This publication introduces Aether, a conversational AI assistant designed to provide users with a seamless and intuitive way to access and understand information from the "Ready Tensor" collection of publications. Aether leverages a Retrieval-Augmented Generation (RAG) architecture to deliver accurate and contextually relevant answers to a wide range of user queries. This document details the project's architecture, implementation, and practical applications, serving as a comprehensive guide for developers, researchers, and anyone interested in the intersection of conversational AI and information retrieval.
The primary purpose of this project is to develop and showcase a sophisticated, yet user-friendly, conversational AI assistant named Aether. The core objective is to provide a tool that can accurately and efficiently answer questions about the "Ready Tensor" publications, demonstrating the practical application of Retrieval-Augmented Generation (RAG) models in creating intelligent systems that can comprehend and converse about specialized knowledge domains. To achieve this, the project focuses on building a robust backend service using FastAPI and LangChain to orchestrate the RAG pipeline, complete with a re-ranking step to enhance search result relevance. This is complemented by an intuitive Next.js frontend, an efficient data ingestion process using a Chroma vector database, and an intent detection mechanism to provide tailored responses while maintaining conversation history for a natural, context-aware user experience.
This publication is designed for a broad technical audience, including developers and AI engineers interested in building conversational AI, researchers and data scientists exploring RAG models, and students or enthusiasts learning about large language models and vector databases. The primary use case for Aether is to serve as an intelligent search and summarization tool for the "Ready Tensor" publications. It allows users to ask questions in natural language and receive concise, accurate answers, eliminating the need to manually sift through lengthy documents.
