Click here the see the project's Github repository.
The Ambience-to-Music Neural Style Transfer (AM-NST) system leverages deep learning to transform the style of ambient audio into musical content by reconstructing audio from a Mel-spectrogram. AM-NST utilizes a custom-designed convolutional neural network (CNN) to compare the Mel-spectrograms of target, content, and style audio at varying abstraction levels. This comparison enables the extraction of both broad features (e.g. timbre) and fine-grained details (e.g. acoustics). The system modifies the target Mel-spectrogram using gradient descent, optimizing for both style and content loss. The final output is an audio signal synthesized from the target Mel-spectrogram after a series of iterations. This end-to-end process, encompassing audio pre-processing and post-processing, marks a novel approach to Neural Style Transfer (NST) applied to music, an area less explored compared to visual arts. By emulating style, AM-NST aims to contribute to our understanding of creativity and its computational modeling.
This project presents the Ambience-to-Music Neural Style Transfer (AM-NST) system, an AI-based method for transferring the style of ambient audio to a musical content piece using Neural Style Transfer (NST). By leveraging a custom-built genre-classification Convolutional Neural Network (CNN), AM-NST operates on Mel-spectrograms, which are visual representations of audio that encode the frequencies (in Mel scale) amplitudes across time.
The idea is to use the Mel-spectrograms of a musical audio signal (the "content") and an ambient audio signal (the "style") to combine them to modify a third Mel-spectrogram, which is either a copy of the content/style Mel-spectrogram, or a new zero-valued Mel-spectrogram. This third Mel-spectrogram –the target – represents an audio signal that retains the content audio's harmonic and melodic structure while being infused with the timbre, texture, and acoustics of the style audio. The final step is to convert the created Mel-spectrogram to an audio signal (hence, the Mel-spectrograms constructed from the content and style audio signals must retain enough information to allow for the reconstruction audio signals).
AM-NST uses the identity and/or convolutional layers of a custom-built genre-classification CNN to compare the Mel-spectrogram of the target audio to the Mel-spectrograms of the content and style audio at different levels of abstraction (each convolutional layer extracts features from the Mel-spectrogram; the deeper the layer, the higher the level of measurement/detail omission, i.e. of abstraction). Comparisons at higher levels of abstraction indicate differences in broader features (e.g. timbre, aural texture, etc.), while comparisons at lower levels indicate differences in narrower, i.e. more fine-grained features (e.g. content, acoustics, etc.).
The target Mel-spectrogram is modified using gradient descent. The loss function used for gradient descent has two components: (1) style loss, calculated as the mean squared error of the Gram matrices of the target and style Mel-spectrograms, (2) content loss is calculated as the mean squared error of the content and target Mel-spectrograms. The loss function is the weighted sum of the content loss and style loss, whicha re weighted by the content weight and the style weight respectively. The gradient of the loss function is then obtained and applied to the target Mel-spectrogram. Gradient descent is done in this way for a set number of iterations, after which the target Mel-spectrogram is converted to an audio signal that can be listened to.
An art piece's style represents the way the piece's features interact with each other, i.e. it represents a method/approach to creativity. Thus, learning to emulate style is a step toward expanding our understanding of creativity. Hence, the goal of this project is to expand our understanding of creativity by learning to emulate styles in music, which is a relatively less researched area in deep learning. The end-to-end process integrates audio pre-processing, style transfer, and post-processing to deliver a seamless user experience. The results themselves are noisy, but the project as a whole demonstrates a comprehensive approach in experimenting with audio neural style transfer, while also demonstrating the challenges inherent in the approach.
Neural Audio Style Transfer - CMPUT 466
This project delves into similar applications of audio style transfer, presenting insights into its implementation and challenges.
Audio Style Transfer by Kevin Lin
A report that discusses the technical and theoretical aspects of transferring audio styles, offering valuable context for this project.
