
This production-ready evolution of the LangGraph-Orchestrated Research Assistant builds on the initial Ready Tensor prototype with significant upgrades in safety, reliability, and usability. The system now incorporates strong guardrails, including input and output validation, prompt protection, and structured response handling. Observability has been improved through advanced logging, user feedback capture, and performance monitoring, ensuring that both errors and efficiency can be tracked effectively. On the deployment side, the assistant is delivered through a Streamlit application, supported by Docker for reproducible builds and cloud-hosting options that allow for scalable adoption. Finally, comprehensive documentation accompanies the release, offering detailed usage guides, step-by-step walkthroughs, and transparent notes on limitations and safety
The primary purpose of this project is to evolve the initial Ready Tensor prototype into a production-ready LangGraph-Orchestrated Research Assistant. While the prototype demonstrated feasibility, this work focuses on building the robustness, safety, and usability required for real-world deployments.
The main objectives are:
This work is significant because it moves beyond proof-of-concept implementations of LangGraph systems and demonstrates how to integrate production best practices such as error handling, monitoring, and deployment pipelines. By bridging the gap between prototype and production, the project contributes to the growing field of agentic AI development and provides a reference architecture for building safe, reliable, and maintainable AI assistants.
The upgraded system transforms the original LangGraph-Orchestrated Research Assistant prototype into a production-grade, reliable, and user-friendly multi-agent AI application. Built on LangChain and LangGraph, it combines structured agent orchestration, strong safety measures, and robust deployment capabilities to handle real-world usage at scale.
The system integrates multiple safeguards to ensure both safe and reliable operation. All inputs and outputs undergo validation to guarantee that only well-structured data is processed. In addition, prompt protection mechanisms are built in to shield the agents from adversarial inputs such as prompt injection attacks. Responses are also constrained to adhere to predefined structures—typically JSON or table-based formats—so that downstream components can consistently parse and use the generated outputs.
Robust observability features make the system easier to monitor, debug, and improve over time. Enhanced logging captures each agent’s decision-making process, along with request–response cycles and any error events that occur during execution. Users are also able to provide direct feedback, submitting corrections or suggestions for improvements. Furthermore, the system includes instrumentation to collect performance metrics, which can be analyzed to optimize both execution time and accuracy.
The project is designed for flexible and scalable deployment. A Streamlit web application provides an interactive interface that makes the tool accessible even to non-technical users. To ensure reproducibility, Docker support is included, enabling containerized builds that behave consistently across environments. For broader adoption, the system also supports deployment to multiple cloud platforms, allowing it to scale seamlessly as demand increases.
To reduce the learning curve, the project ships with comprehensive documentation. Usage guides walk new users through installation and day-to-day interaction with the system. Detailed, step-by-step walkthroughs explain how to perform key tasks and workflows. The documentation also openly addresses the system’s limitations and safety considerations, ensuring transparency around what the tool can and cannot currently do.
The production-ready workflow mirrors the original LangGraph orchestration but with added guardrails and observability hooks at each stage:
Guardrails-AI enforces structured, validated outputs from LLMs.
