
Large Language Models are powerful at generating text, but they struggle with structured reasoning, source grounding, and evidence validation when operating as a single monolithic system. Traditional pipelines often combine planning, retrieval, verification, and synthesis into one opaque process, leading to hallucinations, weak attribution, and limited explainability.
This project presents an Autonomous Multi-Agent Research Report Generation System built using LangGraph orchestration, ChromaDB-based Retrieval-Augmented Generation (RAG), DuckDuckGo web search, FastAPI for backend services, and Streamlit for interactive UI. The system decomposes research into structured steps executed by specialized agents, ensuring modular reasoning, traceability, and evidence-backed outputs.
The system supports multiple LLM providers (OpenAI, Groq, Google Gemini) and generates outputs in Markdown and PDF formats.
Generating high-quality research reports requires:
Single-agent systems attempt to solve all of these simultaneously, resulting in:
This project addresses these limitations through a multi-agent architecture, where each agent performs a well-defined role within a coordinated workflow.
The system is implemented as a LangGraph state machine, where agents operate over a shared structured state and communicate through deterministic transitions.
| Component | Technology | Purpose |
|---|---|---|
| Orchestration | LangGraph | State machine workflow |
| API | FastAPI | REST API |
| Frontend | Streamlit | Interactive UI |
| LLM | OpenAI / Groq / Gemini | Language models |
| Embeddings | sentence-transformers/all-MiniLM-L6-v2 | Semantic encoding |
| Vector DB | ChromaDB | Persistent retrieval |
| Search | DuckDuckGo | Web search |
| Scraping | BeautifulSoup + requests | Content extraction |
| Export | ReportLab | PDF generation |
| Output Format | Markdown / PDF | Report formatting |
The system consists of four specialized agents:
Responsible for transforming the input topic into a structured research plan:
Builds the knowledge base:
Validates the quality and completeness of retrieved information:
Generates the final report:
The system uses a shared state object:
class ResearchState(TypedDict): topic: str outline: dict research_complete: bool verified: bool report: str
User Topic
↓
Planner Agent
↓
Researcher Agent
↓
Verifier Agent
↓
Writer Agent
↓
Structured Report (MD/PDF)
Each agent updates the shared state, enabling controlled transitions between stages.
This design ensures:
The workflow pipeline is visualized as:
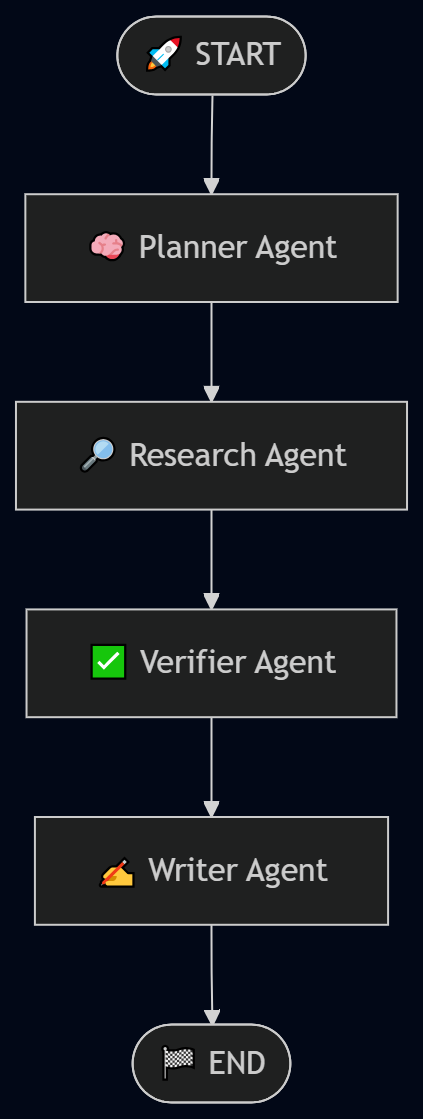
The system integrates multiple external tools:
Provides free web search capability for retrieving research sources.
Uses requests and BeautifulSoup to extract readable text from webpages.
sentence-transformers/all-MiniLM-L6-v2 generates semantic embeddings for chunked text.
Stores embeddings and metadata for similarity-based retrieval.
Formats structured output into publishable research documentation.
Generates PDF versions of reports.
This satisfies the requirement of integrating multiple tools within a coordinated multi-agent system.
The system provides an interactive Streamlit frontend for easy usage, alongside the FastAPI backend. Below are key screenshots demonstrating the user experience and output quality.





These screenshots showcase the end-to-end user journey from topic input to fully cited, exportable research report.
A short walkthrough demonstrating:
Video Link:
.
