Category: Applied Solution ShowCase
The Ready Tensor platform has rapidly emerged as a hub for AI and machine learning publications, drawing contributions from researchers, practitioners, and students worldwide. While this growth reflects the vibrancy of the community, it also introduces a pressing challenge: how can users efficiently discover, navigate, and synthesize insights across an ever-expanding body of knowledge?
Traditional keyword-based search methods often fail to meet this need. They typically operate on surface-level matches and cannot capture the semantic meaning of research content. As a result, publications that address similar problems or propose related methodologies may remain disconnected simply because they use different terminologies. For example, one paper may describe “document chunking” while another discusses “context segmentation,” leaving a researcher unable to easily connect the two without prior domain expertise.
This gap hinders not only research efficiency but also knowledge transfer, making it harder for students to learn effectively and for professionals to apply existing solutions in new contexts.
To address these limitations, our team developed a Retrieval-Augmented Generation (RAG) Assistant, designed specifically for the Ready Tensor ecosystem. By combining semantic retrieval with large language model (LLM)-powered reasoning, this assistant transforms the platform’s publication repository into a conversational knowledge base. Instead of sifting through countless papers, users can now engage in natural, dialogue-driven exploration, receiving fact-grounded answers synthesized directly from published content.
This approach offers a more intuitive, accurate, and scalable solution for interacting with AI/ML research, helping bridge the gap between raw information and actionable understanding.
To implement this assistant, we combined modern AI/ML building blocks into a streamlined pipeline:
1)Framework Orchestration: LangChain
2)Embeddings: HuggingFace all-MiniLM-L6-v2
3)Vector Database: ChromaDB for fast, local semantic search
4)LLM Backbone: Groq API running Llama 3 8B for speed and reasoning
5)User Interface: Streamlit for a conversational web-based interface
6)Environment Management: python-dotenv
This stack allowed us to build a solution that is lightweight, efficient, and privacy-preserving, while still being powerful enough to handle complex queries.
The RAG Assistant is built as a modular pipeline, where each component performs a distinct function but integrates seamlessly with the others. This modularity makes the system scalable, maintainable, and extensible, ensuring that future improvements (e.g., swapping models or databases) can be incorporated with minimal rework.
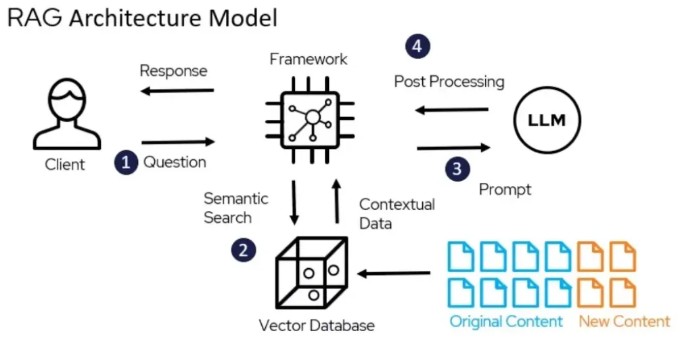
Architectural Flow
Data Loading
Publications are ingested from the Ready Tensor dataset (project_1_publications.json). Metadata such as titles and descriptions are extracted to create a structured foundation for downstream processing. This ensures that the assistant begins with a clean, standardized representation of source content.
Chunking
Using LangChain’s RecursiveCharacterTextSplitter, documents are divided into overlapping segments (chunk size = 1000 characters, overlap = 200). This technique prevents loss of semantic meaning at text boundaries, ensuring that concepts split across sections remain accessible to the retrieval process.
Embeddings
Each chunk is converted into a high-dimensional vector embedding using HuggingFace’s all-MiniLM-L6-v2. These embeddings act as semantic “fingerprints,” capturing the contextual meaning of text and enabling the system to compare concepts rather than just words.
Vector Database (ChromaDB)
All embeddings are stored in ChromaDB, which provides efficient similarity search. By using a local vector store, the system ensures fast retrieval times, user privacy, and independence from heavy external infrastructure.
Retrieval
When a user submits a query, it is first embedded into the same vector space. The system then retrieves the top-3 most relevant text chunks from ChromaDB. These chunks form the factual grounding context for the next step.
Generation (LLM)
The Groq-hosted Llama 3 8B model processes both the user’s query and the retrieved context. Guided by a carefully designed prompt, the model synthesizes an answer strictly based on the retrieved documents, ensuring accuracy and alignment with published sources.
User Interface
Finally, the response is delivered through a Streamlit-based chat interface. This UI provides an intuitive, real-time conversational experience, lowering the barrier for non-technical users while maintaining flexibility for developers to extend functionality.
Architecture Diagram :
Data → Chunking → Embeddings → Vector DB → Retrieval → LLM → UI
The implementation of the RAG Assistant followed a step-by-step, modular approach, ensuring that each stage of the pipeline was well-documented and reproducible. Below we describe the core components in detail, along with representative code snippets and design considerations.
Dataset: The foundation of the assistant is the project_1_publications.json dataset provided by Ready Tensor.