Neural style transfer uses layers of a genre classification CNN (details below). Genre classification is expected to extract and use a piece's style; hence it is used as the basis for audio NST. The methodology is divided into two sections: (1) building and designing a suitable CNN for audio NST, and (2) outlining and describing the NST process.
Inputs were Mel-spectrogram segments with 384 Mel-bands and 431 frames each. The Mel-spectrograms segments were obtained by (1) using the sampling rate 22050 Hz, FFT window size 1024 and hop length 256 and (2) segmenting track-wise Mel-spectrograms into segments 431 frames (corresponding to ~5 seconds of audio). The sampling rate was chosen because that was the sampling rate of the training data. The other parameters were chosen based on the most memory-efficient parameters observed (experimentation was done in the audio preprocessing demo notebook) that would retain audio quality upon reconversion of the Mel-spectrogram to a raw audio signal.
| Layer | Input shape | Parameters |
|---|---|---|
| Input | (None, 384, 431, 1) | 0 |
| Identity * | (None, 384, 431, 1) | 0 |
| Batch normalisation 1 | (None, 384, 431, 1) | 4 |
| Convolutional layer 1 | (None, 383, 430, 32) | 160 |
| Max pooling layer 1 | (None, 192, 215, 32) | 0 |
| Convolutional layer 2 | (None, 191, 214, 32) | 4128 |
| Max pooling layer 2 | (None, 96, 107, 32) | 0 |
| Convolutional layer 3 | (None, 95, 106, 32) | 4128 |
| Max pooling layer 3 | (None, 48, 53, 32) | 0 |
| Convolutional layer 4 | (None, 47, 52, 32) | 4128 |
| Max pooling layer 4 | (None, 24, 26, 32) | 0 |
| Convolutional layer 5 | (None, 23, 25, 32) | 4128 |
| Max pooling layer 5 | (None, 12, 13, 32) | 0 |
| Convolutional layer 6 | (None, 11, 12, 32) | 4128 |
| Max pooling layer 6 | (None, 6, 6, 32) | 0 |
| Convolutional layer 7 | (None, 5, 5, 32) | 4128 |
| Max pooling layer 7 | (None, 5, 5, 32) | 0 |
| Convolutional layer 8 | (None, 4, 4, 32) | 4128 |
| Max pooling layer 8 | (None, 4, 4, 32) | 0 |
| Batch normalisation 2 | (None, 4, 4, 32) | 128 |
| Dropout (rate = 0.3) | (None, 4, 4, 32) | 0 |
| Flatten | (None, 512) | 0 |
| Dense layer 1 | (None, 64) | 32832 |
| Dense layer 2 | (None, 10) | 650 |
* For facilitating value-wise comparison
NOTE: Each convolutional layer has 32 filters, and each max pooling layer has pool size (2, 2) and stride (2, 2).
Results after 30 epochs:
NOTE: The goal here is to obtain a model that can be assumed to be reasonably effective at separating the various defining features of a piece of music. Achieving this is part of the methology, and hence, the above results are shown as a part of the methodology and not as results of the AM-NST system as such.
The same kind of input as for genre classifier is used (so that genre classifier layers can be used). Output is a set of Mel-spectrogram segments of the same shape that can be stitched together to get the whole piece. The intended output is a piece that combines the timbre, acoustics and texture of the style while retaining the melodic and harmonic structure of the content.
Check the README of the resources directory in this repository to see the whole list of audio files used for this project (with links).