Aether's architecture consists of a backend service and a frontend web application that work in tandem. The backend, built with FastAPI, exposes a RESTful API and uses LangChain to orchestrate the entire RAG pipeline, from data ingestion to response generation. The "Ready Tensor" publications are indexed into a Chroma vector database using Google's embedding-001 model, while the gemini-2.5-pro model generates the final natural language responses. The frontend is a responsive Next.js application that provides a clean, intuitive chat interface for users to interact with Aether, sending queries to the backend and displaying the assistant's responses.
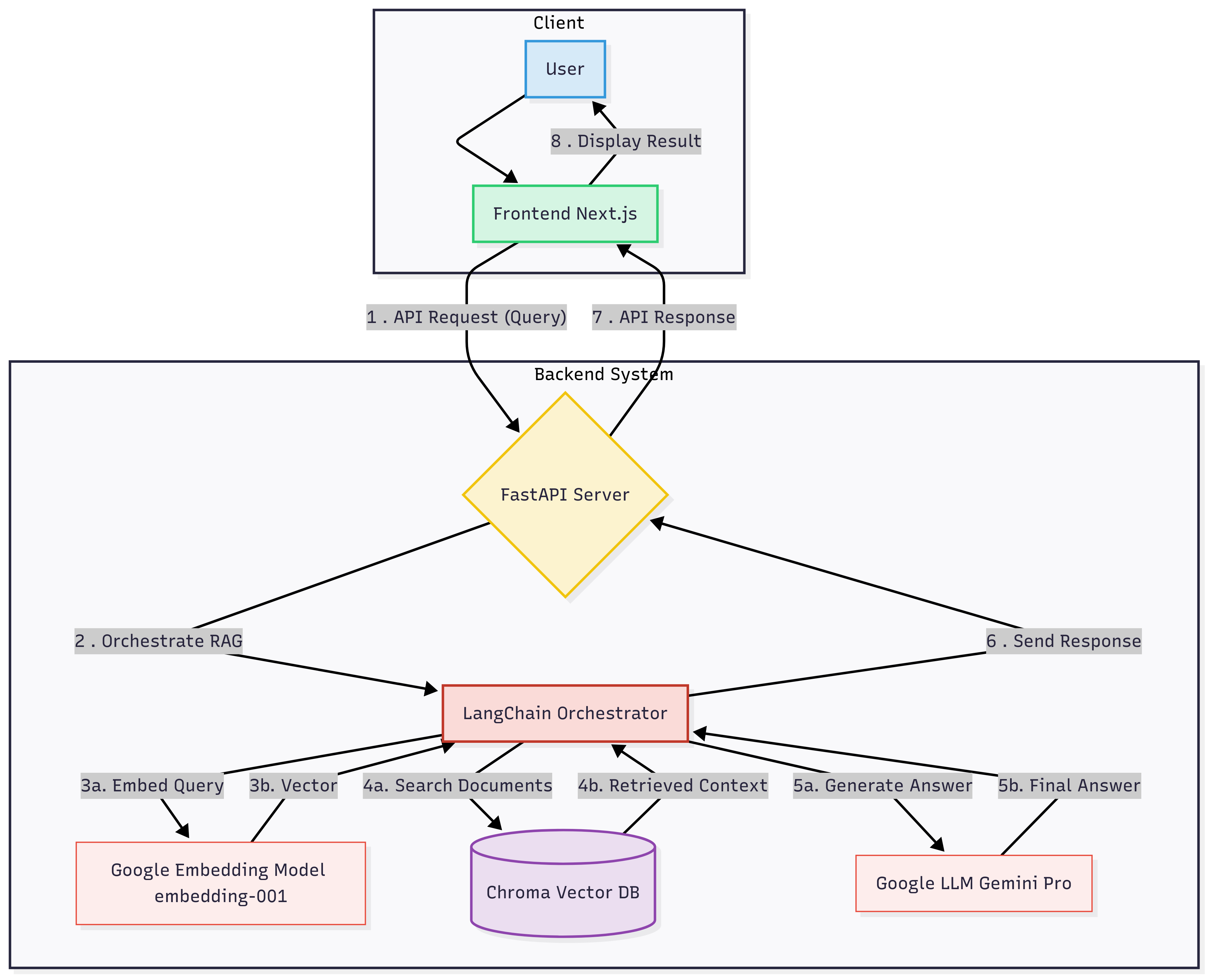
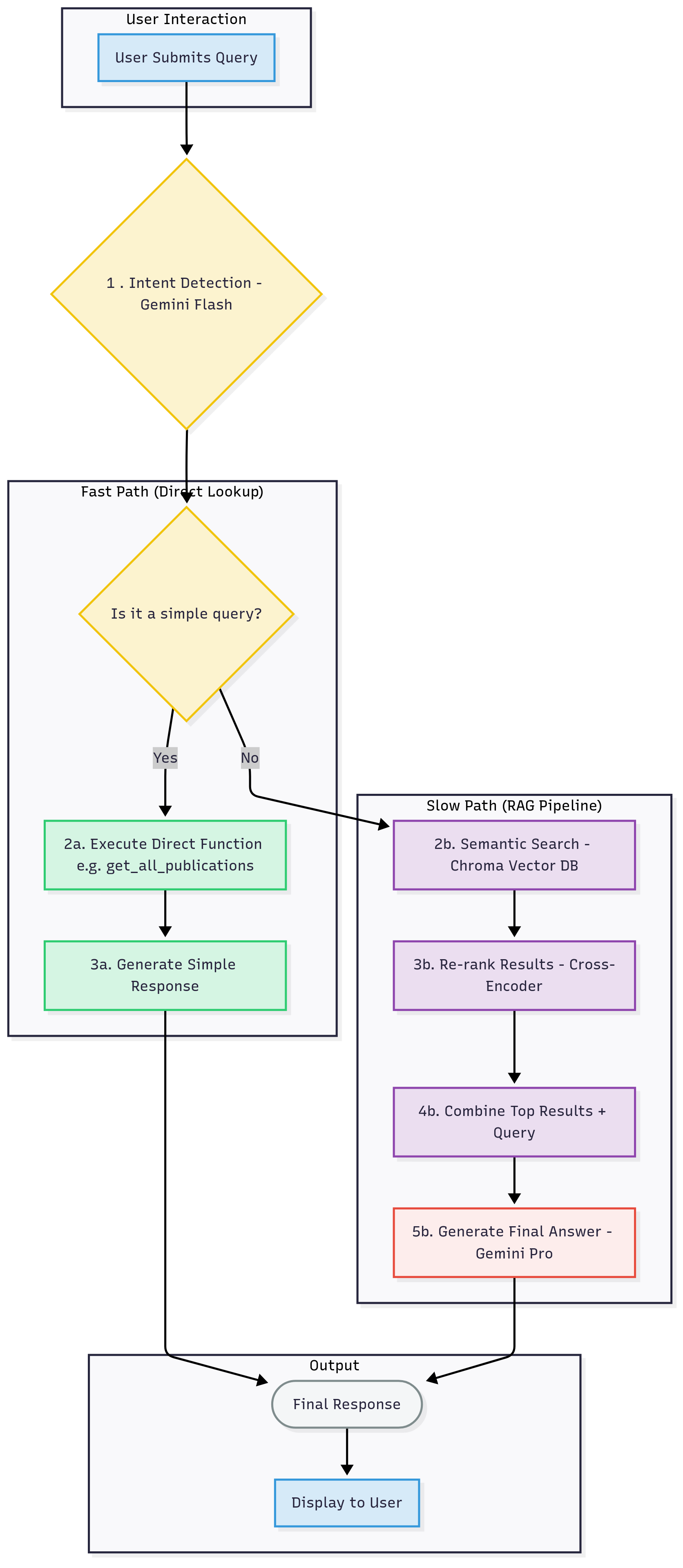
The core of Aether's functionality is its sophisticated RAG pipeline, which processes user queries to generate accurate, context-aware answers. When a user submits a query, it is first assessed by a lightweight gemini-1.5-flash model to determine the user's intent—for instance, whether they are asking a general question, requesting a list of publications, or seeking a summary of a specific document.
Based on this intent, the system follows one of two paths. For straightforward requests, such as "list all publications," Aether takes a "fast path," directly querying a JSON file of publication data to return a precise answer without engaging the more complex RAG components. For more nuanced or open-ended questions, the system initiates the "slow path." This begins with a semantic search in the Chroma vector database to retrieve text chunks whose meanings are closest to the user's query.
To ensure the highest relevance, these retrieved chunks undergo a re-ranking step using a Cross-Encoder model, which meticulously re-orders the results to prioritize the most contextually appropriate information. Finally, the top-ranked document chunks are combined with the original question and fed into the powerful gemini-2.5-pro model. This model synthesizes the information to generate a comprehensive, well-formatted, and friendly response. Throughout this process, Aether maintains a conversation history, allowing it to understand follow-up questions and provide a more natural, flowing conversational experience.
