
This repository contains a synthetic knowledge corpus designed specifically for benchmarking and demonstrating capabilities of Retrieval-Augmented Generation (RAG) pipelines. The dataset simulates a complex, high-governance corporate environment, making it ideal for portfolio projects focused on enterprise AI solutions.
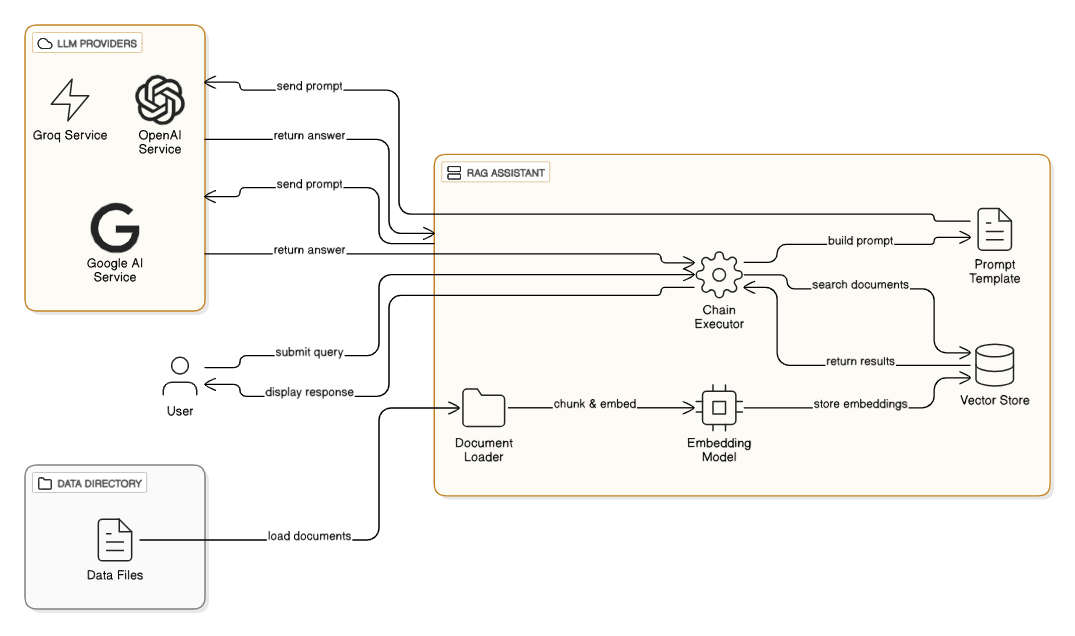
This project implements a RAG (Retrieval-Augmented Generation) AI assistant that can answer questions about corporate documents by finding relevant information and using it to generate responses. The system combines document search with AI chat capabilities, allowing users to query a knowledge base of corporate policies, procedures, and reports.
Key Features:
The system is built using modern AI technologies including ChromaDB for vector storage, LangChain for orchestration, and supports multiple LLM providers (OpenAI, Groq, Google AI).
rt-aaidc-project1/
├── src/
│ ├── app.py # Main RAG application with query pipeline
│ └── vectordb.py # Vector database wrapper and document processing
├── data/ # Corporate documents corpus
│ ├── DOC-COMP-00*.txt # Compliance documents
│ ├── DOC-ENG-00*.txt # Engineering reports
│ ├── DOC-EXEC-00*.txt # Executive memos
│ ├── DOC-FIN-00*.txt # Financial policies
│ ├── DOC-HR-00*.txt # Human resources policies
│ ├── DOC-IT-00*.txt # IT security policies
│ ├── DOC-LEG-00*.txt # Legal documents
│ ├── DOC-LOG-00*.txt # Logistics schedules
│ ├── DOC-MARK-00*.txt # Marketing materials
│ ├── DOC-PROC-00*.txt # Process documentation
│ ├── DOC-PROD-00*.txt # Product specifications
│ └── DOC-SEC-00*.txt # Security audit findings
├── chroma_db/ # Vector database storage (auto-generated)
├── requirements.txt # Python dependencies
├── LICENSE # Project license
├── PROJECT-README.md # Implementation guide
└── README.md # This file
Key Components:
src/app.py: Main application implementing the RAG query pipelinesrc/vectordb.py: Vector database operations and document processingdata/: 18 corporate documents representing different departments and governance levelschroma_db/: Persistent vector database storage for embeddingsThe project uses Sentence-Transformers Embedding model (specifically models like all-MiniLM-L6-v2) for several strategic reasons:
Privacy-Preserving: Local deployment means corporate documents never leave your infrastructure—critical for sensitive enterprise data
Cost-Effective: Zero API costs compared to OpenAI embeddings ($0.0001/1K tokens)
Performance: 384-dimensional embeddings provide excellent semantic similarity for enterprise documents while maintaining fast inference
Offline Capability: No external API dependencies for embedding generation
The system supports three LLM providers to accommodate different deployment scenarios:
OpenAI GPT-4/GPT-4o Best for: Complex multi-hop reasoning, highest accuracy on nuanced queries
Groq Best for: Real-time applications requiring ultra-fast responses
Google Gemini 2.5 Pro Best for: Applications with very long context requirements
The modular design allows users to select the appropriate provider based on their specific constraints (budget, latency requirements, accuracy needs), demonstrating architectural flexibility for enterprise deployment.
Author: Sachin Ambe
Date: October 27, 2025
Description: This project is part of the ReadyTensor AAIDC (Agentic AI Developer Certification) curriculum, designed as a learning template for implementing RAG systems in enterprise environments.
