
In the era of exponential growth in artificial intelligence (AI) and machine learning (ML), terms like "reproducibility," "repeatability," and "replicability" are increasingly used but often misunderstood. While many papers in AI claim "reproducibility," they often only demonstrate "repeatability"—a far more limited form of validation. This article aims to clarify these distinctions and propose a higher standard for scientific rigor in AI research.
Repeatability: The ability to exactly recreate results using the same code and data.
Reproducibility: Independent teams achieving the same results using the original methodology.
Replicability: Obtaining consistent findings under varied conditions, such as different datasets or methods
BioMed Central
This delineation underscores the necessity for AI research to progress beyond mere repeatability towards genuine scientific rigor.
Most AI research today celebrates repeatability. Authors share GitHub repositories that regenerate charts, tables, and results exactly as seen in their papers. While this transparency is commendable and encourages open science, it often stops short of true reproducibility.
Repeatability simply ensures that the same pipeline, when re-run with the same data and code, yields the same results. But this doesn't necessarily verify the correctness or scientific validity of the experiment.
In contrast, reproducibility involves independent verification. A different team should be able to use the original methodology—ideally with modular, well-documented code and datasets—to test the implementation and confirm the findings.
Going even further, replicability examines whether similar conclusions can be reached under different conditions, such as new datasets or alternative analytical methods. This tests the generalizability of the research and adds robustness.
While sharing code and data repositories is commendable, the article emphasizes that this often only ensures repeatability. True reproducibility and replicability require:
Modular and well-documented codebases.
Comprehensive methodological details.
Validation across diverse datasets and conditions. readytensor.ai

The rise of automated code pipelines has made it easier than ever to regenerate results. But this convenience can be deceptive. A working script doesn't prove that the original experiment was well-designed or scientifically sound. In fact, over-reliance on these tools can discourage deeper engagement and critical thinking.
True scientific progress depends not only on sharing results but also on enabling others to rigorously interrogate and extend those results. Reproducibility is not about checking a box—it is about fostering a mindset that welcomes scrutiny and encourages collaboration.
Midway, as part of critique of automation culture _________________________________________________ [ One-Click Reproduction ] ↓ ✅ Same results on same data ❌ No insight into methodology ❌ No transparency or robustness Purpose: Contrasts superficial automation (“push-button reproducibility”) with genuine scientific rigor.
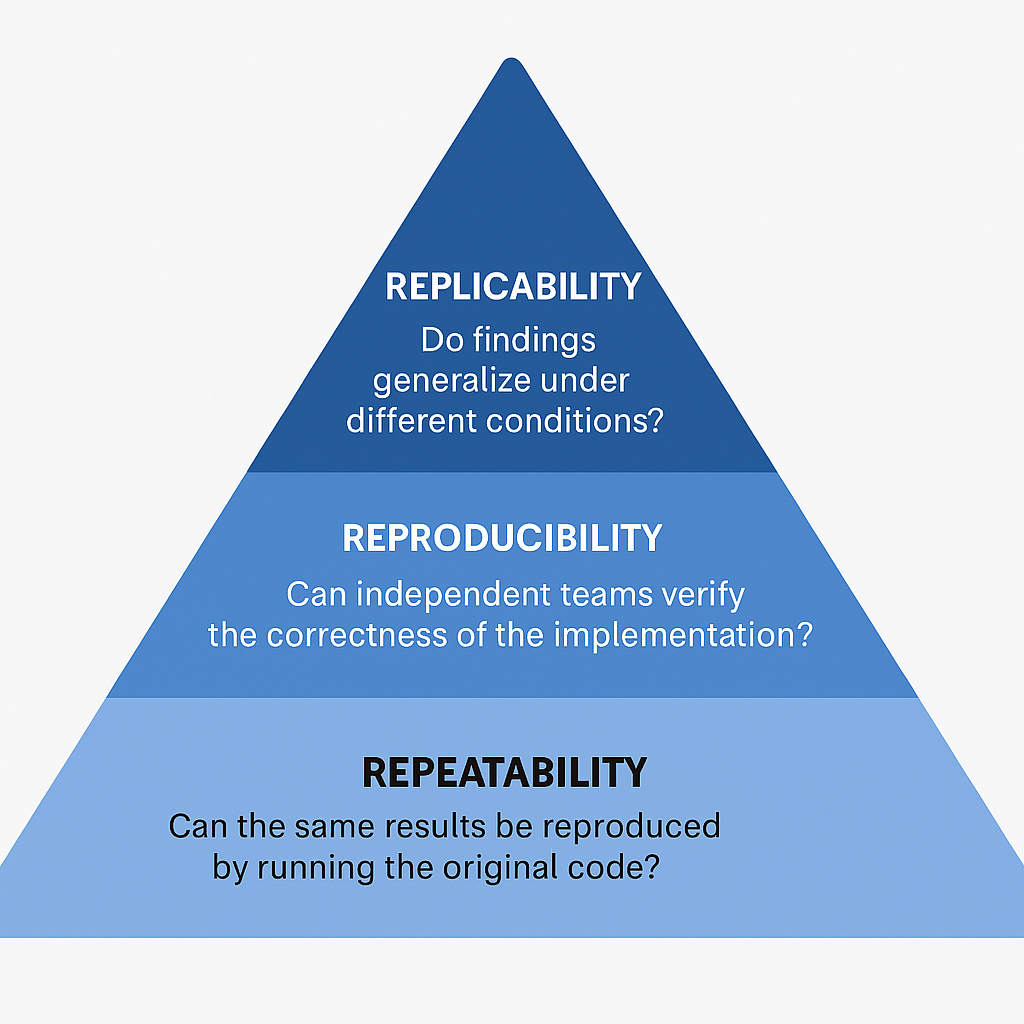
Each layer adds complexity—but also adds scientific value. Collectively, they form a pyramid of validation, with repeatability at the base and replicability at the top.
Achieving this vision requires a cultural shift. Conferences and journals must reward rigorous validation, not just novel results. Reviewers should look for evidence of reproducibility and replicability. Researchers should embrace transparency—not as an obligation, but as a path to greater impact.

