In the rapidly expanding field of Artificial Intelligence, researchers and practitioners face an overwhelming volume of academic literature. Staying up-to-date is a significant challenge. This publication introduces a custom-built AI Research Assistant—a tool that leverages Retrieval-Augmented Generation (RAG) to provide concise, accurate, and source-cited answers from a personal library of research papers.
Imagine being able to "talk" to your entire collection of research papers. Instead of manually searching through dozens of PDFs, you can ask a direct question like, "What are the key challenges in multi-agent reinforcement learning?" and receive a synthesized answer with citations pointing to the exact source papers. This dramatically accelerates research and study.
This project serves as a comprehensive, real-world blueprint for building a production-grade RAG application. It follows professional software engineering practices, including a clean architecture, configuration management, and a robust, intelligent user interface. It answers the question: "How do I build a RAG system that is reliable, maintainable, and user-friendly?"
This document details the system's architecture, implementation flow, and future potential, demonstrating a tool that is not only powerful but also trustworthy and easy to use.
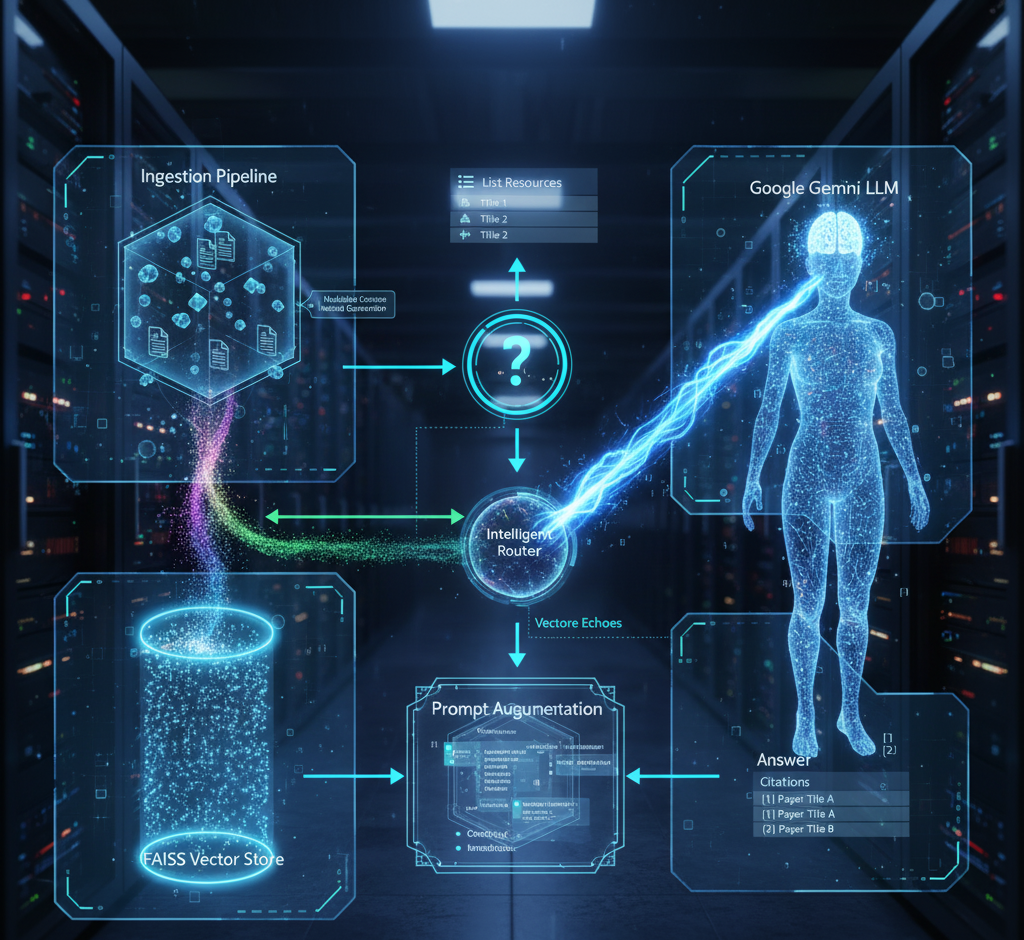
The assistant is built on a Retrieval-Augmented Generation (RAG) architecture, which enhances a Large Language Model (LLM) with an external, searchable knowledge base. This prevents the LLM from relying solely on its pre-trained (and potentially outdated) knowledge, resulting in more accurate and contextually relevant answers. The system is composed of two distinct pipelines.
