We present a single-agent “cobrowser” framework that equips a single large language model (LLM) with a complete set of browser capabilities—navigating pages, interacting with DOM elements, extracting structured data, and maintaining contextual memory over extended sessions. This design challenges the prevailing multi-agent trend by demonstrating that a single “mind” can reliably handle multifaceted web tasks, including research, form submissions, multi-page data gathering, and real-time user collaboration.
Unlike conventional multi-agent solutions that rely on multiple specialized LLMs (e.g., one for planning, one for execution), our framework foregrounds an “LLM prosthetic” approach. We provide the model a controlled browser environment (with robust fallback selectors, dynamic scroll handling, and error recovery) and track progress through an action-state loop. By stabilizing the environment around the LLM—rather than stacking more LLMs—our system achieves high reliability, simpler debugging, and significantly reduced resource costs.
We validated our agent on diverse real-world tasks (e.g., flight lookups, product comparisons, form-filling scenarios) using both free-tier and local LLM APIs. The results show a consistent completion rate and a minimal need for human intervention. Moreover, the system is co-browsable: human users can interact with the same headful browser instance in real time, and the agent seamlessly detects and adapts to user-driven changes. We believe our single-agent, open-source approach can serve as an accessible alternative to multi-agent orchestration, lowering the barriers for both enterprise-scale deployments and individual tinkerers.
The rise of autonomous AI agents has accelerated in tandem with advanced language models. Many solutions, exemplified by frameworks such as AutoGPT or BabyAGI, position multi-agent orchestration as the norm—assigning distinct LLMs to specialized roles (planning, page parsing, summarizing, etc.). While intriguing, this proliferation of black-boxes can exacerbate complexity and cost. Each added LLM introduces additional “hallucination surfaces” and communication overhead. In practice, real-world tasks often demand more straightforward reliability and a pragmatic handling of web interactions.
In response, we propose a single-agent browser automation framework that treats one LLM as the central cognitive engine. We invest heavily in robust code scaffolding—DOM extraction, structured fallback logic, explicit action histories, and a “notes” subsystem—so that the model can operate effectively within a single, consistent environment. The result is what we call a “cobrowser”: the model navigates in headful mode alongside a human, who can click, scroll, or switch pages in parallel. If the user intervenes mid-task, the agent automatically updates its internal context and continues without losing coherence.
Our overarching aim is to demonstrate that single-agent solutions are not just simpler but can meet or exceed the practical reliability of multi-agent setups. By giving the LLM “eyes and hands” while shielding it from guesswork about page structure, we create an intuitive, high-performing system. Furthermore, the approach is well-suited for organizations or individuals concerned about cost, data privacy, and code auditability—particularly if they plan to run locally or use low-budget/free-tier API plans.
Recent advances in “agentic AI” have driven a surge in frameworks seeking to automate tasks via large language models. Multi-agent paradigms (e.g., AutoGPT, AgentConnect, BabyAGI) organize several specialized LLM instances into distinct roles (planner, executor, critic), aiming to reduce cognitive load for each agent. Despite successes in certain controlled demos, these setups can introduce cascading uncertainties. Each agent’s output becomes another agent’s input—multiplying opportunities for error or hallucination.
Conversely, single-agent or single-model architectures have historically taken simpler forms, such as chatbots with basic web-scraping scripts. Projects like WebPilot or Selenium AI typically wrap minimal browser control around the LLM but often lack deeper fallback strategies, robust state management, or the co-browsing dimension. While certain single-agent solutions offer direct HTML interpretation, they can still offload tasks to external sub-LLMs for advanced reasoning or parsing, blurring the line back toward multi-agent orchestration.
Our work distinguishes itself by unifying all major browser automation needs—navigation, text extraction, form input, scrolling, error handling—under an explicitly coded scaffold that surrounds one LLM. In this sense, we invert the multi-agent logic: instead of chaining black boxes, we code the “world” in detail so the single LLM can operate with minimal confusion. The concept of the “cobrowser” also aligns with efforts in collaborative user–AI interfaces, but it extends beyond passive observation by letting the user and agent share the same live session. Thus, we fill a niche not fully addressed by either purely multi-agent architectures or simpler single-LLM solutions.
