
ApplyAI is a production-deployed multi-agent AI system that automates the job application process. Given a resume (PDF) and any form of job input — a URL, company website, company name, or pasted description — the system orchestrates five specialized AI agents to parse the resume, research the role, match skills, generate a tailored cover letter, and critique and polish the output. Built with LangGraph for agent orchestration, LangChain for LLM abstraction, and FastAPI for the backend, it is deployed with a React/Vite frontend on Vercel and a Railway-hosted API. This publication documents the multi-agent architecture, implementation decisions, deployment strategy, and lessons learned.
Writing a tailored cover letter for every job application is time-consuming and cognitively demanding. A good cover letter requires understanding the job requirements, identifying relevant skills from your background, framing your experience compellingly, and polishing the final output — four distinct tasks that most people do sequentially and imperfectly.
General-purpose LLMs can help, but a single prompt asking an LLM to "write me a cover letter" produces generic, placeholder-filled output because the model lacks structured access to both the resume and the job details simultaneously. It also cannot route different types of job input (a LinkedIn URL vs. a company name vs. a pasted description) or perform web scraping to extract job details from live pages.
ApplyAI is a complete agentic system that solves this problem end-to-end:
This project demonstrates several important capabilities in modern AI engineering:
The system uses a LangGraph StateGraph to orchestrate five agents in a directed workflow with a parallel fan-out pattern:
┌─────────────────┐
│ input_router │
│ Classifies job │
│ input type │
└────────┬────────┘
│ Fan-out (parallel)
┌──────────────┴──────────────┐
▼ ▼
┌──────────────────┐ ┌───────────────────┐
│ resume_analyzer │ │ job_researcher │
│ Extracts skills │ │ Scrapes/infers │
│ + personal info │ │ job description │
│ from PDF │ │ + extracts skills│
└──────────┬───────┘ └─────────┬─────────┘
│ │
└──────────────┬────────────┘
│ Fan-in
▼
┌─────────────────────┐
│ application_generator│
│ Matches skills, │
│ generates cover │
│ letter │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ critic_agent │
│ Polishes letter, │
│ removes commentary │
└──────────┬──────────┘
│
▼
END
All agents communicate through a shared AgentState TypedDict. LangGraph requires every field to have a reducer function when parallel fan-out is used — without this, concurrent state writes from two nodes cause an InvalidUpdateError. The state uses two custom reducers:
def _keep_last(a, b): """Last non-empty value wins — for strings and dicts.""" return b if b else a def _merge_lists(a: list, b: list) -> list: """Keep whichever list is non-empty — for skill lists.""" return b if b else a class AgentState(TypedDict): resume_text: Annotated[str, _keep_last] user_input: Annotated[str, _keep_last] input_type: Annotated[str, _keep_last] job_description: Annotated[str, _keep_last] scraped_job_title: Annotated[str, _keep_last] personal_info: Annotated[Dict, _keep_last] resume_skills: Annotated[List[str], _merge_lists] job_skills: Annotated[List[str], _merge_lists] match_results: Annotated[Dict, _keep_last] cover_letter: Annotated[str, _keep_last] improved_cover_letter:Annotated[str, _keep_last]
| Component | Technology | Role |
|---|---|---|
| Agent Orchestration | LangGraph | Stateful graph, parallel execution, routing |
| LLM Framework | LangChain | Prompt templates, LLM abstraction, output parsers |
| LLM Provider | Groq (Llama 3.1 8B / 3.3 70B) | Fast inference for generation and critique |
| Resume Parsing | pdfplumber | PDF text extraction |
| Web Scraping | requests + BeautifulSoup | Job posting and company website scraping |
| Skill Matching | Python difflib (SequenceMatcher) | Fuzzy skill comparison |
| Backend | FastAPI + Uvicorn | REST API, file upload handling |
| Frontend | React 18 + Vite + CSS Modules | Chat-style results dashboard |
| Backend Hosting | Railway | Persistent server, no serverless timeout |
| Frontend Hosting | Vercel | Static site CDN |
The input router classifies the user's job input into one of four categories: job_url, company_website, company_name, or job_description. This classification determines how the job_researcher agent processes the input downstream.