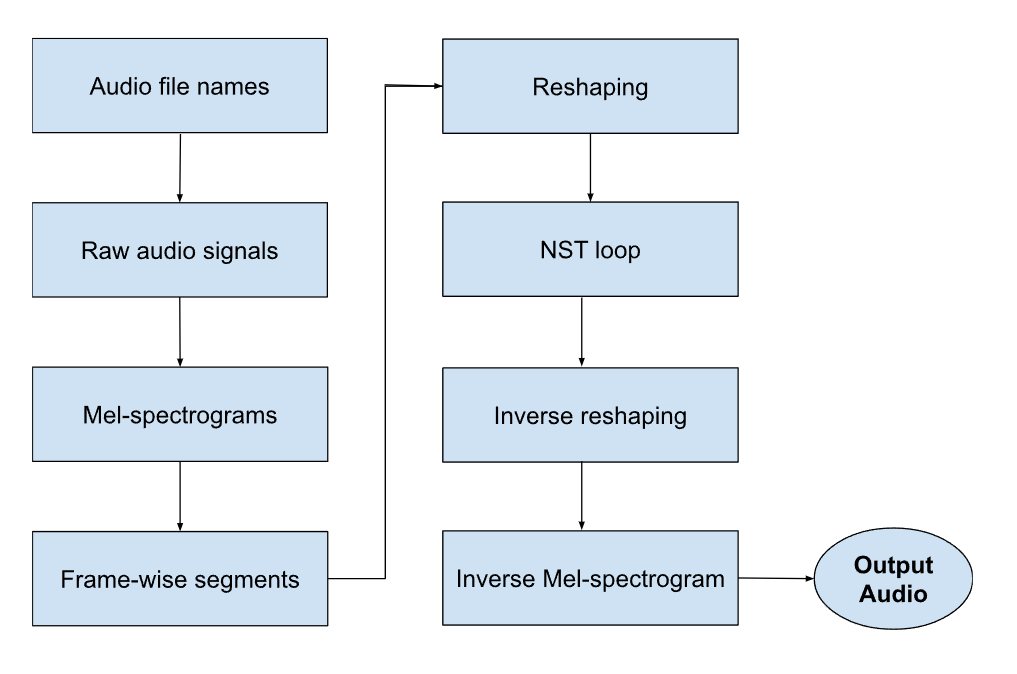
The neural model (i.e.the CNN) is applied as follows:
NOTE: The content/style loss obtained for each layer is added to the total loss
Based on this project's goals, a good style transfer is one wherein (1) the melodic and harmonic structure of the content are present in the output, (2) the timbre and acoustics of the style are present in the output such that it is not merely a superposition of two sets of audio data, and (3) the level of noise is minimal. Apart from human-based evaluation, this project does not address output assessment (other than total loss, i.e. the sum of content and style loss), since a means to quantify the aforementioned criteria for good style transfer. Output is displayed by reshaping the NST output to a Mel-spectrogram, reconstructing the raw audio signal from the Mel-spectrogram, and displaying an audio player for the raw audio signal.
This project explores the potential NST in a specific task, namely the transferring the timbre, texture and acoustics of one piece to the melody and harmony of another. Hence, it aims to address the problem of inferring and transferring musical features by capturing a wider variety of abstract audio features at various levels of abstractions using more layers in the CNN with smaller kernels, hence the 8 convolutional layers. Using a wider selection of layers representing potentially valuable audio features, this project gives a means to experiment with features (of the style audio especially) at varying levels of abstractions and explore the effects of considering any set of abstract features.
This project involves two sets of experiments:
Google Colab Notebook:
InterfaceViaGoogleGolab.ipynb
Using Google Colab, I have provided a sufficiently comprehensive interface that allows for a high level of customisability and thus experimentation in NST parameters (mainly the content and style layers and weights) and NST loop parameters (e.g. learning rate, decay rate, etc.). It also allows for experimentation using any audio that can be uploaded in the session storage or Google Drive, with many comprehensive and customisable path parameters. The process is also end-to-end, removing the need for any pre-processing or post-processing by the user. The only dependency is the file containing pretrained model weights, which can be easily uploaded and used.
