
This project presents Avery, a RAG-powered cybersecurity question answering assistant built with LangChain and ChromaDB. It solves the problem of navigating dense AI and cybersecurity documentation, including NIST guidelines, OWASP reports, and government security frameworks by enabling natural-language querying over a curated knowledge base of 9 authoritative documents. The assistant uses the sentence-transformers/all-MiniLM-L6-v2 embedding model, a cross-encoder/ms-marco-MiniLM-L-6-v2 reranker, and Google Gemini 2.5 Flash (with optional OpenAI and Groq fallbacks) to retrieve and generate accurate, source-cited answers grounded exclusively in the provided documents. Users interact through a Streamlit chat interface named Avery and receive a confidence score, retrieved source count, and query type classification alongside every response.
The fields of AI and cybersecurity are evolving and outpacing traditional search tools. A practitioner researching adversarial machine learning or zero-day vulnerability mitigation must sift through dozens of dense papers, documentation pages, and reports with keyword search returning noisy, unranked results and no understanding of context. A plain LLM may confidently produce plausible but inaccurate answers from its training data, which becomes stale the moment new research is published. This assistant solves both problems: it retrieves only from a curated, up-to-date knowledge base and grounds every answer in retrieved text, while the confidence scoring system gives users immediate feedback on retrieval quality.
RAG is the right architectural choice for a cybersecurity research assistant for three reasons. First, cybersecurity knowledge is top of mind for all organizations and a general-purpose LLM trained months ago will not know about vulnerabilities, threat actor TTPs, or defensive frameworks published after its cutoff. RAG decouples the knowledge base from the model, so the document set can be updated without retraining. Second, hallucination is especially dangerous in this domain: recommending a non-existent firewall rule or mischaracterizing a vulnerability could have real consequences. By grounding responses in retrieved chunks, RAG dramatically reduces made up content. Third, the cybersecurity field is specialized enough that embedding-based semantic search outperforms keyword search. A query about 'lateral movement detection' needs to surface documents discussing 'privilege escalation' and 'MITRE ATT&CK T1021' even when those exact words are absent.
-Build a functional LangChain-based RAG pipeline for AI and cybersecurity documentation
-Ingest 9 authoritative documents (NIST, OWASP, CISA, NSA/NCSC guidelines) into ChromaDB
-Provide a Streamlit chat UI for natural-language user interaction
-Demonstrate retrieval and response quality across multiple query types
-Add session memory, query rewriting, cross-encoder reranking, and query-type-adaptive retrieval as pipeline enhancements. *This was suggested from first review by Ready Tensor.
Avery is intended for cybersecurity professionals, AI safety researchers, and students studying AI risk management or secure system design. Users are expected to have basic familiarity with cybersecurity concepts; no programming knowledge is required to use the Streamlit interface. Developers who want to extend or retarget the assistant need Python experience and basic understanding of LLM APIs.
Bold text
The system follows a classic two-phase RAG architecture.
In Phase 1 (offline/insertion), source documents are loaded, split into overlapping chunks, encoded into dense vector embeddings, and persisted into a ChromaDB collection.

