
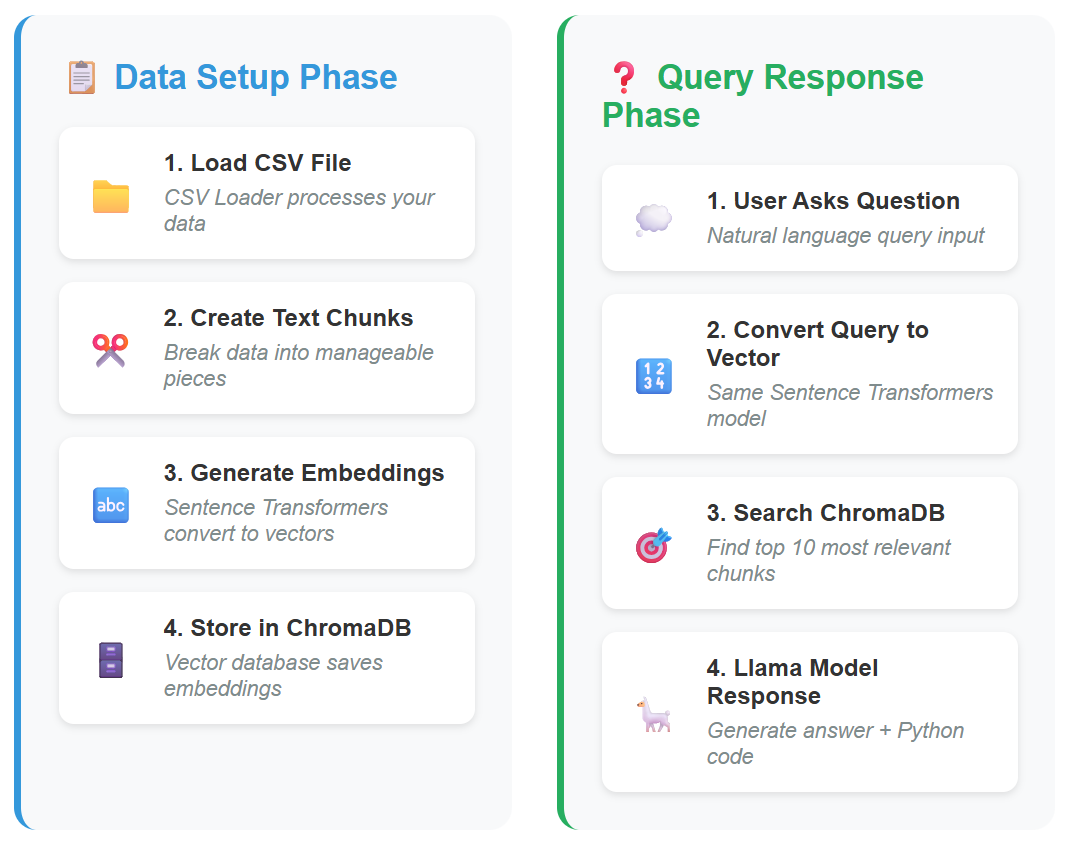
CsvPal is a retrieval-augmented generation (RAG) system specifically designed for interactive analysis of small to medium-sized CSV files through natural language queries. It will help data science beginners overcome the fundamental challenge of identifying and executing analytical opportunities within their CSV datasets. The system leverages advanced AI technologies including LangChain's document processing, ChromaDB vector storage, Sentence Transformers embeddings, and Groq's Llama-3.3-70b-versatile model to intelligently retrieve the top 10 most relevant data rows and provide contextually grounded insights alongside executable python code. Through its user-friendly Gradio web interface deployed on Hugging Face Spaces, users can explore their data using natural language queries.
The entry barrier to data science remains high for beginners, while many educational resources cover theoretical concepts and programming syntax, novice analysts often struggle with a fundamental challenge: "What analysis can be done with this data?" This gap between theoretical understanding and practical application creates a significant bottleneck in data science education. Students may grasp statistical concepts but find it difficult to identify which analyses to apply to real datasets. This is particularly challenging with CSV files, the most common data format in both business and academic contexts.
The rise of large language models (LLMs) offers promising potential to bridge this educational gap. By providing conversational interfaces, LLMs could guide users through data exploration. However, LLMs face significant limitations, including issues with hallucinations and the inability to access user-specific data, which restrict their effectiveness as tools for analyzing real datasets. Retrieval-Augmented Generation (RAG) addresses these challenges by grounding model responses in actual data, ensuring that generated insights and suggestions reflect the unique characteristics of the user's dataset rather than relying on generic examples.