JOB_URL_PATTERNS = re.compile( r"(jobs|careers|job|career|position|vacancy|opening|posting|apply)", re.IGNORECASE, ) def input_router(state: dict) -> dict: user_input = state["user_input"].strip() # URL detection via regex if re.match(r"https?://", user_input): if JOB_URL_PATTERNS.search(user_input): state["input_type"] = "job_url" else: state["input_type"] = "company_website" return state # LLM classification for plain text prompt = f"""Classify this input as exactly one of: - company_name - job_description Reply with only the label. Input: \"\"\"{user_input}\"\"\"""" response = llm.invoke(prompt) label = response.content.strip().lower() # Sanitize with heuristic fallback if label not in ("company_name", "job_description"): label = "job_description" if len(user_input.split()) > 20 else "company_name" state["input_type"] = label return state
Design decision: URL classification uses regex (fast, no LLM cost). Text classification uses an LLM with an explicit fallback heuristic — if the LLM returns an unexpected label, long inputs are treated as descriptions and short inputs as company names.
The resume analyzer runs in parallel with the job researcher. It performs two tasks:
prompt = f"""Extract ALL technical and professional skills from the resume. Normalize skill names (e.g. "MS Azure" → "Microsoft Azure"). Return ONLY a valid JSON array of strings. No explanation. Resume: {resume_text}"""
The LLM is instructed to normalize skill names (e.g., "AWS" → "Amazon Web Services (AWS)") so they align with how job postings phrase the same skills — a critical step for accurate matching.
The job researcher handles all four input types differently:
| Input Type | Strategy |
|---|---|
job_url | Scrape the URL, extract job description text |
company_website | Scrape homepage, use LLM to infer a realistic job description |
company_name | Use LLM to generate a realistic job description for that company |
job_description | Use the text directly |
The web scraper uses BeautifulSoup with a priority strategy — it first looks for job-specific CSS containers (classes matching job, description, career, etc.), then falls back to all meaningful tags (p, li, h1–h4, span, div). This extracts up to 8,000 characters of relevant content even from job sites that don't follow standard markup conventions.
After resolving the description, the agent extracts required skills using the same JSON-format LLM prompt used by the resume analyzer, ensuring consistent normalization between the two skill lists.
