
This project presents a Retrieval-Augmented Generation (RAG)–based assistant designed to explore and answer questions from Ready Tensor publications with accuracy and reliability. The system integrates document loaders, text splitting, embeddings, vector stores, and large language models (LLMs) into a modular pipeline that allows seamless ingestion and retrieval of knowledge from research publications. By combining semantic search with generative language models, the assistant retrieves the most relevant passages from ingested publications and formulates precise, context-aware answers while avoiding hallucination. The architecture supports multiple providers (Groq, Google Gemini) and embedding backends (HuggingFace, Google Generative AI), offering flexibility and scalability. A Gradio-based web interface and command-line interface (CLI) are provided for intuitive interaction. This tool enables researchers, practitioners, and students to efficiently query complex technical documents, ensuring that information from Ready Tensor publications becomes more accessible, interpretable, and actionable.
The methodology for developing the Ready Tensor Publication Explorer – RAG Chatbot follows a modular Retrieval-Augmented Generation (RAG) architecture. The workflow consists of six main phases: data ingestion, text preprocessing, embedding generation, vector storage and retrieval, answer generation, and user interaction. Each phase is implemented as a separate module in the system, ensuring scalability, maintainability, and extensibility.
Publications are collected in multiple formats, including PDF, TXT, Markdown, and JSON. A flexible loader system was implemented using LangChain’s document loaders. Each loader handles its respective format, with a fallback mechanism for plain text.
Code snippet:
from pathlib import Path from langchain_community.document_loaders import PyPDFLoader, TextLoader, UnstructuredMarkdownLoader from langchain.schema import Document import json def load_documents_from_folder(folder: str): folder = Path(folder) docs = [] for p in folder.rglob("*"): if p.is_dir(): continue suffix = p.suffix.lower() if suffix == ".pdf": docs += PyPDFLoader(str(p)).load() elif suffix in {".md", ".markdown"}: docs += UnstructuredMarkdownLoader(str(p)).load() elif suffix == ".txt": docs += TextLoader(str(p), encoding="utf-8").load() elif suffix == ".json": with open(p, "r", encoding="utf-8") as f: data = json.load(f) if isinstance(data, list): for item in data: content = item.get("publication_description", "") if content: docs.append(Document(page_content=content, metadata=item)) else: text = p.read_text(encoding="utf-8", errors="ignore") docs.append(Document(page_content=text, metadata={"source": str(p)})) return docs
This modular approach allows the system to easily integrate new document formats in the future.
Documents are often long and exceed LLM token limits. To address this, documents are segmented into overlapping chunks while preserving semantic continuity and metadata.
Code snippet:
from langchain_text_splitters import RecursiveCharacterTextSplitter from .config import settings def create_splitter(): return RecursiveCharacterTextSplitter( chunk_size=settings.chunk_size, # e.g., 1000 chunk_overlap=settings.chunk_overlap, # e.g., 200 separators=["\n\n", "\n", ". ", "? ", "! ", " "], )
This ensures context is preserved across chunk boundaries, enabling more accurate retrieval.
Each chunk is converted into a dense vector representation using sentence embedding models, enabling semantic search.
Code snippet:
from langchain_huggingface import HuggingFaceEmbeddings def get_embedder(): return HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
The system supports multiple embedding backends, including HuggingFace and Google Generative AI, providing flexibility for performance and cost optimization.
The embeddings are stored in a vector database (Chroma or FAISS). The retriever fetches top-k relevant chunks at query time.
Code snippet:
from langchain_chroma import Chroma class PersistedVectorStore: def create_or_update(self, documents): self.store = Chroma.from_documents( documents, embedding=self.emb, persist_directory=self.persist_directory ) self.store.persist() def as_retriever(self, **kwargs): return self.store.as_retriever(search_kwargs=kwargs)
This enables efficient similarity search, ensuring retrieved chunks are contextually relevant for answering queries.
The retrieved chunks are combined with the user’s query and passed to a large language model (LLM), such as Groq LLaMA or Google Gemini, via a prompt template that enforces fidelity to the source.
Code snippet:
from langchain.chains import RetrievalQA from .llm import get_chat_llm from .retriever import get_retriever from .prompts import QA_SYSTEM def build_rag_chain(persist_directory="VectorStore"): llm = get_chat_llm() retriever = get_retriever(persist_directory=persist_directory) qa = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=retriever, return_source_documents=True, # Return both answer + source documents # return_source_documents=False, # Return only answer chain_type_kwargs={"prompt": QA_SYSTEM} ) return qa
The system prompt ensures the LLM answers only based on retrieved content and refuses to hallucinate.
Two interfaces are provided for user interaction:
Code snippet:
from src.ui.gradio_app import build_and_launch if __name__ == "__main__": build_and_launch()
This dual-interface design enhances usability across different audiences.