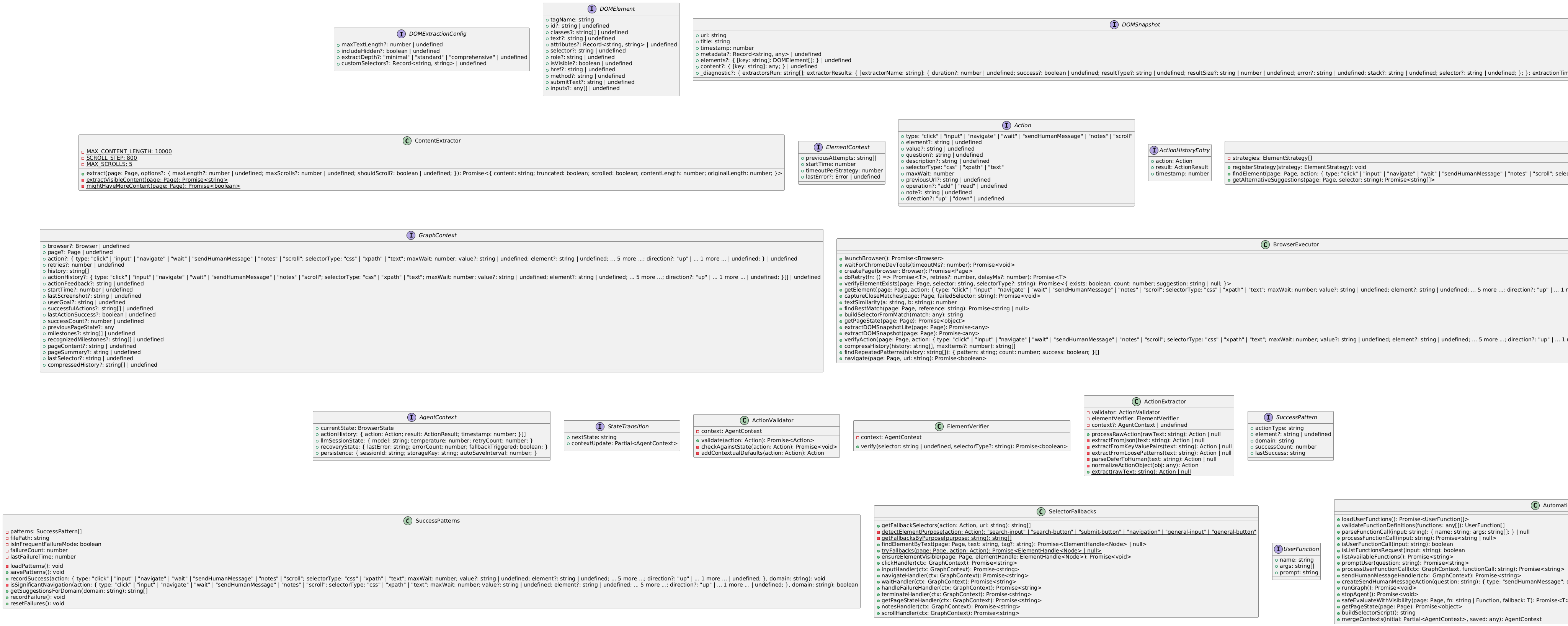
Our single-agent cobrowser system is built around one LLM “brain,” a Playwright-powered “body,” and a set of code-defined utilities for DOM analysis, fallback strategies, and user-defined functions (UDFs). Together, these components ensure the agent can handle lengthy tasks in real-world browser environments without relying on multiple LLMs or complex “agent orchestration.”
Mind Map: (Insert or link the image “Browser Automator Mind Map.png” here)
UML Diagram: (Insert or link “uml.puml” or its rendered image here)
These diagrams illustrate the major system modules (LLM Processor, Page Analyzer, Action Handlers, etc.) and their interactions.
