
In a world awash with AI papers, only a few stand the test of rigour, innovation, and impact. But how do we measure true technical excellence? That’s the puzzle this rubric aims to solve.
Every week, the AI/ML research landscape sees thousands of new preprints, conference submissions, and internal whitepapers. Yet, as this volume grows, so too does the inconsistency in quality, depth, and reproducibility. Researchers often face questions like:
- What defines a “good” contribution in machine learning?
- How do we balance novelty with practical utility?
- Why do some well-engineered papers get overlooked while flashy but shallow ones get through?
In academia, peer reviews can feel subjective. In industry, technical due diligence often lacks structure. Across both, the gap between real impact and perceived value is widening. That’s where this AI/ML Research Evaluation Rubric comes in — a practical framework to benchmark technical excellence across multiple dimensions, designed for use by authors, reviewers, research leaders, and funders alike.
This is more than just a scoring sheet — it's a call for clarity, consistency, and credibility in AI innovation.

Despite the explosion of AI/ML research across academic conferences, preprint servers, and industrial whitepapers, one truth remains unavoidable: there is no unified benchmark for evaluating technical quality. A research paper that earns top scores at one venue might be rejected from another for lacking rigor, clarity, or applicability.
This inconsistency isn’t just anecdotal. A 2022 study from MIT revealed that 40% of peer reviews on NeurIPS submissions displayed significant reviewer disagreement, with many reviewers citing subjectivity in judging “technical novelty” and “depth”.
In the race to push headlines and grab citations, many AI papers focus on novelty and benchmarks rather than reproducibility or robustness. The result is a glut of models that perform well in artificial, narrow tasks but fail under real-world conditions.
Examples include:
- ImageNet-trained vision models that collapse under slight distribution shifts.
- LLM papers showcasing impressive synthetic benchmarks with minimal disclosure of training datasets or evaluation methodologies.
- Reinforcement learning results that perform only in simulated environments, yet are positioned as breakthroughs.
In each of these, technical excellence is either assumed or poorly evidenced.
Academic peer review remains a subjective, inconsistent process, despite its critical gatekeeping function. Reviewer biases, variable experience, time pressure, and lack of structured rubrics often lead to:
- Overemphasis on flashy results.
- Penalizing interdisciplinary work that doesn’t “fit the mold.”
- Underrating robust engineering contributions.
In an anonymous reviewer study conducted across ICLR and CVPR (2021), researchers noted that the same paper received contradictory scores from different reviewers, with one calling it “trivial” and another calling it “transformative.” This signals a broken or at least unreliable system of evaluation.
It’s not just academics who suffer. Investors, hiring managers, product teams, and policy makers increasingly need to judge the technical credibility of research — yet often lack the tools to do so.
Consider:
- A VC firm evaluating a startup’s AI whitepaper.
- A Chief Data Scientist comparing in-house models vs. state-of-the-art publications.
- A government committee reviewing policy submissions with claimed “AI breakthroughs.”
"All of them face the same problem: how to assess the technical and practical validity of what they’re reading."
In a field where hype often overshadows substance, the need for a clear, consistent, and technically rigorous evaluation framework has never been greater. To address this, we introduce a Purpose-Built Rubric designed to elevate the standards of AI/ML research—beyond just novelty or flashy demos—into measurable, reproducible, and impactful contributions.

Peer reviews in AI/ML today often suffer from:
- Inconsistent standards across reviewers and conferences
- Overemphasis on novelty, underweighting clarity, rigor, or reproducibility
- Lack of transparency in scoring methods
- Minimal industry applicability, especially in enterprise or production contexts
This rubric bridges the gap between academic rigor and practical relevance, ensuring researchers and reviewers align on what truly defines excellence.
Relevance
Tailored to today’s challenges in AI/ML research—covering academia, industry, and open-source efforts.
Clarity & Objectivity
Each domain includes structured scoring guidance (1–5 scale) and guiding questions to minimize subjectivity.
Balance of Breadth and Depth
Evaluates both high-level innovation and low-level reproducibility—ensuring depth without losing context.
Scalability & Flexibility
Usable across domains (CV, NLP, RL, etc.) and research types (empirical, theoretical, or applied).
