Are you worried about running DeepSeek and other AI models online because of your data privacy?. Are you concerned that your personal data might end up in the data servers hosted by foreign or geopolitical adversaries?. Do you want to save money by running AI models locally or offline on your personal computer or GPU machine?.
.jpeg?Expires=1780094210&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=EPWgKs8J4ouICCX16U3XpgkiRxfwTRjR8CFgXA5NK~HWpp6pCj4PMenMtA5Q~47Onl4IoswE6WjS3G-CaQUbRHvCMeCqS5LYv4yujN7fy-mbKHPY1jtN1Ew0c0Keeiq3W7tj-~DFlmW7nVMU5sfMs3U6zGgYdoRmHFIzWM~yfyXTENddW8z5NbbTR3mYTBavziMdjG3MKFEIJws0kfQ0GAOAx3l-Pt~D03iEWmngXKeDvtvvM~QGC8PloTWsTPdP5jAOn8D547l7MqyzT1yGCeqI-h63TX9sThi7ssoUwMv45la~T5ejFIUntIo-MfaxIboGvhWbk0w5dAVd4SOsPA__)
AI generated image: Data Privacy and Protecting Your Data in AI context (Microsoft Copilot)
The adoption of Artificial Intelligence (AI) and Large Language Models (LLMs) in many countries and different sectors of modern life has led to growing concerns about data privacy. Leveraging the intelligence and reasoning capabilities of these models, including DeepSeek, is crucial for developers and other users to accelerate the full adoption of AI. Although it is very important for users of generative AI systems such as LLMs — DeepSeek, OpenAI, Meta, etc., to know that these providers are collecting data to improve their models, therefore users should pay attention to the sensitive, personal, and proprietary data they input into these systems. Some of these generative AI systems not only collect personal and sensitive data (including conversations and chats) but also have the capability to track users’ IP addresses, access search query history with highly sensitive information, and monitor other web activities. We will explore ways to utilize the same experience as LLMs in cloud environment by running DeepSeek and other models locally or in private environments.