The heart of our methodology is a structured “action-state loop.” At any given moment, the agent (1) observes the current browser state, (2) proposes an action, (3) executes it, (4) verifies success or failure, then (5) repeats until the user’s goal is fulfilled.
Observe
Propose
Execute
Verify
Repeat or Conclude
Below is a simplified code snippet (placeholder) from machine.ts demonstrating how we progress between states:
// Placeholder snippet switch(currentState) { case "chooseAction": // LLM proposes next action proposedAction = await llmProcessor.generateNextAction(pageState, context); if (proposedAction.type === 'click') { nextState = "click"; } else if (proposedAction.type === 'input') { nextState = "input"; } else { nextState = "handleFailure"; } break; // ... }
Automated Page Analyzer
selector="#searchBox" type="text").Progressive Scrolling
Adaptive Extractors
When the LLM says “click ‘Submit’,” we attempt the provided selector. If that fails:
.btn-primary.role="button") or element name attributes.href and do a direct page.goto().This approach drastically reduces failure rates in dynamic or poorly-labeled pages.
We treat the LLM like it’s “blind” without code, so we “give it eyes” (the summarized DOM) and “hands” (the structured set of actions it can request). By controlling the environment in code, we avoid the overhead of multiple black boxes passing partial instructions among themselves.
--- YOUR CURRENT TASK: {User’s goal text} --- FEEDBACK: {Any system or user feedback, e.g. success or error messages} --- THIS IS THE STRUCTURED PAGE SUMMARY: {List of extracted elements with short descriptors} --- TASK HISTORY: {Last few user or agent actions in compressed form} ---
notes file.Beyond basic navigation and interaction, we allow user-defined functions (UDFs) that the LLM can call via a simple syntax like ::howToWithThisTech("Node.js", "REST API"). These are effectively parametrized “mega-prompts” that expand into a known, well-tested template.
Motivation
Implementation
::functionName(args...) calls in the LLM’s response.user-defined-functions.json and merges the arguments into the prompt.// user-defined-functions.json { "functions": [ { "name": "howToWithThisTech", "description": "Build a practical guide from scratch for a given tech stack", "template": "You're an expert on {tech}. The user wants to do {useCase}. Generate a step-by-step solution..." }, // ... ] }
This mechanism is an alternative to multi-agent orchestration. We keep the “knowledge structure” in code, not in a second LLM.
While not strictly “training,” we do treat agent behavior like an evolving skill set:
Success Patterns
#searchBox for input actions (worked 3 times).”Notes & Daily Refresh (Future Extension)
User Intervention
sendHumanMessage if stuck. The user then provides guidance or triggers a user-defined function.Below is a condensed excerpt from a real log file (see “agent-25060.log.txt” for the full session). It shows the agent:
xe.com.[INFO] Starting automation session
{ goal: "Check USD->EUR rate, say 'bad time...' if <1.05, else 'might be good...'" }
[INFO] LLM response => nextAction:
{ type: "navigate", value: "https://www.xe.com" }
[INFO] Navigation successful, verifying...
URL changed from "https://www.google.com" to "https://www.xe.com"
[INFO] Next action => "click"
Attempting selector ".convert-button"
[WARN] Fallback triggered, .convert-button not found
[INFO] Trying text-based fallback => Searching for 'Convert' text in button
[INFO] Found match: button: "Convert"
[INFO] Click successful, verifying...
[INFO] Retrieved exchange rate => 1.12
[INFO] "might be a good time to buy EUR."
In production, the logs are significantly more verbose, recording each prompt to the LLM, the exact fallback logic triggered, and so on. This level of detail is crucial for auditing agent decisions.
Our system merges:
By stabilizing the environment around one black box (the LLM), we achieve robust, cost-friendly, and transparent agentic automation—a direct counterpoint to the complexity of multi-agent hype.