I have trained genre-classification CNNs that use MFCCs (Mel-frequency Cepstrum Coefficients). The Mel-frequency cepstral coefficients (MFCCs) of an audio signal are a small set of features (usually around 10–20) which describe the overall shape of the spectral envelope (i.e. the overall distribution of a signal's power over its frequency). More precisely, we have the following chain of concepts:
References: Deruty, 2022; Mel-frequency cepstrum, 2024; Power spectral density, 2024
Generally, the essential music dimension used in content-based approaches is timbre. Timbre can be defined as "the character or quality of a musical sound or voice as distinct from its pitch and intensity". It depends on the perception of the quality of sounds, which is related to the used musical instruments, with possible audio effects, and to the playing techniques. In the field of speech recognition, the mel-frequency cepstral coefficients (MFCCs) have been widely used to model important characteristics in speech. Since modelling speech characteristics and timbre are similar, the use of MFCCs has been extended with success in the field of music similarity (e.g. genre classification, which depends to an extent on timbre) (de Leon and Martinez, 2012).
Whether MFCCs models timbre is a somewhat open question, but it is reasonable to assume that they do to some extent. But what is the relevance of tibre? This project aims to transfer the timbral and acoustic qualities of an ambience-type audio to a musical piece. Hence, timbre is relevant in building a model that can (to some extent) model timbral and acoustic qualities of sound and music especially. As with Mel-spectrograms and for similar reasons, this project uses a genre classifier trained on MFCCs to achieve such modelling.
The key challenge in using MFCCs is that the information loss when coverting an audio signal to MFCCs is too great to reconstruct the audio signal without excessive noise and distortion. Hence, using my project’s framework, I tried to combine inferences from Mel-spectrograms (for content) and MFCCs (for style). Although the results were dismal, the possibility seems worth exploring and can be further explored using this project’s framework. Results can be found in this project's repository in the Jupyter Notebook NeuralStyleTransferWithUnevenModelling.ipynb.
Sample outputs:
ambience-to-music-neuralStyleTransfer/sampleOutputs
Based on my goals, a good style transfer is one wherein (1) the melodic and harmonic structure of the content are present in the output, (2) the timbre and acoustics of the style are present in the output such that it is not merely a superposition of two sets of audio data, and (3) the level of noise is minimal. Apart from human-based evaluation, I did not address output assessment (other than total loss), since I did not understand how to quantify my criteria. Output is displayed by reshaping the NST output to a Mel-spectrogram, reconstructing the raw audio signal from the Mel-spectrogram, and displaying an audio player for the raw audio signal.
Google Colab Notebook:
InterfaceViaGoogleGolab.ipynb
Users can input parameters and audio names in input boxes using Google Colab's GUI system (input instructions are given). Interaction requires either mounting Google Drive with required data or uploading required data to the session storage. The process is end-to-end, so the user need not worry about pre-processing or post-processing.
For NST in audio, the available pretrained networks for images were overkill, since features needed to accurately classify images are far more extensive than thoses needed to classify music. Hence, I trained my own, simpler genre-classification model that inputs Mel-spectrograms (Mel-spectrograms were used as they are a means store audio visually that is efficient (in terms of memory) and a good model for human auditory perception). I made the CNN architecture (inspired from Meng, 2021), after testing for a variety of parameters for Mel-spectrogram dimensions and CNN architectures; the parameters and architectures tested have been detailed in the following Jupyter Notebooks:
ambience-to-music-neuralStyleTransfer/DemoForAudioPreprocessing.ipynbambience-to-music-neuralStyleTransfer/genreClassification/GenreClassification.ipynbThe training process is customised (using learning rate decay upon encoutering a plateau in validation accuracy) to ensure steadier convergence. The NST process itself is relatively standard, although I added a means to decay the learning rate and rollback target updates upon exploding gradients. The NST loop is made to be highly customisable to enable testing a range of potential parameters.
Drawing from the essential properties of creativity mentioend by Ritchie (2007), the evaluation of the perceived creativity of the outputs is based on three criteria: (1) novelty, (2) quality and (3) typicality. These criteria are discussed below in the context of the outputs of AM-NST.
