
This publication describes a chatbot built on Retrieval-Augmented Generation (RAG), designed to answer questions using a custom set of documents. The chatbot searches only within the provided materials, ensuring that its responses stay accurate and grounded. Unlike general‑purpose chatbots that may hallucinate or produce speculative answers, this assistant is constrained to respond solely from its indexed documents, making it well‑suited for domain‑specific or compliance‑sensitive use. When a question cannot be answered from the documents, the system simply states this directly rather than guessing.
The chatbot emphasizes trustworthiness through multiple layers of validation, including strict prompt constraints, similarity‑based retrieval checks, and automatic fallback across a few large language models (LLMs). It also remembers the flow of conversation using different memory strategies, so users can ask follow-up questions naturally. Behind the scenes, the system uses ChromaDB to store and search documents, and includes tools for building prompts, reasoning through complex queries, and managing memory. Users can interact with the chatbot through either a command-line interface or a simple web app built with Streamlit.
This publication provides comprehensive guidance on the architecture, operation, and lifecycle management of the RAG‑based chatbot system. It details all core components, including document ingestion, vector search, prompt construction, reasoning strategies, memory management, multi‑LLM integration, and the system’s dedicated persona‑handling module for meta‑questions. The document also explains the chatbot’s hallucination‑prevention mechanisms, follow‑up query augmentation logic, and the logging infrastructure that supports observability and debugging. In addition to architectural coverage, it includes instructions for running the application, configuration options, and a curated test dataset for validating system behavior. The publication further outlines the system’s current state gap identification, highlighting areas for future enhancement, and concludes with maintenance and support status to guide long‑term operational stewardship.
The dataset used for this application is a curated collection of text documents covering major themes related to India—its history, culture, geography, climate, architecture, cuisine, tourism, sports, languages, early civilizations, administrative organization, etc. Together, these files form a broad but encyclopedic, descriptive knowledge base, providing factual overviews, historical narratives, cultural explanations, and thematic analyses intended for retrieval‑augmented question answering.
However, the dataset also has clear limitations: it is not exhaustive, contains no real‑time information, lacks numerical data, statistics, or procedural instructions, and does not include opinions, contemporary events, or external sources beyond the provided texts. It cannot answer questions outside these topics, cannot provide updates, and cannot infer information not explicitly present in the documents. As a result, the assistant built on this dataset can only respond accurately when user queries fall within the scope, depth, and wording of the included materials.
| Component | Description |
|---|---|
| RAG Assistant Core | Manages end-to-end request flow. |
| LLM Integration | Provides multi-provider model support with automatic fallback mechanisms |
| Search Manager | Performs semantic similarity search. Validates retrieved context. |
| Vector Database | Handles document ingestion, chunking, embedding storage, and semantic search operations using ChromaDB. |
| Persona Handler | Detects and responds to meta questions and sensitive questions. |
| Query Processor | Determines whether a query is new or a follow-up. Validates context against similarity thresholds. Augments queries with conversation history. |
| Prompt Builder | Constructs optimized system prompts with hallucination-prevention constraints. Injects dynamic context from retrieved documents. |
| Reasoning Strategies | Applies structured reasoning patterns to enhance response quality. |
| Memory Manager | Maintains conversation history using configurable strategies that balance context preservation with token limits. |
| CLI Interface | Offers a command-line interface for interactive testing and rapid iteration. |
| Streamlit Web UI | Provides a lightweight web interface with session management. |
| Logging Infrastructure | Captures and logs events across all components. |
The application supports multiple LLM providers (OpenAI GPT-4/4o-mini, Groq Llama 3.1, Google Gemini Pro) with automatic fallback logic. This flexibility allows users to choose providers based on cost, speed, and API availability, and the system seamlessly switches to the next available provider if one fails, ensuring uninterrupted service and avoiding vendor lock-in.
Documents are split into smaller chunks using configurable separators (paragraphs, sentences, newlines) based on the document type and domain. This chunking strategy preserves context boundaries, splitting at meaningful semantic breaks rather than arbitrary character limits, ensuring that retrieved chunks contain cohesive information relevant to user queries.
