Post-training pruning is an essential technique for reducing the complexity of neural networks after training, enhancing their deploy-ability on resource-constrained devices. This method optimizes computational resource usage while maintaining model performance. In this post, we introduce the Weight Refinement-based ClearCut Pruning Method, a novel post-training pruning technique that applies sparsity factor to weight matrices. This approach efficiently balances the trade-off between model accuracy and computational efficiency. By calculating weight importance scores, ClearCut Pruning selectively removes less significant weights without the need for retraining. Experimental results on state-of-the-art models, including LLaMA-2-7B, LLaMA-3.1-8B, OPT-6.7B, and OPT-2.7B, show significant performance improvements compared to existing pruning methods, achieving up to 50% sparsity with minimal degradation in accuracy.
The rise of large language models (LLMs) has dramatically reshaped the field of artificial intelligence, setting new benchmarks for natural language processing (NLP) tasks. These models, known for their vast number of parameters, are capable of remarkable feats. However, their large size and immense computational requirements pose challenges, especially in environments with limited resources.
To overcome these obstacles, model compression has gained considerable attention. Among the most promising techniques are network pruning and model quantization. While quantization reduces the size of a model by adjusting the precision of its weights and activations, pruning focuses on removing redundant weights, resulting in a more sparse network.
One of the most exciting methods for introducing sparsity into neural networks is post-training pruning (PTP). PTP allows us to reduce model size after the model is trained, offering a practical solution for deploying large models in resource-constrained settings. However, despite its potential, PTP has been plagued by performance degradation when compared to dense models. Models such as SparseGPT and Wanda have made strides in unstructured pruning, but they often come with significant accuracy drops when aiming for practical speed improvements.
To address these issues, we introduce a new post-training pruning technique specifically designed for LLMs, offering an effective solution for model compression. Our method incorporates two key innovations:
Weight Refinement: This new pruning metric addresses the limitations of traditional methods that typically eliminate entire weight channels. By considering both input and output channels of weight matrices and activation data, weight refinement preserves essential model features.
ClearCut Strategy: This innovative strategy optimally retains important weights, making it more efficient than existing pruning methods.
Our approach is not only robust but also easy to implement, requiring no retraining, and can be seamlessly integrated into models with linear layers. Through extensive evaluations on open-source LLMs like LLaMA, LLaMA-2, and OPT, we demonstrate that our method outperforms existing post-training pruning techniques, offering superior performance in terms of perplexity and inference efficiency for sparse LLMs.
Model compression aims to reduce the computational and storage demands of deep neural networks, with techniques like network pruning, quantization, and low-rank factorization. Early magnitude pruning removes weights based on their size but often needs fine-tuning, while structured pruning prunes entire filters or channels, which can cause performance loss.
N: M sparsity, as seen in SparseGPT and NVIDIA’s Ampere-optimized 2
sparsity, imposes a regular pattern of non-zero weights to speed up inference on modern hardware. Wanda and RIA are post-training pruning (PTP) methods that guide unstructured pruning using activation statistics, but they experience rapid perplexity degradation as sparsity increases.Low-rank approximation (e.g., SVD) reduces parameters and floating-point operations, and hybrid methods combine pruning with low-rank techniques for better compression.
Our approach introduces a new weight refinement metric and the ClearCut algorithm, which enforces sparsity based on refined importance scores. Unlike existing methods, it doesn’t require retraining and shows lower perplexity degradation across models like LLaMA-2 and OPT.
In many machine learning models, particularly those utilizing large datasets or complex architectures, the model can become excessively large and computationally expensive. This often leads to inefficiencies in terms of both processing time and memory usage. The primary challenge we address in this study is how to reduce the size of these models without significantly compromising their accuracy or predictive performance. Recently, various model compression techniques have been proposed, one of which is pruning. A specific variant of pruning, known as post-training pruning has garnered attention due to its ability to reduce model size without the need for retraining, providing an efficient approach to model compression.
Large language models (LLMs) typically have a large number of parameters, making them computationally expensive during inference. Our goal with post-training pruning is to reduce the model size by pruning less important weights, without the need for retraining, while maintaining similar performance in terms of accuracy or task-specific metrics. Specifically, we aim to create a pruned model
In this equation,
measures the relative importance of each weight in relation to the sum of all incoming weights to the
evaluates the importance of the weight relative to all outgoing weights from the
introduces a quadratic scaling factor to amplify the impact of larger weights, ensuring that more significant weights are prioritized during pruning. The scaling factor alpha allows us to control the influence of this quadratic term.
This weight refinement approach improves the pruning process by addressing the limitations of traditional magnitude pruning. By incorporating both the local context (the importance of incoming and outgoing weights) and the global context (the overall network structure), our approach ensures that weights with smaller magnitudes but critical roles in the network are not mistakenly pruned. The quadratic scaling further helps to retain weights that are influential in determining the model's output, even if their magnitude is not the largest.
