YouTube Video Summarizer & Q&A with IBM Watsonx and FAISS
Introduction
This project is a YouTube video summarizer and Q&A system that extracts transcripts from YouTube videos, processes them, and enables AI-powered summarization and question answering using IBM Watsonx AI models and FAISS for efficient similarity searches.
Features
Extracts transcripts from YouTube videos.
Splits long transcripts into smaller chunks for efficient processing.
Uses IBM Watsonx Granite 13B Chat V2 for text summarization.
Employs FAISS (Facebook AI Similarity Search) for efficient text retrieval.
Enables Q&A on video content using WatsonxLLM and embeddings.
Provides a web-based interface using Gradio.
Technologies Used
IBM Watsonx AI (Granite 13B Chat V2, SLATE 30M Embeddings)
YouTube Transcript API (Unofficial API to fetch transcripts)
FAISS (Efficient similarity search and vector storage)
LangChain (LLM-powered prompt handling)
Gradio (User-friendly web interface)
#Installation & Setup
Installation & Setup
- Install Required Libraries
Ensure you have the necessary dependencies installed:
pip install gradio youtube-transcript-api langchain faiss-cpu ibm-watsonx-ai langchain-ibm
- Obtain IBM Watsonx Credentials
You need IBM Watsonx credentials to access the models:
Sign up at IBM Watsonx AI.
Retrieve your API Key and URL from your IBM Cloud account.
- Run the Application
Execute the following command to start the Gradio interface:
python app.py # Ensure your script filename matches
#Code Explanation
- Extract YouTube Transcripts
from youtube_transcript_api import YouTubeTranscriptApi
import re # For extracting video ID
def get_video_id(url):
pattern = r'https://www.youtube.com/watch?v=([a-zA-Z0-9_-]{11})'
match = re.search(pattern, url)
return match.group(1) if match else None
def get_transcript(url):
video_id = get_video_id(url)
transcript = YouTubeTranscriptApi.get_transcript(video_id)
return transcript
- Process and Chunk Transcripts
from langchain.text_splitter import RecursiveCharacterTextSplitter
def process(transcript):
return "\n".join([f"{i['text']}" for i in transcript])
def chunk_transcript(processed_transcript, chunk_size=200, chunk_overlap=20):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
return text_splitter.split_text(processed_transcript)
- Set Up IBM Watsonx API
from ibm_watsonx_ai import APIClient, Credentials
from ibm_watsonx_ai.foundation_models.utils.enums import ModelTypes
def setup_credentials():
model_id = ModelTypes.GRANITE_13B_CHAT_V2
credentials = Credentials(url="https://us-south.ml.cloud.ibm.com")
client = APIClient(credentials)
