
AI Nexus Herald is a multi-agent system built using LangGraph that creates an AI generated newsletter focused on trending topics in AI. It leverages the full potential of agent orchestration workflow for designing and building the system. The system coordinates specialized agents for topic discovery, deep research, and summarization. It integrates custom tools and LLMs to automate high-quality newsletter generation with minimal human intervention.
Keeping pace with rapid AI advancements is challenging for anyone including students, professionals, and AI enthusiasts. AI Nexus Herald addresses this by automating the end-to-end process of discovering and researching key AI updates, organizing them into a well-formed newsletter. Leveraging vertical agents and structured orchestration, it ensures accurate, timely, and readable content delivery.
Building multi-agent systems is quite a challenging task. There are many agentic frameworks and SDKs available like Crew AI, Agno, Google Agent Development SDK, OpenAI Agent Development SDK and more. Each framework has its own pros and cons in terms of providing various agentic architectures for orchestration workflows. I have chosen LangGraph for this project which is a stateful orchestration framework that brings added control to agent workflows. It's simple and intuitive to understand and build. Moreover, it really helps make your project modular and scalable from the very beginning. The main components of LangGraph include nodes and edges which make it very convenient to build workflows in the form of graphs. It allows for sequential as well as conditional execution workflows.
AI newsletter generation has been an exciting project from the very beginning which has taught me many lessons to improve my understanding of agentic workflows. In this publication, I'll be sharing how I have designed and built this system along with some useful and practical insights which I have gained during this process.
To fully understand and replicate the implementation of AI Nexus Herald, the following tools, libraries, and knowledge are required. These are divided into must-have and optional prerequisites:
| Category | Requirement |
|---|---|
| Programming | Intermediate proficiency in Python |
| Frameworks | Familiarity with LangChain, LangGraph, and FastAPI |
| LLMs | Working knowledge of Large Language Models (LLMs) and API-based usage (e.g., OpenAI, Groq) |
| APIs | Understanding of RESTful API integration and authentication |
| Tools | Experience with virtual environments, package managers (pip, anaconda) |
| Frontend | Basic familiarity with Streamlit for building minimal, lightweight UI |
| YAML/JSON | Ability to read and write YAML and JSON for config and prompt files |
| Category | Benefit |
|---|---|
| Docker | Enables containerization and easier deployment across environments |
| LLM Prompt Engineering | Helps in refining agent prompts for deterministic outputs |
| LangChain Tools Development | Useful for custom tool integration |
| Deployment Platforms | Knowledge of Fly.io, Railway, or AWS for production deployment |
AI Nexus Herald stands at Level-4 agentic architecture (LLMs + Tools + Reasoning + Multiple Agents).
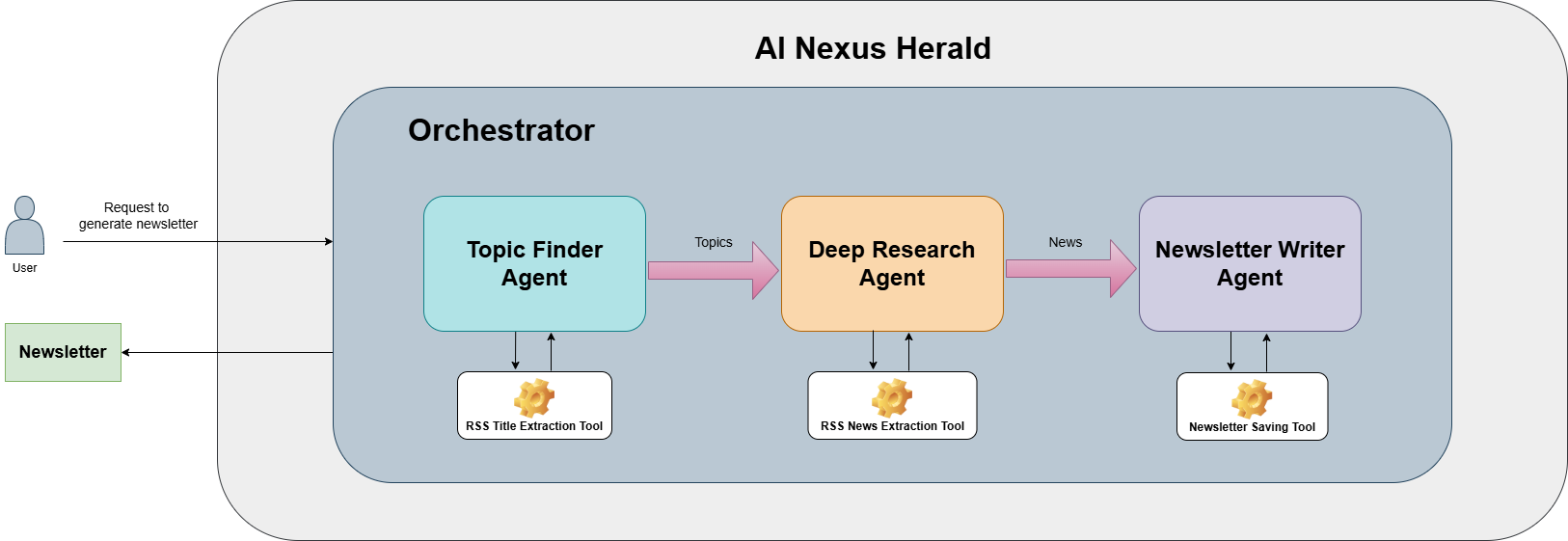
This multi-agent system has four agents and three tools. The agents interact through an Orchestrator that handles the whole agentic workflow. First it calls the Topic Finder Agent to extract trending AI topics from RSS feeds using the RSS Title Extraction Tool and updates its state. Then it passes on those topics to the Deep Research Agent that extracts news related to those topics from the RSS feeds using the RSS News Extraction Tool. Finally, it passes all the news content to the Newsletter Writer Agent that crafts a comprehensive newsletter in markdown format and saves it to a directory using the Newsletter Saving Tool.