The naive approach — exact set intersection of skill lists — produces a 0% match score for obvious reasons: "Azure" never matches "Microsoft Azure", and "AWS" never matches "Amazon Web Services (AWS)". The fuzzy matcher uses Python's SequenceMatcher with substring containment:
def _fuzzy_match(a: str, b: str, threshold: float = 0.82) -> bool: a, b = a.lower().strip(), b.lower().strip() if a == b: return True if a in b or b in a: # handles abbreviations return True return SequenceMatcher(None, a, b).ratio() >= threshold
This correctly matches:
"AWS" ↔ "Amazon Web Services (AWS)" (substring containment)"scikit-learn" ↔ "sklearn" (fuzzy ratio)"REST API" ↔ "REST APIs" (fuzzy ratio)The application generator is where the cover letter is created. Earlier versions used only skill lists as input, producing generic output with placeholder text ([Your Name], [Company Name]). The improved version passes:
prompt = f"""You are a professional career coach writing a cover letter. APPLICANT: {candidate_name} | {candidate_email} | {candidate_phone} DATE: {today} FULL RESUME: {resume_text} JOB DESCRIPTION: {job_description} SKILL MATCH: {score}% — Matched: {matched} | To address: {missing[:6]} INSTRUCTIONS: - Use the applicant's REAL name and contact details — never use placeholders - Highlight 2–3 specific achievements from the resume most relevant to the role - For missing skills, briefly acknowledge eagerness to grow — do not dwell on gaps - Output ONLY the cover letter — no preamble or notes """
The critic agent uses a stronger model (llama-3.3-70b-versatile) to review and polish the generated letter. A persistent problem with LLM critics is that they append "Improvements made:" commentary after the polished letter. The critic agent addresses this with:
cutoff_phrases = [ "improvements made", "changes made", "notes:", "here's what i changed", "explanation:", "i made the following", ] lower = letter_text.lower() for phrase in cutoff_phrases: idx = lower.find(phrase) if idx != -1: letter_text = letter_text[:idx].strip()
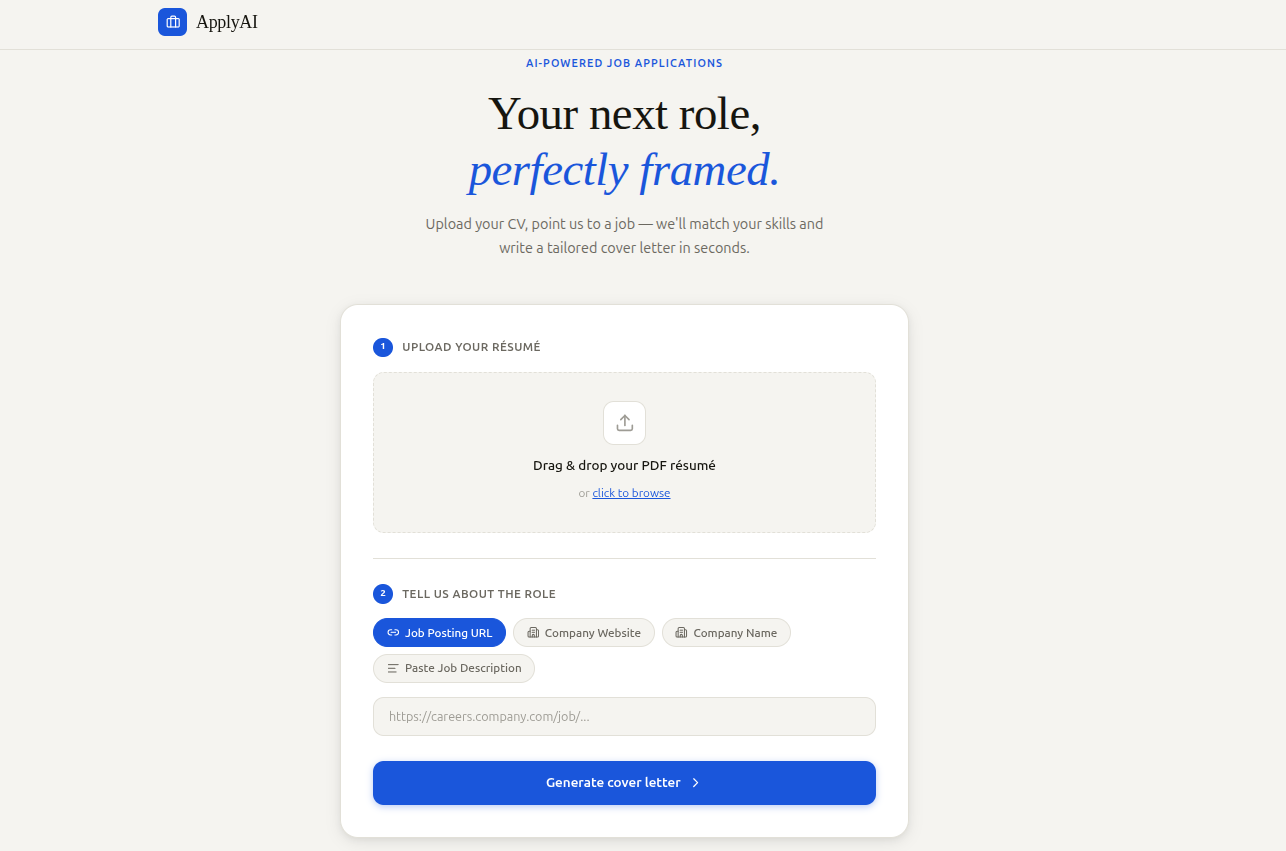
The upload page accepts a PDF resume via drag-and-drop (react-dropzone) and job input via four selectable modes: Job Posting URL, Company Website, Company Name, or Paste Job Description. While the agents are running, an animated progress bar cycles through human-readable status messages ("Parsing your resume…", "Researching the role…", "Matching your skills…") to communicate progress during the ~30–60 second pipeline execution.