1. Novelty:
Since the outputs are a combination of the content and style genres, the outputs can stand apart from typical examples of either genre. For example, combining a piano piece by Bach with an electric hum leads to an output dissimilar from Bach's usual sound but unlike examples of genres with similar textures, such as techno or electronic music. However, the system has no process to alter the artistic quality of either the content or the style, so novelty depends entirely on the novelty of the content with respect to the style.
2. Quality:
Quality depends heavily on the input quality (artistic and acoustic) and NST parameters used. The system cannot isolate and alter the melodic and harmonic aspects of the content alone, which means style transfer leads to varying levels of background noise and sometimes a mere superposition of content and audio. Furthermore, the system has no means to show what features constitute timbre or texture and how to transfer those features from the style to the audio, thereby often resulting in a dubious, unconvincing mixture.
3. Typicality:
Considering a hypothetical typical mixture of content and style (e.g. Bach played in a horror-ambience style, or Mozart played in a cinematic style), the outputs of the system are atypical, i.e. they do not conform to any well-defined idea of a content-style mixture; this is in part due to poor quality, in part due to an ill-defined conceptual basis for audio style transfer.
AM-NST is a weak computational creativity project, i.e. it focuses more on generating valuable artefacts than emulating creative behaviour. NST only leverages the performance of CNNs in estimating abstractions in an opaque manner (i.e. as a black-box) without emulating the essence creative behaviour, at least not in a well-defined way.
The Ambience-to-Music Neural Style Transfer (AM-NST) project presents an approach to style transfer in audio that leveraging a CNN for extracting and applying both content and style features from Mel-spectrogram representations of audio. While the system demonstrates potential for transferring timbre, texture, and acoustics from one piece of music to another, the quality of the output is noisy and reveals inadequate isolation of melodic and harmonic elements. Additionally, the system's ability to capture and transfer more abstract features of audio remains a work in progress, suggesting future improvements in the handling of creative behavior within neural networks.
From a computational creativity perspective, the system is more effective in generating unique audio artefacts than in simulating human-like creative processes. Nevertheless, while the current model does not yet emulate creative behavior as comprehensively as desired, it offers a valuable platform for experimenting with various audio features and parameters. The inclusion of customisable parameters and a user-friendly interface via Google Colab makes the system accessible for testing and future exploration. Furthermore, the project opens up avenues for deeper integration of Mel-spectrograms and MFCCs, which, despite poor results in preliminary trials, may offer a means to richer audio synthesis if refined further.
Overall, the project represents a step toward advancing neural style transfer in the realm of audio, particularly in capturing diverse abstract features across different levels of abstraction in audio. However, substantial challenges remain in improving the system's ability to produce consistently high-quality results and better emulate the complex creative processes associated with musical style transfer.
Deruty, E. (2022). Intuitive understanding of MFCCs. Medium. Available at: https://medium.com/@derutycsl/intuitive-understanding-of-mfccs-836d36a1f779 (Accessed: 30 December 2024).
Wikipedia (2024). Mel-frequency cepstrum. Available at: https://en.wikipedia.org/wiki/Mel-frequency_cepstrum (Accessed: 30 December 2024).
Wikipedia (2024). Power spectral density. Available at: https://en.wikipedia.org/wiki/Spectral_density#Power_spectral_density (Accessed: 30 December 2024).
de Leon, F., Martinez, K. (2012). Enhancing Timbre Model Using MFCC And Its Time Derivatives For Music Similarity Estimation. 20th European Signal Processing Conference (EUSIPCO 2012).
Men, Y. (2021). Music Genre Classification: A Comparative Analysis of CNN and XGBoost Approaches with Mel-frequency cepstral coefficients and Mel Spectrograms. Department of Statistics, University of California. arXiv preprint arXiv
.04737.Ritchie, G. (2007). 'Some Empirical Criteria for Attributing Creativity to a Computer Program'. Minds & Machines 17, pp. 67–99. https://doi.org/10.1007/s11023-007-9066-2
I shall also discuss their relevance to my project where necessary.