Before insertion into the vector database, identical or nearly-identical chunks are detected and removed. Deduplication reduces storage overhead, improves search performance by eliminating redundant results, and prevents LLM context from being polluted with duplicate information that wastes token limits.
Chunks and embeddings are inserted into ChromaDB in configurable batches (default 300 chunks per batch) rather than one-by-one. Batch processing dramatically reduces API calls and execution time, while respecting database constraints and memory limits. The free tier limits batch insertions to 300 records maximum, requiring larger document collections to be split into multiple 300-record batches, while paid tiers support larger batch sizes for more efficient processing.
Document retrieval uses cosine similarity (measuring the angle between vector embeddings) combined with HNSW (Hierarchical Navigable Small World) indexing. HNSW is a fast approximate nearest neighbor algorithm that reduces search complexity from O(n) to logarithmic time, enabling instant semantic search even on large document collections while maintaining accuracy.
Retrieval is controlled by two parameters: k (number of top results to return, typically 5-10) determines how many candidate documents are retrieved, while distance_threshold (typically 0.35 distance = 0.65 similarity on cosine scale) filters results by relevance. Together they ensure only semantically similar documents are used as context, preventing irrelevant information from biasing the LLM response.
The system automatically detects questions about itself (e.g., "What features do you have?", "How do you work?", "What are your limitations") using pattern matching, and responds by dynamically extracting relevant sections from the README file. This eliminates unnecessary document retrieval for system-related queries and provides always up-to-date information directly from project documentation without the risk of hallucination. Additionally, the system includes safeguards to detect and appropriately handle sensitive questions (e.g., requests for credentials, API keys, personal data, output constraints, etc.) by declining to process them or routing them to secure channels, preventing accidental exposure of confidential information.
The application supports two prompt configurations for different use cases. Each configuration defines custom system prompts, style directives, output constraints, and reasoning instructions. Users can select configurations in settings, enabling role-based or domain-specific behavior without code modification. More configurations can be added, if needed.
System prompts contain strict constraints (e.g., "only use information from provided documents", "if information is not available, respond with 'I'm sorry, that information is not known to me.'") and critical rules marked with visual emphasis. Output prompts enforce specific formats and prevent speculation. The LLM-based context validation layer performs semantic checking to ensure retrieved documents actually address the question before generating responses
The application supports four memory strategies to maintain conversation history:
Sliding Window — the default strategy, which retains the most recent n message pairs (default n = 10) along with running summaries to stay within token limits.
Simple Buffer — preserves the full conversation history without pruning.
Summarization — maintains a condensed summary of prior interactions rather than storing full messages.
None — disables memory entirely, treating each query as an independent request with no conversational context.
These strategies can be switched through configuration without modifying application code, allowing users to balance context retention, performance, and token efficiency based on their specific use case.
The system detects follow-up questions using keywords (e.g., "tell me more", "continue", "anything else?") and augments them with previous conversation context. This allows pronouns and references in follow-ups to be resolved correctly. For example, "Tell me more about them" becomes "Tell me more about [previous topic] / [retrieved content]", thus enabling natural multi-turn conversations.
The application supports five configurable reasoning approaches that shape how the LLM interprets context and generates responses:
RAG‑Enhanced Reasoning — the default strategy, which retrieves relevant documents first and grounds all reasoning in that evidence.
**Chain‑of‑Thought **— enables step‑by‑step internal reasoning for complex or multi‑stage questions.
ReAct — interleaves reasoning with retrieval actions, allowing the model to iteratively think and fetch information.
Few‑Shot Prompting — incorporates curated examples to guide the structure, tone, or format of the response.
Metacognitive Prompting — encourages the model to reflect on uncertainty, confidence, and potential limitations.
These strategies can be enabled or disabled through configuration, allowing users to tailor the assistant’s reasoning behavior to the needs of their specific application.
The application uses a focused LLM chain combining three core components: Prompt Template (system prompts combined with user query and context) → LLM Provider (generates response) → Output Parser (converts to string format).
Supporting components like Persona Handler, Query Processor, and Search Manager orchestrate around this chain to prepare inputs and handle meta questions, but the actual function chaining is limited to prompt engineering, language model inference, and output parsing.
