
If this is your first time hearing about RAG, you might think of it as a torn piece of cloth used for cleaning. You're not wrong. In artificial intelligence, RAG, which stands for Retrieval Augmented Generation, works like a digital cleaning tool. It uses pieces of external knowledge, such as documents or databases, to clean up hallucinations and outdated information from large language models, helping them give more accurate and reliable answers.
This article begins by introducing the concept and theory behind Retrieval-Augmented Generation (RAG). It then demonstrates how to implement a simple RAG pipeline using LangChain for orchestration, Hugging Face language models for generation, and ChromaDB as the vector database for document retrieval.
In 2020, Lewis et al. proposed a flexible technique called Retrieval-Augmented Generation (RAG) in the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In this paper, the researchers combined a generative model with a retriever module to provide additional information from an external knowledge source that can be updated more easily.
WHAT IS RAG?
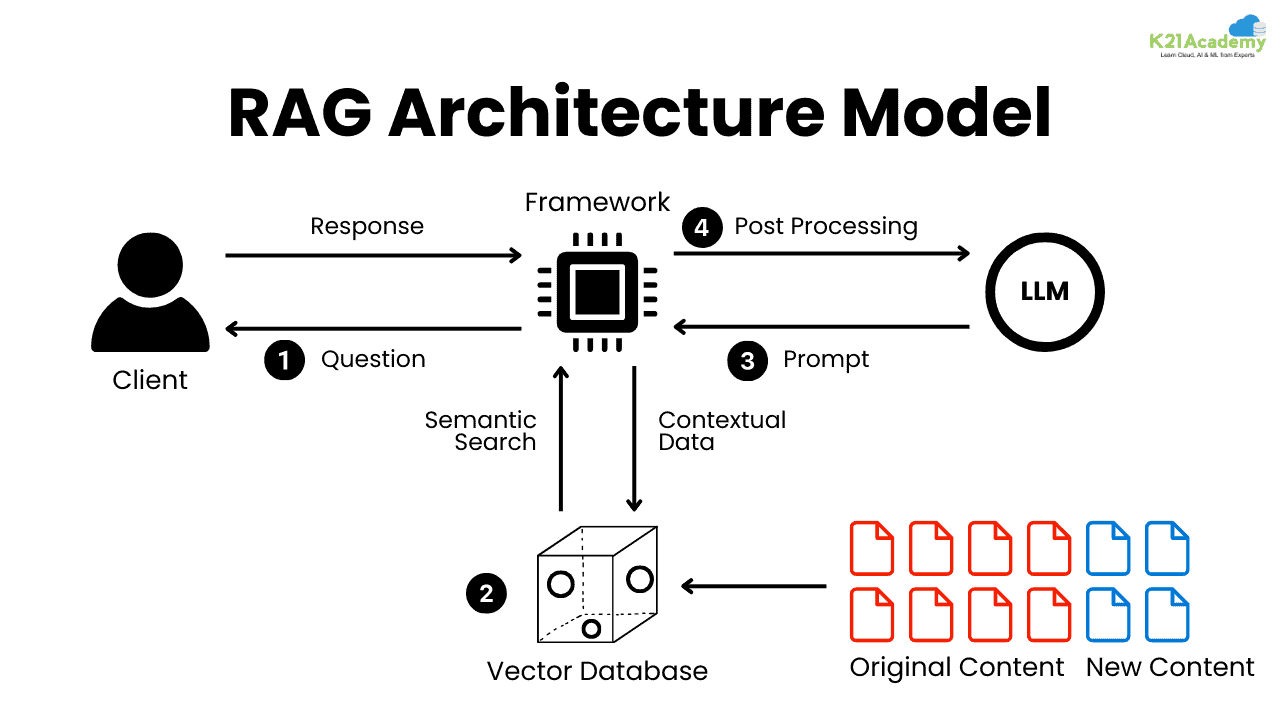
RAG stands for Retrieval-Augmented Generation. It is a technique where an LLM is enhanced with external document retrieval to generate more accurate, up-to-date, and contextual responses.. This helps reduce LLM Hallucinations whereby the llm model makes up stuff that sounds real but isn’t true. It might give fake facts, wrong answers, or invented names.