| Feature | Without Guardrails-AI ❌ | With Guardrails-AI ✅ |
|---|---|---|
| Output format | Free-form, unstructured text | Schema-validated JSON |
| Input flexibility | High | Moderate (requires schema) |
| Retry on invalid | No | Yes |
| Production-safety | Risk of LLM drift | Robust |
| Dev speed | Fast | Requires setup effort |
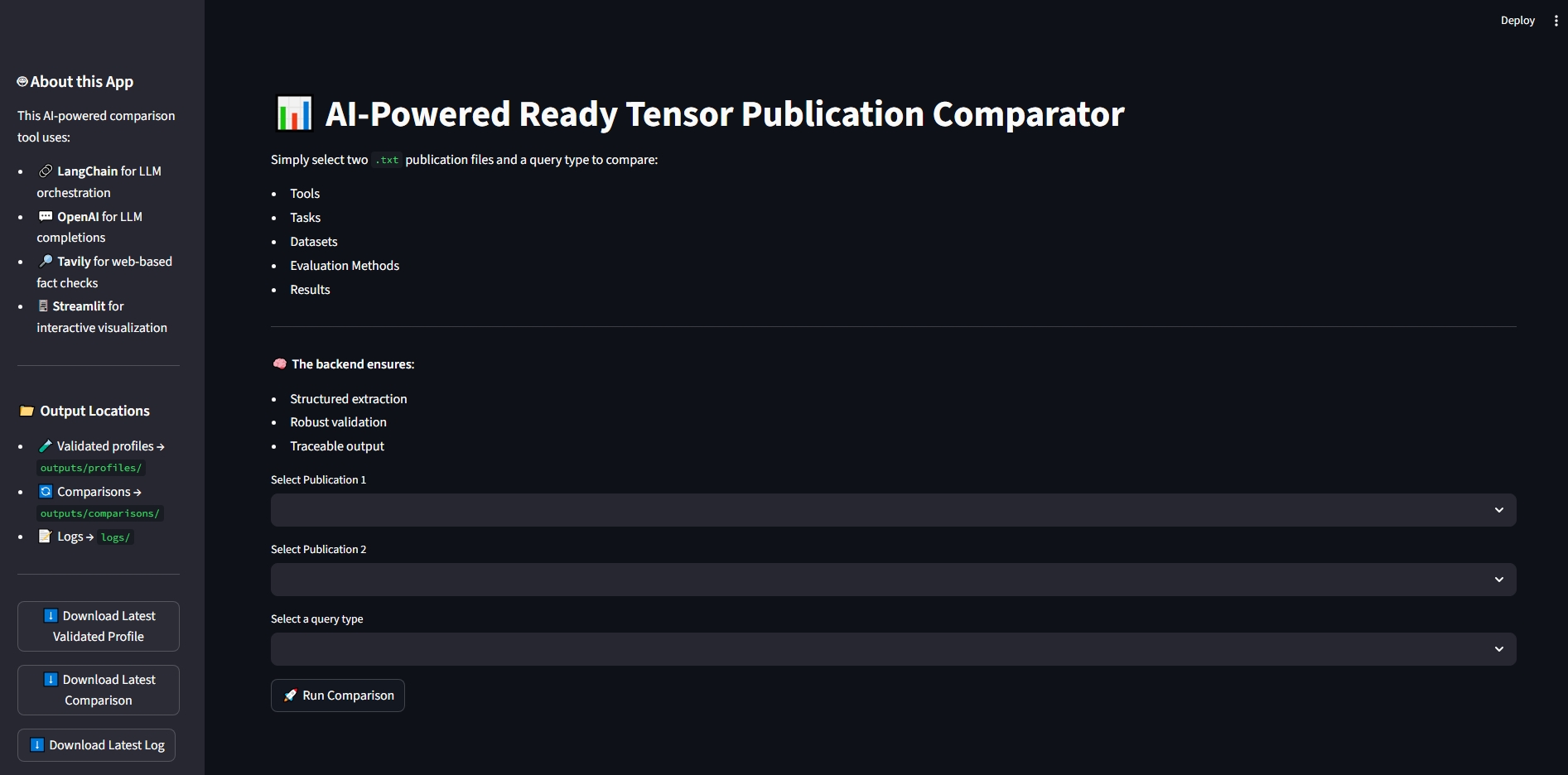
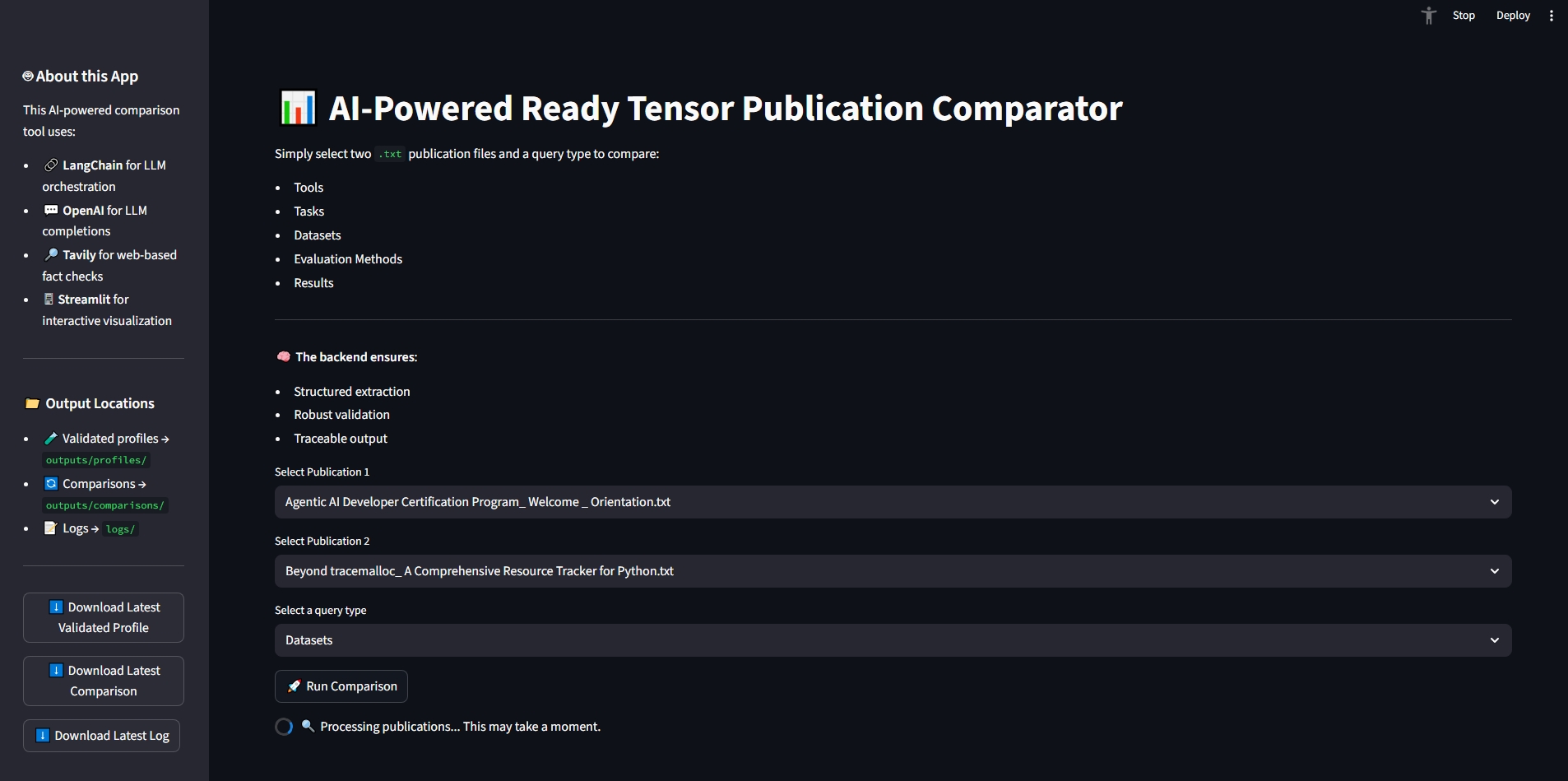
guardrails-ai..rail schema for publication profiling.PublicationExplorer.analyze_pub1(), PublicationExplorer.analyze_pub2() in src/explorer.py).Validated output includes:
tools: Frameworks/libraries extracted from publicationevaluation_methods: Metrics or strategies describeddatasets: Benchmarks usedtask_types: Types of tasks addressedresults: Key findingsThe Research Assistant includes a comprehensive test suite implemented with pytest. These tests confirm correctness, resilience, and robustness of the system under both normal and adversarial conditions.