The application provides both a command-line interface (CLI) for local development and scripting, and a Streamlit web interface for user-friendly interaction. This dual approach caters to different user preferences—developers prefer the terminal-based CLI for automation and testing, while non-technical users benefit from the intuitive web UI with chat history and visual controls.
The application uses structured logging with different levels (DEBUG for detailed flow, INFO for key decisions, WARNING for issues, ERROR for failures) to document the entire query processing pipeline. Logs capture decision points (follow-up detection, meta-question routing, context validation results), enabling developers to understand system behavior and troubleshoot issues.
A unified configuration system manages all settings: LLM provider selection, distance thresholds, chunking parameters, memory strategies, reasoning strategies, prompt configurations, and logging levels. This centralized approach enables environment-specific settings (development vs. production) and eliminates hardcoded values.
Document Standardization: Raw documents are normalized into a consistent format with extracted metadata (title, tags, filename) before processing, ensuring reliable chunking and context retrieval.
Similarity Score Logging: The system logs retrieval similarity scores and context validation results, enabling users to understand why certain documents were selected or rejected.
Error Handling and Graceful Degradation: Comprehensive exception handling at each processing stage ensures failures in one component (e.g., LLM timeout) don't crash the system—fallback mechanisms maintain service availability.
Customizable Output Formatting: Output constraints in prompts enforce consistent response formats (no markdown headers, emoticons, cited sources, etc.) ensuring professional and readable answers.
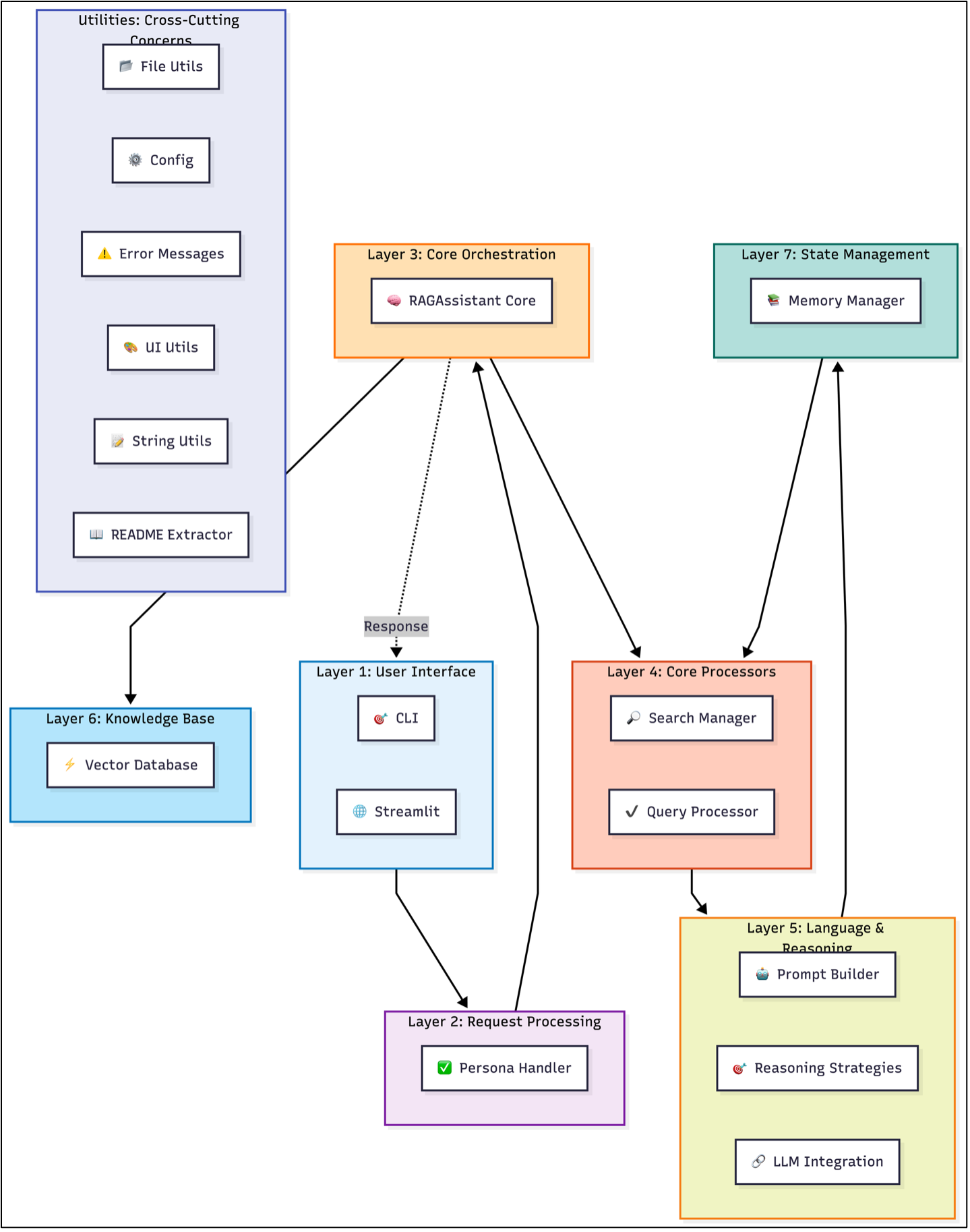
The system is organized into eight interconnected layers, each responsible for a distinct stage of query processing and response generation.
