AeroIntel: AI RAG based ChatBot Assistant for Government Policymakers

Introduction
AeroIntel is a cutting-edge Retrieval-Augmented Generation (RAG)-based AI assistant chatbot powered by OpenAI & Pathway. Designed to support government policymakers and high officials, particularly from the Center of Atmospheric Sciences, AeroIntel provides data-driven insights on air quality, pollution control measures, and health impacts of air pollution in India. This AI-driven tool aids informed decision-making for effective environmental policy implementation.
AeroIntel in action :
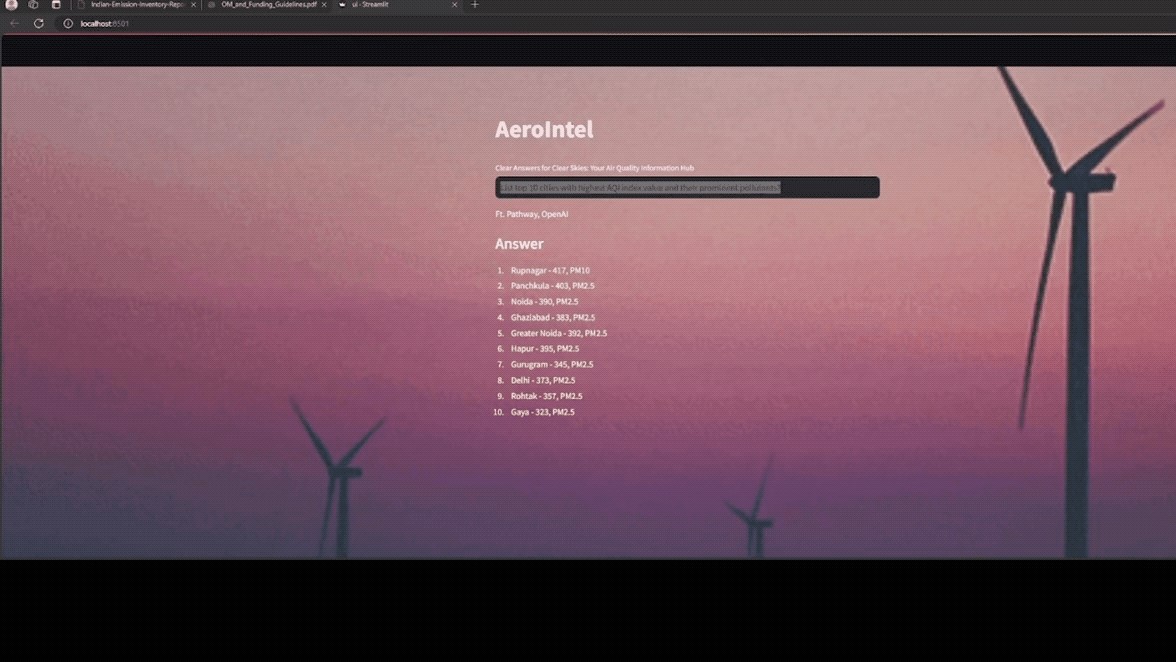
End Users:
Government Officials:
High-ranking officials responsible for maintaining air quality standards and addressing environmental challenges. AeroIntel provides critical insights for identifying pollution hotspots, implementing policy changes, and making informed decisions.
Environmental Agencies:
Departments and agencies monitoring air quality and executing pollution control measures. AeroIntel aids in tracking pollution levels, evaluating initiatives, and strategizing future actions.
Corporate Sector:
CSR departments of companies funding environmental projects. AeroIntel offers valuable data to guide investments and measure impact.
Environmental Consulting Firms:
Firms advising businesses on environmental regulations and carbon footprint reduction. AeroIntel provides up-to-date information and analytics to support their services.
Research Institutions/Academic Researchers:
Scholars and scientists researching air quality, environmental science, and public health. AeroIntel supports research with robust data and analytical tools.
Think Tanks:
Organizations dedicated to policy analysis and advocacy in the environmental sector. AeroIntel provides comprehensive data for policy recommendations and reports.
Non-Governmental:
Environmental advocacy groups using AeroIntel for reliable data to raise awareness, campaign for policy changes, and monitor environmental health.
