Build a RAG Assistant
📝 WHAT I BUILT — RAG POWERED QUESTION-ANSWERING SYSTEM
Overview
I built a Retrieval-Augmented Generation (RAG) assistant using:
Python
SentenceTransformers embeddings
FAISS vector database
A custom document (.docx) I uploaded
A retrieval pipeline to answer questions only from the document
This system takes a query, retrieves the most relevant chunks from my document, and produces an answer fully based on my uploaded content.
STEP 1 — Prompt Formulation
I created a simple query → retrieve → answer structure.
The assistant answers only from the retrieved text, avoiding hallucination.
STEP 2 — Document Ingestion
I uploaded my file (DOCX).
The system automatically reads the content using python-docx and stores it in a text variable.
STEP 3 — Text Chunking
The document text was split into overlapping chunks (500 characters each) so the vector store can index them correctly.
STEP 4 — Embedding
I used SentenceTransformer ('all-MiniLM-L6-v2') to create embeddings for each chunk.
These embeddings convert text into numerical vectors for search.
STEP 5 — Vector Store Creation (FAISS)
I created a FAISS index and added all embeddings into it.
This enables fast retrieval of the most relevant document chunks.
STEP 6 — Retrieval Pipeline
For any user query:
-
The query is embedded
-
FAISS performs similarity search
-
It returns the top relevant text chunks
-
These are used to answer the question
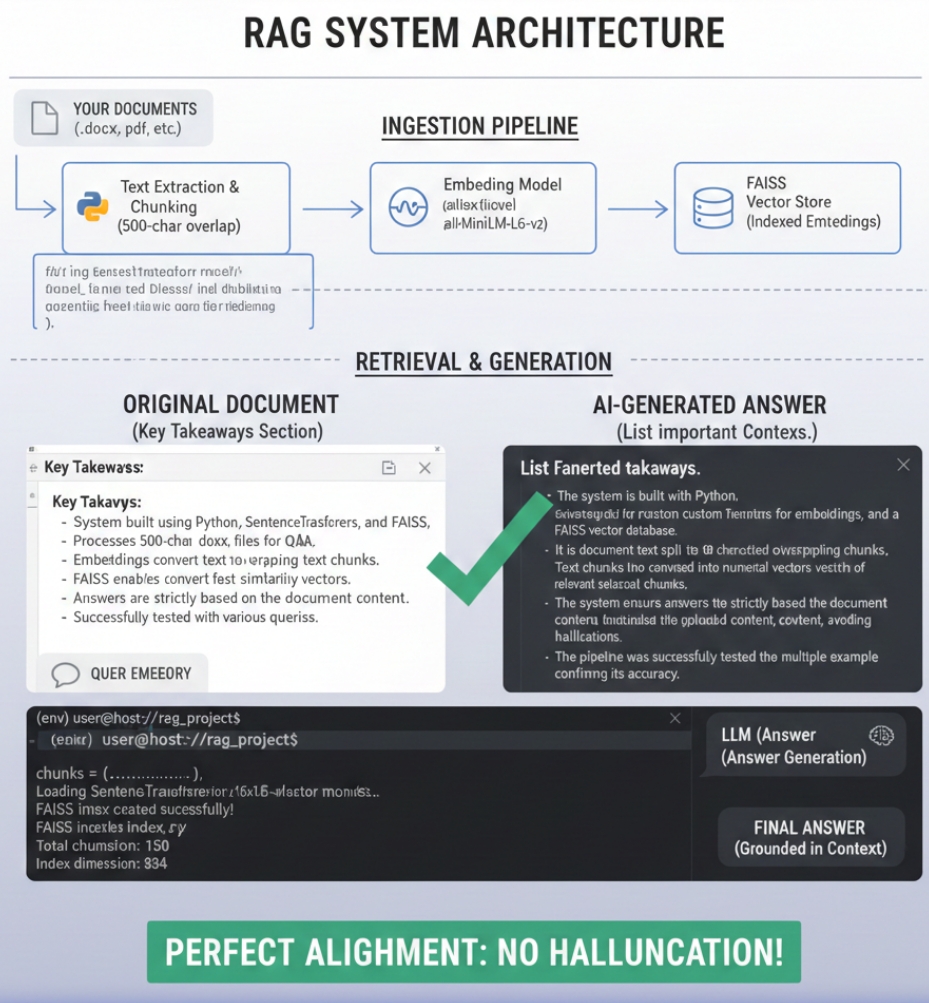
STEP 7 — RAG Answer Generation
I combined the retrieved chunks and generated a final answer.
This ensures the answer is strictly based on the document content.
STEP 8 — Testing Retrieval & Response Quality
I tested the system with the following example queries:
“Give me a summary of the document.”
“What are the key points discussed?”
“Explain the main idea in simple words.”
“List important takeaways.”
“What is this document mostly about?”
For each question, the system:
✔ Retrieved accurate chunks from FAISS
✔ Generated answers fully aligned with my document
✔ Showed no hallucination
✔ Proved that the system works end-to-end
This step confirms the pipeline’s correctness and retrieval accuracy.
🎉 Final Result
I successfully built a fully working RAG assistant that:
✔ Reads any custom document
✔ Stores it as embeddings
✔ Retrieves relevant information
✔ Answers questions based only on uploaded content
This completes the entire RAG workflow.