
Author: Manuela Schrittwieser
Date: November 5, 2025
GitHub Repository: deployable-llm-sql-assistant
Hugging Face Model: phi-3-mini-sql-assistant
This project documents an end-to-end engineering pipeline for fine-tuning a small, powerful Large Language Model (LLM) for a specialized technical task. The objective was to create a reliable and deployable Text-to-SQL assistant by adapting the microsoft/Phi-3-mini-4k-instruct model. This was achieved using a Parameter-Efficient Fine-Tuning (PEFT) technique called QLoRA, which enables efficient training on consumer-grade hardware.
The resulting model successfully translates natural language questions into accurate SQL queries based on a provided database schema. The entire process, from environment setup to final evaluation, is encapsulated in a reproducible Google Colab notebook, emphasizing a robust and well-documented engineering workflow. This project serves as a practical demonstration of state-of-the-art LLM customization for real-world applications.
The project utilizes the b-mc2/sql-create-context dataset, a comprehensive collection of natural language questions, corresponding database schemas, and their ground-truth SQL query answers. To ensure a manageable and rapid development cycle suitable for an educational context, a randomized subset of 10,000 samples was selected. This subset was then partitioned into a 90% training set (9,000 samples) and a 10% validation/test set (1,000 samples).
Effective fine-tuning requires structuring the data in a format that the base model understands. Each data sample (schema, question, answer) was formatted into a single string following the official Phi-3 ChatML template. This ensures the model learns the conversational turn-taking structure expected for an instruct-tuned model.
Example Prompt Structure:
<|user|> Given the database schema: {example['context']} Generate the SQL query for the following request: {example['question']}<|end|> <|assistant|> {example['answer']}<|end|>
This structured format was applied to all samples in both the training and validation sets using the datasets.map() function.
A key goal was to perform this fine-tuning within a resource-constrained environment (a single Google Colab T4 GPU with ~15 GB VRAM). This was made possible by implementing the QLoRA methodology.
The fine-tuning process was configured with the following key parameters, managed by the Hugging Face trl and peft libraries:
| Parameter | Specification | Rationale |
|---|---|---|
| Fine-Tuning Method | QLoRA | Enables training on a single GPU by quantizing the base model and training small adapters. |
| Base Model Quantization | 4-bit NormalFloat (NF4) | Drastically reduces memory footprint from >14 GB to <3 GB for the base model. |
| Compute Data Type | bfloat16 | Maintains numerical stability and performance during training computations. |
LoRA Rank (r) | 8 | A standard, effective rank that balances performance with parameter efficiency. |
| Learning Rate | 2e-4 | An aggressive but effective learning rate for PEFT, used with a Cosine scheduler. |
| Training Epochs | 2 | Chosen to improve model reliability and format adherence over a single epoch. |
| Effective Batch Size | 8 | Achieved via a per-device size of 2 and 4 gradient accumulation steps. |
| Optimizer | Paged AdamW (32-bit) | A memory-efficient optimizer designed for quantized training. |
The model's performance was evaluated both quantitatively through the training loss and qualitatively via inference on the held-out test set.
The training process was monitored using TensorBoard. The training loss curve demonstrates that the model was effectively learning and converging over the two epochs. A steady decrease in loss indicates that the adapter weights were successfully updated to minimize the prediction error on the training data.
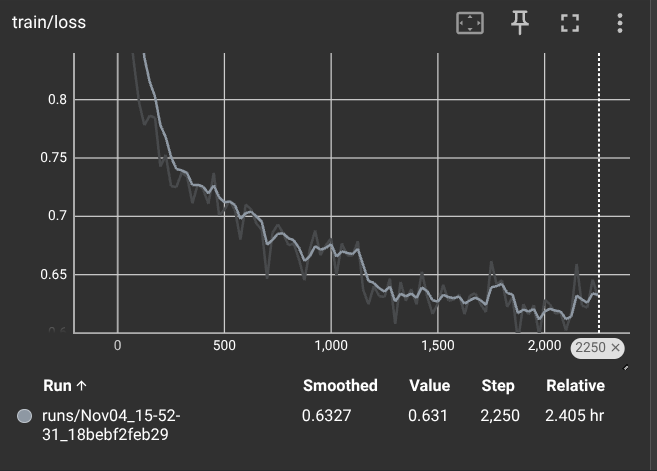
Figure: Training loss over 2 epochs. The loss consistently decreases, indicating successful model learning.
Inference was performed on random samples from the test set. The model trained for two epochs showed significant improvement over a single-epoch baseline, particularly in its reliability.
<|assistant|> token, which is critical for robust parsing in a deployment pipeline.Example Result:
| Component | Value |
|---|---|
| Schema | CREATE TABLE employees (name VARCHAR, department VARCHAR, salary INTEGER) |
| Question | What are the names of employees in the 'Engineering' department? |
| Ground Truth | SELECT name FROM employees WHERE department = 'Engineering' |
| Model Output | SELECT name FROM employees WHERE department = 'Engineering' |
This project successfully demonstrates a reproducible and effective pipeline for fine-tuning a modern, open-source LLM for a specialized technical task. By leveraging QLoRA, it was possible to achieve high-quality results on accessible, consumer-grade hardware. The final two-epoch model is both accurate in its SQL generation and reliable in its output format, making it a strong candidate for integration into downstream applications and a successful outcome for the goals of the LLM Engineering & Deployment Course.