It’s important to note that the performance of models run locally cannot match that of DeepSeek-R1 671B model in the cloud. The 671B model, which has the highest parameters, performs better and smarter in terms of reasoning and output. The number of parameters is analogous to the Intelligence Quotient (IQ) level of the model. For example, the actual Deepseek-R1 model has around 671 billion parameters, this model is too large to run on small GPU machines or personal computers. However, smaller or distilled models, such as those with 1.5B, 7B, 8B or 70B parameters, can be run locally, and their performance depends on both the selected model and the hardware capacity of personal computers or GPU machines. Generally, higher parameter models yield better performance.
Additionally, running open-source models like Llama or DeepSeek locally is cost-free because there are no API charges when using these models. Furthermore, data security and privacy are guaranteed when running these open-source models offline. Let us delve deep into the step-by-step guide to localizing DeepSeek and other AI models, explaining how to run them locally without compromising your data.
# pip install -U ollama
Go to the Command Prompt (Windows PowerShell) and open Windows PowerShell as Administrator.
Execute the command below to get the smallest distilled DeepSeek model locally using Ollama.
# ollama run deepseek-r1:1.5b
# ollama run deepseek-r1:7b
.png?Expires=1780094210&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=ggOZjk5SbLqJo1c1NcDb4Lw1IKbFn~f072FLud67FmRUhl4xI-nHPYLMSAOkob~s4tUKQECqrsEKKe0JS0jSirKAE8Vt4ZASNPGZYX63qvsRQoqFpXN9Rob8iRbYLsAQiEZJD6Sew9KoOcY6ZC0UUoTcYwiBaeesiiakfQW8OkV6joseoq127urD3cd~xoGXslqOKRhpTr3bVD4OAMQyM0SOtkUsJuoLP3T8bByO3KjOskRfxBw2DSCliNpzFQcE~fR6owdv6Q2KV20wZwgvJqDlPKXuYNwtA8dfpMwq3OOTJN5dKD3yP1WlGhJdnjY32JbwSo04wJKMfVqVr7f47A__)
