Introduction
In the rapidly evolving landscape of artificial intelligence, Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for combining large language models with external knowledge sources. This publication presents an Advanced Agentic RAG System that leverages multiple specialized agents working in concert to provide accurate, fact-checked, and safe responses to user queries.
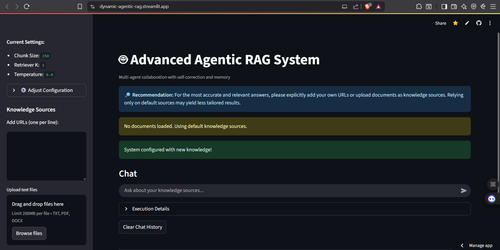
Figure 1: Main interface of the Advanced Agentic RAG System showing configuration options, knowledge sources, and chat interface
The system represents a significant advancement over traditional RAG implementations by incorporating self-correction mechanisms, fact-checking capabilities, and safety protocols through a sophisticated multi-agent architecture built on LangGraph.
System Architecture
Core Components
The Advanced Agentic RAG System is built upon a robust technology stack:
-
Streamlit: Provides an intuitive web interface for user interaction
-
LangChain: Offers comprehensive RAG capabilities and tool integration
-
LangGraph: Enables sophisticated multi-agent workflow orchestration
-
Chroma: Serves as the vector store for efficient document retrieval
-
Google Generative AI Embeddings: Powers semantic search capabilities
-
Groq: Delivers high-performance LLM inference with Llama 3
-
Tavily Search: Provides real-time web search capabilities
Multi-Agent Design
The system employs nine specialized agents, each with distinct responsibilities:
1. Router Agent: Determines the optimal workflow path based on query analysis
2. Retrieval Agent: Fetches relevant documents from the knowledge base
3. Reformulation Agent: Improves query formulation for better retrieval
4. Web Search Agent: Accesses real-time information when needed
5. Synthesis Agent: Combines information from multiple sources
6. Generation Agent: Creates coherent final responses
7. Fact Check Agent: Verifies factual claims in generated content
8. Safety Agent: Ensures content appropriateness and harm prevention
9. Clarification Agent: Requests additional information when needed
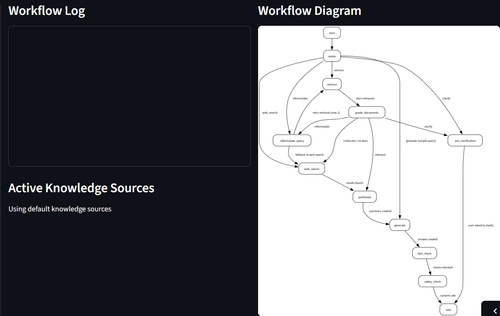
Figure 2: System workflow showing the multi-agent collaboration and decision flow
Key Features and Capabilities
1. Intelligent Query Routing
The system analyzes each query to determine the most appropriate processing path:
def router_agent(state: AgentState) -> dict: """Decide initial workflow path based on query and history""" model = ChatGroq( temperature=st.session_state.temperature, model_name="llama3-70b-8192", groq_api_key=GROQ_API_KEY ) prompt = PromptTemplate( template="""As the Router Agent, analyze the user's question and conversation history to determine the best next step. Conversation History: {history} Current Question: {question} Choose one of these actions: - "retrieve": If question can be answered with known documents - "reformulate": If query needs refinement for better retrieval - "web_search": If question requires current/realtime information - "clarify": If question is ambiguous or needs more details - "generate": If question is simple or conversational Only respond with the action word.""", input_variables=["question", "history"] )
2. Self-Correction Mechanisms
The system implements multiple layers of self-correction:
-
Query Reformulation: Automatically improves poorly formulated queries
-
Document Grading: Evaluates retrieved document relevance
-
Fact-Checking: Verifies claims against external sources
-
Safety Filtering: Ensures content appropriateness
3. Flexible Knowledge Sources
Users can integrate multiple knowledge sources:
# Load from URLs for url in urls: try: docs.extend(WebBaseLoader(url).load()) except Exception as e: st.error(f"Failed to load {url}: {str(e)}") # Load from uploaded files for uploaded_file in uploaded_files: try: ext = os.path.splitext(uploaded_file.name)[1].lower() if ext == ".txt": loader = TextLoader(temp_file_path, encoding="utf-8") elif ext == ".pdf": loader = PyPDFLoader(temp_file_path) elif ext == ".docx": loader = Docx2txtLoader(temp_file_path) # ... process documents
4. Advanced Fact-Checking