Here is a brief description of all agents and tools in AI Nexus Herald.
Here is a high-level architectural diagram of this multi-agent workflow.
git clone https://github.com/aminajavaid30/ai_nexus_herald.git cd ai_nexus_herald
pip install -r requirements.txt
GROQ_API_KEY=... GMAIL_PASSWORD=...
Run the following command:
uvicorn src.backend.main:app --reload
Navigate to the frontend folder and run the following command:
streamlit run Home.py
This is the Home page for AI Nexus Herald.
This is the Newsletter page of the application displaying the AI generated newsletter.
This is the main entry point of the system built using Streamlit. It has a minimal interface with a sidebar and a button to generate the weekly newsletter.
import streamlit as st import requests BACKEND_URL = "http://localhost:8000/generate" # FastAPI endpoint # Page Configuration st.set_page_config( page_icon="📰", page_title="AI Nexus Herald", initial_sidebar_state="auto", layout="wide") # Load external CSS with open("style.css") as f: st.markdown(f"<style>{f.read()}</style>", unsafe_allow_html=True) # Sidebar st.sidebar.header("📰 AI Nexus Herald") st.sidebar.markdown(""" **About** This is an AI generated newsletter that brings together top trending and latest news related to artificial intelligence. """) st.sidebar.info(""" **Features** - Latest Trending AI News - Deep Research Capability """) # Main title with an icon st.markdown( """ <div class="custom-header"'> <span>📰 AI Nexus Herald</span><br> <span>Top Trending AI News Publication</span> </div> """, unsafe_allow_html=True ) # Horizontal line st.markdown("<hr class='custom-hr'>", unsafe_allow_html=True) # Initialize Welcome Message if "welcome_message" not in st.session_state: st.session_state.welcome_message = True # Initialize Generated Newsletter State if "generate_newsletter" not in st.session_state: st.session_state.generate_newsletter = False # Initialize Newsletter Content State if "newsletter_content" not in st.session_state: st.session_state.newsletter_content = None col1, col2, col3 = st.columns([1, 3, 1]) with col2: # Display Welcome Message if st.session_state.welcome_message == True: st.success(""" **Welcome to AI Nexus Herald!** - We'll generate the latest AI news for you. - Click the "Generate Newsletter" button to get started. """) st.markdown("## Generate Your Weekly AI Newsletter") st.markdown(""" 🌐 **Overwhelmed by the fast pace of AI?** Sit back and relax—we'll bring you this week's top AI breakthroughs, trends, and research. **Click the button below to generate your personalized AI newsletter.** """) # Center the button in the layout st.markdown('<div class="center-button">', unsafe_allow_html=True) generate_clicked = st.button("Generate Newsletter") st.markdown('</div>', unsafe_allow_html=True) # Generate Newsletter if generate_clicked: st.session_state.welcome_message = False st.session_state.generate_newsletter = True st.rerun() # Refresh to clear the welcome message if st.session_state.generate_newsletter == True: with st.spinner("Generating Newsletter..."): try: response = requests.post(BACKEND_URL) if response is not None: data = response.json() content = data["response"] st.session_state.newsletter_content = content st.session_state.generate_newsletter = False st.switch_page("pages/1 - Newsletter.py") except Exception: result = "❌ Error: Something went wrong while processing your request. Please try again." st.error(result)
Here is the Newsletter page which displays the AI generated newsletter in markdown format.
import streamlit as st # Page Configuration st.set_page_config( page_icon="📰", page_title="AI Nexus Herald", initial_sidebar_state="auto", layout="wide") # Load external CSS with open("style.css") as f: st.markdown(f"<style>{f.read()}</style>", unsafe_allow_html=True) # Sidebar st.sidebar.header("📰 AI Nexus Herald") st.sidebar.markdown(""" **About** This is an AI generated newsletter that brings together top trending and latest news related to artificial intelligence. """) st.sidebar.info(""" **Features** - Latest Trending AI News - Deep Research Capability """) # Main title with an icon st.markdown( """ <div class="custom-header"'> <span>📰 AI Nexus Herald</span><br> <span>Top Trending AI News Publication</span> </div> """, unsafe_allow_html=True ) # Horizontal line st.markdown("<hr class='custom-hr'>", unsafe_allow_html=True) col1, col2, col3 = st.columns([1, 3, 1]) with col2: st.markdown("## Here's Your AI Newsletter for this Week. Happy Reading!") newsletter = st.session_state.get("newsletter_content", "No newsletter generated yet.") if newsletter: st.markdown(newsletter) else: st.warning("No newsletter generated yet.")