1. User Interface Layer
Handles user interaction through both the CLI and the Streamlit web interface, receiving queries and presenting responses.
2. Request Processing Layer
Uses the Persona Handler to detect meta‑questions and sensitive input, queries about the system itself, and routes them to README extraction or other specialized handlers when appropriate.
3. Core Orchestration Layer
Serves as the central orchestrator, coordinating search, query processing, and hallucination‑prevention components to manage the end‑to‑end workflow.
4. Core Processing Components
Performs semantic search to retrieve relevant documents from the vector database, augments queries with conversation history, handles hallucination prevention, and validates the retrieved context using similarity thresholds.
5. Language & Reasoning Layer
Combines prompt construction with one of the reasoning strategies and integrates with LLM providers such as OpenAI, Groq, and Google Gemini. The reasoning strategy enabled for this application is RAG Enhanced Reasoning.
6. Knowledge Base Layer
Manages document storage and semantic retrieval through ChromaDB, using embeddings to perform vector similarity search.
7. State Management Layer
Maintains conversation history using configurable memory strategies—such as sliding window, buffer, or summarization—to preserve context across interactions.
8. Cross-Cutting Concerns & Utilities: These support modules provide essential functionality across all layers, including file operations, structured logging, centralized configuration management, error handling, UI styling, and dynamic README extraction for meta-questions.
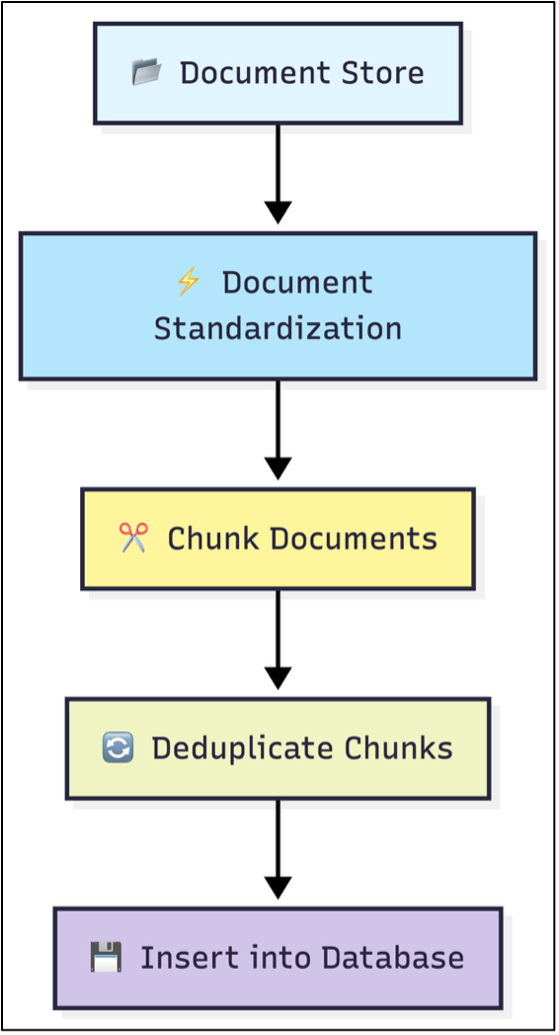
At application startup, the system automatically loads all documents located in the designated data directory. It supports both plain‑text and Markdown files, converting their raw contents into structured Document objects using LangChain’s Document class. Each document is normalized into a consistent internal schema to ensure uniform processing across the pipeline. The standardized representation includes the document’s content, title, filename, and any tags extracted from a dedicated Tags section:
{ "content": "the page content of the document", "title": "the title of the text/Markdown file", "filename":"the name of the text/Markdown file", "tags": "tags from the section in the document named 'Tags'" }
After standardization, documents are segmented into smaller, semantically meaningful chunks using LangChain’s RecursiveCharacterTextSplitter. The chunk_size and chunk_overlap parameters control how aggressively the text is divided; larger chunks with moderate overlap typically preserve context more effectively for downstream retrieval tasks. Empty chunks and those identical to the document title are discarded. The system retains the original chunk text while applying the standardized metadata schema for consistency.
To avoid redundant storage, the ingestion pipeline performs deduplication against existing entries in ChromaDB. Because ChromaDB returns results in paginated batches (up to 300 items per request), the system retrieves stored chunks incrementally, compares them against newly generated chunks, and removes duplicates. Chunk text is normalized by stripping whitespace and punctuation to ensure reliable matching during deduplication.
Once deduplication is complete, the remaining chunks are inserted into ChromaDB in batches. Each chunk is assigned a unique identifier (e.g., document_0, document_1, …). ChromaDB automatically generates embeddings for each chunk and indexes them for high‑performance vector similarity search, enabling efficient retrieval during query processing.
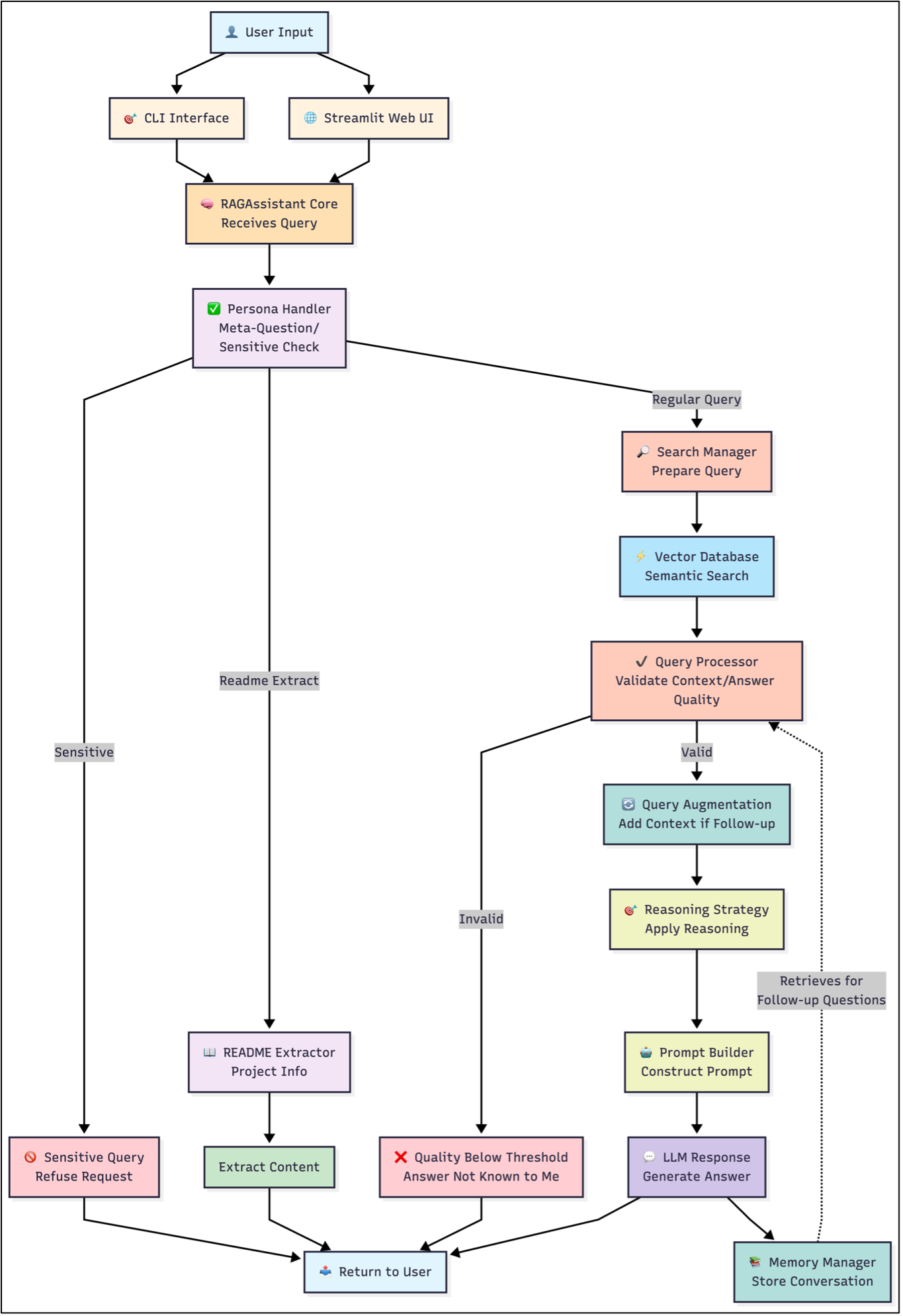
When a user submits a query through either the CLI or the Streamlit web interface, the request enters the processing pipeline at the RAGAssistant Core, which serves as the central orchestrator for all downstream components. The first stage of analysis is performed by the Persona Handler, which handles meta-questions and classifies the query into two categories: meta-question, or regular knowledge‑based query. Meta-questions are classified into three types: sensitive, descriptive and readme-extract.