Public Health Organizations:
NGOs focused on public health outcomes related to air quality. AeroIntel offers data on health impacts, aiding in the development of programs and policies to protect public health.
Impacted Industry:
Environment and Socio-Economic (Policy makers)
Business Usecase:
AeroIntel is designed to be an invaluable tool for officials involved in environmental policy and management. By providing accurate, timely information, it supports efforts to mitigate air pollution and protect public health.Below are the top features/usecases that can be executed by the end users using aerointel.
Air Quality Data:
Access real-time and historical air quality data for various regions in India.
Funding Information:
Obtain details on funds allocated to each state for pollution control.
Track the impact of these funds on air quality improvements.
Pollution Hotspots:
Identify states and cities with high pollution levels.
Health Impact Analysis:
Explore the health impacts of air pollution on different populations.
Access studies and reports on pollution-related health issues.
Interactive Chat Interface:
Engage with the AI chatbot for quick answers to specific queries.
Receive detailed reports and summaries on requested topics.
License: AeroIntel is released under the MIT License, promoting open collaboration and innovation.
Tech-Design
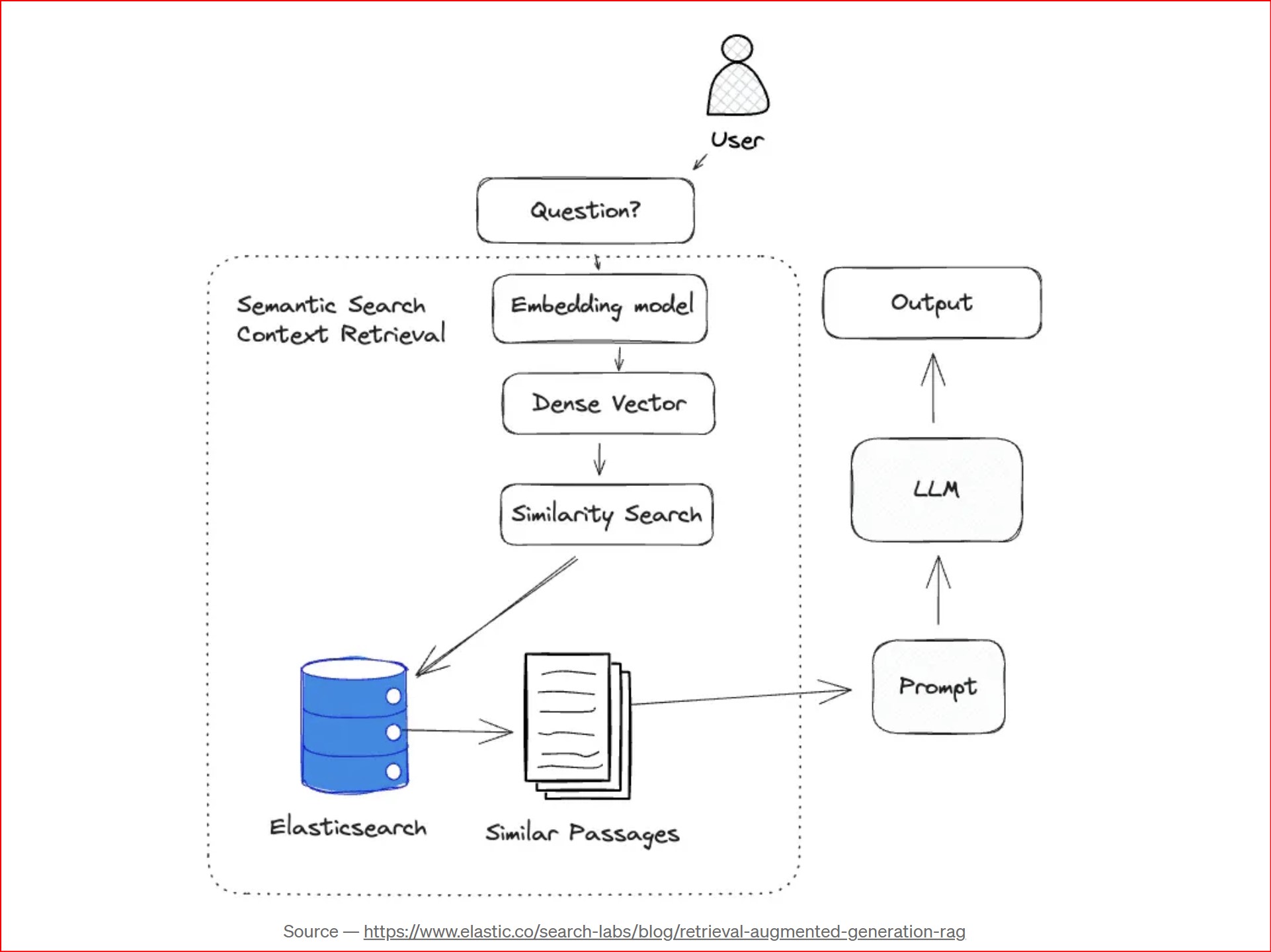
At its core, Retrieval-Augmented Generation (RAG) leverages the strengths of two powerful AI techniques: information retrieval and large language models (LLMs). Let’s delve into the process:
Query Understanding:
When a user interacts with your chatbot, RAG first employs natural language processing (NLP) techniques. This involves breaking down the user’s question into its constituent parts (tokens) and analyzing its semantic meaning and intent.
