In today’s hyper-competitive job market, preparing for interviews isn’t just about knowing answers ,it’s about knowing the right answers for the right roles. That’s where PrepNexus steps in.

PrepNexus is an AI-powered interview preparation platform that analyzes resumes and predicts particular job roles, scrapes live job openings, and generates personalized QnA , all in one seamless web interface. Powered by advanced transformer models like RoBERTa and LLaMA, it helps candidates go from resume to role-ready with smart, targeted preparation. Whether you're aiming for your first job or switching careers, PrepNexus gets you interview-ready faster and smarter.
~ In today’s job market, rejections are more common than callbacks , not because candidates lack potential, but because they are often not prepared for the specific demands of a role.
~ I noticed this with peers with great resumes were still struggling in interviews, mostly because their preparation was not at point.
~ That’s when I realized interview preparation in a correct way is very important. It should be personalized and role-specific.
~ This insight led to creation of an AI-powered platform that doesn’t just prepare you with random questions, but prepares you for your resume, your target role, and current job market needs.
In this section, we walk through how simply uploading a resume leads to the prediction of suitable job roles .So User can then apply for those specific role and their selection chances will increase. This is done by a RoBERTa-based deep learning pipeline. This includes loading data, preprocessing it, tokenizing the text, training a transformer model, and finally using it to make predictions .
!pip install transformers datasets PyPDF2 scikit-learn joblib -q
import os, pandas as pd, torch, joblib, PyPDF2 from transformers import RobertaTokenizer, RobertaForSequenceClassification, Trainer, TrainingArguments from datasets import Dataset from sklearn.model_selection import train_test_split from sklearn.utils import class_weight import numpy as np from google.colab import files
df = pd.read_csv("dataset.csv") df.fillna('', inplace=True) df['contact info'] = df['contact info'].astype(str)
Transformer models work with sequential text, so we concatenate structured fields into one input string.
Convert structured input :
where :
𝑇 = sequence length
𝑉 = vocabulary size
def preprocess_data(df): df['text'] = ( "Skills: " + df['skills'].astype(str) + " | " + "Experience: " + df['experience'].astype(str) + " | " + "Domain: " + df['domain'].astype(str) + " | " + "Education: " + df['education'].astype(str) + " | " + "Certifications: " + df['certifications'].astype(str) + " | " + "Projects: " + df['projects'].astype(str) ) return df[['text', 'predicted role']] df = preprocess_data(df)
Converts the roles to integers :
where C = number of roles
labels = {role: i for i, role in enumerate(df['predicted role'].unique())} df['label'] = df['predicted role'].map(labels)
train_texts, val_texts, train_labels, val_labels = train_test_split( df['text'].tolist(), df['label'].tolist(), test_size=0.2, stratify=df['label'], random_state=42 )
tokenizer = RobertaTokenizer.from_pretrained('roberta-base') def tokenize_function(examples): return tokenizer(examples['text'], padding="max_length", truncation=True, max_length=256) train_dataset = Dataset.from_dict({'text': train_texts, 'label': train_labels}).map(tokenize_function, batched=True) val_dataset = Dataset.from_dict({'text': val_texts, 'label': val_labels}).map(tokenize_function, batched=True)
model = RobertaForSequenceClassification.from_pretrained('roberta-base', num_labels=len(labels))
Where:
Learning rate
𝐿= cross-entropy loss
# Prepare training arguments training_args = TrainingArguments( output_dir="./results", num_train_epochs=4, per_device_train_batch_size=8, learning_rate=2e-5, ) # Train the model trainer = Trainer( model=model, args=training_args, train_dataset=train_data, eval_dataset=val_data, ) trainer.train()
The model is finally trained and ready for making the predictions .
In this research, an Retrieval-Augmented Generation (RAG) model was developed to provide an intelligent interview assistant capable of answering job-related queries. The methodology involves four main components: data collection and preprocessing, vector storage and embedding generation, the RAG model, and the process of sentence formation and response generation.
The initial step in this research involved a systematic collection and structuring of interview preparation content, such as a diverse collection of data from interview books, guides, and question banks in PDF format.
This preprocessing step segmented large amounts of content into smaller chunks, setting the stage for downstream retrieval and embedding tasks.