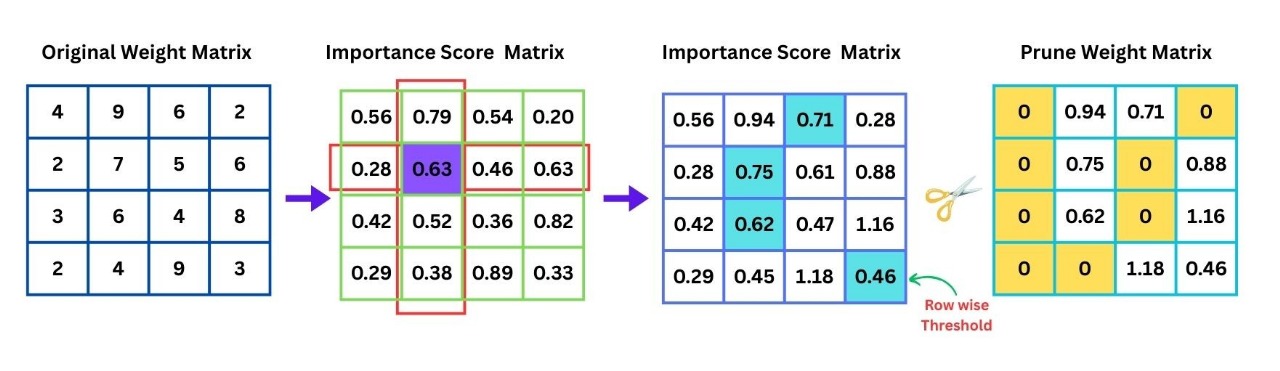
We propose a new method called ClearCut. This algorithm efficiently applies sparsity ratio to the weight matrix
First, for each row
Where
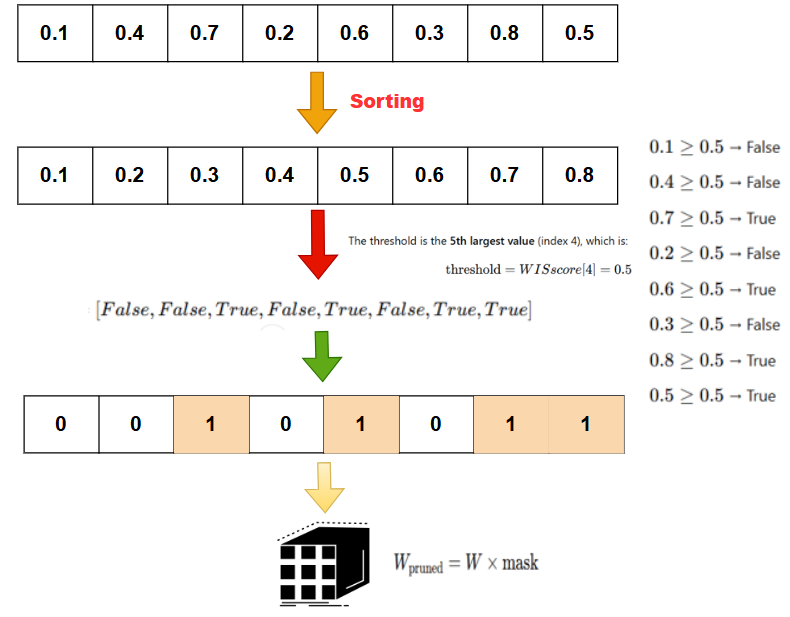
Next, for each row, we find the threshold value above which weights are retained. The threshold is determined by finding the
The threshold value torch.kthvalue function, which finds the torch.kthvalue is 1-indexed). This value acts as the cutoff for pruning:
Following this, a binary mask is created for each row. The mask is set to 1 for weights whose importance scores are greater than or equal to the threshold, and 0 for those that should be pruned. The binary mask for each row is defined as:
Where
Finally, the pruned weight matrix is obtained by multiplying the original weight matrix
This operation selectively retains the important weights based on the calculated importance scores, effectively pruning the less significant weights and reducing the model size.
In this study, we test the proposed method on four widely-used large language models (LLMs): LLaMA2-7B, LLaMA3.1-8B, OPT-6.7B, and OPT-2.7B. The models are loaded from the public checkpoints available through the HuggingFace Transformers library. For consistency, we apply uniform pruning across all linear layers of the models, excluding the embedding layers and the output head. Specifically, for the LLaMA models, each self-attention module contains four linear layers, while the MLP modules have three linear layers. In the OPT models, the MLP modules consist of two linear layers. To maintain a fair comparison, all evaluations are carried out using the same codebase across all models.