Retrieval from the Knowledge Base:
Armed with an understanding of the user’s query, RAG interacts with a specialized database like FAISS, Weaviate, or Pinecone. These databases don’t store text directly. Instead, they store meaning-based mathematical representations of information called vectors. RAG generates a similar vector for the user’s query and finds the most closely matching vectors in the database. These matching vectors lead RAG to the specific sections of text most likely to contain the answer.
Enhancing the LLM with Retrieved Knowledge:
Once RAG successfully retrieves the most pertinent information (text snippets, article summaries etc.), it feeds this data to a pre-trained LLM like GPT, Gemini etc. These LLMs are statistical models trained on massive amounts of text data, granting them the ability to process information and generate human-quality text.
Response Generation:
Empowered by the retrieved knowledge from the provided text, the LLM steps in to craft the response to the user’s query. This response can take various forms depending on the prompt provided. It could be a concise answer to the question, a comprehensive summary of the article, or even a creatively formatted text response.
Summary :
Traditionally, an LLM relies on its stored knowledge to answer questions. RAG enhances this process through three key steps: retrieval, augmentation, and generation. First, your question is converted into a “vector embedding”. RAG then performs retrieval, searching a database where content from your information source is also stored as vectors. It identifies the most relevant content, which is used for augmentation — combining it with your original question to create a richer input. Finally, the LLM uses this enhanced input for generation, producing a more accurate and helpful answer.
Technology stack Used
LLM Models :
OPENAI's GPT-3.5-turbo via PATHWAY LIB WRAPPER
ENCODER MODEL :
text-embedding-ada-002
Streaming Pipeline:
The incoming data from these sources is processed and after processing, the data is split into smaller chunks. This is necessary because it’s often more efficient to work with smaller pieces of text when performing NLP tasks. The changes in data are automatically synced to the pipeline enabling real-time Retrieval Augmented Generation (RAG) using llm-app . Embedding: These chunks are then embedded into a vector space using an OpenAI embedding model. Embedding converts text data into numerical vectors that capture the semantic meaning of the text.
KNN Vector Indexing:
The numerical vectors are indexed using a KNN (k-nearest neighbors) algorithm. In used to quickly retrieve the most relevant text chunks in response to a query based on vector similarity. The AURA is reactive to changes to the corpus of documents: once new snippets are provided, it reindexes them and starts to use the new knowledge to answer subsequent queries. This technique is significantly faster and more efficient than conducting individual comparisons between the query and every document.
User Query Processing:
When a user submits a query, a Spacy module is used to extract relevant keywords from the question. Spacy is an open-source software library for advanced NLP. Concurrently, the user's question is also embedded using the same OpenAI embedding model to ensure that the question and the data chunks are in the same vector space.
Integration of User Query and Knowledge Base:
The embedded user query is then used to perform a KNN search in the vector index to find the most relevant chunks of embedded data from the processed sources. This combination of user query embeddings and indexed data allows the system to understand and retrieve information that is contextually relevant to the user's question.
Response Generation:
The LLM (Large Language Model), uses the retrieved information to generate an appropriate response. The response generation is likely informed by a prompt template, which structures how the model should incorporate the information into a coherent reply.