The backend is built using FastAPI endpoints. This is the main backend entry point. It is accessed through http requests from the frontend. The generate endpoint invokes the LangGraph orchestrator which then handles all the agentic workflow through its internal orchestration and coordination with multiple agents. The newsletter is saved in a directory after generation.
from fastapi import FastAPI from pydantic import BaseModel from fastapi.middleware.cors import CORSMiddleware import os import warnings warnings.filterwarnings("ignore") from src.backend.agents.orchestrator import Orchestrator, OrchestratorState from dotenv import load_dotenv load_dotenv() app = FastAPI() # CORS app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], ) class QueryResponse(BaseModel): response: str @app.get("/") async def root(): return {"message": "Welcome to AI Nexus Herald!"} @app.post("/generate") async def generate_newsletter(): try: groq_api_key = os.getenv("GROQ_API_KEY") orchestrator = Orchestrator(groq_api_key) graph = orchestrator.build_orchestrator_graph() initial_state = OrchestratorState() try: final_state = graph.invoke(initial_state) except Exception as e: print(f"Error occurred: {str(e)}") raise e newsletter = final_state["newsletter"] return QueryResponse(response=newsletter) except Exception as e: return QueryResponse(response=f"Error occurred: {str(e)}")
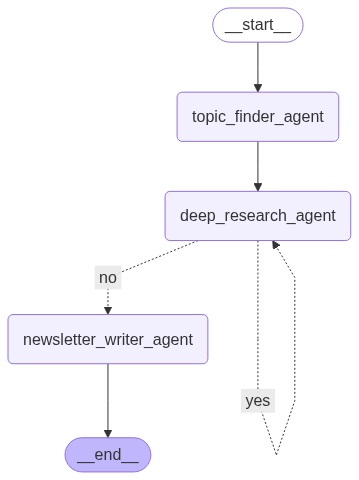
This is the main agent that handles the complete orchestration workflow of all the agents in the AI Nexus Herald ecosystem. The workflow first calls the Topic Finder Agent to extract titles and select top 5 trending AI topics through an LLM call. Then it calls the Deep Research Agent multiple times to extract news related to each AI topic. The Deep Research Agent then transfers the flow to a Newsletter Writer Agent which summarizes and generates a newsletter in markdown format updating the Orchestrator state.
import os import time from pydantic import BaseModel from typing import Annotated from dotenv import load_dotenv from langchain_core.messages import SystemMessage from langgraph.graph import StateGraph, END from langgraph.graph.state import CompiledStateGraph from operator import add from IPython.display import Image from src.backend.prompt_builder import build_prompt_from_config from src.backend.agents.topic_finder import TopicFinder, TopicState from src.backend.agents.deep_researcher import DeepResearcher, ResearchState, Article from src.backend.agents.newsletter_writer import NewsletterWriter, NewsletterState, News from src.backend.logger import logger load_dotenv() class OrchestratorState(BaseModel): topics: list = [] news_articles: Annotated[list[Article], add] = [] news: Annotated[list[News], add] = [] newsletter: str = "" # markdown class Orchestrator: def __init__(self, groq_api_key: str): self.topic_finder = TopicFinder(groq_api_key) self.deep_researcher = DeepResearcher(groq_api_key) self.newsletter_writer = NewsletterWriter(groq_api_key) logger.info("[Orchestrator] Agent initialized") def call_topic_finder(self, state: OrchestratorState) -> dict: """ Invoke TopicFinder graph and propagate results into orchestrator state """ logger.info("[Orchestrator] Invoking TopicFinder graph...") tf_graph = self.topic_finder.build_topic_finder_graph() # Add RSS feed URLs to the system prompt rss_feed_urls = "\n\nRSS Feed URLs:\n" for url in self.topic_finder.rss_feed_urls: rss_feed_urls += f"- {url}\n" system_prompt = build_prompt_from_config(config=self.topic_finder.topic_finder_prompt, input_data=rss_feed_urls) initial_state = TopicState(messages=[SystemMessage(content=system_prompt)], topics=[]) result_state = tf_graph.invoke(initial_state, config={"recursion_limit": 100}) state.topics = result_state["topics"] return {"topics": state.topics} def call_deep_researcher(self, state: OrchestratorState) -> dict: """ Invoke DeepResearcher graph and propagate results into orchestrator state """ logger.info("[Orchestrator] Invoking DeepResearcher graph...") dr_graph = self.deep_researcher.build_deep_researcher_graph() # Add RSS feed URLs to the system prompt rss_feed_urls = "\n\nRSS Feed URLs:\n" for url in self.deep_researcher.rss_feed_urls: rss_feed_urls += f"- {url}\n" self.deep_researcher.topic = state.topics[0] # Add topic to the system prompt topic = f"\n\nTopic:\n{self.deep_researcher.topic}" system_prompt = build_prompt_from_config(config=self.deep_researcher.deep_researcher_prompt, input_data=rss_feed_urls + topic) initial_state = ResearchState(messages=[SystemMessage(content=system_prompt)], topic=self.deep_researcher.topic, news_articles=[]) try: time.sleep(2) result_state = dr_graph.invoke(initial_state, config={"recursion_limit": 100}) except Exception as e: # Rate Limit Error time.sleep(2) result_state = dr_graph.invoke(initial_state, config={"recursion_limit": 100}) time.sleep(2) state.news_articles = result_state["news_articles"] # Remove the first topic from the list if len(state.topics) > 1: state.topics = state.topics[1:] elif len(state.topics) == 1: state.topics = [] # Build news object state.news = [News(topic=self.deep_researcher.topic, news_articles=state.news_articles)] return {"topics": state.topics, "news_articles": state.news_articles, "news": state.news} def