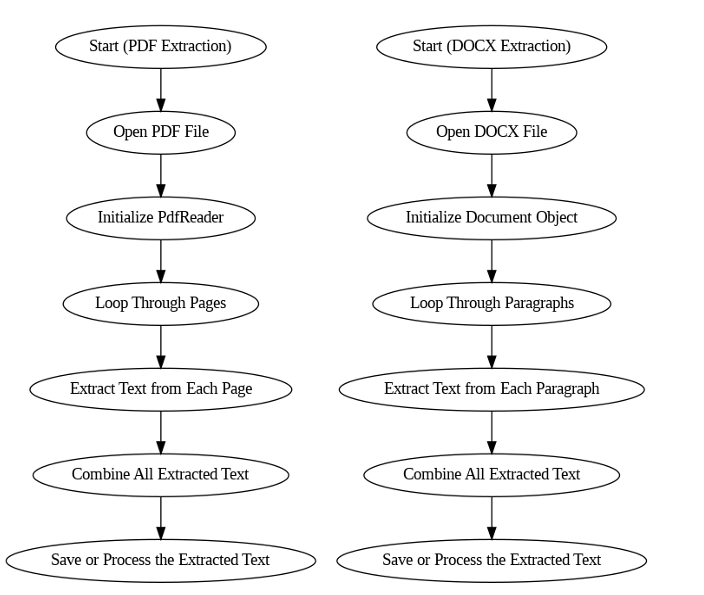
The extraction of text was saved as a datatext.txt file, which was then processed through a text splitting step. Once the text was chunked appropriately, the output was stored in the Chroma vector database. This entire process is termed Data Initialization.
The following diagram represents the Data Initialization.
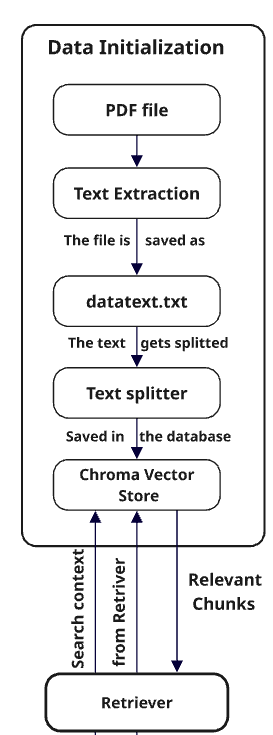
Vector Storage and Sentence Embeddings:
After the textual information had been pulled from the books, the second task is to represent this unstructured text in a computational retrieval and processing-friendly form. This conversion is done through sentence embeddings
Numerical vector representations that capture the semantic meaning of the text.
Mathematical Foundation of Embedding Generation:
Given an input text x, the objective is to map it into a dense vector space using a transformer model. Formally, the embedding function E(x) is defined as:
where:
In this work, the model used is "all-MiniLM-L6-v2" from HuggingFace's sentence-transformers, which generates high quality, low-dimensional embeddings ideal for retrieval tasks.
where N is the total number of text chunks, and 𝑣𝑖 denotes the vector for the 𝑖𝑡ℎ chunk.

Storage in Vector Space Using ChromaDB:
The resulting vector embeddings {𝑣1,𝑣2,…,𝑣𝑁} are then stored in ChromaDB which is a very high performance vector database designed for similiarity search and fast retrieval . The core idea of storing embeddings is to enable efficient semantic search: given a user query qqq, we find the document chunks whose embeddings are most similar to the query embedding.
The query embedding is computed similarly:
Where 𝑣𝑞 is the vector representation of the user query q.
Retrieval via Cosine Similarity:
To find the most relevant document chunks, cosine similarity is used as the similarity measure between vectors. The cosine similarity between two vectors A and B is mathematically defined as:
where:
Higher cosine similarity values indicate greater semantic similarity. Thus, for a query 𝜈𝑞 , the retrieval process involves selecting document vectors 𝜈𝑖 such that:
Chunking and Metadata Storage:
In reality, the extracted data is split into smaller pieces {𝑥1,𝑥2,…,𝑥𝑁} with Recursive Character TextSplitter. Each piece is embedded and saved together with metadata in ChromaDB with SQLite3 backing. This enables fine-grained retrieval based on not only semantic similarity but also contextual metadata. Formally, the metadata-aware embedding can be expressed
as:
Where:
𝑣𝑖 = Embedding vector
𝑚𝑖= Metadata associated with 𝑣𝑖
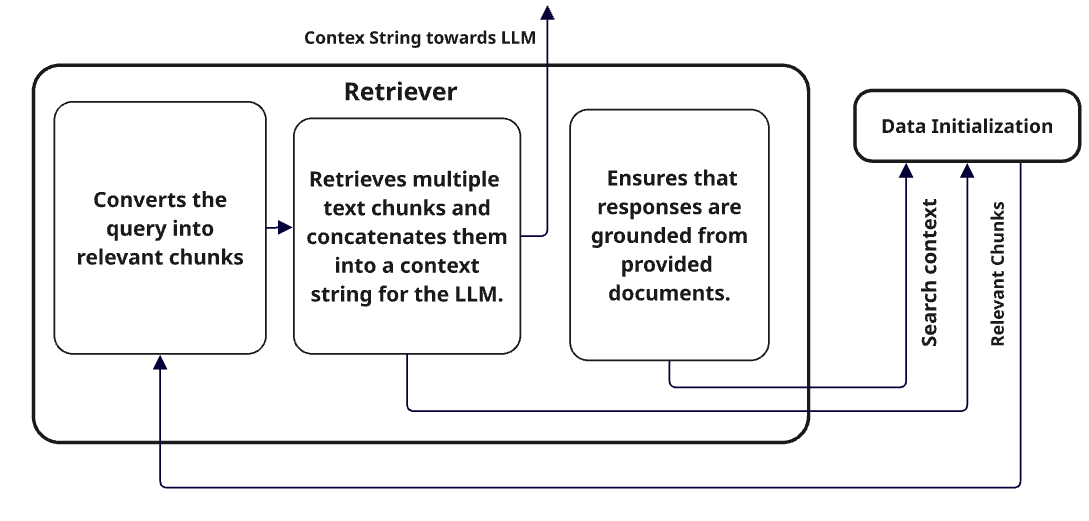
Integration with Large Language Models (LLMs) for Contextual Understanding:
Once the target document chunks are fetched using cosine similarity from ChromaDB, the next step involves leveraging a Large Language Model (LLM) to interpret and synthesize the content with contextual awareness.