Ethical Intelligence
Integrates considerations of fairness, safety, and societal impact into the technical evaluation process.
| Domain | What It Measures | Key Questions Asked |
|---|---|---|
| 🧠 Innovation | Originality, novelty, and creative advancement | Does the work present a fundamentally new idea or approach? |
| ⚙️ Technical Depth | Algorithmic, architectural, or mathematical rigor | Are models/methods deeply explained and grounded in strong theory? |
| 🔁 Reproducibility | Clarity of method, code, and data accessibility | Can others replicate the results easily with what's provided? |
| 🌍 Impact Potential | Real-world applicability, influence, or scalability | Could this work influence practice, policy, or future research? |
| ⚖️ Ethical Soundness | Bias, safety, fairness, and sustainability | Does the paper acknowledge risks, and are mitigation strategies included? |
| 🚀 Scalability | Extensibility to production systems or ecosystems | Can this approach scale to larger datasets, tasks, or deployment settings? |
Each domain is scored on a 1–5 scale, where:
- 1 = Needs Work
- 3 = Solid Foundation
- 5 = Outstanding Contribution
Example Use Cases
# USE CASES: - 🔍 Reviewers can apply it as a transparent, structured scoring guide for papers. - 📄 Authors can use it pre-submission to refine and balance their contributions. - 💼 VCs and CTOs can quickly assess the technical merit behind "buzzword-rich" pitches. - 🎓 Educators and mentors can guide students in crafting high-quality, impactful research.
This rubric is designed not as a static checklist, but as a living framework—open to feedback, community contribution, and domain-specific extensions. It is a call for shared responsibility in raising the bar of technical excellence in AI/ML.
“Rigor is the new research currency. And this rubric is your ledger.”
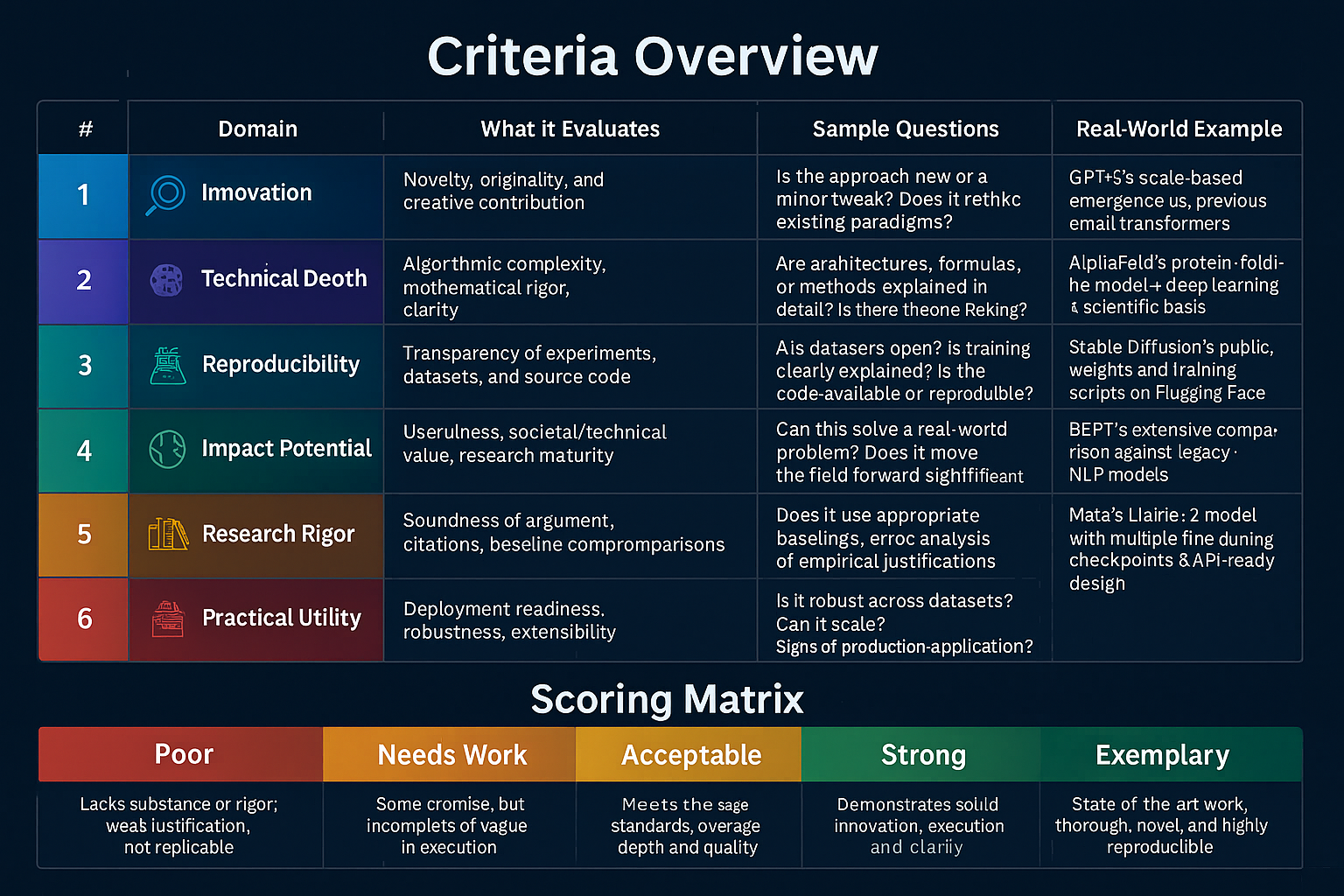
| # | Domain | What It Evaluates | Sample Questions | Real-World Example |
|---|---|---|---|---|
| 1 | 🔬 Innovation | Novelty, originality, and creative contribution | Is the approach new or a minor tweak? Does it rethink existing paradigms? | GPT-3’s scale-based emergence vs. previous small transformers |
| 2 | 🧠 Technical Depth | Algorithmic complexity, mathematical rigor, clarity | Are architectures, formulas, or methods explained in detail? Is there theoretical backing? | AlphaFold’s protein-folding model + deep learning + scientific basis |