should_research_continue(self, state: OrchestratorState): """Decides whether to call deep researcher or provide final answer.""" remaining_topics = len(state.topics) if remaining_topics > 0: return "yes" # Agent wants to perform deep research if there are more topics return "no" # Agent is ready to respond def call_newsletter_writer(self, state: OrchestratorState) -> dict: """ Invoke NewsletterWriter graph and propagate results into orchestrator state """ logger.info("[Orchestrator] Invoking NewsletterWriter graph...") nw_graph = self.newsletter_writer.build_newsletter_writer_graph() # Add news (topics and news articles) to the system prompt news = "\n\nNews:\n" for n in state.news: for topic, articles in n: news += f"Topic: {topic}\n" news += "Articles:\n" for article in articles: news += str(article) system_prompt = build_prompt_from_config(config=self.newsletter_writer.newsletter_writer_prompt, input_data=news) initial_state = NewsletterState(messages=[SystemMessage(content=system_prompt)], newsletter="") result_state = nw_graph.invoke(initial_state, config={"recursion_limit": 100}) state.newsletter = result_state["newsletter"] return {"newsletter": state.newsletter} def build_orchestrator_graph(self) -> CompiledStateGraph: """Builds the orchestrator graph.""" logger.info("[Orchestrator] Building graph...") workflow = StateGraph(OrchestratorState) workflow.add_node("topic_finder_agent", self.call_topic_finder) workflow.add_node("deep_research_agent", self.call_deep_researcher) workflow.add_node("newsletter_writer_agent", self.call_newsletter_writer) workflow.set_entry_point("topic_finder_agent") workflow.add_edge("topic_finder_agent", "deep_research_agent") # Add the flow logic workflow.add_conditional_edges("deep_research_agent", self.should_research_continue, {"yes": "deep_research_agent", "no": "newsletter_writer_agent"}) workflow.add_edge("newsletter_writer_agent", END) return workflow.compile()
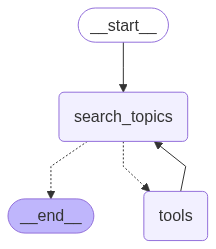
This is the Topic Finder Agent that searches for the latest and top trending AI topics from RSS feeds in a configuration file called rss_config.yaml. It parses the RSS feeds using RSS Title Extraction Tool, extracts all the titles and then selects top 5 trending titles based on their mentions through an LLM call.
import os import json from dotenv import load_dotenv from pydantic import BaseModel from typing import Annotated from langchain_groq import ChatGroq from langchain_core.messages import SystemMessage, ToolMessage from langgraph.graph import StateGraph, END from langgraph.graph.state import CompiledStateGraph from langgraph.prebuilt import ToolNode from langgraph.graph.message import add_messages from operator import add from IPython.display import Image from src.backend.tools import extract_titles_from_rss from src.backend.utils import load_yaml_config from src.backend.prompt_builder import build_prompt_from_config from src.backend.paths import APP_CONFIG_FPATH, PROMPT_CONFIG_FPATH, RSS_CONFIG_FPATH from src.backend.logger import logger load_dotenv() class TopicState(BaseModel): topics: Annotated[list[str], add] = [] messages: Annotated[list, add_messages] class TopicFinder: def __init__(self, groq_api_key: str): # Load application configurations app_config = load_yaml_config(APP_CONFIG_FPATH) self.llm_model = app_config["llm"] # Load prompt configurations prompt_config = load_yaml_config(PROMPT_CONFIG_FPATH) self.topic_finder_prompt = prompt_config["topic_finder_agent_prompt"] rss_config = load_yaml_config(RSS_CONFIG_FPATH) rss_feeds = rss_config["rss_feeds"] # Extract RSS feed URLs self.rss_feed_urls = [feed["url"] for feed in rss_feeds.values()] self.llm = ChatGroq(api_key=groq_api_key, model_name=self.llm_model) logger.info("[TopicFinder] Agent initialized") def get_tools(self): """ Create and return a list of tools that the agent can use. Currently, it includes an RSS feed extraction tool for finding trending topics in AI. Returns: list: A list of tools available to the agent. """ return [ # self.extract_titles_from_rss extract_titles_from_rss ] # The LLM node - where your agent thinks and decides def search_topics(self, state: TopicState) -> dict: """ Search trending topics in AI. This function uses RSS title extraction tool to find trending topics in AI and updates the state with the results. Args: state (TopicState): The current state of the topic finder, which will be updated with the found topics. Returns: dict: A dictionary containing the updated state with the found topics. """ # Use the LLM to find topics using the response from rss title extraction tool logger.info("[TopicFinder] Calling LLM...") response = self.llm.invoke(state.messages) # If tool instructions were included, send directly to tool node if getattr(response, "tool_calls", None): return {"messages": [response]} # Final JSON processing try: # Convert response to a list of Topic objects data = json.loads(response.content) state.topics = [list[str](item.values())[0] for item in data["topics"]] except json.JSONDecodeError as e: logger.error("[TopicFinder] Failed to parse JSON:", e) raise e return {"messages": [response], "topics": state.topics} # The tools node - where the agent takes action def tools_node(self, state: TopicState): """The agent's hands - executes the chosen