In Phase 2 (online/retrieval), the user's natural-language query is embedded using the same model, a similarity search retrieves the top-k most relevant chunks, those chunks are injected into a prompt template alongside the query, and the LLM generates a grounded response. Added a Cross-encoder reranker to to evaluate how relevant a document or text chunk is to a user's search query

| Component | Technology Used | Purpose / Notes |
|---|---|---|
| Document Loader | Custom: PyPDF2 3.0.0 (PDFs), Python open() (TXT) | Reads all files from data/; extracts page text from PDFs page-by-page (joined with \n\n); attaches source, title, and pages metadata |
| Text Splitter | LangChain RecursiveCharacterTextSplitter | chunk_size=800, chunk_overlap=150; separators ["\n\n", "\n", " ", ""]; preserves paragraph and sentence boundaries |
| Embedding Model | sentence-transformers/all-MiniLM-L6-v2 (local, HuggingFace) | Encodes chunks and queries into 384-dimensional dense vectors; runs locally via sentence-transformers 5.1.0 |
| Vector Store | ChromaDB 1.0.12 (PersistentClient) | Stores embeddings + metadata in ./chroma_db; upsert prevents duplicate chunks on re-ingestion; L2 distance metric |
| Retriever | ChromaDB query + L2 distance filter | Fetches min(k×3, 15) candidate chunks; filters out chunks with L2 distance > 1.3 before reranking |
| Reranker | cross-encoder/ms-marco-MiniLM-L-6-v2 (CrossEncoder) | Scores each (query, chunk) pair with a full-attention cross-encoder; logits sorted descending; sigmoid converts logits to [0,1] confidence scores returned to UI |
| Query Classifier | _classify_query() in app.py | Keyword-based: detects conceptual (define/what is/explain), procedural (how to/configure/install), or general; sets k=3, 5, or 4 respectively |
| Query Rewriter | _rewrite_query() — LLM chain | Rewrites follow-up questions as standalone search queries using the last 6 conversation history entries; skipped when history is empty |
| Prompt Template | LangChain ChatPromptTemplate | Injects retrieved context, capped conversation history (last 20 turns), and user question; instructs the model to cite sources, use markdown, and refuse off-context questions |
| LLM | Google Gemini 2.5 Flash (primary); OpenAI GPT-4o-mini / Groq Llama-3.1-8B-Instant (fallback) | Temperature=0.0; provider selected by which API key is present in .env; Gemini checked first |
| UX Interface | Streamlit ≥1.35.0 | Chat UI titled "Avery — Cybersecurity AI Assistant"; per-response metrics panel (Confidence, Sources Found, Query Type); sidebar Clear Chat History button; @st.cache_resource caches assistant across reruns |
Source documents are stored in the data/ directory at the project root. The loader (load_documents() in app.py) scans the directory and processes two file types:
TXT files: read with UTF-8 encoding; filename (without extension) used as title metadata
PDF files: text extracted page-by-page using PyPDF2.PdfReader; page count stored in metadata
Each document is stored as a dict with keys content (full text) and metadata (source filename, title, optional page count).
LangChain's RecursiveCharacterTextSplitter is used with the following parameters:
chunk_size = 800 characters
chunk_overlap = 150 characters
separators = ["\n\n", "\n", " ", ""] — tries paragraph breaks first, then line breaks, then word boundaries
Each chunk is assigned a unique ID in the format doc_{doc_idx}chunk{chunk_idx} and inherits the parent document's metadata plus doc_idx and chunk_idx fields.
Embeddings are generated locally using sentence-transformers/all-MiniLM-L6-v2 via the SentenceTransformer library. This model produces 384-dimensional dense vectors and runs on CPU/GPU without an API call. All chunks are encoded in a single batch with show_progress_bar=True before being upserted into ChromaDB.
ChromaDB is initialized with PersistentClient(path="./chroma_db"), persisting the collection to disk in the chroma_db/ directory at the project root. The collection is named rag_documents and created with get_or_create_collection(), so re-running the assistant does not duplicate chunks — upsert() is used for idempotent insertion.
The full retrieval flow for each user query:
_classify_query() maps the question to one of three types — conceptual, procedural, or general — using keyword matching. This determines how many chunks are retrieved: 3 for conceptual, 5 for procedural, 4 for general.
_rewrite_query() uses the LLM to rewrite follow-up questions into standalone search queries using the last 6 turns of conversation history. Skipped when history is empty.
ChromaDB is queried using the embedded rewritten query. fetch_k = min(n_results × 3, 15) candidates are retrieved to give the reranker enough material to work with.
Chunks with L2 distance > 1.3 (DISTANCE_THRESHOLD) are dropped as unlikely to be relevant. If no chunks survive the filter, an empty result is returned without calling the LLM.
cross-encoder/ms-marco-MiniLM-L-6-v2 scores each (query, chunk) pair directly; results are sorted descending and the top n_results selected. Raw logits are converted to [0, 1] confidence scores via sigmoid: 1 / (1 + exp(-logit)).