Retrieval:- fetches relevant documents or facts from an external knowledge base (e.g Wikipedia or a custom dataset).
Augmentation:- enriches the language model by connecting it to external knowledge sources.
Generation:- using a language model (like GPT or BART) to generate answers
based on the retrieved information.
WHY HAS IT BEEN A GAME-CHANGER IN THE AI INDUSTRY?
RAG has become a significant advancement in the AI field because it addresses one of the core limitations of large language models. These models are trained on vast and diverse datasets, allowing them to develop a broad understanding of many topics. The knowledge they gain is stored in deep neural networks, enabling strong performance on general language tasks. However, once training is complete, these models cannot access new, proprietary, or domain-specific information that falls outside their original dataset. This can result in outdated, inaccurate, or even entirely fabricated outputs.
RAG solves this problem by enabling the model to retrieve relevant information from external sources in real time. Instead of relying solely on its static internal knowledge, the model can search for and use the most current or specialized data available before generating a response. This leads to more accurate, trustworthy, and context-aware outputs, making RAG especially useful for data scientists and professionals who work with specialized or fast-changing information.
This section demonstrates how to implement a simple RAG pipeline using LangChain for orchestration, Hugging Face language models for generation, and ChromaDB as the vector database for document retrieval.
Requirements
Ensure you have the necessary Python packages installed:
LangChain for managing the orchestration
HuggingFace for using the embedding model and language model
ChromaDB for storing and querying the vector database
# Install !pip install langchain huggingface_hub chromadb !pip install -U langchain-community !pip install pypdf sentence-transformers
Define your relevant environment variables in a .env file in your root directory.
Create a Hugging Face API token at huggingface.co/settings/tokens by clicking “New token” and choosing a role
Create an .env File in Your Root Directory
HUGGINGFACEHUB_API_TOKEN="your_hugging_face_token_here"
Replace your_hugging_face_token_here with your actual token from Hugging Face.
Then, run the following command to load the relevant environment variables.
Load the Environment Variable in Python
You can use the dotenv package to load environment variables:
import dotenv from dotenv import load_dotenv import os load_dotenv() hf_token = os.getenv("HUGGINGFACEHUB_API_TOKEN")
Setup
As a preparation step, you need to prepare a vector database as an external knowledge source that holds all additional information.Follow these simple steps:
Load your data:- Add the files or text you want to use.
Break it into smaller parts:- Split long text into chunks.
Embed and store chunkse:- Use a model to convert the chunks and store them in the database.
Collect and load your data:-
For this example, you will use E-MOTIVE Trial Protocol by University of Birmingham as additional context. To load the data, You can use one of LangChain’s many built-in DocumentLoaders. A Document is a dictionary with text and metadata. To load text, you will use LangChain’s PyPDFLoader.
import requests from langchain.document_loaders import PyPDFLoader # Download the PDF pdf_url = "https://www.birmingham.ac.uk/Documents/college-mds/trials/bctu/E-MOTIVE/E-MOTIVE%20protocol%20v2.0%20clean.pdf" pdf_path = "emotive_protocol.pdf" response = requests.get(pdf_url) if response.status_code == 200: with open(pdf_path, "wb") as f: f.write(response.content) else: raise Exception("Failed to download PDF: {response.status_code}") # Load the PDF document loader = PyPDFLoader(pdf_path) documents = loader.load()
Chunk your documents: —
Since the PDF file, in its original state, is too long to fit into the LLM’s context window, you need to chunk it into smaller pieces. LangChain comes with many built-in text splitters for this purpose. For this simple example, you can use the CharacterTextSplitter with a chunk_size of about 500 and a chunk_overlap of 50 to preserve text continuity between the chunks.