CsvPal harnesses these principles to create an educational tool tailored for beginner data scientists. The system retrieves the 10 most relevant rows for each query, ensuring that the generated insights are grounded in the actual data. Users upload CSV files and ask open-ended questions like "What analysis can I perform with this data?" or "What patterns might be interesting here?" The system responds with specific suggestions tailored to their dataset's characteristics, complete with executable Python code that demonstrates proper analytical techniques.
Test CSVPal‑AI on the Iris dataset to check accuracy, beginner‑friendliness, and responsiveness using top‑10 row retrieval.
Dataset: 150 samples, 4 numeric features, 1 species label (3 classes). Stack: all‑MiniLM‑L6‑v2 embeddings, ChromaDB vector store, Llama‑3.3‑70B‑Versatile, LangChain, Gradio (Hugging Face Spaces). Schema‑aware row chunks used for retrieval.
Once the analysis is done, users can select the Clear option in the interface. This removes all vectors for the current CSV from ChromaDB and resets the session, ensuring no mixing of data between files. The user can then upload a new CSV and start fresh without any leftover context from the previous dataset.
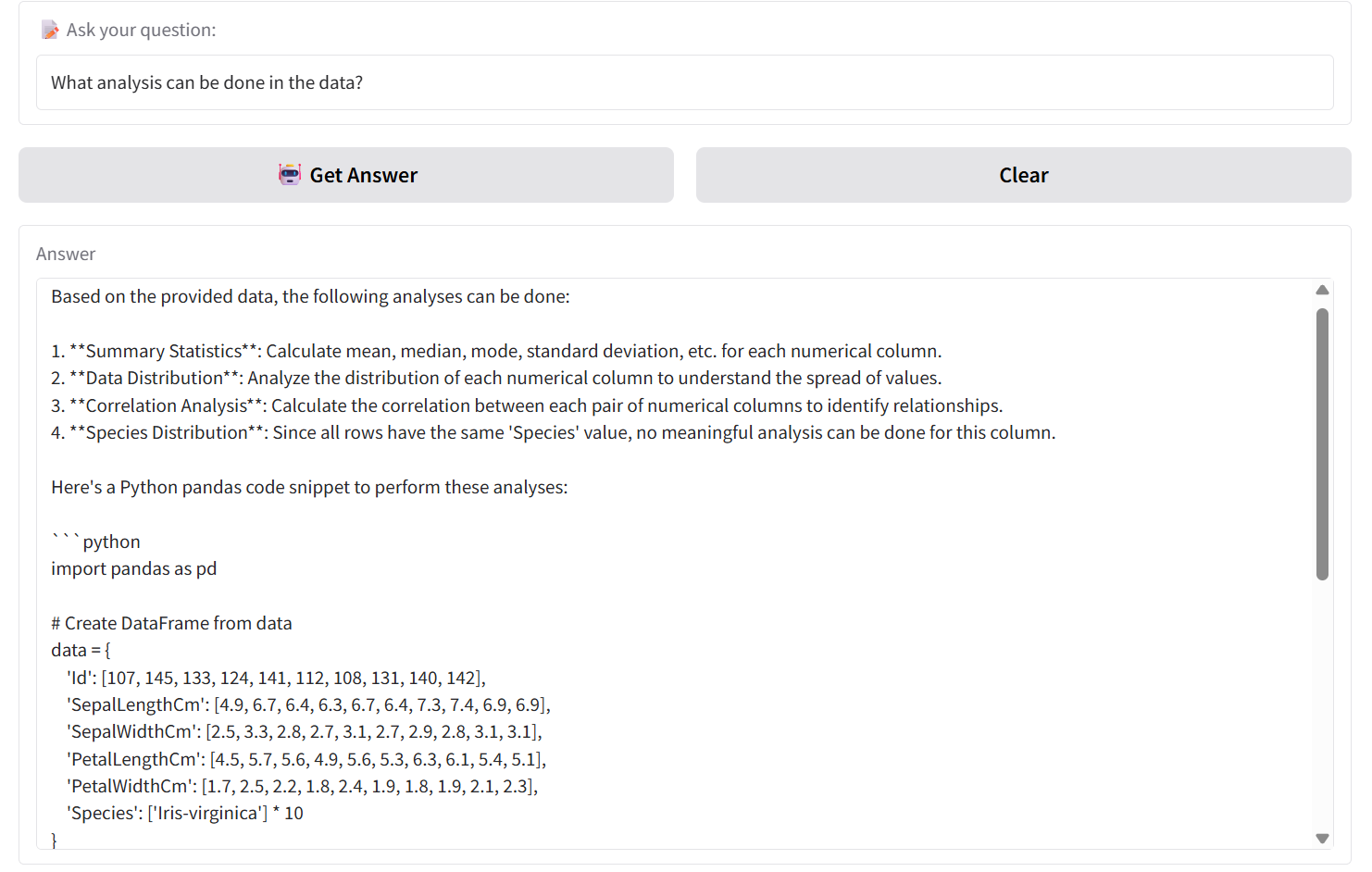
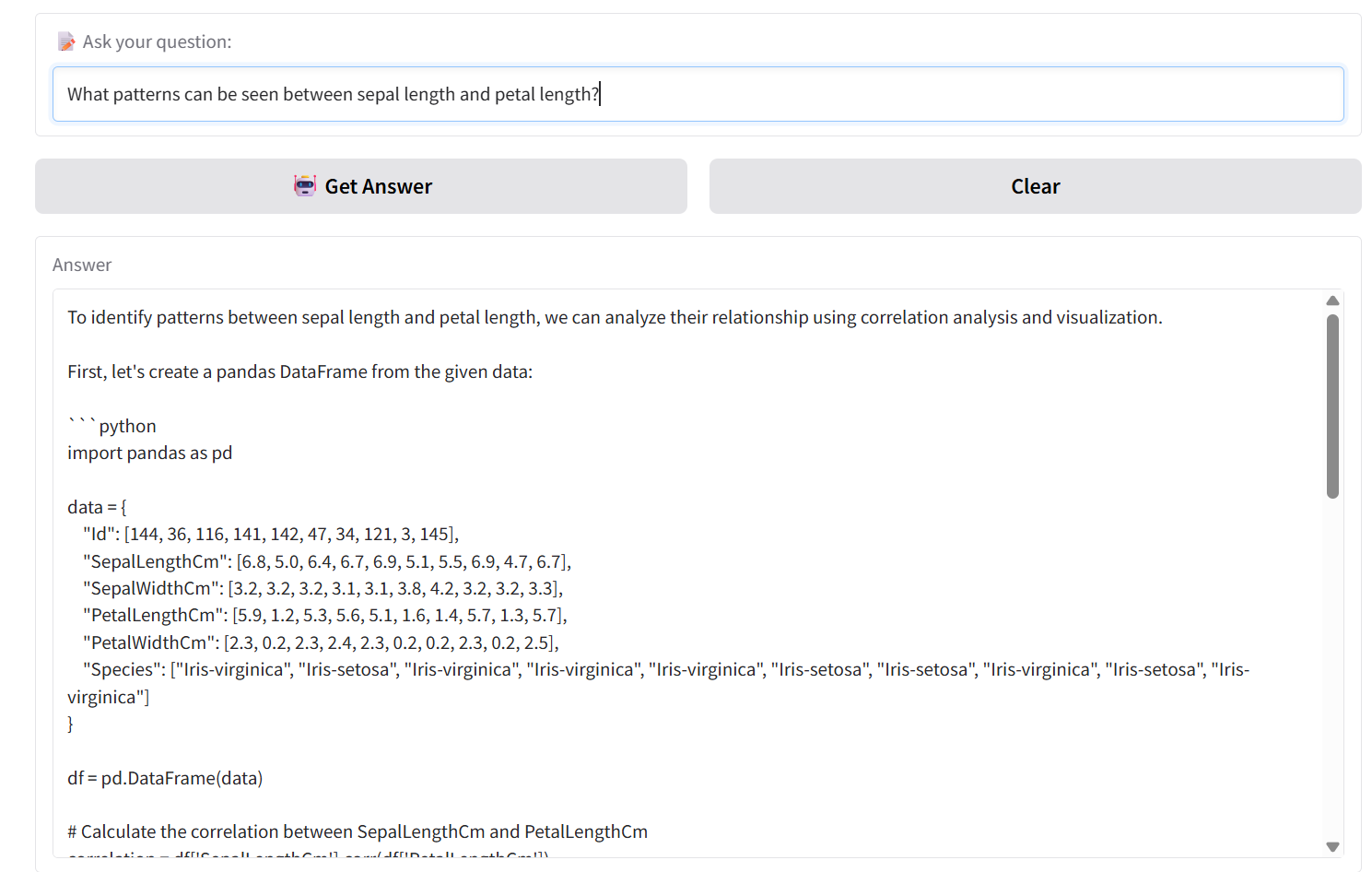
The results showed that CSVPal‑AI provided accurate and context‑aligned answers, consistently referencing correct feature names and species labels from the retrieved rows.
Input: What analysis can be done in the data?
Input: What patterns can be seen between sepal length and petal length?
CsvPal-AI demonstrates the effectiveness of retrieval-augmented generation for making CSV data analysis accessible through natural language interaction. The integration of semantic retrieval with code generation addresses both immediate user information needs and longer-term reproducibility requirements, bridging the gap between conversational interfaces and traditional programmatic data analysis.
Future enhancements could address current limitations through several directions: implementing hybrid retrieval strategies combining semantic and keyword-based search, adding support for larger datasets through optimized chunking and indexing approaches, and incorporating automatic data profiling to enhance query understanding.