| 3 | 🧪 Reproducibility | Transparency of experiments, datasets, and source code | Are datasets open? Is training clearly explained? Is the code available or reproducible? | Stable Diffusion’s public weights and training scripts on Hugging Face |
| 4 | 🌍 Impact Potential | Usefulness, societal/technical value, research maturity | Can this solve a real-world problem? Does it move the field forward significantly? | Tesla’s AI for self-driving vs. academic toy problems |
| 5 | 📚 Research Rigor | Soundness of argument, citations, baseline comparisons | Does it use appropriate baselines, error analysis, or empirical justifications? | BERT’s extensive comparison against legacy NLP models |
| 6 | 🧰 Practical Utility | Deployment readiness, robustness, extensibility | Is it robust across datasets? Can it scale? Are there signs of production-level application? | Meta’s Llama-2 model with multiple fine-tuning checkpoints & API-ready design |
| Score | Label | Description |
|---|---|---|
| 1 | Poor | Lacks substance or rigor; weak justification; not replicable |
| 2 | Needs Work | Some promise, but incomplete or vague in execution |
| 3 | Acceptable | Meets the basic standards; average depth and quality |
| 4 | Strong | Demonstrates solid innovation, execution, and clarity |
| 5 | Exemplary | State-of-the-art work; thorough, novel, and highly reproducible |
Paper Title: “A Novel Transformer for Low-Power Edge Devices”
| Domain | Score | Why |
|---|---|---|
| Innovation | 4 | Introduces an architecture optimized for low-power constraints |
| Technical Depth | 3 | Architecture is explained but lacks mathematical proof of compression efficiency |
| Reproducibility | 2 | Code is promised but not yet released |
| Impact Potential | 5 | Can bring deep learning to underpowered devices in rural areas |
| Research Rigor | 3 | Compares with MobileNet but ignores newer efficient models |
| Practical Utility | 4 | Shows prototype running on Raspberry Pi with 1GB RAM |
NOTE: Total Score: 21 / 30 — Promising, but needs clearer documentation for replication.
# 🔧 Use Cases - Researchers – Validate your work pre-submission - Reviewers – Bring consistency to peer review processes - Investors/Funders – Vet the technical depth of pitches - Educators – Teach evaluation standards for AI/ML publications

While the rubric is a theoretical tool, its real strength lies in how it differentiates between surface-level innovation and deeply technical, impactful work. Let's walk through a few illustrative case studies that demonstrate the power of this evaluation system.