To run Aether on your local machine, you will need Python (3.8+), Node.js (14.0+), and their respective package managers (pip and npm) installed. The setup process for the backend and frontend is as follows:
# Backend Setup: # 1. Clone the project repository from GitHub. git clone <repository_url> # 2. Navigate to the foundoune directory. cd foundoune # 3. Install the required Python packages: pip install -r requirements.txt # 4. Set the DATA_PATH environment variable to the path of your project_1_publications.json file. export DATA_PATH=/path/to/your/project_1_publications.json # 5. Add the GEMINI and GOOGLE api keys to the project’s environment. export GEMINI_API_KEY="YOUR_GEMINI_API_KEY" export GOOGLE_API_KEY="YOUR_GOOGLE_API_KEY" # 6. Start the FastAPI server: uvicorn main:app --reload
# Frontend Setup: # 1. Navigate to the aether-frontend directory. cd aether-frontend # 2. Install the required npm packages: npm install # 3. Start the Next.js development server: npm run dev
Once both services are running, you can access the Aether chat interface by navigating to http://localhost:3000 in your web browser.
Live URL: https://aether.alkenacode.dev
To validate the effectiveness and reliability of the Aether assistant, a systematic evaluation of its core RAG capabilities was conducted. The assessment focused on three critical metrics that define the quality of any retrieval-augmented system:
The test suite for this evaluation included a diverse set of queries targeting specific topics within the knowledge base, such as the implementation of YOLO models, the nuances of software licenses, and best practices for open-source contributions.
The results of this evaluation were definitive. The system demonstrated exceptional performance, achieving a perfect 5/5 score across all three metrics for every test case. This outcome confirms that the system not only excels at retrieving the correct documents but also at synthesizing their content into answers that are both factually accurate and directly relevant to user queries.
The figure below provides a visual summary of this high performance, illustrating the consistent success of the RAG pipeline across the test suite.