LLMs trained on a diverse multimodal and multilingual dataset. It is designed to perform well on reasoning, summarization, and QA tasks, making it highly suitable for Retrieval-Augmented Generation (RAG) workflows.
The combination of ChromaDB, sentence-transformer-based embeddings, and LLM allows for more precise and human-like response generation. Cosine similarity is used to return the most semantically relevant document fragments, which are then passed as context to LLM.The LLM is tasked with generating a response or understanding by processing these chunks together. This can be formulated as:
where:
𝑥1 represents the ith document chunk
After retrieving the top−𝑘 chunks {𝑥1,…,𝑥𝑘} , we build a single "prompt" for the LLM model.
interview_chain = ( ChatPrompt_template( "Act as a senior {role} hiring manager. Generate 10 technical interview questions along with detailed, correct answers for each. Format each question and answer pair as:\n\n1. Question: ...\n Answer: ..." ) | llm | StrOutputParser() )
Let the initial output generated by the LLM be denoted as:
where:
P(ŷ) includes text cleaning, structuring, filtering, and formatting operations.
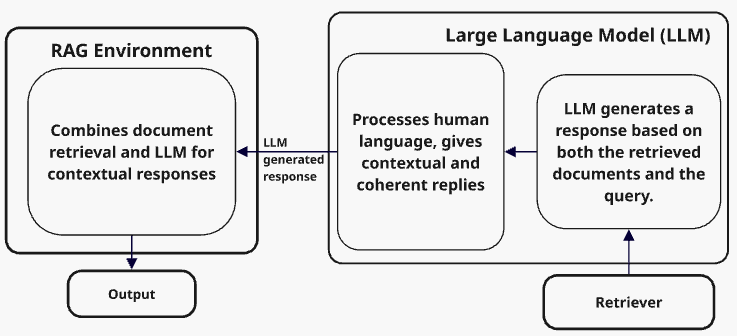
With the top-ranked document chunks retrieved and formatted into a prompt, the LLM now generates detailed responses. This output, once cleaned and structured, forms the final answer presented to the user during the interview preparation .
To enhance real-world relevance, the system includes a web scraping module designed to check current job openings based on the predicted role. Once a resume is analyzed and a suitable role (e.g., "Data Scientist") is identified, a Python-based scraper fetches live job listings from Job listing website. This bridges the gap between preparation and opportunity by directly showing which roles are in demand and where they are available. The job listing website's search engine is queried dynamically using the predicted role, and the HTML content is parsed using bs4 to extract job titles along with their corresponding links.
This functionality ensures that the platform not only supports interview preparation but also provides immediate visibility into real-time job availability for the predicted role, making the experience both practical and actionable.
For privacy and compliance reasons, the name of the job listing platform used cannot be explicitly mentioned here .
def fetch_jobs(query): headers = { "User-Agent": "Custom User-Agent string to simulate a browser" } query = query.replace(" ", "+") url = f"https://joblistingwebsite.com/jobs?q={query}&l=" try: response = requests.get(url, headers=headers, timeout=10) response.raise_for_status() except requests.RequestException as e: return f"Error fetching jobs: {e}" soup = BeautifulSoup(response.text, "html.parser") jobs = [] for card in soup.select("a.tapItem")[:5]: title_elem = card.find("h2", class_="jobTitle") title = title_elem.text.strip() if title_elem else "No title" link = "https://joblistingwebsite.com" + card.get("href", "") jobs.append(f"{title} - {link}") return "\n\n".join(jobs) if jobs else "No current openings found."
The resume role prediction model demonstrated reliable performance, correctly identifying suitable job roles in 8 out of 10 cases, and often recognizing closely related or relevant roles in additional instances.
In addition, when multiple relevant roles are predicted, the correct role is often included among the top suggestions, increasing the model’s practical usefulness in guiding candidates toward appropriate job opportunities.
This approach enables the chatbot to generate highly relevant, role-specific interview questions and answers dynamically. As a result, users receive personalized interview preparation support that closely mirrors real-world scenarios, significantly improving their readiness and confidence.

© 2025 © Harsh Rawte. All rights reserved.