The system includes a sophisticated fact-checking agent:
def fact_check_agent(state: AgentState) -> dict: """Fact-check generated answer using web search""" # Identify factual claims claims_prompt = """Identify factual claims in this text. List them as bullet points: {text} Respond ONLY with the bullet points of claims.""" # Verify each claim with web search for claim in claims_list[:3]: search_query = claim[2:] if claim.startswith('- ') else claim results = st.session_state.web_search_tool.invoke({"query": f"Verify: {search_query}"}) verification_prompt = f"""Based on these sources, is this claim true? Claim: {claim} Sources: {sources} Respond with "TRUE" or "FALSE" and a brief explanation.""" verdict = model.invoke(verification_prompt).content verified_claims.append(f"{claim} → {verdict}")
Technical Implementation
State Management
The system uses a comprehensive state management approach:
class AgentState(BaseModel): messages: List[BaseMessage] = Field(default_factory=list) chat_history: List[BaseMessage] = Field(default_factory=list) reformulation_count: int = 0 current_query: Optional[str] = None retrieved_docs: List[Dict[str, Any]] = Field(default_factory=list) generated_answer: Optional[str] = None next_step: Optional[str] = None
Workflow Orchestration
The LangGraph workflow coordinates agent interactions:
workflow = StateGraph(AgentState) # Add specialized agent nodes workflow.add_node("router", router_agent) workflow.add_node("retrieve", retrieve_agent) workflow.add_node("reformulate_query", reformulate_agent) workflow.add_node("web_search", web_search_agent) workflow.add_node("synthesize", synthesize_agent) workflow.add_node("generate", generate_agent) workflow.add_node("fact_check", fact_check_agent) workflow.add_node("safety_check", safety_agent) workflow.add_node("ask_clarification", ask_clarification) # Add edges and conditional routing workflow.add_edge(START, "router") workflow.add_conditional_edges( "router", route_decision, { "retrieve": "retrieve", "reformulate": "reformulate_query", "web_search": "web_search", "clarify": "ask_clarification", "generate": "generate" } )
Vector Store Integration
The system uses Chroma for efficient document retrieval:
# Create vector store embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001", google_api_key=GOOGLE_API_KEY) vectorstore = Chroma.from_documents( documents=doc_splits, collection_name="rag-chroma", embedding=embeddings, ) # Create retriever tool retriever_tool = create_retriever_tool( retriever_instance, "retrieve_knowledge", "Search and return information from the provided knowledge sources.", )
Performance and Benefits
High-Speed Inference
Leveraging Groq's LPU inference engine, the system achieves exceptional performance:
-
Token Processing: Up to 241 tokens per second for Llama 3 70B
-
Low Latency: Sub-second response times for most queries
-
Consistent Quality: No performance degradation under load
Enhanced Accuracy
The multi-agent approach significantly improves response accuracy:
-
Document Relevance Grading: Ensures only relevant information is used
-
Query Reformulation: Improves retrieval success rates
-
Fact-Checking: Reduces hallucinations and inaccuracies
-
Safety Filtering: Prevents harmful or inappropriate content
Scalability and Flexibility
The system architecture supports:
-
Multiple Knowledge Sources: URLs, documents, and real-time web search
-
Configurable Parameters: Chunk size, retrieval K, temperature
-
Extensible Design: Easy to add new agents or modify workflows
-
Multi-User Support: Isolated sessions and state management
Real-World Applications
Enterprise Knowledge Management
The system excels in enterprise environments where:
-
Document Volume: Large collections of internal documents need to be searchable
-
Accuracy Requirements: High-stakes decisions require verified information
-
Security: Sensitive information requires controlled access
-
Compliance: Responses must meet regulatory requirements
Customer Support