This offline process prepares the research papers to be searched. It indexes the knowledge so that relevant information can be found quickly.
metadata.json file is created to map each unique PDF filename to the paper's full title, ensuring user-friendly citations.This real-time process occurs when a user asks a question. It is designed for both intelligence and efficiency.
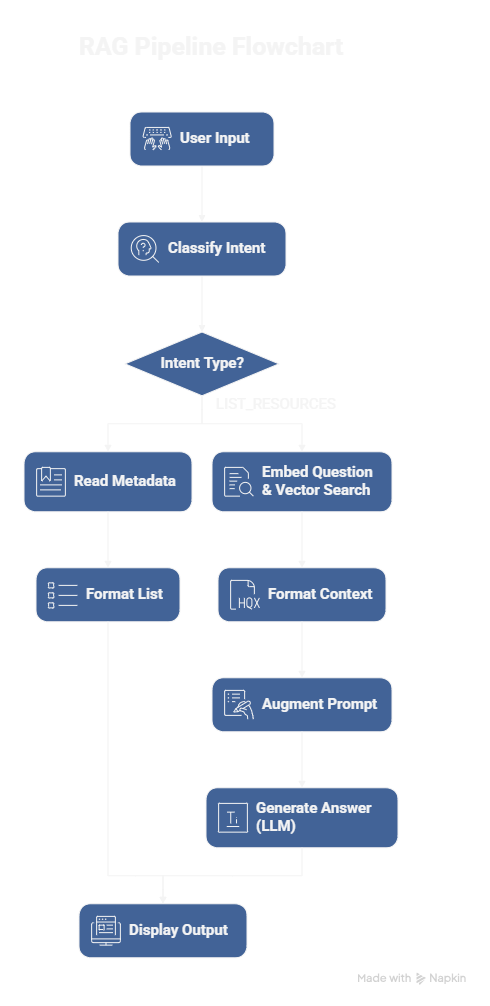
gemini-1.0-pro model to generate a synthesized, in-text cited answer.To understand how the assistant works, let's trace the journey of a single question from user input to final answer.
RAGPipeline's Router. The router makes its first, lightweight call to the Gemini LLM with a specific prompt, asking it to classify the question as either LIST_RESOURCES or RESEARCH_QUESTION.RunnableBranch logic directs the flow based on the classification.
LIST_RESOURCES: The system takes a shortcut. It reads the metadata.json file and instantly returns a formatted list of all available paper titles. No retrieval or second LLM call occurs.RESEARCH_QUESTION (Default Path): The main RAG process begins.metadata.map to find the full paper title. It then formats this information into a single, clean context block, with each piece of evidence clearly labeled with its source (e.g., Source: [Title of Paper]).Yes! The project is open-source under the MIT License, and you can get it running with a few simple steps.
This guide includes the crucial steps for creating a virtual environment and ensuring all dependencies are installed correctly.
First, clone the project from your GitHub repository to your local machine. You need to replace <your-repository-url> with the actual URL from GitHub.
git clone <your-repository-url> cd Ai-Research-RAG-system
This is a critical best practice. It creates an isolated environment for your project's dependencies.
# For Windows python -m venv venv .\venv\Scripts\activate # For macOS/Linux python3 -m venv venv source venv/bin/activate
You should see (venv) appear at the beginning of your terminal prompt.
Instead of relying on a requirements.txt file that may not exist yet, let's install all the packages we've used directly. This is the most likely step that was failing.
pip install gradio langchain langchain-google-genai faiss-cpu sentence-transformers pypdf python-dotenv arxiv langchain-huggingface
requirements.txt FileNow that all the packages are installed, you can create the requirements.txt file for future use with this one command:
pip freeze > requirements.txt
Create a new file named .env in the project root and add your Google Gemini API key to it.
GOOGLE_API_KEY="your_api_key_here"
You are now fully set up. Run the scripts in order.
python scripts/download_papers.py
python ingest.py
# For the Gradio web interface python app.py # Or for the command-line interface python main.py
If you follow these more detailed steps and still encounter an issue, please copy and paste the full error message you see in the terminal. We will solve it immediately.
While robust, the assistant has several limitations that offer clear opportunities for future enhancements.
ConversationBufferMemory) to allow for multi-turn, contextual conversations.This project successfully demonstrates the creation of a complete, end-to-end AI Research Assistant. By integrating an intelligent routing system with a robust RAG pipeline, the final application is not only functional but also efficient and user-friendly. It stands as both a practical tool for researchers and a professional blueprint for developers, showcasing how modern AI techniques can be applied to solve the real-world problem of information overload. The commitment to a clean architecture, detailed documentation, and user-centric features ensures that this project is a valuable asset for anyone looking to build or understand production-grade RAG systems.