We utilize the WikiText2 dataset for evaluation, following the standard practices in evaluating language models. The perplexity metric is used to quantify model performance, with lower perplexity indicating better performance. For all experiments, we implement our pruning methods using PyTorch and perform evaluations on NVIDIA T4 GPUs to ensure consistent computational resources.
Perplexity results on WikiText2 were obtained by applying 50% unstructured sparsity to the model.
| Model | SparseGPT | Wanda | Magnitude | Dense | RIA | ClearCut (ours) |
|---|---|---|---|---|---|---|
| LLaMA2-7B | 7.24 | 7.26 | 17.28 | 5.68 | 6.81 | 6.78 |
| LLaMA3.1-8B | - | - | - | - | 9.43 | 9.39 |
| OPT-2.7B | 13.48 | 14.28 | 265 | 12.47 | 14.20 | 14.19 |
| OPT-6.7B | 11.55 | 11.94 | 969 | 10.86 | 11.84 | 11.44 |
The ClearCut (ours) approach has proven to be a major success across multiple large language models (LLMs) as illustrated in the table above. In the LLaMA-7B model, we reduced perplexity to 6.78, outperforming RIA and surpassing both SparseGPT and Wanda. For LLaMA-3.1-8B, we achieved a perplexity of 9.39, ahead of RIA and demonstrating strong performance. The OPT-2.7B and OPT-6.7B models also saw impressive reductions in perplexity, with ClearCut (ours) outperforming SparseGPT, Wanda, and RIA. These results highlight the effectiveness of ClearCut (ours) in reducing perplexity, marking a significant achievement in model pruning.
Unstructured pruning, a technique commonly used for model compression, encounters a significant challenge when approximately 50% of the weights are pruned, leaving the model with an equal distribution of non-zero and zero values. While this pruning approach eliminates a portion of the weights, it does not lead to a reduction in the model size, as the total number of parameters remains the same. The presence of zero values does not mitigate the computational burden since the multiplication of parameters still takes place during inference, resulting in unnecessary computations and resource wastage. Consequently, the computational cost and Floating Point Operations (FLOPS) remain unaffected, preventing any meaningful reduction in computational workload.
 Low Rank Decomposition applied after Pruning the model
Low Rank Decomposition applied after Pruning the model
To overcome this limitation, we propose the application of Low-Rank Decomposition to compress the weight matrix, thereby enhancing computational efficiency as shown in the figure above. In this method, the original weight matrix
Where
| Reduction (%) | Base Pruned Perplexity | Low Rank Perplexity | Original Parameters | New Parameters | Rank |
|---|---|---|---|---|---|
| 10.5% | 18.04 | 23.97 | 402,849,792 | 362,348,544 | 921 |
| 20.01% | 18.04 | 27.26 | 402,849,792 | 322,240,512 | 819 |
| 40.02% | 18.04 | 49.96 | 402,849,792 | 241,631,232 | 614 |
| 60.03% | 18.04 | 323.95 | 402,849,792 | 161,021,952 | 409 |
| 80.04% | 18.04 | 2228.15 | 402,849,792 | 80,412,672 | 204 |
In our experiment, we used the OPT-1.3B model as a baseline for testing. We applied Low-Rank Decomposition to the self-attention layers, specifically targeting the key (K), query (Q), value (V), and output (O) matrices. Through various tests with different ranks shown in the table above, we achieved parameter reductions ranging from 10.5% to 80.4%.
Our findings indicate that the optimal parameter reduction occurs between 20% to 40%, where the reduction in model size is significant, and the degradation in perplexity is minimal, as shown in the figure below. For larger models, such as the OPT-6.7B, we observed that even a parameter reduction of over 50% resulted in only a small increase in perplexity. Specifically, the perplexity increased from 11.76 to 22.16, as shown in Table. This demonstrates that substantial model compression can be achieved with relatively minor performance degradation in terms of perplexity.
| Reduction (%) | Base Pruned Perplexity | Low Rank Perplexity | Original Parameters | New Parameters | Rank |
|---|---|---|---|---|---|
| 40.03% | 11.76 | 17.59 | 2,148,007,936 | 1,288,175,616 | 1228 |
| 50.00% | 11.76 | 22.16 | 2,148,007,936 | 1,074,266,112 | 1024 |
| 60.00% | 11.76 | 37.23 | 2,148,007,936 | 859,308,032 | 819 |
This post addresses the challenge of deploying large language models (LLMs) efficiently in resource-constrained environments. We introduced a novel post-training pruning method combining Weight Refinement and the ClearCut pruning algorithm to reduce model size without retraining.
The Weight Refinement metric enhances pruning by assessing weight importance both locally (relative to row/column sums) and globally (activation-based). The ClearCut algorithm uses these refined scores to apply effective sparsity, ensuring critical weights are retained while maximizing parameter reduction.