This project is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).
For the full license text, see the LICENSE file in this repository.
The project requires the following key packages (see requirements.txt for complete list):
Core RAG Components:
chromadb==1.0.12 - Vector database for embeddings storagelangchain==0.3.27 - Framework for LLM applicationssentence-transformers==5.1.0 - Embedding model for text similarityLLM Providers (choose one):
openai==1.107.1 - OpenAI GPT modelsgroq==0.31.1 - Groq API for fast inferencelangchain-google-genai==2.1.10 - Google AI modelsAdditional Dependencies:
fastapi==0.115.9 - Web framework for API endpointspython-dotenv==1.1.1 - Environment variable managementnumpy==2.3.3 - Numerical computingpydantic==2.11.7 - Data validationYou need an API key from one of these providers:
Install dependencies:
pip install -r requirements.txt
Set up environment variables:
# Create .env file echo "OPENAI_API_KEY=your_key_here" > .env # OR echo "GROQ_API_KEY=your_key_here" > .env # OR echo "GOOGLE_API_KEY=your_key_here" > .env
Run the application:
python src/app.py
The project requires implementing 7 main components:
Document Loading (src/app.py)
data/ directoryText Chunking (src/vectordb.py)
Document Ingestion (src/vectordb.py)
Similarity Search (src/vectordb.py)
RAG Prompt Template (src/app.py)
RAG Query Pipeline (src/app.py)
Testing and Validation
Once implemented, you can ask questions like:
For additional RAG test cases, see section RAG Test Cases below
The Aether Dynamics Corp. corpus is a collection of 18 small, interrelated text documents across three essential organizational categories: Operational, Governance, and Strategic.
| Characteristic | Detail | RAG Challenge Focus |
|---|---|---|
| Size | 18 individual text files (approx. 200–350 words each). | Low latency retrieval on a small, dense corpus. |
| Structure | Documents use explicit internal citations (e.g., <Referenced-Document: DOC-XXX>) to link policies, incidents, and procedures. | Multi-hop reasoning and relational query pathing.[1] |
| Governance | Files are intentionally tagged in the content with specific governance tiers: LT Tier (Long-Term/Approved) and HOT Tier (Draft/Unstable). | Testing governance filters and conflict resolution (e.g., prioritizing verified knowledge over preliminary findings).[2] |
| Content | Includes procedural guides, audit findings, financial memos, and post-mortem reports, ensuring a high density of actionable entities (Rules, Claims, Temporal Markers).[3] | Factual accuracy and synthesis of information from multiple sources. |
The core value of this dataset for a portfolio project is its ability to test the RAG implementation's ability to not just find keywords, but to reason over linked pieces of information, a key requirement for enterprise AI deployment.[1]
The following table provides essential test cases designed to stress-test key features of your RAG pipeline, including multi-hop retrieval, conflict resolution, and compliance checking.
| Sample Query | Required Documents (Evidence Chain) | RAG Challenge Focus | Expected Result |
|---|---|---|---|
| Q1 (Direct Retrieval): What training is recommended for Product Engineering and by when? | DOC-HR-002 | Single-Hop Factual Extraction | Secure Coding Principles, by Q4 2025. |
| Q2 (Conflict Resolution/Governance): The Q2 compliance report stated security was fine, but a later audit found a vulnerability. Why was a policy change mandated regarding device security? | DOC-ENG-001 DOC-SEC-003 DOC-IT-001 | Causal Tracing and Policy Implementation Traceability.[4] | The policy change was mandated by DOC-SEC-003 because the March 2024 System Outage (DOC-ENG-001) was definitively caused by a successful brute-force attack enabled by the former 6-character PIN length. |
| Q3 (Conditional Logic/Three-Hop): What is the standard daily meal expense limit for a Full-Time employee in the Marketing department? | DOC-HR-001 (Status) DOC-FIN-002 (Cost Center) DOC-FIN-001 (Limit Rule) | Three-Hop Conditional Lookup and Synthesis.[1] | $100.00 USD. |
| Q4 (Temporal Constraint Check): If code QA sign-off happened on November 4th, can the Staging Environment deployment proceed on November 5, 2025? | DOC-PROC-001 DOC-LOG-001 | Conflict Identification and Temporal Reasoning | No, the deployment must be rescheduled because DOC-LOG-001 lists mandatory Security Patching for the Staging Environment on 2025-11-05 from 03 - 08. |
| Q5 (Factual Integrity Check): Does the Q4 Marketing Campaign's key mobile messaging align with the current version of the known issues log? | DOC-MARK-001 DOC-PROD-002 | Identifying factual contradiction between related documents. | No. The claim of "seamless mobile integration" in DOC-MARK-001 conflicts with Bug ID 451 in the issues log, which reports intermittent failure of data visualization on mobile devices. |
| Q6 (Governance Boundary Testing): Which specific document, containing HOT Tier findings, mandates an urgent budget increase for the IT Security department? | DOC-FIN-003 DOC-SEC-003 | Filtering by Status Tier and tracing HOT knowledge to its immediate financial consequence. | The urgent budget transfer in DOC-FIN-003 is based on the Quarterly Security Audit Findings Q3-2024 (DOC-SEC-003). |
| Q7 (Policy Justification): What is the executive-level rationale for the new Remote Work Policy Addendum? | DOC-HR-003 DOC-EXEC-001 | Tracing a policy back to its Strategic Justification. | The policy is justified by the strategic goal defined in DOC-EXEC-001 to maximize digital presence and remote workforce efficiency (Key Result 2.1) for talent retention. |