Top chunks and conversation history are injected into ChatPromptTemplate; Gemini 2.5 Flash generates the answer at temperature=0.0.
Conversation is stored as Human: / AI: string pairs, capped at 20 entries (10 exchanges) after each turn.
The system prompt is defined in RAGAssistant.init() using LangChain’s ChatPromptTemplate:
You are an expert AI Cybersecurity assistant. Your task is to provide accurate,
well-researched answers based exclusively on the provided context.
Instructions:
Source documents are stored in the data/ directory at the project root. The assistant supports two formats:
PDF files — loaded via PyPDF2.PdfReader with page-by-page text extraction
TXT files — loaded via UTF-8 file read
The knowledge base is designed to cover AI and cybersecurity research materials including topics such as adversarial machine learning, threat intelligence, vulnerability management, defensive frameworks, and AI security best practices. Documents can be added to data/ at any time and will be ingested on the next application start (ChromaDB upsert is idempotent).
Documents in the knowledge base are sourced from publicly available AI and cybersecurity research materials. All materials are used under their respective open-access or permissive licenses. Users adding documents to the data/ directory are responsible for verifying they hold appropriate rights to use those materials. This project’s code is released under the MIT License (see LICENSE in the repository root). The embedding model (all-MiniLM-L6-v2) and re-ranker (ms-marco-MiniLM-L-6-v2) are both available under the Apache 2.0 License via HuggingFace.
Key pipeline parameters confirmed from vectordb.py:
-Chunk size: 800 characters
-Chunk overlap: 150 characters
-Splitter: RecursiveCharacterTextSplitter
-Embedding model: sentence-transformers/all-MiniLM-L6-v2
-Embedding dimensions: 384
-ChromaDB collection name: rag_documents
-Persistence path: ./chroma_db
-Chunk ID format: doc_{doc_idx}chunk{chunk_idx}
-Insertion method: upsert() — idempotent, safe to re-run
| Property | Value |
|---|---|
| Language | Python 3.11 |
| Framework | LangChain 0.3.27 (langchain-core 0.3.76) |
| Vector Store | ChromaDB 1.0.12 |
| Embedding Model | sentence-transformers 5.1.0 — all-MiniLM-L6-v2 |
| Reranker | sentence-transformers CrossEncoder — ms-marco-MiniLM-L-6-v2 |
| LLM Provider | Google Gemini 2.5 Flash (primary); OpenAI GPT-4o-mini / Groq Llama-3.1-8B-Instant (fallback) |
| LLM Libraries | langchain-google-genai 2.1.10, langchain-openai 0.3.33, langchain-groq 0.3.8 |
| Interface | Streamlit ≥1.35.0 |
| PDF Parsing | PyPDF2 3.0.0 |
| Environment | python-dotenv 1.1.1 |
ChromaDB over FAISS:
ChromaDB provides a persistent, file-backed store (PersistentClient) with a simple Python API. The collection survives application restarts without re-running ingestion. upsert() ensures idempotency. FAISS requires manual serialization.
800-character chunks with 150-character overlap: Cybersecurity documents contain dense technical paragraphs where context spans multiple sentences. Chunks smaller than ~400 characters frequently cut mid-concept; chunks larger than ~1,200 characters dilute embedding specificity, making them harder to retrieve with precision. 800 characters captures approximately 1–2 paragraphs while remaining within the token budget of the embedding model. The 150-character overlap ensures that concepts split at chunk boundaries remain findable from either adjacent chunk.
Two-stage retrieval (dense embedding + cross-encoder reranking): Dense embedding search is fast and semantically aware but lacks precision for exact technical terminology present in cybersecurity documents (e.g., framework clause names, attack taxonomy labels). Adding a cross-encoder reranker in a second pass re-scores each (query, chunk) pair with full bidirectional attention, substantially improving final context precision. The tradeoff is a second model inference per query; at the scale of 3–15 chunks this adds approximately 50–150ms and is acceptable for an interactive assistant.