# while($true) { # Check if OLLAMA is running Get-Process ollama | ForEach-Object{ $id = $_.Id Write-Host "`nConnections for Ollama & DeepSeek process $id" -ForegroundColor Cyan Get-NetTCPConnection | Where-Object OwningProcess -eq $id | Select-Object LocalAddress,LocalPort,RemoteAddress,RemotePort,State } # Check every 5 seconds Start-Sleep -Seconds 5 Clear-Host }
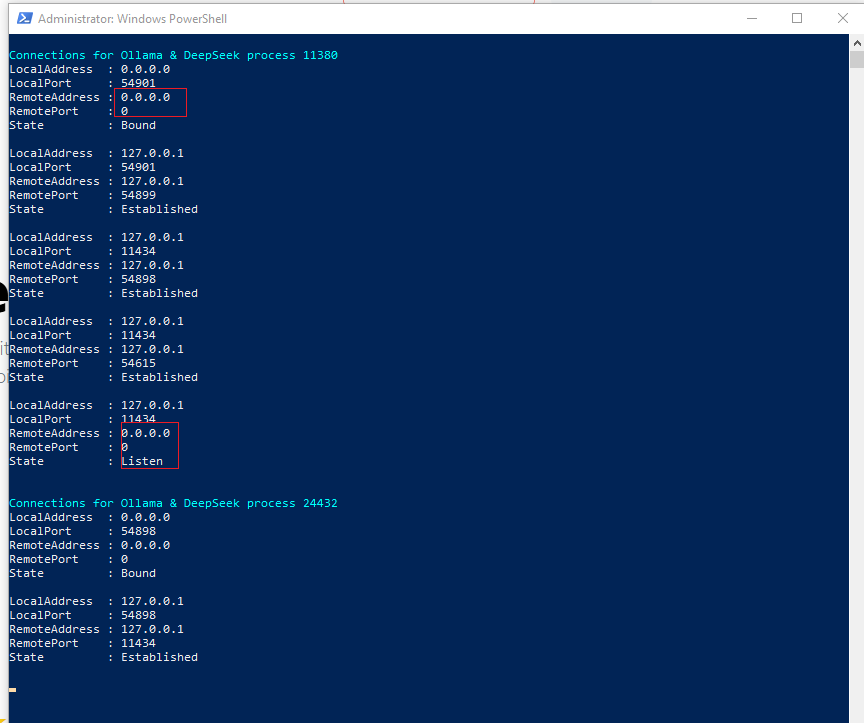
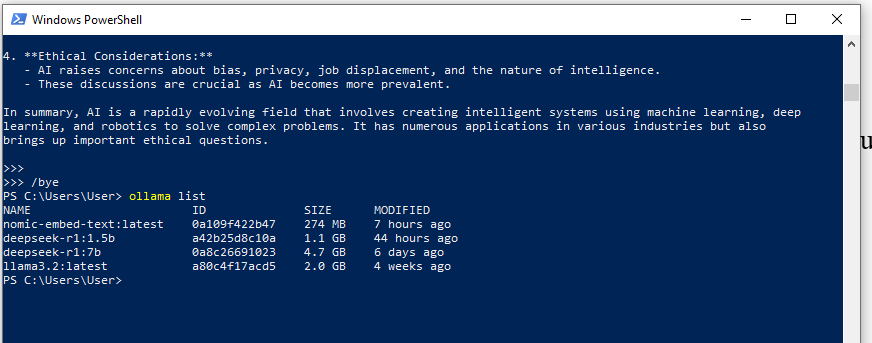
If you are not comfortable with running commands or chatting on Command Line Interface (CLI) for Linux and Command Prompt for Windows PowerShell. Other THREE alternative methods to interact with LLMs locally without any external connections.
1.Download LM Studio from www.lmstudio.ai , based on your OS.
2.Open LM Studio and go to My Models at the top left corner and select the desired model, if it is not installed then search for other models in the search box at the top left corner and download the desired model depending on the system capacity.
3.Select the appropriate model and use the chat or query section below to interact with the LLM locally.

1.Download ChatBox AI from https://chatboxai.app/en
Open ChatBox and go to the settings at the bottom left corner.
Select Ollama API and select the appropriate model from the drop-down menu
Use the chat or query section below to interact with the LLM locally.
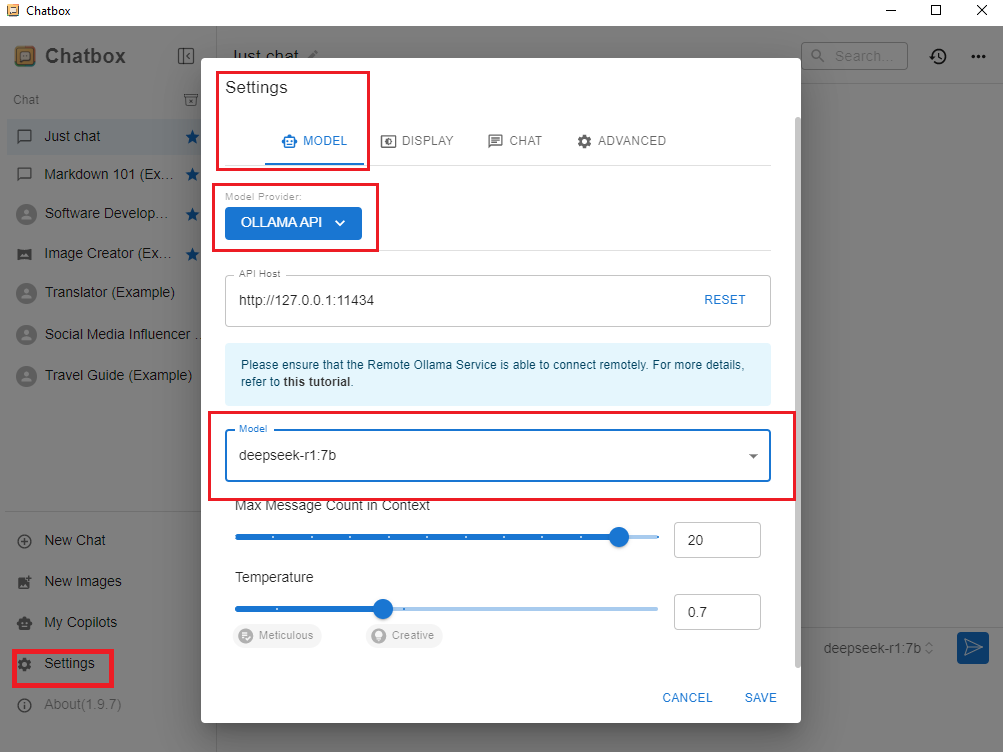
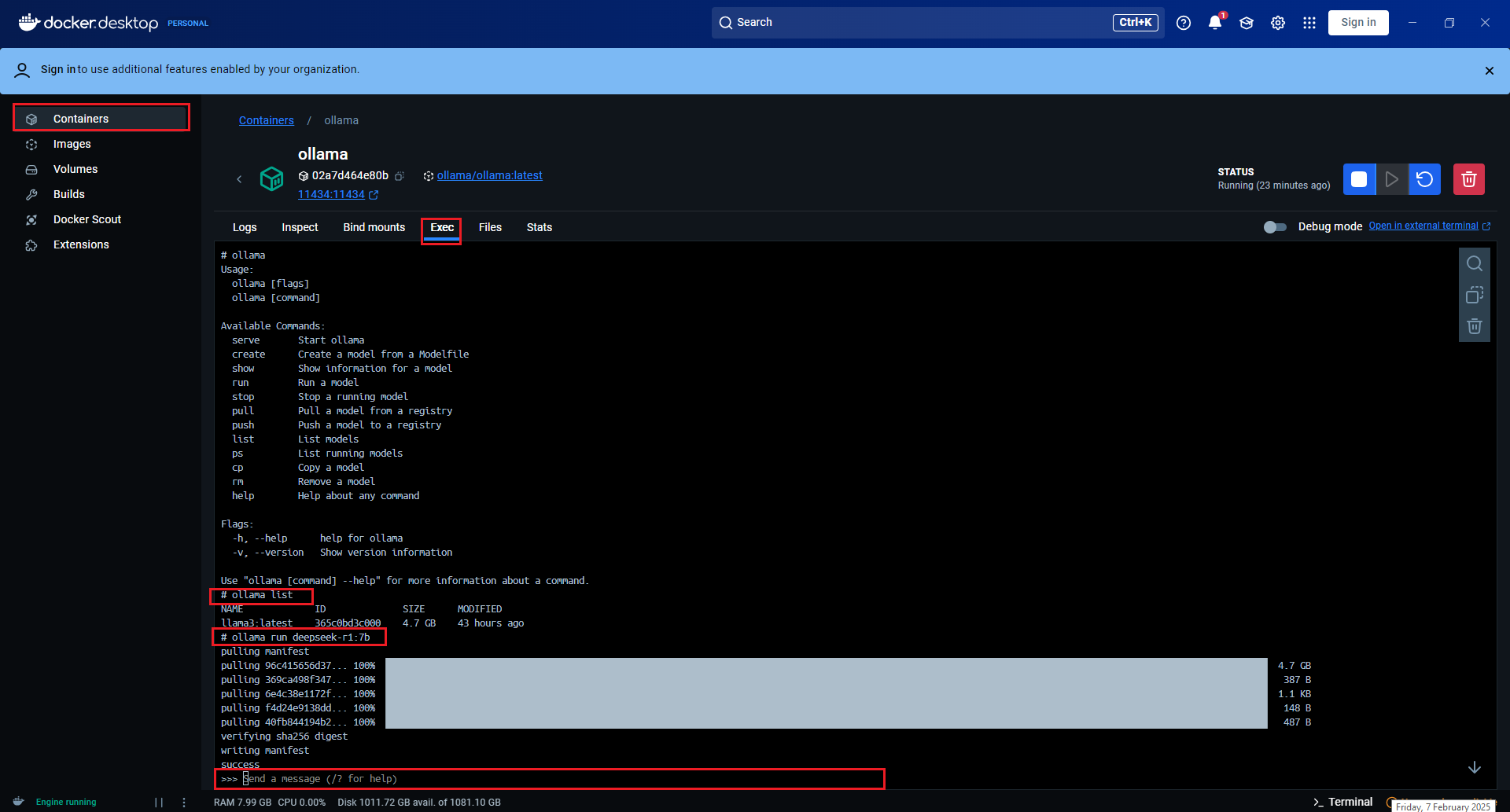
This another safe method to is to segment or completely isolate the LLM from the computer system, by using Docker container.
1.Download Docker Desktop and keep it open or running
2.Run the command below on bash.
# docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
To mitigate risks of personal and proprietary data exposure in generative AI systems, it is imperative to consider running LLMs locally or offline and adopt cautious practices described in this article to protect sensitive information.