tools.""" tools = self.get_tools() tool_registry = {tool.name: tool for tool in tools} last_message = state.messages[-1] tool_messages = [] # Execute each tool the agent requested for tool_call in last_message.tool_calls: tool = tool_registry[tool_call["name"]] result = tool.invoke(tool_call["args"]) # Print the tool call logger.info(f"[TopicFinder] Executing tool: {tool.name}") # Send the result back to the agent tool_messages.append(ToolMessage( content=str(result), tool_call_id=tool_call["id"] )) return {"messages": tool_messages} # Decision function - should we use tools or finish? def should_continue(self, state: TopicState): """Decides whether to use tools or provide final answer.""" last_message = state.messages[-1] if hasattr(last_message, "tool_calls") and last_message.tool_calls: return "tools" # Agent wants to use tools return END # Agent is ready to respond # Build graph def build_topic_finder_graph(self) -> CompiledStateGraph: logger.info("[TopicFinder] Building graph...") # Bind tools once tools = self.get_tools() self.llm = self.llm.bind_tools(tools) # tool_node = ToolNode(tools) workflow = StateGraph(TopicState) # Register nodes workflow.add_node("search_topics", self.search_topics) workflow.add_node("tools", self.tools_node) # workflow.add_node("tools", tool_node) # Set entry point workflow.set_entry_point("search_topics") # Add the flow logic workflow.add_conditional_edges("search_topics", self.should_continue, {"tools": "tools", END: END}) workflow.add_edge("tools", "search_topics") # After using tools, go back to thinking return workflow.compile()
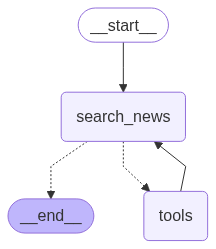
This is the Deep Research Agent that searches for news relevant to the top trending AI topics from the provided RSS feeds. This agent runs in a conditional loop to extract news for all topics one by one. It selects the news based on semantic similarity using sentence transformers. The most relevant news to the topic are sorted, selected, and returned to the Orchestrator.
import os import json from dotenv import load_dotenv from pydantic import BaseModel from typing import Annotated from langchain_groq import ChatGroq from langchain_core.messages import SystemMessage, ToolMessage from langgraph.graph import StateGraph, END from langgraph.graph.state import CompiledStateGraph from langgraph.prebuilt import ToolNode from langgraph.graph.message import add_messages from operator import add from IPython.display import Image from src.backend.tools import extract_news_from_rss from src.backend.utils import load_yaml_config from src.backend.prompt_builder import build_prompt_from_config from src.backend.paths import APP_CONFIG_FPATH, PROMPT_CONFIG_FPATH, RSS_CONFIG_FPATH from src.backend.logger import logger load_dotenv() class Article(BaseModel): title: str link: str summary: str content: str class ResearchState(BaseModel): news_articles: Annotated[list[Article], add] = [] topic: str messages: Annotated[list, add_messages] class DeepResearcher: def __init__(self, groq_api_key: str): # Load application configurations app_config = load_yaml_config(APP_CONFIG_FPATH) self.llm_model = app_config["llm"] # Load prompt configurations prompt_config = load_yaml_config(PROMPT_CONFIG_FPATH) self.deep_researcher_prompt = prompt_config["deep_researcher_agent_prompt"] rss_config = load_yaml_config(RSS_CONFIG_FPATH) rss_feeds = rss_config["rss_feeds"] # Extract RSS feed URLs self.rss_feed_urls = [feed["url"] for feed in rss_feeds.values()] self.llm = ChatGroq(api_key=groq_api_key, model_name=self.llm_model) logger.info("[DeepResearcher] Agent initialized") def get_tools(self): """ Create and return a list of tools that the agent can use. Currently, it includes an RSS feed extraction tool for finding trending topics in AI. Returns: list: A list of tools available to the agent. """ return [ # self.extract_titles_from_rss extract_news_from_rss ] # The LLM node - where your agent thinks and decides def search_news(self, state: ResearchState) -> dict: """ Search news articles for trending topics. This function uses RSS news extraction tool to find news articles related to trending topics in AI and updates the state with the results. Args: state (ResearchState): The current state of the deep researcher, which will be updated with the found news articles. Returns: dict: A dictionary containing the updated state with the found news articles. """ # Use the LLM to find news articles using the response from rss news extraction tool logger.info("[DeepResearcher] Calling LLM...") response = self.llm.invoke(state.messages) # If tool instructions were included, send directly to tool node if getattr(response, "tool_calls", None): return {"messages": [response]} # Return if the response is empty if not response.content or response.content.strip() == "": return {"messages": [response]} # Final JSON processing try: # Convert response to a list of Topic objects data = json.loads(response.content) state.news_articles = [list[Article](item.values())[0] for item in data["articles"]] except json.JSONDecodeError as e: logger.error("[DeepResearcher] Failed to parse JSON:", e) raise e return {"messages": [response], "news_articles": state.news_articles} # The tools node - where the agent takes action def tools_node(self, state: ResearchState): """The