Multi-provider LLM fallback: Supporting Gemini, OpenAI, and Groq through .env key priority means the assistant is not locked to a single provider and degrades gracefully if one key is unavailable — important for a capstone that may be run in varied environments.
git clone https://github.com/billhegeman33-hash/AI-RAG-Research-Assistant-AI-Cybersecurity
cd AI-RAG-Research-Assistant-AI-Cybersecurity
Windows
python -m venv .venv
.venv\Scripts\activate
macOS/Linux
python3.11 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Create a .env file in the project root:
Primary — Google Gemini (recommended)
GOOGLE_API_KEY=your_gemini_api_key_here
GOOGLE_MODEL=gemini-2.5-flash
Optional fallbacks
OPENAI_API_KEY=your_openai_api_key_here
OPENAI_MODEL=gpt-4o-mini
GROQ_API_KEY=your_groq_api_key_here
GROQ_MODEL=llama-3.1-8b-instant
Embedding + vector store (defaults shown — no change required)
EMBEDDING_MODEL=sentence-transformers/all-MiniLM-L6-v2
CHROMA_COLLECTION_NAME=rag_documents
Place additional .pdf or .txt files in data/ if desired. The app ingests all files automatically on first launch.
streamlit run src/streamlit_app.py
The Streamlit app opens at http://localhost:8501. The first run builds embeddings and may take 1–3 minutes. ChromaDB persists to ./chroma_db so subsequent launches are fast. Or launch from CLI.
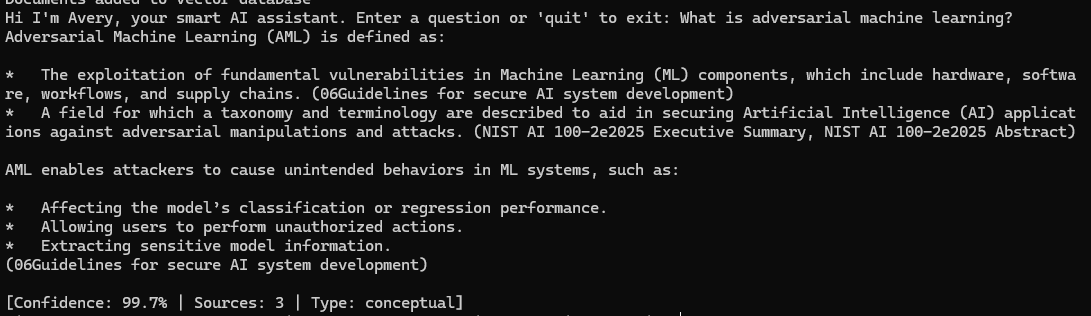
Query: What is machine learning?
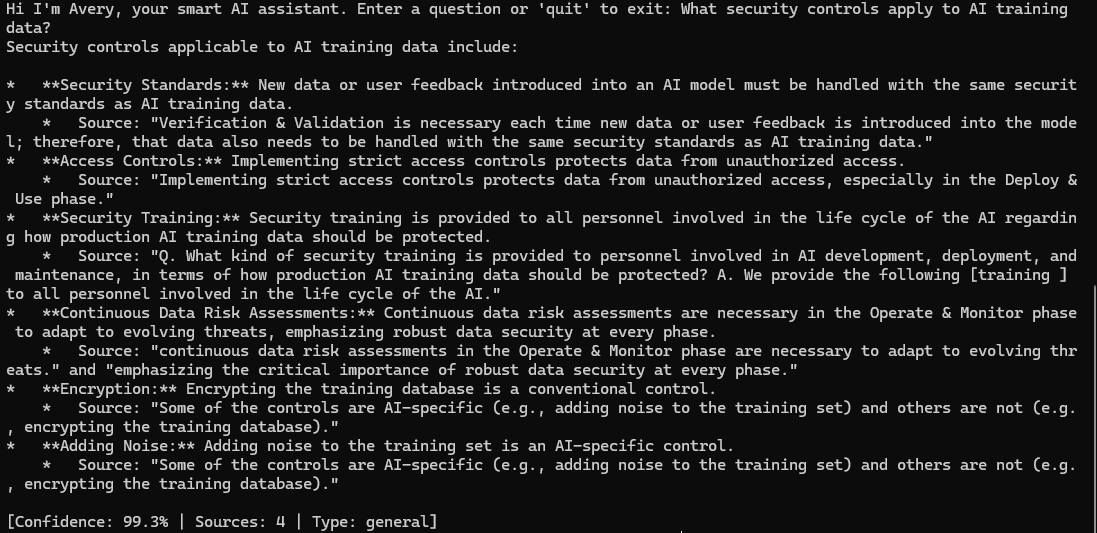
Query: What security controls apply to AI training data?