The short-time Fourier transform (STFT) is a Fourier-related transform used to determine the sinusoidal frequency and phase content of local sections of a signal (e.g. an audio file) as it changes over time. In practice, the procedure for computing STFTs is to divide a longer time signal (e.g. a longer audio file) into shorter segments (windows) of equal length and then compute the Fourier transform separately on each shorter segment. Conceptually, we are taking the discrete Fourier transform (DFT) of successive windowed regions of the original signal (note that these regions overlap if the hop length is smaller than the window length).
References:
The way we hear frequencies in sound is known as 'pitch'. It is a subjective impression of the frequency. So a high-pitched sound has a higher frequency than a low-pitched sound. Humans do not perceive frequencies linearly. We are more sensitive to differences between lower frequencies than higher frequencies. For example, the pair at 100Hz and 200Hz will sound further apart than the pair at 1000Hz and 1100Hz, even if the actual frequency difference between each pair is the same (100 Hz); you will hardly be able to distinguish between the pair at 10000Hz and 10100Hz. However, this may seem less surprising if we realize that the 200Hz frequency is actually the double of 100Hz, whereas the 10100Hz frequency is only 1% higher than the 10000Hz frequency.
This is how humans perceive frequencies; we hear them on a logarithmic scale rather than a linear scale. The mel scale was developed to take this into account by conducting experiments with a large number of listeners. It is a scale of pitches such that each would be unit is judged by human listeners to be equal in pitch distance from the next.
Why use Mel-spectrograms for NST?
Modelling audio based on how humans perceive audio is a practical starting point to try to model audio recognition according to human needs (e.g. genre, key signature, etc.). Instead of frequencies, we consider mel bands that convey the most significant frequencies to a human ear and their relationships between each other with respect to human perception; this allows us to reduce data while preserving most or all the relevant information needed for audio recognition tasks.
NOTE: We could also scale signal power with decibel (a logarithmic scale) instead of amplitude (a linear scale), the former modelling human perception more closely. However, I shall not do this because I intend eventually to reconstruct the audio signals from the Mel-spectrograms passed and modified through my models, and I found that converting the signal power to decibel scale led to too much information loss, which led to poor signal reconstruction.
Reference: Doshi, K. (2021). Audio Deep Learning Made Simple (Part 2): Why Mel Spectrograms perform better
GradientTape in TensorflowGradientTapeTensorflow's GradientTape record operations on a given set of variables (given within its context) for automatic differentiation. Trainable variables (created by tensorflow.Variable or tensorflow.compat.v1.get_variable, where trainable=True is default in both cases) are automatically watched. Tensors can be manually watched by invoking the watch method on this context manager. Now, note that since GradientTape only watches trainable Tensorflow variables, converting the watched variables at any point within GradientTape's context to other data types (e.g. NumPy arrays) erases previous operations, thus erasing or resetting its gradient to zero. Needless to say, operations on variables of other data types are not recorded by GradientTape, and thus, do not contribute to the gradient's calculation.
tensorflow.GradientTape.watchTensorflow's GradientTape watches all trainable variables under its context by default. However, if I have given the optional argument watch_accessed_variables as false (to allow for more fine-grained control over the variables observed, if needed), I have to specify which variables I want GradientTape to record operations for, a tensorflow.GradientTape.watch function call would be needed. By default, however, the function call is redundant.
Reference:
tf.GradientTape(Tensorflow documentation)
persistent=True in GradientTapeA persistent tape is a tape that can be used multiple times to compute multiple gradients. By default, a tape is not persistent and can only be used once. If I intend to compute the gradient for two variables, so I need a persistent tape.
Reference: GeeksForGeeks (2024). tf.GradientTape in TensorFlow