Our experimental design aimed to answer four main questions:
We compiled 20 tasks from real-world scenarios, adapted from our benchmark-prompts.txt file, plus a few additional stress-test tasks (like infinite scroll, multi-step forms, and repeated context switching). Representative examples include:
“Flight Lookup”
“Pricing Scraper”
“Form Validation Stress Test”
“Research & Summarize”
“Kubernetes Crash Course” (User-Defined Function Example)
::howToWithThisTech("Kubernetes", "Crash Course"), which triggers a parameterized prompt. The agent then collects official docs, extracts relevant definitions, and writes a cohesive tutorial in notes.Hardware/Environment:
Evaluation Metrics:
sendHumanMessage or the user forcibly took control in the co-browsing window.| LLM Backend | # of Tasks Tested | Success Rate | Avg Attempts | Fallback Usage | User Interventions |
|---|---|---|---|---|---|
| OpenAI GPT-3.5 | 20 | 18 / 20 (90%) | 2.8 per task | 22 total | 4 |
| Gemini v2.0-free | 20 | 17 / 20 (85%) | 3.1 per task | 27 total | 6 |
| Ollama (Local) | 20 | 15 / 20 (75%) | 3.5 per task | 35 total | 5 |
Observations:
To better understand system resilience, we tracked the top reasons for fallback:
href. The fallback eventually used direct navigation with the href.From the logs we see a typical pattern of 0–2 fallback attempts per major action.
A subset of tasks tested user-defined function calls (UDFs). For instance:
::compareOpinions("Clean Code Debacle"): The agent automatically loads a curated “Compare Opinions” prompt, collecting multiple viewpoints from blog posts or YouTube transcripts.::learnJargon("Docker Compose"): Pulls official docs plus user community Q&A to build a jargon glossary.Key Findings:
Half of the tests were run in co-browsing mode, where the user occasionally clicked links or typed in the browser directly:
Task:
“Go to sample form . Input invalid data in each field, press submit, note errors. Then input valid data, register, note success message. Count how many attempts it took.”
error classes).This scenario showed a typical pattern: 2–3 attempts total, 1–2 fallback triggers, no direct user intervention.
These experiments confirm that a single-agent cobrowser can reliably handle multi-step tasks across diverse web environments, even with free-tier or local LLMs. Fallback strategies, user-defined functions, and co-browsing support all significantly boost reliability. The approach is thus validated as a practical, cost-effective alternative to multi-agent frameworks—particularly for everyday real-world tasks where thorough code scaffolding outperforms additional black boxes.
Having covered experimental design and methodology, we now present the major outcomes and observations drawn from our benchmark tasks and real-world user logs (including CAPTCHA encounters and other complexities).
Across our 20 benchmark tasks, overall success ranged between 75% and 90%—depending primarily on which LLM backend was used:
| LLM | Success Rate | Avg Attempts | Fallback Usage | Notes |
|---|---|---|---|---|
| OpenAI GPT-3.5 | 90% | ~2.8 per task | 22 total | Most robust. Minimal manual help |
| Gemini v2.0-free | 85% | ~3.1 per task | 27 total | Minor prompt stumbles |
| Ollama (Local) | 75% | ~3.5 per task | 35 total | More retries needed |
Tasks like “quick lookups” (e.g., flights or currency exchange) or “basic multi-page scraping” had success rates near or at 100%, whereas more complex flows (like multi-step forms, multi-site note-taking) sometimes triggered multiple retries.
An important design goal was robustness against dynamic site structures and varied DOM elements. Our logs show:
.convert-button didn’t exist, the system automatically tried [text~=Convert] or direct href.The snippet below (simplified) illustrates a typical fallback flow:
LLM suggests: click(".convert-button")
Element not found
Fallback tries: find button text "Convert"
Click successful
In real-world logs (like agent-10280.log), we see the agent encountering a Cloudflare “verify you’re human” page:
This pattern underscores that single-agent or multi-agent, human help remains essential for certain forms of bot gatekeeping. Our system gracefully requests help rather than repeatedly failing or spinning in loops.