Preprocessing: From this dataset, we extracted key metadata such as titles and descriptions for each publication. This structured information formed the initial knowledge corpus that the assistant could later process into semantic units.
Rationale: Using concise publication metadata ensured that the system remained lightweight while still capturing the most informative portions of each document.
To prepare the data for semantic search, we divided each publication into smaller overlapping text segments. This was accomplished with LangChain’s RecursiveCharacterTextSplitter, configured as follows:
Chunk size: 1000 characters
Overlap: 200 characters
The overlap ensures that important context spanning across chunk boundaries is preserved, reducing the risk of fragmented or incomplete retrieval.
Example:
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200 ) chunked_docs = text_splitter.create_documents(documents)
Once chunked, the documents were transformed into dense vector embeddings using HuggingFace’s all-MiniLM-L6-v2 model.
Why this model? It provides a strong balance between semantic accuracy and computational efficiency, making it well-suited for medium-scale retrieval tasks.
Vector Database: The embeddings were stored in ChromaDB, a lightweight local vector store. This enabled:
Fast semantic similarity searches
Privacy-preserving storage (no external dependency on cloud-hosted vector databases)
Scalability for future datasets
The assistant’s retrieval process is designed to ensure that all answers remain grounded in verified sources:
A user’s query is embedded in the same vector space as the documents.
The system retrieves the top-3 most semantically relevant chunks from ChromaDB.
A custom prompt ensures that the language model generates responses only from the retrieved context.
Prompt Template Example:
prompt_template = """
You are a helpful AI research assistant.
Answer the user's question based ONLY on the provided research context and previous conversation.
If the answer is not present in the context, clearly state: "I cannot find the information in the provided documents."
"""
This design prevents the model from fabricating answers (hallucinations), thereby enhancing trustworthiness and credibility.
To make the assistant accessible, we developed a Streamlit-based web UI that provides an intuitive, chat-style interaction:
Real-Time Conversational Experience: Users can input questions and receive immediate, context-grounded responses.
Accessible Design: Requires no technical expertise — ideal for students, researchers, and practitioners alike.
Extensibility: Developers can easily expand the UI with additional controls (e.g., persistent memory, advanced filtering).
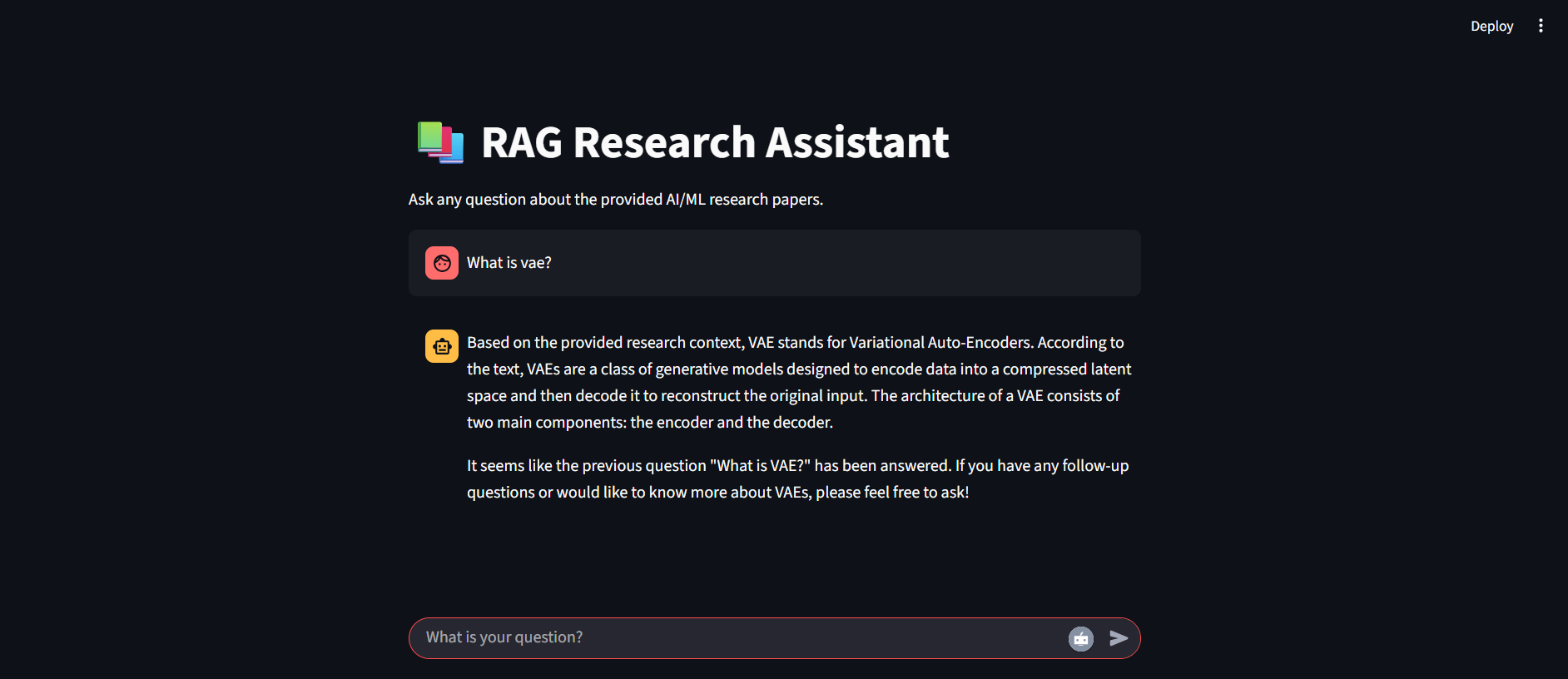
The assistant is able to synthesize complex answers by combining insights from multiple retrieved sources.