For customer support applications, the system provides:
-
Consistent Responses: Standardized answers based on official documentation
-
Real-time Updates: Integration with current product information
-
Multi-language Support: Handling queries in various languages
-
Escalation Path: Clear protocols for complex queries
Research and Analysis
Researchers benefit from:
-
Literature Review: Efficient searching across academic papers
-
Fact Verification: Cross-referencing claims against multiple sources
-
Synthesis Capabilities: Combining information from diverse sources
-
Citation Tracking: Automatic source attribution
Future Enhancements
Planned Improvements
1. Multi-modal Support: Integration of image and video processing
2. Advanced Analytics: Detailed performance metrics and insights
3. Collaborative Filtering: Learning from user feedback patterns
4. Enhanced Security: Role-based access control and audit trails
5. Deployment Options: Cloud-native and on-premises deployment packages
Research Directions
1. Agent Specialization: More granular agent roles and responsibilities
2. Memory Optimization: Efficient long-term conversation memory
3. Cross-lingual Capabilities: Seamless multi-language processing
4. Real-time Learning: Continuous improvement from user interactions
Getting Started
Prerequisites
-
Python 3.8+
-
Streamlit
-
LangChain
-
LangGraph
-
Chroma
-
Google Generative AI API key
-
Groq API key
-
Tavily API key
Github Repo Link
https://github.com/Abdullah-47/Multi-Agentic-RAG/tree/main
Installation
git clone https://github.com/Abdullah-47/Multi-Agentic-RAG/tree/main pip install -r requirements.txt
Configuration
Set up environment variables:
os.environ["LANGCHAIN_TRACING_V2"] = "true" os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com" os.environ["LANGCHAIN_API_KEY"] = "your_langchain_api_key" os.environ["TAVILY_API_KEY"] = "your_tavily_api_key" GOOGLE_API_KEY = "your_google_api_key" GROQ_API_KEY = "your_groq_api_key"
Running the Application
streamlit run app.py
Streamlit Hosted App Link
https://dynamic-agentic-rag.streamlit.app/
References and Resources
Core Technologies
1. LangGraph Multi-Agent Systems - Official Documentation
2. Streamlit for RAG Applications - Medium Article
3. Chroma Vector Store - Analytics Vidhya Guide
4. Google Generative AI Embeddings - Official Documentation
Advanced RAG Techniques
1. Advanced RAG Architectures - Machine Learning Mastery
2. Self-Reflective RAG with LangGraph - LangChain Blog
3. Corrective RAG (CRAG) - LangGraph Tutorial
Performance and Optimization
1. Groq Inference Performance - Official Benchmarks
2. Tavily Search for RAG - Medium Article
3. Fact-checking with LLMs - Research Paper
Community and Support
1. LangChain Community - Discord Server
2. Streamlit Community - Forum
3. Groq Developer Community - GitHub
Conclusion
The Advanced Agentic RAG System represents a significant leap forward in the field of intelligent document processing and question-answering systems. By leveraging multiple specialized agents, self-correction mechanisms, and state-of-the-art technologies, it provides a robust, accurate, and scalable solution for organizations seeking to harness the power of AI with their knowledge bases.
The system's modular architecture, combined with its comprehensive safety and fact-checking features, makes it suitable for deployment in enterprise environments where accuracy, security, and reliability are paramount. As the field of AI continues to evolve, this system provides a solid foundation for future enhancements and adaptations to emerging requirements and technologies.
For organizations looking to implement advanced RAG capabilities, this system offers a proven architecture that balances performance, accuracy, and usability while maintaining the flexibility to adapt to specific use cases and requirements.
This publication is part of an ongoing effort to advance the state of RAG systems and multi-agent AI architectures. For the latest updates and contributions, please refer to the project repository and documentation.