Pre-Requisites
For window users, you will need to download & install Windows Subsystem for Linux first.You can refer the [Tutorial Video] for more information regarding the installation.(https://www.youtube.com/watch?v=eId6K8d0v6o)
Windows Subsystem for Linux (WSL): WSL is a compatibility layer for running Linux binary executables natively on Windows. WSL 2, the latest version, uses a real Linux kernel and offers improved performance and full system call compatibility.
Advantages of WSL:
Integration: Allows running Linux applications and tools alongside Windows applications.
Performance: WSL 2 offers significant performance improvements over WSL 1 by using a real Linux kernel.
Ease of Use: Provides a seamless development environment for developers who work on both Windows and Linux.
For MAC/Linux/Debian users no specific requirements needed.
Since you are inside new Linux Environment, you might need to install many python libraries like pip,python3 etc.You will know once you run the aeroIntelRun.py file.
Also, we are using the OpenAI LLM model and encder model ,please be handy with the APIKey.
Docker and WSL on Windows
Docker: Docker is a platform that enables developers to build, ship, and run applications in containers. Containers are lightweight, standalone, and executable packages that include everything needed to run a piece of software, including the code, runtime, libraries, and system dependencies.
Advantages of Docker:
Consistency:
Ensures that applications run the same way regardless of where they are deployed.
Isolation:
Each container runs in its own isolated environment, preventing conflicts between dependencies.
Portability:
Containers can run on any system that supports Docker, including different operating systems and cloud platforms.
Efficiency:
Containers are more lightweight compared to virtual machines, sharing the host OS kernel and using fewer resources.
Using Docker with WSL:
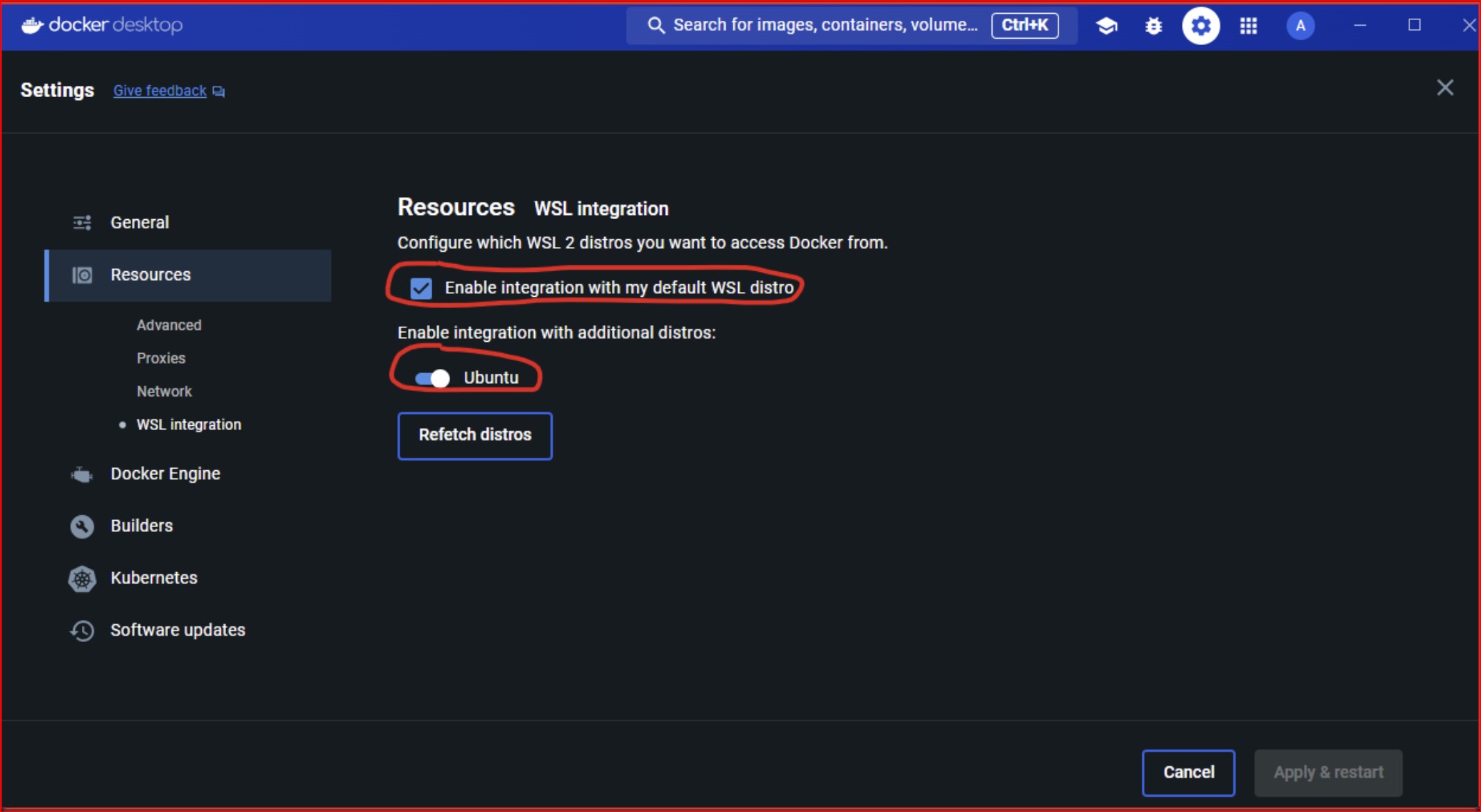
Combining Docker with WSL 2 provides a powerful and efficient development environment on Windows. Docker Desktop for Windows integrates with WSL 2 to provide a native-like Linux development experience.
Install Docker Desktop:
Download and install Docker Desktop for Windows from the Docker website.
During installation, enable the option to use the WSL 2-based engine.
Integrate Docker with WSL:
Install DropBox:
Since we are using drop box as our context repository,we require drop box and the access token to call drop box api in order to download the context building materials.