Platforms like ReadyTensor are ideally positioned to lead this transformation. By facilitating open publication, modular code sharing, and collaborative validation, they can help set a new standard for scientific integrity in AI.

To enhance comprehension, the inclusion of a visual representation of the three-tiered framework is recommended. A pyramid diagram can effectively depict the progression from repeatability at the base to replicability at the apex.
"A Framework for Scientific Rigor in AI" section to visually reinforce the conceptual model.
For maximum clarity and publication-ready appeal, you should embed the following **visuals at key points**: - Validation Pyramid → After the “Framework for Scientific Rigor” section. - Comparison Chart (Repeatability vs. Reproducibility vs. Replicability) → Early in the paper to anchor definitions. - One-Click vs Scientific Reproducibility Diagram → Midway, to critique automation culture. - Ready Tensor Workflow Architecture → Near the community/cultural shift discussion. [ Scientific Consensus ] ▲ [Independent Replication ] ▲ [ Reproducible Results (New Data, New Methods) ] ▲ [ Reproducible Results (Same Data, Different Methods) ] ▲ [ Repeatability (Same Data, Same Methods) ] The hierarchy of validation in scientific inquiry, emphasizing that repeatability is the base, but true consensus is built at the top through rigorous and independent validation over time.
just a technical primer—it’s a philosophical statement on the direction of AI science:

It presents a visionary yet actionable path forward: AI mVII. Visualization Enhancements
ust transcend engineering tricks and embrace replicable, falsifiable, generalizable science.
Validation Pyramid (for Scientific Rigor)
[ Scientific Consensus ] ▲ [ Independent Replication ] ▲ [ Reproducible Results (New Data, New Methods) ] ▲ [ Reproducible Results (Same Data, Different Methods) ] ▲ [ Repeatability (Same Data, Same Methods) ] Purpose: Shows the hierarchy of validation in scientific inquiry, emphasizing that repeatability is the base, but true consensus is built at the top through rigorous and independent validation over time.
Comparison Table: Repeatability vs. Reproducibility vs. Replicability
| Term | Definition | Who Executes It | Data | Methods | Purpose |
|---|---|---|---|---|---|
| Repeatability | Ability to get the same results using the same setup, data, and method. | Same team | Same | Same | Verifies internal consistency of a single study. |
| Reproducibility | Ability to reproduce results using the same data but different methods. | Different team | Same | Different | Tests transparency and robustness of methods. |
| Replicability | Ability to achieve similar results using new data and similar methods. | Independent team | Different | Same/Similar | Validates generalizability and external validity. |
One-Click vs. Scientific Reproducibility Diagram
[ One-Click Reproduction ] ↓ ✅ Same results on same data ❌ No insight into methodology ❌ No transparency or robustness VS [ Scientific Reproducibility ] ↓ ✅ Result consistency with new data or methods ✅ Open methodology and parameter disclosure ✅ Enables peer scrutiny and trust Purpose: Contrasts superficial automation (“push-button reproducibility”) with genuine scientific rigor.
ReadyTensor Workflow Architecture
[ Data Ingestion ] → [ Model Definition Layer ] → [ Experiment Tracking ] ↓ ↓ ↓ [ Metadata Logging ] [ Config Management ] [ Artifact Storage ] ↓ ↓ ↓ [ Reproducibility Engine ] ← [ Version Control & Audit ] ↓ [ Community Publishing Portal ] Purpose: Illustrates the technical backbone of ReadyTensor’s reproducibility-focused ecosystem, highlighting integration points that support open science and community validation.
| For Researchers | For Reviewers | For Industry |
|---|---|---|
| Modularize code, document methods, invite independent replication. | Demand clarity, method reuse, and dataset variability. | Adopt reproducible benchmarks before model deployment. |
| Treat reproducibility as a scientific ethic. | Reward replicable findings over benchmark state-of-the-art. | Push vendors to open-code safety-critical AI modules. |
In a field accelerating faster than its norms can stabilize, the reproducibility crisis in AI is not a side issue—it is a central threat to credibility. The terms repeatability, reproducibility, and replicability are not just semantic distinctions; they represent a hierarchy of scientific validation essential for building trustworthy, transferable, and testable AI systems.
Repeatability is foundational—it shows that code executes and results regenerate. But it is not enough. Reproducibility, achieved by independent teams applying the same methodology, tests whether results are methodologically sound and transparent. Replicability, the apex of scientific rigor, demonstrates that findings generalize across contexts, data, and time.
Today’s over-reliance on "push-button reproducibility" and automated pipelines risks reducing science to output replication without understanding. To truly mature, AI must embrace a deeper commitment to methodological clarity, community verification, and open scientific culture.
Platforms like ReadyTensor represent this next phase—where infrastructure supports not just deployment, but disciplinary accountability. By enabling metadata tracking, version control, and community validation, such ecosystems offer a blueprint for AI to transition from a field of impressive demos to a science of defensible knowledge.
Reproducibility is not a benchmark—it's a covenant with the future.
In an era defined by accelerating innovation, the reproducibility crisis in AI is not peripheral—it is existential. Terms like repeatability, reproducibility, and replicability are not academic nuance. They form a scientific hierarchy—a scaffold upon which reliable, responsible AI must be built.
Today, most research stops at repeatability—a necessary but insufficient step. Over-reliance on automated pipelines and "one-click reproducibility" obscures methodological depth and discourages scrutiny. True progress demands more than regenerating outputs; it requires transparency, collaboration, and independent validation.
Platforms like ReadyTensor are instrumental to this transition. Their infrastructure—emphasizing modularity, experiment tracking, auditability, and community publishing—does more than scale models. It institutionalizes accountability.
⚖️ Reproducibility is not a benchmark. It’s a covenant with the future. Let’s move beyond leaderboard chasing. Let’s ask not just “Can this be rerun?” but “Can this be trusted?” Because the integrity of AI—and its safe, just integration into human society—depends on scientific rigor, not speed.
#AIReproducibility #ScientificRigor #TrustworthyAI #OpenScience #Replicability #ReadyTensor #MLValidation #ReproducibleResearch
Let us move beyond leaderboard chasing. Let us raise the bar from can we re-run this code to can we trust this claim. The credibility of AI, and its responsible integration into high-stakes domains, depends on it.
Note: To further enhance the publication, consider incorporating the following visual elements using ReadyTensor's Markdown capabilities: Validation Pyramid Diagram: Illustrate the hierarchy from repeatability to replicability. Comparison Table: Detail differences between repeatability, reproducibility, and replicability. One-Click vs. Scientific Reproducibility Diagram: Contrast superficial automation with genuine scientific rigor.
# Repeatability: Consistent Results with Identical Setup import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.datasets import make_classification from sklearn.metrics import accuracy_score # Set random seed for reproducibility np.random.seed(42) # Generate synthetic dataset X, y = make_classification(n_samples=1000, n_features=20, random_state=42) # Split dataset X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Initialize and train model model = LogisticRegression(random_state=42) model.fit(X_train, y_train) # Evaluate model predictions = model.predict(X_test) accuracy = accuracy_score(y_test, predictions) print(f"Accuracy: {accuracy:.2f}")
Key Point
# Reproducibility: Independent Verification Using the Same Methodology import numpy as np from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # Set seed for reproducibility np.random.seed(42) # Create dataset features, labels = make_classification(n_samples=1000, n_features=20, random_state=42) # Split data X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42) # Train model classifier = LogisticRegression(random_state=42) classifier.fit(X_train, y_train) # Predict and evaluate y_pred = classifier.predict(X_test) acc = accuracy_score(y_test, y_pred) print(f"Reproduced Accuracy: {acc:.2f}")
Key Point

# Replicability: Consistent Findings Under Varied Conditions import numpy as np from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # Set seed for reproducibility np.random.seed(24) # Generate a different synthetic dataset X_new, y_new = make_classification(n_samples=1000, n_features=20, random_state=24) # Split dataset X_train_new, X_test_new, y_train_new, y_test_new = train_test_split(X_new, y_new, test_size=0.2, random_state=24) # Initialize and train model model_new = LogisticRegression(random_state=24) model_new.fit(X_train_new, y_train_new) # Evaluate model predictions_new = model_new.predict(X_test_new) accuracy_new = accuracy_score(y_test_new, predictions_new) print(f"Replicated Accuracy on New Data: {accuracy_new:.2f}")
Key Point
🧠 **Final Note: Science, Not Scripts** True progress in AI doesn’t come from running the same code—it comes from asking if the result still holds when the code, the data, or even the team changes. Reproducibility isn’t a feature; it’s a foundation. 📌 **Disclaimer:** The views expressed here reflect a commitment to scientific rigor and open research culture. They do not represent the stance of any single institution or platform, including ReadyTensor.