| Rubric Domain | Evaluation |
|---|---|
| Innovation | ✅ High – Introduced Reinforcement Learning with Human Feedback (RLHF) in a novel, accessible interface. |
| Technical Depth | ✅ High – Combined GPT-3 with RLHF pipeline, large-scale deployment, deep transformer stack. |
| Reproducibility | ❌ Limited – Model weights not released initially, and limited architectural transparency. |
| Impact Potential | ✅ Very High – Transformed productivity, writing, tutoring, and API markets. |
Sample Insight: While ChatGPT scored high on innovation and impact, it fell short on reproducibility—a key concern among researchers.
| Rubric Domain | Evaluation |
|---|---|
| Innovation | ✅ Groundbreaking – First model to remove recurrence in favor of self-attention. |
| Technical Depth | ✅ High – Strong math formulation, extensive ablation studies. |
| Reproducibility | ✅ High – Full code + datasets available. |
| Impact Potential | ✅ High – Foundation of modern LLMs, computer vision transformers, etc. |
Takeaway: This is a “gold-standard” example where every criterion was clearly satisfied and meticulously documented.
| Rubric Domain | Evaluation |
|---|---|
| Innovation | ⚠️ Superficial – Repackaging known ideas with minor modifications. |
| Technical Depth | ❌ Weak – Vague explanations, no pseudocode, shallow experiments. |
| Reproducibility | ❌ None – No code or hyperparameter info provided. |
| Impact Potential | ⚠️ Overstated – Claimed generalizability without evidence. |
🚨 Warning Sign: This kind of research gains social hype but fails rigorous evaluation. A good rubric prevents bias toward such flashy submissions.

| Paper Title | Innovation | Technical Depth | Reproducibility | Impact Potential |
|---|---|---|---|---|
| ChatGPT (OpenAI) | ✅ High | ✅ High | ❌ Low | ✅ Very High |
| Attention Is All You Need | ✅ Very High | ✅ Very High | ✅ High | ✅ High |
| X “Hype” Paper | ⚠️ Low | ❌ Low | ❌ None | ⚠️ Exaggerated |
✅ Why This Matters Reviewers, research leads, or VCs can quickly identify real potential using the rubric: - Academia: Select papers worth publishing at top conferences. - Industry: Pick reproducible ideas for product innovation. - Policy/Investors: Identify work with real societal or business impact.
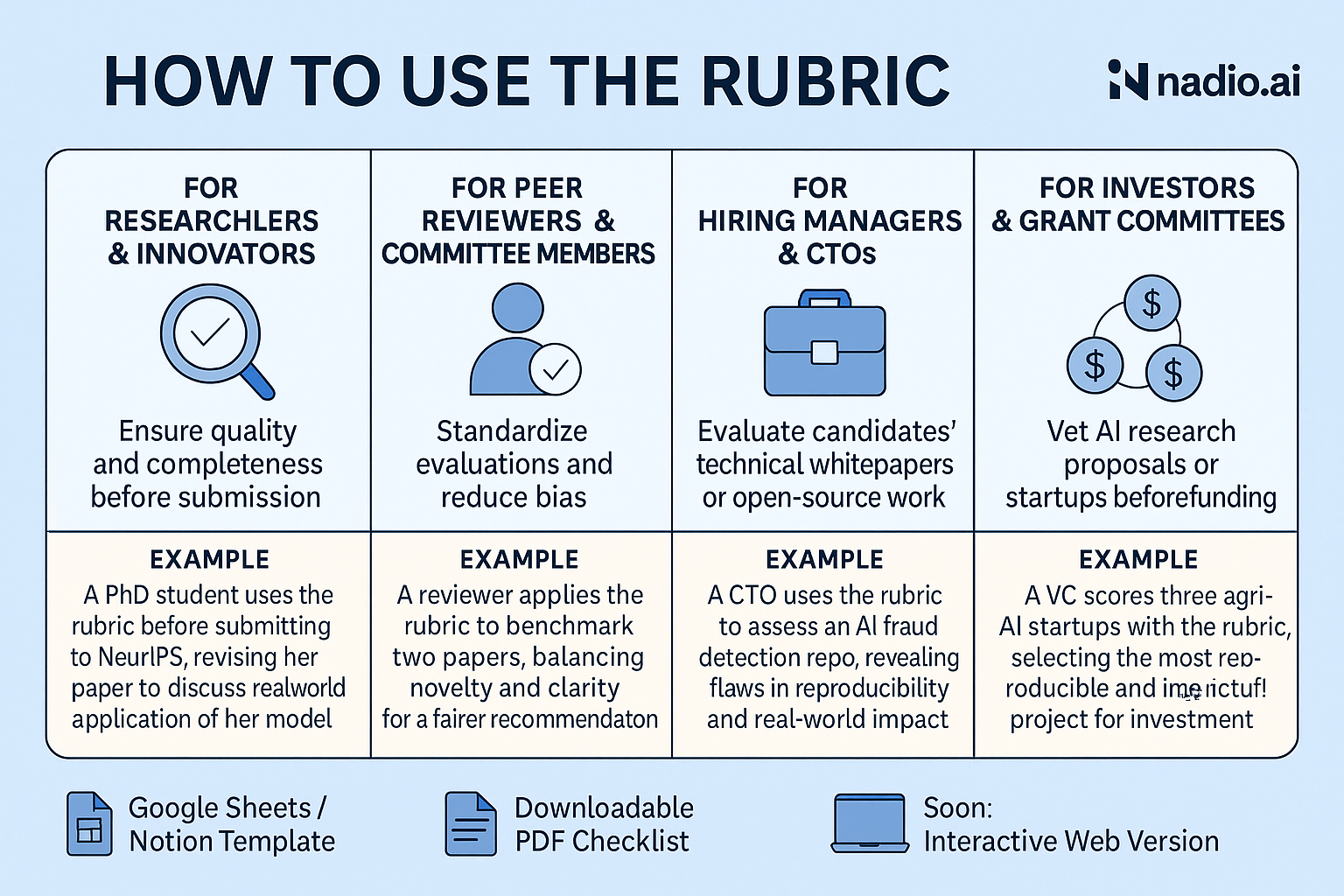
The AI/ML Research Evaluation Rubric isn’t just a theoretical framework — it’s designed for real-world utility across academia, industry, and investment. Here's how different audiences can use it:
🔬 For Researchers & Innovators
Purpose: Ensure quality and completeness before submission.
Example:
A reviewer receives two similar papers. One has a more complex method, but the other has clear code and reproducible results. The rubric helps balance novelty and clarity to make a fairer recommendation.
Purpose: Evaluate candidates’ technical whitepapers or open-source work.
Use Case:
Example:
A candidate shares a repo claiming “AI-based fraud detection.” Using the rubric, the CTO sees it lacks reproducibility and real-world impact — a red flag for production deployment.
Purpose: Vet AI research proposals or startups before funding.
Use Case:
A VC is reviewing 3 startups working on AI in agriculture. One scores high in “Reproducibility” and “Impact Potential” with published results and pilot deployments — securing the investment.
✅ Google Sheets / Notion Template ✅ Downloadable PDF Checklist ✅ Soon: Interactive Web Version
In the era of exponential AI growth, clarity and credibility aren’t luxuries — they are necessities. While AI hype fills headlines, we need tools that cut through noise and focus on lasting value. This rubric is more than a scoring system — it’s a framework for trust, reproducibility, and meaningful impact.
We invite researchers, peer reviewers, journal editors, startup CTOs, and AI policymakers to:
Whether you’re publishing a new model, funding a team, or teaching the next generation — this framework gives you a common standard to aim for.

✅Download the PDF rubric (with scoring matrix)
✅ Try the Notion or Google Sheets templates
✅ Suggest enhancements or share use-cases
✅ Join our open-source rubric community via GitHub or Discord
✅ Restack & other.
"Let’s create a future where AI innovation is measured not just by performance, but by purpose, transparency, and trust."
“Technical excellence isn’t about complexity — it’s about clarity, credibility, and contribution.”
To ensure the rubric is not just a concept, but a usable tool across academia, industry, and research organizations, we've created and curated ready-to-use resources that complement the evaluation framework:
Downloadable PDF: AI/ML Research Evaluation Rubric
The rubric is a living framework designed for evolution. We welcome suggestions, edge cases, and adaptations.
→ Submit feedback, issues, or suggestions
🔗 Email Us
🔗 Join the AI Research Rubric Slack Community
Why This Rubric Matters
The pace of AI innovation is staggering — but rigor must match speed. A shared rubric helps ensure that groundbreaking work is not just loud, but also sound. Whether you're a researcher, reviewer, investor, or policymaker, adopting this rubric brings transparency, fairness, and focus to the heart of AI/ML evaluation.
"We don’t just need more research — we need better research."
Be Part of the Movement