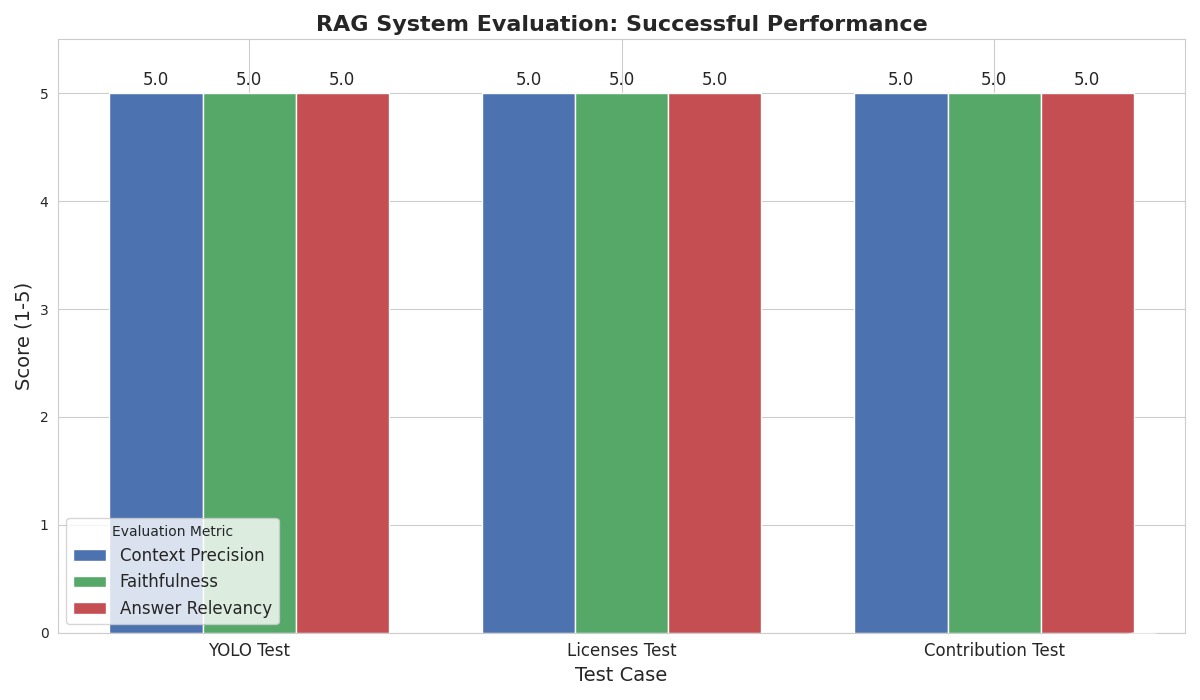
This rigorous validation confirms that Aether's RAG architecture provides a robust and trustworthy foundation for information retrieval and response generation.
With its performance validated, Aether excels at handling a wide variety of queries about the "Ready Tensor" publications. For example, a user can request a high-level overview by asking, "Can you summarize the main points of the 'Hands on Computer Vision' publication?" For more targeted information, a user might ask, "What are the key features of the MIT License?" The assistant also supports comparative analysis, answering questions like, "What are the key differences between the 'Transformers' and 'RNNs' publications?" These examples illustrate Aether's ability to function as a versatile and reliable information retrieval tool.
Built upon a successful and validated foundation, Aether is well-positioned for future enhancements. The most immediate step is to expand the knowledge base beyond the "Ready Tensor" publications to include a wider range of documents, thereby increasing its utility. Concurrently, the intent detection mechanism could be refined to handle a broader and more complex spectrum of user queries with greater precision. Finally, future development can focus on improving Aether's ability to handle complex questions that require multi-step reasoning and inference, moving it closer to a truly comprehensive research assistant.
The successful evaluation of Aether confirms its efficacy as a powerful and versatile conversational AI assistant. The results demonstrate that the system reliably grounds its responses in the provided knowledge base, effectively bridging the gap between information retrieval and natural language generation. By implementing a robust RAG architecture, Aether provides a seamless and intuitive way for users to access and understand specialized knowledge domains with a high degree of confidence in the accuracy of the information provided.
The project is open-source and available for exploration and contribution. Feedback and collaborative efforts from the community are welcome. The project can be accessed at https://github.com/Kiragu-Maina/aether-rag-assistant.