The Ready Tensor Publication Explorer – RAG Chatbot was tested on a diverse set of publications in PDF, Markdown, TXT, and JSON formats. The evaluation focused on the system’s accuracy, responsiveness, and usability.
chunk_size=1000, chunk_overlap=200) provided a balance between context retention and performance, ensuring accurate responses without excessive computation.The system provides two interfaces for users:
Screenshot of the RAG Chatbot Interface:
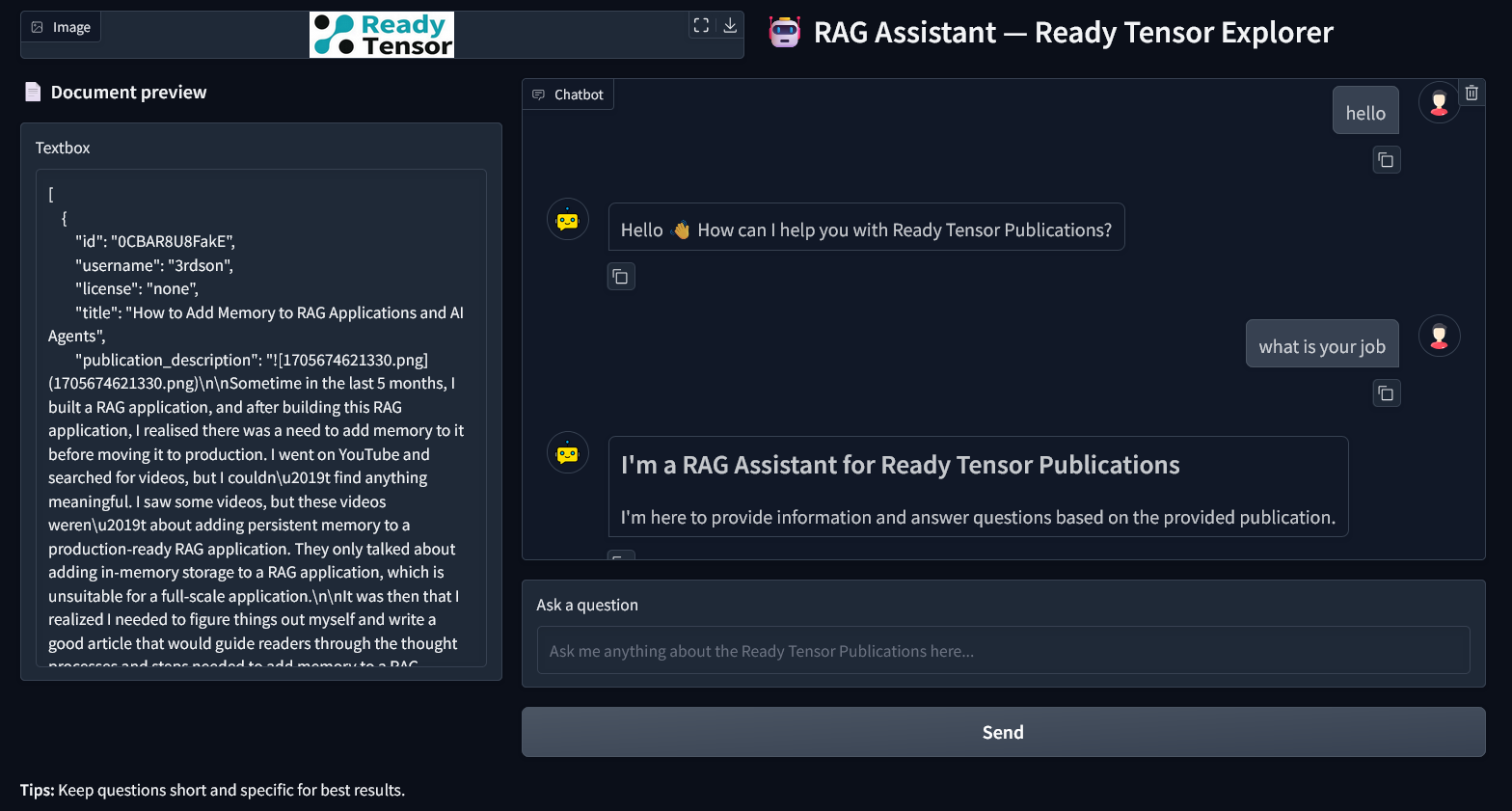
Figure 1: Screenshot of the Ready Tensor Publication Explorer web interface showing a sample query and response. The interface displays document preview, chatbot conversation, and sources of retrieved information.
| Challenge | Solution |
|---|---|
| Large documents exceeding token limits | Implemented hierarchical chunking with overlapping windows to preserve context |
| Hallucination by LLM | Enforced strict system prompts limiting responses to retrieved content |
| Diverse file formats | Modular loaders and JSON parsing handled different formats robustly |
| Vector store persistence issues | Enabled Chroma persistence and ensured re-ingestion when needed |
The Ready Tensor Publication Explorer – RAG Chatbot effectively combines document retrieval and LLM-based synthesis to provide accurate, context-aware, and interactive exploration of publications.
Key points:
This system provides a robust, user-friendly, and extensible solution for knowledge discovery and research applications.