Experiments on models like LLaMA-2-7B, LLaMA-3.1-8B, and OPT demonstrated that our method outperforms baselines like SparseGPT and Wanda, achieving significantly lower perplexity even at 50% sparsity. Additionally, combining our pruning technique with Low-Rank Decomposition further reduces parameter count and FLOPS.
The main advantage of our approach is its post-training, one-shot nature, eliminating the need for fine-tuning. Our method offers a practical solution for optimizing LLMs, making them more accessible and efficient for deployment.
Our novel method combining local weight importance with global activation statistics:
def compute_clearcut_score(W, row_sum, col_sum, activation_norm, alpha=0.1, eps=1e-8): """ Compute ClearCut importance scores for weight matrix W """ abs_W = torch.abs(W) # Local importance components col_term = abs_W / (col_sum + eps) row_term = abs_W / (row_sum + eps) # Global interaction term interaction = alpha * (abs_W**2) / (row_sum * col_sum + eps) # Activation-aware adjustment activation_weight = activation_norm ** args.a return (col_term + row_term + interaction) * activation_weight
SVD-based compression for attention layers:
def apply_low_rank_decomposition(model, target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], rank_ratio=0.5): # Perform SVD on weight matrices U, S, Vh = torch.linalg.svd(weight, full_matrices=False) # Truncate to target rank target_rank = int(min_dim * rank_ratio) U_r, S_r, Vh_r = U[:, :target_rank], S[:target_rank], Vh[:target_rank, :] # Create factorized matrices A = U_r @ torch.diag(torch.sqrt(S_r)) B = torch.diag(torch.sqrt(S_r)) @ Vh_r return LowRankLinear(A, B)
├── main.py # Main entry point for pruning experiments
├── prune.py # Core pruning algorithms (ClearCut, RIA, magnitude, wanda, sparsegpt)
├── data.py # Dataset loading utilities (C4, WikiText2, PTB)
├── eval.py # Evaluation scripts for perplexity and zero-shot tasks
├── layerwrapper.py # Layer wrapping utilities for activation collection
├── sparsegpt.py # SparseGPT implementation
├── quant.py # Quantization utilities
└── README.md # This file
# Evaluate on WikiText2 python main.py --model meta-llama/Llama-2-7b-hf --eval_dataset wikitext2 # Evaluate on multiple datasets python main.py --model facebook/opt-6.7b --eval_dataset c4
# Run zero-shot evaluation on common sense reasoning tasks python main.py \ --model meta-llama/Llama-2-7b-hf \ --prune_method ClearCut \ --sparsity_type 2:4 \ --eval_zero_shot
Supported zero-shot tasks: BoolQ, RTE, HellaSwag, ARC-Challenge, MNLI
git clone https://github.com/cRED-f/ClearCut-Pruning-Efficient-Weight-Refinement-for-LLM-Compression.git
Dependencies:
import torch from transformers import AutoModelForCausalLM, AutoTokenizer from main import main import argparse # Load model model_name = "meta-llama/Llama-2-7b-hf" model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, device_map="auto" ) # Configure pruning arguments args = argparse.Namespace( model=model_name, prune_method="ClearCut", # Choose: magnitude, wanda, ria, ClearCut, sparsegpt sparsity_type="2:4", # unstructured, 1:4, 2:4, 3:4, 4:8 sparsity_ratio=0.5, # For unstructured pruning calib_dataset="c4", # c4, wikitext2, ptb nsamples=128, seqlen=2048, reallocation=True, # Enable channel reallocation lsa=True, # Enable Linear Sum Assignment apply_low_rank=True, # Apply low-rank decomposition rank_ratio=0.5, # Rank ratio for SVD target_modules="q,k,v,o" # Attention modules for low-rank ) # Run pruning main(args)
# ClearCut Pruning with 2:4 sparsity python main.py \ --model meta-llama/Llama-2-7b-hf \ --prune_method ClearCut \ --sparsity_type 2:4 \ --calib_dataset c4 \ --save # Combined Pruning + Low-rank Decomposition python main.py \ --model meta-llama/Llama-2-7b-hf \ --prune_method ClearCut \ --sparsity_type 2:4 \ --apply_low_rank \ --rank_ratio 0.3 \ --target_modules q,k,v,o \ --eval_zero_shot
--prune_method: Choose from magnitude, wanda, ria, ClearCut, sparsegpt--sparsity_type: unstructured, 1:4, 2:4, 3:4, 4:8--sparsity_ratio: Sparsity level for unstructured pruning (0.0-1.0)--reallocation: Enable heuristic channel reallocation--lsa: Enable Linear Sum Assignment optimization--reconstruction: Use SparseGPT-based weight reconstruction--semi_sparse_acc: Use PyTorch 2 semi-structured acceleration--apply_low_rank: Apply low-rank decomposition after pruning--rank_ratio: Fraction of singular values to keep (0.0-1.0)