Sensitive queries, such as jailbreak attempts or requests for restricted information, are immediately refused, bypassing all retrieval and reasoning components. For example, here is a sensitive question asked by the user.

Descriptive meta-questions that match a certain pattern are answered by pre-determined responses. Given below is an example of a descriptive meta-question.

A meta-question of type readme-extract triggers the README Extractor, which retrieves and returns relevant sections of the system’s documentation without invoking the knowledge base.

Regular knowledge‑based queries proceed through the full RAG workflow.
Given below is a knowledge based query that asked to the assistant.

What happens in the background?
The Search Manager prepares the query for semantic retrieval by issuing a similarity search against ChromaDB. Retrieved chunks are flattened, scored, and forwarded along with their associated metadata. The Query Processor then evaluates the relevance of this context using both similarity‑based filtering and LLM‑driven relevance checks. Two thresholds govern this stage: Top‑K, which specifies how many of the highest‑scoring chunks are considered, and the distance threshold, which defines the maximum allowable embedding distance for a chunk to be treated as relevant. Because the system uses cosine similarity, distances range from 0 to 1, where larger distances indicate lower semantic similarity. The similarity score is computed as 1 - distance, meaning higher similarity values correspond to more relevant chunks.
From the logs, we can see how the responses derived from ChromaDB were scored. The thresholds set for this application are distance threshold = 0.5, and Top-K = 5.
INFO | __main__:<module>:153 - User question: What do you know about Indian rivers?