Unit Tests
Individual components such as analyze_pub1, compare, and react_agent_tool are tested in isolation with mocked LLM responses, ensuring reproducibility.
Integration Tests
The Streamlit interface (app.py) is tested with AppTest to confirm the UI initializes correctly and responds without crashing.
Schema Validation Tests
Guardrails-AI .rail schemas are tested with both well-formed and malformed JSON to verify strict schema adherence.
Resilience Tests
Missing or malformed fields are automatically repaired using fallback mechanisms, guaranteeing that all required fields (tools, evaluation_methods, datasets, task_types, results) are always present.
Observability is essential for monitoring, tracing, and debugging during real-world deployment. Logging and monitoring use Python’s logging module and node tracing.
| Feature | Tool/Technique | Purpose |
|---|---|---|
| Structured Logs | Python’s logging + JSON formatting | Centralized log collection & readability |
| Tracing | uuid session ID + node info | Track LLM invocation paths & failures |
The implementation begins with the installation of the required logging tools, followed by the creation of a dedicated logger.py module. Within this setup, structured logging is introduced through the use of Loguru, which provides a cleaner and more flexible logging interface. To improve traceability, each session is assigned a unique UUID, allowing logs to be linked back to specific execution runs. Logging is configured to be centralized, capturing events both in the console for real-time feedback and in persistent log files for later analysis. Finally, logging is applied consistently across all major graph nodes, ensuring that system activity can be fully monitored and debugged when needed.
The application runs locally via Streamlit, or can be deployed to cloud platforms (Streamlit Cloud, Docker, Hugging Face Spaces).
| Feature | Before (Prototype) | After (Production) |
|---|---|---|
| Guardrails | ❌ None | ✅ .rail schema with fallback |
| Logging | ⚠️ Basic | ✅ Structured logs with timestamps |
| Output Separation | ❌ Mixed outputs | ✅ Separate folders: outputs/profiles/, outputs/comparison/ |
| Validation | ❌ Ad-hoc | ✅ Schema-driven, strict validation |
| Resilience | ❌ Fragile | ✅ Robust with fallbacks and logs |
| Deployment | ❌ Prototype | ✅ Docker & cloud ready |
| Interface | ⚠️ Exposed API key | ✅ Clean sidebar info, no key exposure |
| Documentation | ⚠️ Incomplete | ✅ README, deployment.md, code docstrings |
Note: "Before" refers to the workflow in the original publication.
/Agentic_AI_Developer_Certification_Project3-main
├── LICENSE
├── README.md # Project overview and instructions
├── deployment.md # Deployment guide for various environments
├── Dockerfile # Instructions for Docker image config
├── requirements-test.txt # Development and test dependencies
├── requirements.txt # Project dependencies
├── .gitignore # Ignored files and folders
├── .env.example # Example environment file for API keys
├── data/
│ ├── project_1_publications.json # Sample Ready Tensor dataset
│ ├── sample_publications/ # Input publication .txt files
├── docs/
│ ├── Untitled diagram _ Mermaid Chart-2025-07-09-115351.png
│ ├── langgraph_flowchart.mmd
│ ├── publication_flowchart.png
├── examples_screens/ # Streamlit interface screenshots
├── logs/ # Runtime log output
│ └── pipeline.log
├── outputs/ # Validated profiles and comparison results
│ ├── profiles/
│ └── comparisons/
├── src/ # Source code
│ ├── app.py # Main Streamlit App
│ ├── explorer.py # LLM-based publication comparison engine
│ ├── generate_flowchart_graphviz.py
│ ├── generate_flowchart_mermaid.py
│ ├── loader.py # Converts JSON into individual .txt files
│ ├── paths.py # Centralized path definitions
│ ├── utils.py # Helper functions
│ ├── logger.py # Centralized log configuration
│ ├── docs/
│ │ ├── langgraph_flowchart.mmd
│ │ ├── publication_flowchart.png
│ ├── rails/ # Guardrails XML schemas
│ │ ├── profile_extraction.rail
├── tests/
│ ├── conftest.py # Reusable fixtures for explorer and sample publications
│ ├── test_app.py # Checks app entrypoint doesn’t break imports
│ ├── test_explorer.py # Validates the core pipeline
│ ├── test_guardrails.py # Ensures Guardrails schema works
├── pytest_output.log
OPENAI_API_KEY and TAVILY_API_KEY environment variablesClone the repository
git clone https://github.com/micag2025/Agentic_AI_Developer_Certification_Project3 cd Agentic_AI_Developer_Certification_Project3
Install dependencies
pip install -r requirements.txt # For testing: pip install -r requirements-test.txt
Note: Test dependencies are separated from runtime dependencies.