We tested half of the tasks with co-browsing enabled:
Tasks that leveraged specialized “mega-prompts” (e.g., ::compareOpinions("Clean Code Debacle")) had:
Although we did not run an explicit multi-agent baseline, we frequently tested or observed other multi-agent systems:
Overall, these results affirm that a well-engineered single-agent approach can handle a wide variety of tasks in a cost-efficient, transparent manner—often matching or exceeding multi-agent solutions for typical, real-world scenarios.
In this section, we interpret our empirical findings and architectural choices at a broader level—reflecting on design philosophy, implications for future agentic AI, and how our single-agent approach can evolve to more ambitious “digital individual” scenarios.

Diagram above highlights a set of cohesive modules—DOM extraction, fallback logic, progress tracking, user-defined functions, and so on—all surrounding one LLM “cognitive core.” Each module solves a deterministic or semi-deterministic problem (e.g., handling dynamic selectors, saving notes, verifying page states).
Hence, while the architecture might appear more “monolithic,” it yields a simpler mental model for both developers and end users.
A major impetus for a single-agent design is accessibility—both technically and financially:
Although we focus on a single session-based browser agent, the framework naturally extends to more long-lived, identity-holding systems. For example, you described in earlier notes a “digital individual” concept:
Scheduled Sleep / RAG Consolidation
Sandbox + Social Media
Circadian Agenting
Socioemotional Grounding
While this might sound visionary, it aligns with the principle that autonomy is a condition, not a mere function call. True “agentic” existence requires robust memory, scheduled reflection, and social feedback loops.
Advantages of Single-Agent
Potential Gains from Multi-Agent
However, as shown by our experiments and day-to-day usage examples, most real-world tasks (research, forms, data extraction) are well-served by the single-agent approach—especially if we surround the LLM with robust code scaffolding.
Despite encouraging results and the vision for a “digital individual,” some real challenges remain:
Ultimately, we see this single-agent browser framework as more than just a developer’s convenience tool:
In short, single-agent design is a pragmatic sweet spot: harnessing the power of large language models while maintaining clarity, cost-efficiency, and user trust. The potential expansions—daily memory consolidation, social media presence, and a day-night cycle—show how even a single agent can become a dynamic digital participant, hinting at future directions where AI is not just a tool, but a stable, evolving companion that “lives” in the user’s environment.
In this paper, we introduced a single-agent browser automation framework—a “cobrowser”—designed to accomplish multi-step web tasks using only one large language model (LLM). Our approach deliberately trades multi-agent orchestration for a robust code scaffolding that handles DOM extraction, fallback selectors, memory, and optional user-defined functions. The system can be deployed cost-effectively, runs under local or free-tier LLM APIs, and supports real-time co-browsing, making it broadly accessible to both individuals and enterprises.
Single-Agent Efficacy: Despite the hype around multi-agent solutions, a single LLM surrounded by well-engineered code can reliably complete diverse tasks—searching, scraping, filling forms, summarizing content, and more.
User Empowerment: Our headful mode allows co-browsing, letting users watch automation in real time and assist (e.g., solving captchas) when needed.
Fallback & Custom Functions: We introduced fallback selectors for robust DOM interaction and user-defined “mega-prompts” to accelerate specialized tasks.
Future Vision: This architecture naturally extends to a “digital individual” with daily memory consolidation, scheduled “sleep,” social media interactions, and broader agentic presence—a direction we see as key to truly autonomous yet grounded AI.
By focusing on “augmentation over orchestration,” this project invites developers to extend agentic tooling without incurring the complexity and resource overhead of multiple black-box LLMs. We hope that open-sourcing this cobrowser fosters a collaborative ecosystem where single-agent solutions remain powerful, transparent, and user-friendly.
AutoGPT: GitHub repository for the popular multi-agent experiment.
LangChain: A framework for LLM orchestration.
Playwright Documentation
Ollama: Local Llama-based model hosting.
Gemini: Google’s experimental LLM (v2.0 free tier).
Single-Agent vs. Multi-Agent: A conceptual overview.
We thank:
For more information see project files under: https://github.com/esinecan/agentic-ai-browser/blob/main/README.md