INFO | rag_assistant:invoke:217 - Searching for top 5 documents with max distance of 0.5
DEBUG | vectordb:search:109 - Retrieved 5 results
DEBUG | vectordb:search:112 - document_314 | Similarity: 0.7126 | Title: Indian Rivers | File: indian_rivers.txt
DEBUG | vectordb:search:112 - document_304 | Similarity: 0.6762 | Title: Indian Rivers | File: indian_rivers.txt
DEBUG | vectordb:search:112 - document_296 | Similarity: 0.6730 | Title: Indian Rivers | File: indian_rivers.txt
DEBUG | vectordb:search:112 - document_297 | Similarity: 0.6281 | Title: Indian Rivers | File: indian_rivers.txt
DEBUG | vectordb:search:112 - document_342 | Similarity: 0.6145 | Title: India's Physical Geography and Geology | File: india_physical_geography_and_geology.txt
...
DEBUG | query_processor:_is_context_relevant_to_query:181 - Validation response: YES
...
INFO | query_processor:_is_context_relevant_to_query:182 - Context relevance validation: True
...
INFO | __main__:<module>:185 - Cleaned response: India's river systems represent among the world's most significant and culturally important water,,,
For queries with valid context, the system performs query augmentation. This is explained in the next section.
After this, the Prompt Builder constructs a structured prompt containing system instructions, reasoning directives, retrieved document context, and the user’s question. This prompt is sent to the configured LLM provider, with automatic fallback to alternative providers if the primary model is unavailable. The generated response is then returned to the Memory Manager, which stores the interaction according to the configured memory strategy, which, in our case, is the Sliding Window approach. The Sliding Window is configured with a window size of 10, meaning the system retains only the ten most recent message pairs while discarding older entries. This ensures that the assistant maintains enough conversational context for coherent follow‑up questions while preventing unbounded memory growth and keeping prompt sizes within token limits.
Finally, the response is delivered back to the user through the originating interface, completing the query–response cycle and enabling context‑aware handling of subsequent follow‑up questions.
This step determines whether the query is a follow‑up question and, if so, incorporates relevant conversation history retrieved from the Memory Manager. The augmented query, along with the validated context, is then processed by the Reasoning Strategy module, which selects the appropriate reasoning approach. For this application, we have chosen RAG‑grounded reasoning. For, example here is a follow up question to the previous question.
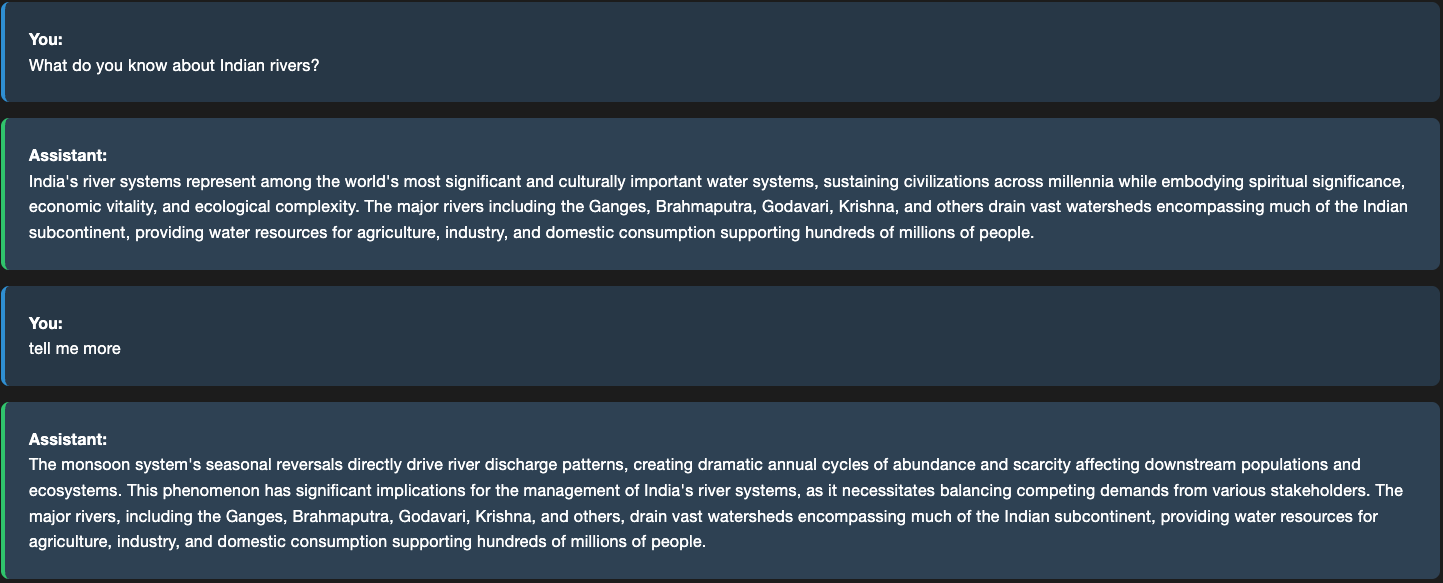
Here are the logs that show what happens in the background.