Go to DropBox oauth-guide site to get your Dropbox access token
Installation
Clone this repoAeroIntel Github
Navigate to home directory ->
# cd AeroIntel
Fetch the data from the dropbox
Export Dropbox content to a 'local folder' inside the 'AeroIntel\Dropbox' folder. This can be done by running 'dropbox_script.py'. Remember , Windows users needs to run this step outside the Linux/WSL-2 environment, i.e in the windows shell As, we need a common root for Dropbox ( C:\Users\Sumit Chand\Dropbox) and our project folder, which is present inside the linux/WSL-2 environment ( \wsl.localhost\Ubuntu\home\Sumit\AeroIntel)
Update Access Token in dropbox_script.py generated from dropbox developer section in above step:
# Define your access token ACCESS_TOKEN = 'Dropbox access token'
Update your local_path where your application will access files for context building and your dropbox path where the files will be kept originally.This will be done inside dropbox_script.py.
# Specify the Dropbox path and local folder path dropbox_path = 'C:\Users\Sumit Chand\Dropbox' local_path = '\\wsl.localhost\Ubuntu\home\sumit\AeroIntel\Dropbox'
We'll copy the dropbox content to this local Dropbox folder, inside our project folder.Run the dropbox_script.py
Modiy the .env file in the root directory of the project.
Replace the "OPENAI_API_TOKEN" value, place your OpenAI API key inside a quotation.Replace the dropbox address, use relative address of your dropbox.
OPENAI_API_TOKEN= "Your_OPENAI_API_KEY" HOST=0.0.0.0 PORT=8080 EMBEDDER_LOCATOR=text-embedding-ada-002 EMBEDDING_DIMENSION=1536 MODEL_LOCATOR=gpt-3.5-turbo MAX_TOKENS=200 TEMPERATURE=0.0 DROPBOX_LOCAL_FOLDER_PATH="./Dropbox"
All the important ministry documents will be placed in a common shared dropbox path which can act as a common repository for all the context training material fed to the encoder models to generated embeddings. This could be made more robust in terms of the security but as for now in this project we see this dropbox directory as a golden source.
Install the app dependencies Install the required packages:
pip install --upgrade -r requirements.txt
Build up the Docker containers
docker-compose build #one time task; will take time ( ~ 45 mins using iitk-sec(Highspeed-5GHz) ) docker-compose up
Once your container has been generated you would able to see in the docker app. You can run the app directly from there.
Run the Pathway API : python3 main.py
Run the Ui via ui.py streamlit run ui.py