return model_id, credentials, client
- Summarization with Watsonx LLM
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
def create_summary_prompt():
template = """
Summarize the following YouTube video transcript:
{transcript}
"""
return PromptTemplate(input_variables=["transcript"], template=template)
def create_summary_chain(llm, prompt):
return LLMChain(llm=llm, prompt=prompt, verbose=True)
- Embeddings & FAISS Indexing
from langchain_ibm import WatsonxEmbeddings
from langchain_community.vectorstores import FAISS
def setup_embedding_model(credentials):
return WatsonxEmbeddings(model_id="IBM_SLATE_30M_ENG", url=credentials["url"])
def create_faiss_index(chunks, embedding_model):
return FAISS.from_texts(chunks, embedding_model)
- Question Answering with Watsonx LLM
def create_qa_prompt_template():
qa_template = """
Based on the video content:
{context}
Answer the question:
{question}
"""
return PromptTemplate(input_variables=["context", "question"], template=qa_template)
def generate_answer(question, faiss_index, qa_chain):
relevant_context = faiss_index.similarity_search(question, k=7)
return qa_chain.predict(context=relevant_context, question=question)
- Gradio Web Interface
import gradio as gr
def summarize_video(video_url):
transcript = get_transcript(video_url)
processed_transcript = process(transcript)
summary_prompt = create_summary_prompt()
summary_chain = create_summary_chain(llm, summary_prompt)
return summary_chain.run({"transcript": processed_transcript})
def answer_question(video_url, user_question):
transcript = get_transcript(video_url)
processed_transcript = process(transcript)
chunks = chunk_transcript(processed_transcript)
faiss_index = create_faiss_index(chunks, embedding_model)
return generate_answer(user_question, faiss_index, qa_chain)
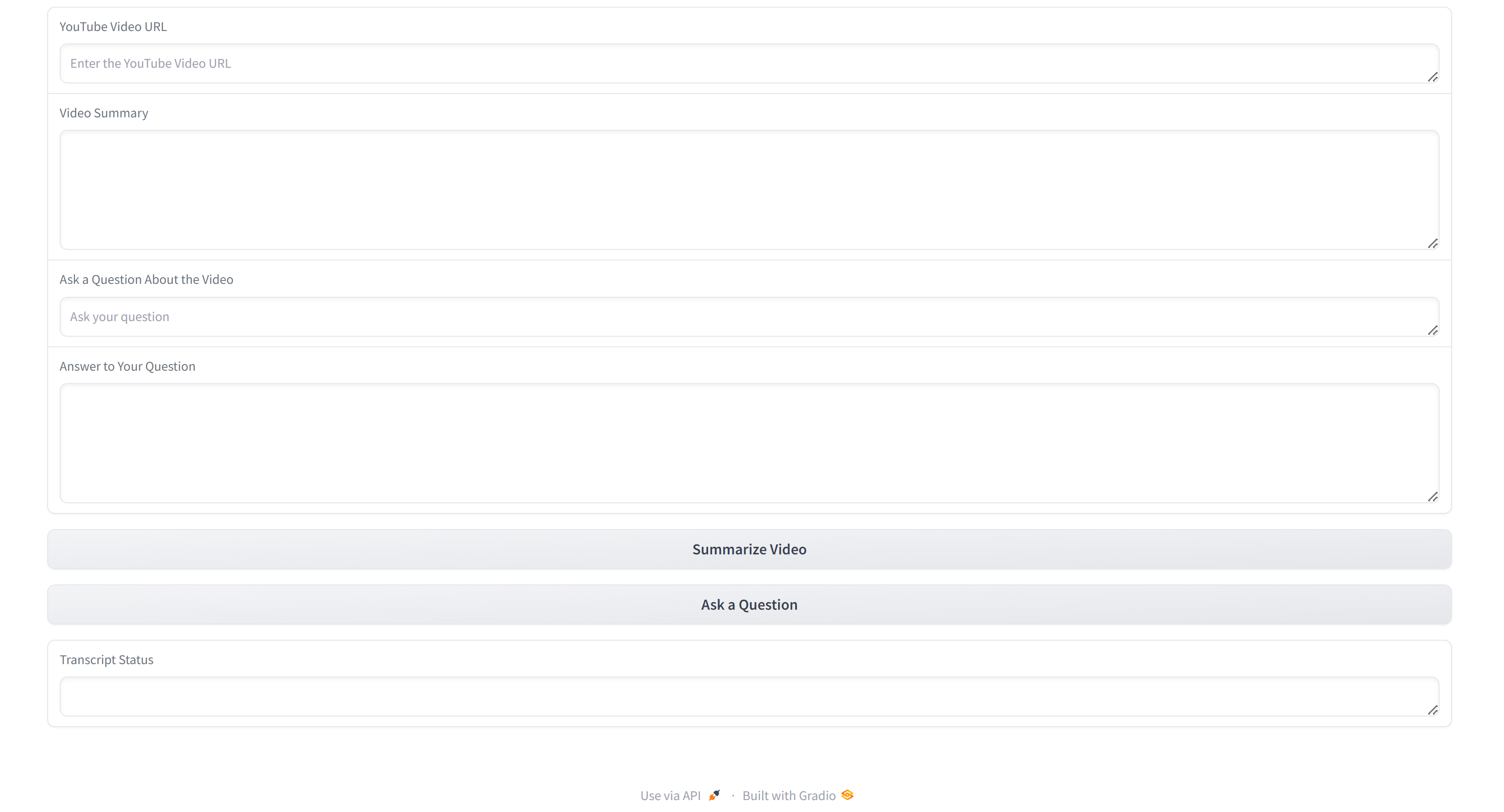
with gr.Blocks() as interface:
video_url = gr.Textbox(label="YouTube Video URL")
summary_output = gr.Textbox(label="Video Summary")
question_input = gr.Textbox(label="Ask a Question")
answer_output = gr.Textbox(label="Answer")
summarize_btn = gr.Button("Summarize Video")
question_btn = gr.Button("Ask a Question")
summarize_btn.click(summarize_video, inputs=video_url, outputs=summary_output)
question_btn.click(answer_question, inputs=[video_url, question_input], outputs=answer_output)
interface.launch()
Conclusion
This project enables efficient summarization and Q&A for YouTube videos using IBM Watsonx AI and FAISS. It allows users to quickly grasp the essence of long videos and retrieve information using natural language queries.