INFO | __main__:<module>:153 - User question: tell me more
INFO | query_processor:augment_query_with_context:77 - Follow-up question detected. Augmenting query with recent context.
DEBUG | query_processor:augment_query_with_context:93 - Found last user question with prefix 'User: ': What do you know about Indian rivers?...
DEBUG | query_processor:augment_query_with_context:101 - Query augmented with last user question for follow-up
INFO | rag_assistant:invoke:217 - Searching for top 5 documents with max distance of 0.5
DEBUG | vectordb:search:109 - Retrieved 5 results
DEBUG | vectordb:search:112 - document_314 | Similarity: 0.7070 | Title: Indian Rivers | File: indian_rivers.txt
DEBUG | vectordb:search:112 - document_296 | Similarity: 0.6920 | Title: Indian Rivers | File: indian_rivers.txt
...
DEBUG | query_processor:_is_context_relevant_to_query:181 - Validation response: YES. The retrieved context contains relevant information related to the user's follow-up question, as it provides more details about Indian rivers, their geographical significance, cultural importance, and ecological functions, which aligns with the user's initial question.
INFO | query_processor:_is_context_relevant_to_query:182 - Context relevance validation: True
..
INFO | __main__:<module>:185 - Cleaned response: The monsoon system's seasonal reversals directly...
What happens when the relevant information could not be found in the documents? For example, here the assistant is asked a question that seem related but are not in the documents.

If the retrieved context fails validation, the system returns a standardized “information not known” response to prevent hallucination.
INFO | __main__:<module>:153 - User question: What are the longest rivers of Europe?
INFO | query_processor:augment_query_with_context:74 - New topic question detected. Using original query for clean search.
INFO | rag_assistant:invoke:217 - Searching for top 5 documents with max distance of 0.5
DEBUG | vectordb:search:109 - Retrieved 0 results
WARNING | rag_assistant:invoke:224 - No documents found for query: What are the longest rivers of Europe?
...
INFO | __main__:<module>:185 - Cleaned response: I'm sorry, that information is not known to me.
#Quick Start
Navigate to the root folder and run this command:
python src/app.py
You should see this prompt appear asking for your input:
Enter a question or 'q' to exit:
Navigate to the root folder and run this command:
streamlit run src/streamlit_app.py
This will open a user interface on your browser that looks like this:
You may type in your questions in one of the interfaces.
The Web UI includes a “Clear Chat History” option that removes all stored conversation context, ensuring that the next user query is treated as a completely new question rather than a follow‑up.
Here are some sample questions you can ask the assistant:
See the Datasets included with this publication for the complete list of topics the assistant is trained to answer from.
Although the RAG‑Based AI Assistant is production‑ready and functionally robust, it could be further improved by addressing some gaps that separate the current implementation from the desired enterprise‑grade future state. Some of these are:
This RAG-based assistant is actively maintained and supported as an open project. The codebase follows semantic versioning, with regular updates for bug fixes, security patches, and incremental feature enhancements.
For production deployments, users are advised to pin dependencies in requirements.txt, apply updates in a controlled environment, and regularly monitor upstream packages for security advisories. When issues arise, users should first consult the troubleshooting documentation and existing GitHub issues, then open a new issue with detailed logs and reproduction steps if needed. Support is provided on a best-effort basis, with typical response times.
Email: thomasssonyjacob@gmail.com
GitHub: https://github.com/sonyjtp
LinkedIn: https://www.linkedin.com/in/sonyjacobthomas