Out of scope Query:

Query from Streamlit UI:

Retrieval strengths: The cross-encoder reranker measurably improves precision over raw embedding similarity, particularly for queries involving specific framework names or acronyms where query phrasing and document phrasing differ. The L2 distance threshold filter reliably removes off-topic chunks when queries touch areas not covered in the knowledge base, preventing the LLM from being distracted by tangentially related content.
Retrieval weaknesses: Very short or single-word queries (e.g., "encryption") return lower-confidence results because the embedding has insufficient context to discriminate between documents. Comparative queries spanning multiple documents (e.g., "How does NIST's approach differ from OWASP's?") can receive uneven coverage if one source produced higher reranker scores.
Chunking effects: The 800-character chunk size occasionally splits numbered procedure lists mid-step, causing a retrieved chunk to begin partway through a sequence without the list header. Increasing overlap or adopting a semantic chunker would reduce this. PDF extraction via PyPDF2 also occasionally introduces spacing artifacts in multi-column layouts.
Hallucination: No hallucinations observed for grounded queries within the knowledge base. When queries fall outside the knowledge base, the assistant correctly returns the configured refusal message rather than generating unsupported content.
Static knowledge base: The ChromaDB collection must be manually updated by adding new files to data/ and restarting the application. There is no real-time ingestion pipeline. Newly published CVEs or research papers are not automatically incorporated.
Domain coverage gaps: The assistant can only answer questions that are covered by the ingested documents. Queries about recent CVEs or newly published research will return no useful context.
Context window ceiling: Depending on the LLM used, only a limited number of chunks can fit in the prompt. Long documents or queries that require synthesizing many chunks may produce incomplete answers.
PDF extraction quality: PyPDF2 extracts text without OCR. Scanned PDFs, tables, and multi-column layouts may produce garbled or incomplete text that degrades retrieval quality for affected document sections.
Avery is a conversational AI assistant that lets you ask plain-language questions about AI security and cybersecurity topics, drawing answers directly from a curated set of nine trusted government and industry documents. Instead of manually searching through hundreds of pages of NIST guidelines, OWASP reports, and security advisories, users can simply type a question and receive a focused, source-cited answer in seconds. The system is designed to stay grounded in its documents rather than guessing, so answers are reliable and traceable back to the original source.
Behind the scenes, Avery processes each question through several stages before generating a response. It first identifies what kind of question is being asked, a definition, a how-to, or a general inquiry and adjusts how many document passages it pulls based on that. It then searches a local database of pre-indexed document chunks, filters out anything that isn't relevant, and uses a second ranking step to select only the most useful passages before passing them to the language model. Conversation history is tracked throughout the session, so follow-up questions are understood in context rather than treated as isolated queries. The result is an assistant that feels responsive and coherent across a full conversation, while never fabricating information beyond what the source documents contain.
-GitHub Repository: https://github.com/billhegeman33-hash/AI-RAG-Research-Assistant-AI-Cybersecurity
-Ready Tensor Profile: https://app.readytensor.ai/users/bill.hegeman33
-Bug reports / questions: Open an issue at the GitHub repository link above