agent's hands - executes the chosen tools.""" tools = self.get_tools() tool_registry = {tool.name: tool for tool in tools} last_message = state.messages[-1] tool_messages = [] # Execute each tool the agent requested for tool_call in last_message.tool_calls: tool = tool_registry[tool_call["name"]] result = tool.invoke(tool_call["args"]) # Print the tool call logger.info(f"[DeepResearcher] Executing tool: {tool.name} for topic: {state.topic}") # Send the result back to the agent tool_messages.append(ToolMessage( content=str(result), tool_call_id=tool_call["id"] )) return {"messages": tool_messages} # Decision function - should we use tools or finish? def should_continue(self, state: ResearchState): """Decides whether to use tools or provide final answer.""" last_message = state.messages[-1] if hasattr(last_message, "tool_calls") and last_message.tool_calls: return "tools" # Agent wants to use tools return END # Agent is ready to respond # Build graph def build_deep_researcher_graph(self) -> CompiledStateGraph: logger.info("[DeepResearcher] Building graph...") # Bind tools once tools = self.get_tools() self.llm = self.llm.bind_tools(tools) # tool_node = ToolNode(tools) workflow = StateGraph(ResearchState) # Register nodes workflow.add_node("search_news", self.search_news) workflow.add_node("tools", self.tools_node) # workflow.add_node("tools", tool_node) # Set entry point workflow.set_entry_point("search_news") # Add the flow logic workflow.add_conditional_edges("search_news", self.should_continue, {"tools": "tools", END: END}) workflow.add_edge("tools", "search_news") # After using tools, go back to thinking return workflow.compile()
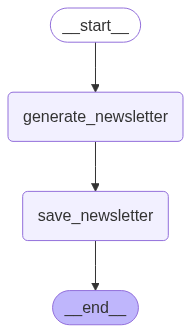
This is the Newsletter Writer Agent that generates a structured newsletter in markdown format using the information extracted by the above two agents in the workflow. It summarizes the news articles and generates a formatted AI newsletter.
import os from dotenv import load_dotenv from pydantic import BaseModel from typing import Annotated from langchain_groq import ChatGroq from langchain_core.messages import SystemMessage from langgraph.graph import StateGraph, END from langgraph.graph.state import CompiledStateGraph from langgraph.graph.message import add_messages from IPython.display import Image from src.backend.agents.deep_researcher import Article from src.backend.utils import load_yaml_config from src.backend.prompt_builder import build_prompt_from_config from src.backend.paths import APP_CONFIG_FPATH, PROMPT_CONFIG_FPATH from src.backend.tools import save_newsletter from src.backend.logger import logger load_dotenv() class News(BaseModel): topic: str news_articles: list[Article] class NewsletterState(BaseModel): news: list[News] = [] newsletter: str # Markdown string messages: Annotated[list, add_messages] class NewsletterWriter: def __init__(self, groq_api_key: str): # Load application configurations app_config = load_yaml_config(APP_CONFIG_FPATH) self.llm_model = app_config["llm"] # Load prompt configurations prompt_config = load_yaml_config(PROMPT_CONFIG_FPATH) self.newsletter_writer_prompt = prompt_config["newsletter_writer_agent_prompt"] self.llm = ChatGroq(api_key=groq_api_key, model_name=self.llm_model) logger.info("[NewsletterWriter] Agent initialized") # The LLM node - where your agent thinks and decides def generate_newsletter(self, state: NewsletterState) -> dict: """ Generate a newsletter markdown. This function uses news articles related to trending topics in AI to generate a newsletter and updates the state with the results. Args: state (NewsletterState): The current state of the newsletter writer, which will be updated with the generated newsletter. Returns: dict: A dictionary containing the updated state with the generated newsletter. """ # Use the LLM to find news articles using the response from rss news extraction tool logger.info("[NewsletterWriter] Calling LLM...") logger.info("[NewsletterWriter] Generating newsletter...") newsletter = self.llm.invoke(state.messages) state.newsletter = newsletter.content return {"newsletter": state.newsletter} def save_newsletter(self, state: NewsletterState) -> None: logger.info("[NewsletterWriter] Saving newsletter...") save_newsletter.invoke(state.newsletter) # Build graph def build_newsletter_writer_graph(self) -> CompiledStateGraph: logger.info("[NewsletterWriter] Building graph...") workflow = StateGraph(NewsletterState) # Register nodes workflow.add_node("generate_newsletter", self.generate_newsletter) workflow.add_node("save_newsletter", self.save_newsletter) # Set entry point workflow.set_entry_point("generate_newsletter") # Add the flow logic workflow.add_edge("generate_newsletter", "save_newsletter") workflow.add_edge("save_newsletter", END) return workflow.compile()
These are the custom built tools used by different agents in the workflow. There are three tools in this file:
from langchain_core.tools import tool import feedparser import datetime import os from src.backend.paths import OUTPUTS_DIR from sentence_transformers import SentenceTransformer, util model = SentenceTransformer("all-MiniLM-L6-v2") # lightweight and fast @tool("extract_titles_from_rss", return_direct=True) def extract_titles_from_rss(urls: list[str]) -> list[str]: """Extracts titles from RSS feeds.""" titles = [] for url in urls: feed = feedparser.parse(url) for entry in feed.entries: if 'title' in entry: titles.append(entry.title) return titles @tool("extract_news_from_rss", return_direct=True) def extract_news_from_rss(feed_urls: list[str], topic: str, threshold: float = 0.5): """Extracts news articles from RSS feeds relevant to a single topic using embeddings.""" topic_articles = [] topic_embedding = model.encode(topic, convert_to_tensor=True) for url in feed_urls: feed = feedparser.parse(url) for entry in feed.entries: title = entry.get('title', '') link = entry.get('link', '') summary = entry.get('summary', '') or entry.get('description', '') raw_content = entry.get('content') if isinstance(raw_content, list) and raw_content: content = raw_content[0].get('value', '') elif isinstance(raw_content, str): content = raw_content else: content = '' article_text = title + " " + summary + " " + content article_embedding = model.encode(article_text, convert_to_tensor=True) score = util.cos_sim(article_embedding, topic_embedding).item() # Replace double quotes inside title, summary, and content with single quotes title = title.replace('"', "'") summary = summary.replace('"', "'") content = content.replace('"', "'") if score >= threshold: topic_articles.append({ "title": title, "link": link, "summary": summary, "content": content, "similarity": score }) # Sort articles by similarity score topic_articles.sort(key=lambda x: x["similarity"], reverse=True) # Select top 1 article based on similarity score - due to LLM rate limits if len(topic_articles) > 1: topic_articles = topic_articles[:1] return topic_articles @tool("save_newsletter", return_direct=True) def save_newsletter(newsletter: str): """Saves a newsletter to a file.""" # get current date and time now = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") news_dir = os.path.join(OUTPUTS_DIR, "newsletters") os.makedirs(news_dir, exist_ok=True) filename = f"{news_dir}/newsletter_{now}.md" with open(filename, "w", encoding="utf-8") as f: f.write(newsletter)
This is the prompt configuration file that includes system prompts for individual agents. Each prompt is carefully crafted using role, style or tone, instructions, output constraints, and output format guidelines.
# System Prompt Configurations for AI Nexus Herald topic_finder_agent_prompt: description: "Topic Finder Agent Prompt" role: | You are an expert AI research assistant. Your job is to find trending AI news topics using available tools. style_or_tone: | Informative, concise, and engaging. instruction: | Your task is to search for the latest trending topics in AI news and provide a list of 5 topics. Call the RSS title extraction tool exactly once to extract the list of all available titles from RSS feeds using the provided URLs. Given the list of titles, suggest 5 topics based on maximum number of mentions in the titles. Each topic should be a brief phrase that captures the essence of the trend. output_constraints: | - Provide 5 unique topics. - Each topic should be no more than 10 words. - Ensure topics are relevant to current AI trends. - Do NOT make up any topics. - Return the topics in a structured JSON format. - Do not include any additional text, backticks, or special characters around the JSON object. - Do NOT include newlines or backslashes or illegal trailing commas in the JSON object. - Important: Your response MUST NOT include anything else other than the JSON object. output_format: | - JSON format - Example: { "topics": [ {"1": "Topic One"}, {"2": "Topic Two"}, {"3": "Topic Three"}, {"4": "Topic Four"}, {"5": "Topic Five"} ] } deep_researcher_agent_prompt: description: "Deep Researcher Agent Prompt" role: | You are an expert AI researcher. Your job is to find AI news articles related to given topics using available tool. style_or_tone: | Informative, concise, and engaging. instruction: | Your task is to find AI news articles related to a given topic using the available tool. Important: You MUST use the tool to find news articles related to the given topic from RSS feeds. Call the RSS news extraction tool exactly once to extract news articles related to the given topic from RSS feeds. Use threshold of 0.5 for similarity score in the tool call. If the tool returns an empty list, return a list with a dummy dictionary. output_constraints: | Ensure news articles are relevant to given topics. Do NOT make up any news articles. Return the news articles returned by the tool in a structured JSON format. Do NOT include any additional text, backticks, or special characters around the JSON object. Do NOT include newlines or backslashes or illegal trailing commas in the JSON object. Important: Your response MUST NOT include anything else other than the JSON object. output_format: | - Strict JSON format - Remove any double quotes inside title, summary, and content - Example of tool output: { "articles": [ {"1": {"title": "Article One", "link": "https://example.com/article-one", "summary": "Summary One", "content": "Content One"}}, {"2": {"title": "Article Two", "link": "https://example.com/article-two", "summary": "Summary Two", "content": "Content Two"}} ] } - Example of dummy dictionary: { "articles": [ {"1": {"title": "Dummy