|
| Application (FastAPI) | slowapi | 100 requests/minute per IP |
| API Gateway (Nginx) | nginx limit_req | 20 burst requests |
| Daily cap | Application logic | 5,000 requests/day per API key |
Responses to rate-limited requests return HTTP 429 with a Retry-After header.
All user-submitted code is validated before reaching the inference server:
Size limits:
Blocked patterns (prompt injection and dangerous code execution):
blocked_patterns: - "__import__" # Dynamic import injection - "exec(" # Code execution injection - "eval(" # Expression evaluation injection - "os.system" # Shell command injection - "subprocess" # Process spawning injection
Any request containing a blocked pattern is rejected with HTTP 400 and logged for security audit.
The instruction template uses a strict delimiter structure that prevents user input from overriding the system instruction:
### Instruction:
Fix the bug in the following Python code.
### Input:
[USER CODE HERE]
### Response:
The ### Instruction: and ### Response: delimiters are added by the backend — users only supply the ### Input: section. The stop parameter in vLLM is configured to halt generation if the model produces ### Instruction:, preventing prompt echo attacks.
At rest: No user code is persisted to long-term storage. Redis cache entries have a 1-hour TTL and store only hashed request fingerprints as keys. Logs capture metadata (latency, token counts) but not raw user code by default; full prompt logging in Langfuse is opt-in and governed by data residency settings.
In transit: All external-facing traffic uses TLS 1.2+ enforced at the Nginx layer. Internal service-to-service traffic (FastAPI ↔ vLLM) is confined to a private Docker network or Modal's internal mesh — not exposed to the internet.
Secrets management: All credentials (HF token, API keys, Redis password, Langfuse keys) are managed via Modal Secrets or Docker Secrets — never in .env files committed to version control. The .gitignore explicitly excludes all .env files.
| Limitation | Description | Mitigation |
|---|---|---|
| Complex logical bugs | The model reliably fixes syntax/structural errors but may miss multi-line algorithmic logic errors | Scope documentation clearly communicates supported bug types |
| Single-language support | Deployed for Python only | Future work: multi-language adapters |
| Cold start latency | Modal serverless containers take 60–120s to warm up after idle period | Container keep-warm setting (5-min idle timeout); pre-warming for predictable traffic |
| No unit test execution | Fixed code is not executed/tested; correctness is probabilistic | Future: integrate sandbox execution (e.g., Judge0) for verification |
| Quantisation quality trade-off | INT4 quantisation introduces minor quality degradation (~2%) | Monitor with Langfuse; fall back to FP16 if regressions detected |
| Limited dataset generalisation | LoRA was trained on ~900 MBPP samples; rare bug patterns may not be handled | Expand training data in future iterations |
Sandbox Code Execution: Integrate a sandboxed Python executor (e.g., Judge0 or AWS Lambda) to verify that the "fixed" code runs correctly and passes unit tests — transforming the system from probabilistic to verifiable output.
Multi-Language Support: Fine-tune additional LoRA adapters for JavaScript and Java and route requests to the appropriate adapter based on detected language.
IDE Plugin Integration: Package the client as a VS Code extension for real-time, inline bug suggestions without leaving the development environment.
Streaming Responses: Enable vLLM's streaming API to stream token-by-token output, improving perceived latency for longer fixes.
A/B Testing Framework: Use Langfuse's experiment tracking to systematically compare model versions (e.g., FP16 vs INT4, different LoRA ranks) on production traffic.
User Feedback Loop: Collect thumbs-up/down feedback on fixes to build a preference dataset for RLHF or DPO fine-tuning in a subsequent training cycle.
Multi-Region Deployment: Add an eu-west-1 replica to reduce latency for European users and provide geographic failover.
This publication has presented a complete production deployment architecture for DebugLLM — demonstrating how a fine-tuned compact LLM can be deployed with professional-grade reliability, security, and observability on modest infrastructure budgets.
Key engineering decisions and their rationale:
generate() callsThe full deployment is reproducible from the accompanying GitHub repository, which includes working deployment scripts, a documented client library, and an integration test suite.
| Resource | Link |
|---|---|
| 🐙 GitHub Repository | suddhumaddi/debugllm-deployment |
| 🤗 Fine-Tuned Model | Sud1212/phi3-debug-llm-lora |
| 📦 Base Model | microsoft/Phi-3-mini-4k-instruct |
| 🔍 vLLM Documentation | docs.vllm.ai |
| 🖥️ Modal Labs | modal.com |
| 📊 Langfuse | langfuse.com |
| 🏋️ Module 1 Publication | DebugLLM Fine-Tuning |
| Tool | Version | Purpose |
|---|---|---|
| Phi-3 Mini | 4k-instruct | Base LLM for bug fixing |
| PEFT / LoRA | 0.11.1 | Parameter-efficient fine-tuning |
| vLLM | 0.4.2 | High-throughput LLM inference server |
| FastAPI | 0.111.0 | REST API framework |
| Redis | 7.2 | Response caching |
| Langfuse | 2.25.0 | LLM observability and tracing |
| LiteLLM | 1.40.0 | Cost tracking |
| Modal Labs | 0.62 | Serverless GPU deployment |
| Docker Compose | v2 | Self-hosted container orchestration |
| Nginx | 1.25 | Reverse proxy and rate limiting |
| slowapi | 0.1.9 | FastAPI rate limiting middleware |
| AWS CloudWatch | — | Infrastructure monitoring |
Sudarshan Maddi
Student, Woxsen University
ReadyTensor LLMED Certification — Module 2 Capstone
🔗 GitHub | 🤗 HuggingFace
For questions, issues, or collaboration, please open an issue on the GitHub Repository.
Published on ReadyTensor · Real-World Applications → Solution Implementation Guide