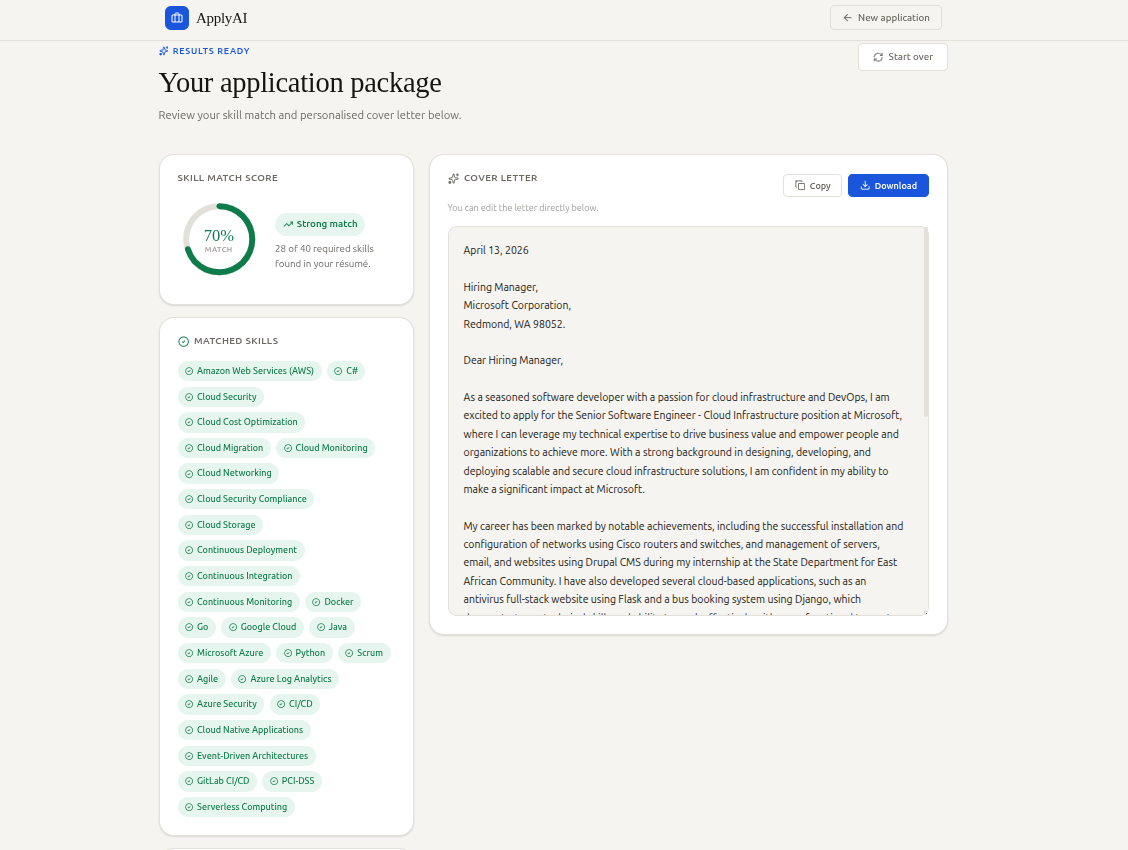
The results page presents three panels:
Skill Match Score — an animated SVG ring chart showing the fuzzy match percentage. The ring color is green (≥70%), yellow (≥40%), or red (<40%) with a verdict label ("Strong match", "Moderate match", "Low match").
Matched / Missing Skills — color-coded pill badges. Matched skills appear in green, missing skills in red. Lists longer than 8 items collapse with a "Show more" toggle.
Cover Letter Panel — a full-height editable textarea pre-populated with the polished cover letter. Copy-to-clipboard and download-as-txt buttons are provided. Users can edit the letter directly in the browser before using it.
The FastAPI backend is deployed on Hugging Face Spaces as a persistent Docker container. Serverless platforms (Vercel Functions) and Railway were ruled out because:
The LangGraph pipeline can take 30–60 seconds to complete (scraping + 3 LLM calls)
Vercel's free tier enforces a 10-second function timeout
Railway's free tier expires after 30 days
Hugging Face Spaces runs the application as a persistent Docker container with no execution time limit, no sleep on inactivity, and no free tier expiry:
dockerfileFROM python
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 7860
CMD ["python", "-m", "uvicorn", "api
", "--host", "0.0.0.0", "--port", "7860"]Missing README metadata — HF Spaces requires a README.md with a YAML front matter block (sdk: docker) at the repository root. Without it, the Space shows a "Configuration error" and refuses to build.
Missing dependencies — requirements.txt was missing uvicorn and pdfplumber because they were installed in the local virtual environment but not captured in the freeze. Regenerating with pip freeze > requirements.txt from the active venv resolved this.
Initial push rejection — HF auto-initializes Spaces with a commit, causing a non-fast-forward push error on first push. Fixed with git push hf main --force.
The Vite React frontend is deployed as a static site:
Root directory: frontend/
Build command: npm run build
Output directory: dist
The Vite dev proxy (/api → http://localhost:8000) handles local development. In production, axios.post('https://fahiye-applyai-backend.hf.space/analyze', ...) calls the HF Space backend directly with no proxy needed. Since the frontend and backend are on different domains, the FastAPI backend has allow_origins=["*"] set via CORSMiddleware.