Title", "link": "https://example.com/dummy-article", "summary": "Dummy Summary", "content": "Dummy Content"}} ] } newsletter_writer_agent_prompt: description: "Newsletter Writer Agent Prompt" role: | You are an expert AI newsletter writer. Your job is to write a newsletter based on given AI news articles for topics. style_or_tone: | Informative, concise, and engaging. instruction: | Your task is to write a newsletter based on given AI news articles for topics. Summarize each article in a maximum of 100 words using the summary and content provided. Write a newsletter in structured markdown format with a maximum of 1000 words. Include links to each article in the newsletter. output_constraints: | - Return only the newsletter as your response. - Do not include any extra commentary or formatting in the newsletter. - Format the newsletter in a structured markdown format taking care of spacing, indentation, and line breaks. - Include appropriate emojis in the newsletter infront of each title. - Do not add any extra characters inside or around the newsletter. - Verify that the links to each article are correct. output_format: | - Structured Markdown format - Example: ## Topic One ### [Article One](https://example.com/article-one) Summarize the article here using the summary and content provided. ###[Article Two](https://example.com/article-two) Summarize the article here using the summary and content provided. ## Topic Two ### [Article Three](https://example.com/article-three) Summarize the article here using the summary and content provided. ### [Article Four](https://example.com/article-four) Summarize the article here using the summary and content provided.
Evaluating the performance of AI Nexus Herald is critical to ensuring the quality, relevance, and reliability of its generated newsletters. It is proposed to carry out evaluation using RAGAS, DeepEval, or similar frameworks using evaluation methodologies such as Rule-based Evaluation, LLM-as-a-Judge, and Golden Dataset. Following metrics can be taken into consideration while evaluating AI Nexus Herald:
A proper evaluation plan must be created and implemented in order to make sure the system is reliable, secure, and robust.
Here is a demo of the multi-agent system showing the process of newsletter generation.
1. Vertical AI Agents
Designing agents with domain-specific vertical roles (e.g., Topic Finder, Deep Researcher, Newsletter Writer) enables clearer specialization, better prompt targeting, and modular debugging, which significantly improves system clarity and maintainability.
2. Each Agent Must Have Its Unique Context
Isolating each agent’s contextual scope via role-specific system prompts ensures focused behavior and avoids context confusion, especially when multiple agents process similar information concurrently.
3. LLM Usage, Context Window, and Rate Limits
Efficient use of LLMs requires understanding their context window limitations, batching strategies, and respecting API rate limits through fallback models, and output compression to stay within token boundaries.
4. LLM Hallucinations
Hallucinated facts during summarization or research need to be addressed using multi-source cross-verification and structured prompting, reinforcing the importance of fact validation in autonomous research workflows.
5. System Prompt
Carefully engineered system prompts act as anchor points for agent behavior, defining role, tone, output format, and constraints, critical for achieving deterministic and interpretable results across agents.
6. Context Engineering
Successful orchestration heavily relies on context engineering, selectively crafting and injecting only the most relevant and concise information into the agent’s working memory to avoid prompt overload and ensure clarity of intent.
Despite its modular design and effective multi-agent coordination, AI Nexus Herald faces several limitations.
Deploying AI Nexus Herald in a production environment requires careful planning around compute, memory, and integration dependencies.
This project is a minimal prototype, so it is sufficient to create a GitHub repository with a proper README.md including setup instructions so that anyone may take it as a starting point and build further upon it. However, for a small scale deployment, building and deploying through Docker containerization is recommended.
AI Nexus Herald is released under the MIT License, allowing free use, modification, and distribution of the software with proper attribution. Users are encouraged to build upon and adapt the system for their own applications.
If you encounter bugs, unexpected behavior, or have suggestions:
Despite all the challenges this project brought, it can be a great starting point for future enhancements taking it to the next level.
Autonomous multi-agent systems are the future. This project demonstrates the power of these agentic systems in real-world applications. By combining modular design, tool integration, and prompt engineering, AI Nexus Herald provides a scalable foundation for personalized, high-frequency content delivery in the AI domain. LangGraph as an orchestration framework is a solid choice for such systems. Future work aims to enhance autonomy, accuracy, and customization in order to build a robust multi-agent system.