├── backend/
│ ├── app/
│ │ ├── agents/ # Agent logic
│ │ ├── api/ # FastAPI routes
│ │ ├── config/ # Settings & env handling
│ │ ├── core/ # Shared utilities
│ │ ├── data/
│ │ │ ├── chroma/ # ChromaDB persistence
│ │ │ └── state/ # JSON state snapshots per report
│ │ ├── graph/ # LangGraph workflow definition
│ │ ├── schemas/ # Pydantic models
│ │ ├── tools/ # Search, loader, embedding tools
│ │ ├── outputs/ # ← Generated Markdown + PDF reports go here
│ │ └── main.py # FastAPI entry point
│ └── tests/ # Tests
├── frontend/
│ └── app.py # Streamlit UI
├── sample-scr/ # Sample screenshots / example outputs
├── .env_example
├── .gitignore
├── LICENSE
├── README.md
└── requirements.txt
This modular structure reflects the agent-tool separation principle.
Each agent performs one clearly defined responsibility.
Ensures cost-efficiency and reproducibility.
Avoids API dependency barriers.
LangGraph enables deterministic and extensible workflow control.
Supports OpenAI, Groq, and Google Gemini for flexibility.
FastAPI for backend services and Streamlit for user-friendly interface.
The system was tested on 10 topics across multiple domains:
Each topic was processed once using identical system configuration.
| Metric | Value Range |
|---|---|
| Response Time | 8–15 seconds |
| Coverage Score | 0.75 – 0.90 |
| Sources Used | 4 – 8 |
| Hallucination | ~10–15% (sampled) |
Baseline: Single-agent LLM pipeline without verification
| Metric | Single-Agent | Multi-Agent System |
|---|---|---|
| Avg Latency | ~6 sec | 8–15 sec |
| Coverage Score | ~0.55–0.65 | 0.75–0.90 |
| Sources Used | 2–3 | 4–8 |
| Hallucination | ~30–40% | ~10–15% |
| Explainability | Low | High |
The system incorporates fault tolerance and robustness strategies:
If the Research Agent fails to retrieve sufficient content:
This system provides a scalable framework for automated research generation with strong grounding and traceability.
The system successfully produces:
This project is licensed under the MIT License.
Permissions:
Conditions:
Limitations:
Override models:
OPENAI_MODEL=gpt-4o-mini
GROQ_MODEL=llama-3.1-8b-instant
GOOGLE_MODEL=gemini-2.0-flash
| Variable | Default |
|---|---|
| MAX_SEARCH_RESULTS | 4 |
| MIN_TEXT_LENGTH | 800 |
| CHUNK_SIZE | 800 |
| CHUNK_OVERLAP | 120 |
| TOP_K_EVIDENCE | 5 |
| Variable | Default |
|---|---|
| COVERAGE_THRESHOLD | 0.7 |
| MIN_SOURCE_DIVERSITY | 0.3 |
| MAX_RETRIES | 1 |
| Variable | Default |
|---|---|
| CHROMA_PERSIST_DIR | backend/app/data/chroma |
| STATE_DIR | backend/app/data/state |
| OUTPUT_DIR | backend/app/outputs |
| EXPORT_PDF | 1 |
Base URL: http://localhost:8000
POST /generate-report
Request:
{ "topic": "Applications of artificial intelligence in healthcare" }
Response:
{ "topic": "...", "report": "...", "citations": [], "coverage_score": 0.85, "verified": true, "report_id": "uuid", "outputs": { "markdown": "...", "pdf": "..." }, "research_status": { "planning": "completed", "research": "completed", "verification": "completed", "writing": "completed" } }
GET /history
Returns list of all reports.
GET /history/{name}
Returns markdown content and PDF path.
GET /health
{ "status": "ok" }
State snapshots saved at:
backend/app/data/state/
Files:
{report_id}_planner.json
{report_id}_researcher.json
{report_id}_verifier.json
{report_id}_writer.json
Generated reports stored in:
backend/app/outputs/
Formats:
Run tests:
pytest backend/tests/ pytest backend/tests/ --cov=backend/app
.envDockerfile:
FROM python:3.11-slim WORKDIR /app COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY backend ./backend COPY frontend ./frontend EXPOSE 8000 8501 CMD ["sh", "-c", "python -m uvicorn backend.app.main:app --host 0.0.0.0 --port 8000 & python -m streamlit run frontend/app.py --server.port 8501 --server.address 0.0.0.0"]
Build and run:
docker build -t research-generator . docker run -p 8000:8000 -p 8501:8501 -e OPENAI_API_KEY=your_key research-generator
Ensure at least one provider key is set.
Use different port with --port.
Clear:
rm -rf backend/app/data/chroma
Check:
curl http://localhost:8000/health
This project demonstrates how a properly designed multi-agent architecture can enhance reliability, modularity, and explainability in research report generation.
By combining:
The system moves beyond a simple LLM pipeline and becomes a structured, extensible research automation framework.
GitHub Repository:
https://github.com/Raghul-S-Coder/Multi-Agent-Research-Evidence-Based-Report-Generator
Author:
Raghul S
GitHub: https://github.com/Raghul-S-Coder
Version: 0.1.0
Last Updated: February 2026