Set up environment variables
.env.example to .env and add your OpenAI and Tavily API keys.(Recommended) Use a virtual environment
python3 -m venv .venv source .venv/bin/activate # Linux/macOS .\.venv\Scripts\activate # Windows
Ensure project_1_publications.json is present in data/.
The sample dataset is available in the "Datasets" section of the related publication.
Launch the Streamlit app:
streamlit run src/app.py
Open your browser to the local Streamlit URL (usually http://localhost:8501).
You can now interact with the LangGraph-Orchestrated Research Assistant for Ready Tensor!
Output Locations
outputs/profiles/*.jsonoutputs/comparisons/*.json and .htmllogs/*.logDownload the latest validated profile and log file directly from the Streamlit interface.
Debugging Guardrails Integration
Run the app and monitor the terminal for raw vs. validated outputs. The pipeline will:
analyze_pub1 and analyze_pub2Sample output in outputs/ when query_type="evaluation_method:
{ "tools": ["LangGraph", "Microsoft AutoGen"], "evaluation_methods": [], "datasets": [], "task_types": ["AI Agent", "Autonomous Agents", "Multi-Agent System"], "results": [] }
If evaluation_methods is empty, this means the publication lacks evaluation details or the model did not extract any. Guardrails validated the output using the .rail schema.
Logs are stored in the /logs directory, and the system records events with the detail and rigor expected of a production-grade application. Each log entry captures the function, line, module, process, and thread involved, along with precise timestamps. Informative tags such as 📊, 📈, 📝, 🔍, and 🤖 make it easier to quickly distinguish between different types of events. Both raw model responses and validated outputs are logged, ensuring that every stage of the workflow can be audited and traced when necessary.
Before deployment, the system requires that the outputs/profiles/, outputs/comparisons/, and logs/ directories exist and are writable. The Streamlit interface provides direct access to validated profiles and logs, which can be downloaded from the user interface for further analysis. For containerized setups, Docker is fully supported, allowing local volumes to be mapped as needed to maintain persistent outputs and logs across environments.
streamlit run src/app.py

We welcome enhancements and issue reports:
Please adhere to existing code style and update documentation as needed.
We encourage and welcome community contributions to help make this assistant even more robust and versatile. Here are several potential areas for future improvement, along with example contributions for each:
Expand the system to support multiple large language model backends (e.g., OpenAI, Anthropic Claude, Google Gemini), allowing users to select or compare across different models.
src/utils.py and updating explorer.py to enable backend selection.Enhance the user interface to provide more flexibility and usability.
Adapt and extend validation schemas to better handle domain-specific needs.
.rail schema for extracting information from specific types of publications, and update the validation logic in explorer.py to accommodate new domain-specific fields.Improve accuracy in extraction, summarization, and reasoning tasks by supporting fine-tuned or specialized LLMs.
Enhance reliability by investigating why the system sometimes fails to extract evaluation methods from publications.
MAX_CHARS = 12000), key evaluation sections may be omitted from analysis. Improving data preprocessing or LLM prompts could mitigate this issue.Licensed under the MIT License
For questions or feedback, please contact the authors:
This work is part of the Agentic AI Developer Certification program by
ReadyTensor Special thanks to the Ready Tensor developer community for guidance and feedback.