Then you convert chunks to plain text strings because many downstream components in LangChain or LLM pipelines expect raw text, not full Document objects.
from langchain.text_splitter import RecursiveCharacterTextSplitter # Split PDF into chunks text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20) chunks = text_splitter.split_documents(documents) # Convert chunks to plain text strings chunk_texts = [chunk.page_content for chunk in chunks]
The embed_documents function takes a list of text strings and generates vector embeddings for each using a Hugging Face model. It checks the available hardware (CUDA, MPS, or CPU) to decide the device for running the model. The selected model is then used to convert each document into a high-dimensional vector. These vectors capture the semantic meaning of the
input texts.
The insert_publications function stores the text chunks and their corresponding embeddings into a ChromaDB collection. It calculates the next available document ID based on the current count in the collection. For each batch of documents, it generates embeddings and assigns unique IDs before inserting them. This process enables efficient semantic search and retrieval of the inserted documents later.
from langchain.embeddings import HuggingFaceEmbeddings import torch import chromadb from chromadb.config import Settings from chromadb.api.models import Collection def embed_documents(documents: list[str]) -> list[list[float]]: device = ( "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu" ) model = HuggingFaceEmbeddings( model_name="sentence-transformers/all-MiniLM-L6-v2", model_kwargs={"device": device}, ) return model.embed_documents(documents) def insert_publications(collection, publications: list[str]): next_id = collection.count() for i in range(0, len(publications), 10): batch = publications[i:i+10] embeddings = embed_documents(batch) ids = [f"document_{next_id + j}" for j in range(len(batch))] collection.add( embeddings=embeddings, ids=ids, documents=batch ) next_id += len(batch) chroma_client = chromadb.Client(Settings(anonymized_telemetry=False)) collection = chroma_client.get_or_create_collection(name="emotive_documents") insert_publications(collection, chunk_texts)
Retrieve
Once the vector database is populated, you can define it as the retriever component, which fetches the additional context based on the semantic similarity between the user query and the embedded chunks.
from langchain_core.runnables import RunnableLambda, RunnablePassthrough def search_documents(collection, query: str, top_k: int=5): query_embedding = embed_documents([query])[0] results = collection.query( query_embeddings = [query_embedding], n_results = top_k ) return results["documents"][0] results = search_documents(collection, "management of postpartum hemorrhage") def retrieve_context(query: str) -> str: docs = search_documents(collection, query) return "\n".join(docs) retriever = RunnableLambda(retrieve_context)
Augment
Next, to augment the prompt with the additional context, you need to prepare a prompt template. The prompt can be easily customized from a prompt template, as shown below.
from langchain.prompts import ChatPromptTemplate template = """ You are a medical assistant trained in interpreting clinical protocols. Use the retrieved context from the E-MOTIVE protocol to answer the following question accurately. If the protocol does not provide enough information, respond by saying "The E-MOTIVE protocol does not specify this." Focus on evidence-based practices for managing postpartum hemorrhage (PPH), and limit your response to three concise sentences. Question: {question} Context: {context} Answer: """ prompt = ChatPromptTemplate.from_template(template) print(prompt)
Generate
Finally, you can build a chain for the RAG pipeline, chaining together the retriever, the prompt template and the LLM. Once the RAG chain is defined, you can invoke it.
from transformers import pipeline from langchain.llms import HuggingFacePipeline from langchain_core.output_parsers import StrOutputParser pipe = pipeline( "text2text-generation", model="google/flan-t5-base", ) llm = HuggingFacePipeline(pipeline=pipe) rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser() ) query = "What is the first step recommended in E-MOTIVE for managing postpartum hemorrhage?" result = rag_chain.invoke(query) print(result)
You have built a Retrieval-Augmented Generation (RAG) system using open-source tools. This involves loading PDF medical documents, splitting them into manageable chunks, and embedding them with Hugging Face models. You store these embeddings in a ChromaDB vector store, and then use a retriever to find relevant chunks in response to a user query. The retrieved content is then passed to a generative model like FLAN-T5 for response generation. The system integrates LangChain components and HuggingFace Pipelines, and it runs on GPU (CUDA) when available for efficiency.
https://github.com/AhmadTigress/Rag_System/tree/main
This project is licensed under the MIT License.