Example Query:
“What are the different memory management strategies for long conversations?”
Assistant Answer:
Based on the provided documents, there are three main strategies:
Stuff Everything In – retaining the entire history (but not scalable).
Sliding Window – keeping only the most recent N messages.
Summarization/Refinement – compressing older messages into summaries to preserve context efficiently.
This demonstrates the assistant’s ability to provide coherent, fact-grounded answers, directly tied to Ready Tensor publications.
The RAG Assistant delivers value across multiple dimensions, addressing the needs of different audiences within the AI/ML ecosystem while also contributing to the broader Ready Tensor community.
a) Accelerated Literature Review: The assistant enables researchers to query and synthesize insights across multiple publications in seconds, significantly reducing the time required for manual searches.
b) Deeper Knowledge Discovery: By retrieving semantically relevant passages, it surfaces connections that keyword search might overlook, uncovering relationships between methods, datasets, or findings.
c) Grounded Exploration: The grounding mechanism ensures that answers remain fact-based, improving trust in the assistant’s outputs and supporting research accuracy.
a) Interactive Learning: Instead of passively reading dense academic papers, students can engage in a conversational format, making complex AI/ML concepts more approachable.
b) Accessible Knowledge Transfer: The assistant lowers the entry barrier for newcomers by summarizing technical content in real time, helping them understand research trends, methods, and applications.
c) Skill Development: Students can replicate the pipeline to gain hands-on experience with cutting-edge technologies such as LangChain, ChromaDB, HuggingFace embeddings, and LLM APIs.
a) Blueprint for Domain-Specific Assistants: This project serves as a reproducible example for building tailored RAG systems, encouraging community members to adapt the approach for their own datasets, research areas, or industry problems.
b) Applied AI Contribution: By providing both the methodology and an open-source implementation, the assistant bridges the gap between research concepts and real-world application.
c) Ecosystem Strengthening: The project enhances the utility of Ready Tensor’s publication repository, transforming static resources into interactive, living knowledge systems.
While the RAG Assistant demonstrates clear potential and delivers strong results, several limitations remain that highlight opportunities for continued development and community collaboration.
a) At present, the assistant’s memory is session-limited. Once a session ends, the conversation history is lost, preventing continuity of research across multiple interactions.
b) This limits its usefulness for long-term projects where users may want to revisit prior queries or build on earlier explorations.
a) The current implementation focuses on text-based publication metadata (titles, descriptions, abstracts).
b) Expanding to multimodal content (figures, tables, equations, and embedded code) would greatly increase its comprehensiveness but requires more sophisticated data processing and storage strategies.
a) While the system demonstrates accuracy through qualitative examples, it lacks a formal evaluation framework.
b) Metrics such as retrieval precision, recall, and factuality scores would provide stronger evidence of effectiveness and help benchmark against other approaches.
a) Currently, the assistant runs locally in a development environment.
b) Without packaging and deployment (e.g., Docker containers, cloud hosting), broader accessibility is limited for community members who may not have the technical setup required.
a) Introduce persistent memory mechanisms so users can maintain a history of research conversations across sessions.
b) This would transform the assistant into a true long-term research partner, supporting iterative learning and project continuity.
a) Extend the knowledge base to incorporate visual figures, structured tables, and even executable code snippets.
b) By enriching the assistant with multimodal data, users could access a more holistic understanding of publications.
a) Implement systematic validation pipelines with quantitative benchmarks (e.g., precision@k, groundedness scores).
b) Encourage community-driven evaluations to assess performance across diverse datasets and domains.
a) Package the assistant using Docker for reproducible builds.
b) Host on cloud platforms to enable community-wide access, removing dependency on local installations.
This would position the assistant as a shared resource for the Ready Tensor ecosystem, available anytime and anywhere.
References :
The Rag Architecture Image url : https://www.deepchecks.com/glossary/rag-architecture/
dataset : https://drive.google.com/drive/folders/1HAqLXL2W-sh8hqoBb1iSauJ_0wZVRxB9?usp=drive_link
citation: Ready Tensor
Closing Perspective
By addressing these challenges, the RAG Assistant can evolve from a functional prototype into a scalable, multimodal, and persistent AI research companion. Future iterations will not only extend technical capabilities but also strengthen its role as a blueprint for building intelligent, domain-specific assistants within and beyond Ready Tensor.