job-application-agent/
├── api.py # FastAPI entry point
├── main.py # CLI entry point
├── Procfile # Railway start command
├── requirements.txt
├── agents/
│ ├── input_router.py # Agent 1: classify input
│ ├── resume_analyzer.py # Agent 2: extract resume skills
│ ├── job_researcher.py # Agent 3: research job + skills
│ ├── application_generator.py # Agent 4: generate cover letter
│ └── critic_agent.py # Agent 5: polish cover letter
├── graph/
│ ├── agent_workflow.py # LangGraph StateGraph definition
│ └── state.py # AgentState with Annotated reducers
├── tools/
│ ├── resume_parser.py # pdfplumber + personal info regex
│ ├── job_scraper.py # BeautifulSoup web scraper
│ └── skill_matcher.py # Fuzzy SequenceMatcher
└── frontend/
├── src/
│ ├── App.jsx # Router + state
│ ├── pages/
│ │ ├── UploadPage.jsx # Drag-drop + input form
│ │ └── ResultsPage.jsx # Match dashboard + letter editor
│ └── components/
│ └── Navbar.jsx
└── vite.config.js
The most technically significant lesson was that LangGraph's parallel execution requires every state field to have an explicit reducer function — not just the fields written by parallel nodes. When resume_analyzer and job_researcher both return the full state dict, LangGraph tries to merge all fields simultaneously. Without reducers, this raises InvalidUpdateError: Can receive only one value per step.
The fix — wrapping every field with Annotated[type, reducer_fn] — is not prominent in LangGraph's documentation for simple sequential graphs. It only becomes necessary when adding parallel edges.
The original skill matcher used exact set intersection and produced a 0% match score. The root cause was not the matching algorithm — it was inconsistent normalization. "Azure" and "Microsoft Azure" are the same skill, but without normalization they are different strings.
The solution has two parts: (1) prompt the LLM skill extractors to normalize to full canonical names, and (2) use fuzzy matching with substring containment as a safety net. Both are necessary — LLM normalization is imperfect, and fuzzy matching catches the cases the LLM misses.
The first version of the application generator passed only skill lists to the LLM. The output was generic because the LLM had no knowledge of the candidate's actual experience, projects, or achievements. Passing the full resume text (even at 2,000+ tokens) dramatically improved specificity — the LLM could reference real projects, real employers, and real accomplishments.
The practical concern about token costs is real but manageable: at Groq's free tier, even a 3,000-token resume adds negligible latency and zero cost.
Instructing an LLM to "improve this cover letter" consistently produces the improved letter followed by "Improvements made: 1. Clarity..." commentary. This is the default behavior of instruction-tuned models, which are trained to explain their reasoning.
Two countermeasures work together: (1) strong explicit prompt instructions to output only the letter, and (2) deterministic post-processing that truncates at known commentary phrases. The post-processing acts as a safety net for the cases where the LLM ignores the prompt instruction.
Not all company websites are scrapable. Single-page React apps render content in the browser, not in the raw HTML. Some sites block scrapers via user-agent filtering. The scraper handles these cases with a cascade:
The job researcher also falls back gracefully: if the input type is company_website but the scraped content is empty, it prompts the LLM to generate a realistic job description based on the company name extracted from the URL.
requests + BeautifulSoup. A headless browser (Playwright, Selenium) would be required for these.StreamingResponse and server-sent events on the frontend — renders the letter token-by-token as it is generated# Clone the repository git clone https://github.com/fahiyemuhammad/job-application-agent.git cd job-application-agent # Create and activate virtual environment python -m venv venv source venv/bin/activate # Windows: venv\Scripts\activate # Install dependencies pip install -r requirements.txt # Set environment variables echo "GROQ_API_KEY=your_key_here" > .env # Run the CLI version python main.py # Or start the FastAPI backend uvicorn api:app --reload --port 8000
# Frontend (separate terminal) cd frontend npm install npm run dev
Open http://localhost:5173.
| Variable | Required | Description |
|---|---|---|
GROQ_API_KEY | Yes | Groq API key for LLM inference |
Backend (Railway):
cd src && uvicorn api:app --host 0.0.0.0 --port $PORTGROQ_API_KEY environment variableFrontend (Vercel):
frontend/npm run build | Output: distUploadPage.jsx)ApplyAI demonstrates that multi-agent systems built with LangGraph can solve real, practical problems in a production-deployable way. The key architectural insight is the separation of concerns across agents — each agent does one thing well, and LangGraph's stateful graph handles the coordination, including parallel execution that would otherwise require complex async programming.
The most important engineering lessons from this project are: parallel LangGraph nodes require Annotated state reducers, skill matching quality depends on normalization before matching, LLM critics need deterministic post-processing to suppress commentary, and full resume context produces dramatically better cover letters than skill lists alone.
The full source code is available in the linked repository.
This project is released under the MIT License. You are free to use, modify,
distribute, and build upon this work for both personal and commercial purposes,
provided the original copyright notice is retained. See the
LICENSE
file in the repository for full terms.