
⬅️ Previous - Data Privacy and Compliance in Agentic AI
➡️ Next - Agentic System Architect's Blueprint
Choosing the right LLM means deciding between proprietary APIs and open-weight models. Proprietary options offer ease and cutting-edge performance, while open-weight models provide more control, privacy, and flexibility. This lesson breaks down the tradeoffs — and the hosting options — so you can make the right call for your agentic system.
In the previous lesson, we explored how data privacy and compliance requirements shape your system design — from GDPR's right to deletion to HIPAA's restrictions on PHI sharing. Now let's see how those same requirements influence one of your most critical architectural decisions: which LLM to use and where to run it.
The choice between proprietary APIs and open-weight models isn't just about performance or cost. It's about who controls your data pipeline — and whether you can meet the privacy promises you made to your users.
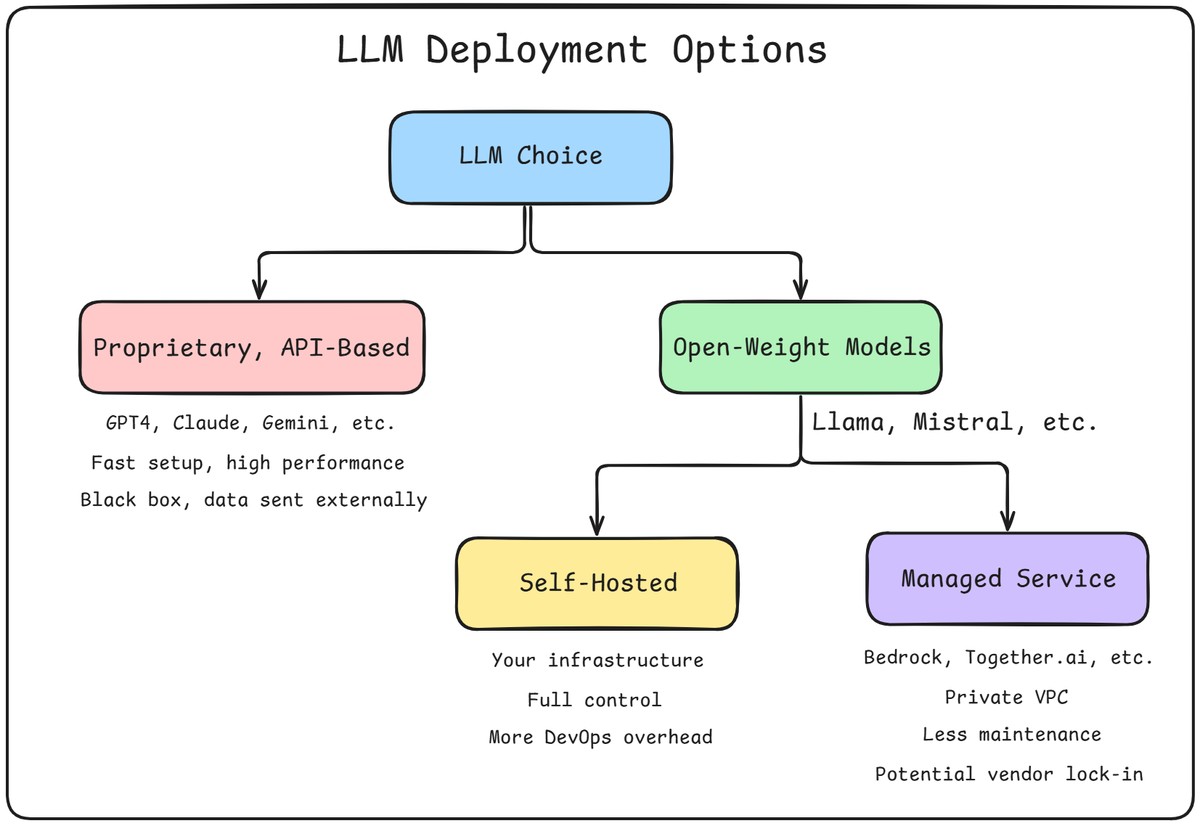
If you’re building an agentic system, one of the first architectural choices you’ll face is this:
Do you build around a closed-source API like GPT-4, or choose an open-weight model you can run yourself?
This isn’t a simple “which model is better” debate. It’s a decision about control, transparency, compliance, and long-term cost. Closed models can offer incredible out-of-the-box performance, but they’re black boxes. Open-weight models might take more effort to use — but you own the stack, and you decide how it evolves.
And while it might seem like the choice only affects developers or infrastructure teams, it runs deeper. Your answer will shape how flexible your system can be, how safe your data is, how easily you can scale, and how well you can audit or explain your AI’s behavior down the line.
Let’s break it down.
If you’re using OpenAI’s GPT-4, Anthropic’s Claude, or Google’s Gemini, you’re not running the model — you’re just sending data to someone else’s servers and getting a response back.
And in return, you get a lot: world-class performance, smooth developer tooling, constant improvements. It’s hard to beat the convenience.
But what you don’t get is transparency.
These models are closed-source and closed-weights, essentially a black-box.
You can’t inspect the model. You can’t freeze the version. You don’t know what data it was trained on, or when it will change. And you definitely can’t run it inside your secure environment unless you’re on an enterprise-tier plan with private deployment options.
That means every request comes with risk: legal, operational, and reputational. Even if your API provider says they won’t train on your data, you’re still sending sensitive information across the wire — and relying on a third party to handle it responsibly.
For some teams, that tradeoff is fine. But for agentic systems working with sensitive docs, private records, or user inputs that require strong compliance controls, it quickly becomes a blocker.
Note: Some proprietary providers now allow version pinning — for example, gpt-4.1-mini-2025-04-14. This helps reduce surprise updates, but you still don’t control when new versions are introduced or what’s changed under the hood. It’s transparency by label, not by design.
Now let’s flip the script.
Instead of sending your data to a model, what if the model came to you?
Open-weight models like LLaMA 3, Mistral, Qwen, and DeepSeek give you the flexibility to host the model wherever you want — on your laptop, in your private cloud, behind your firewall.
That means no more API gatekeeping. No more wondering if your prompts are being logged. No more last-minute model updates breaking your prompt chains. Just full control over how, where, and when the model runs.
This also opens the door to customization. You can fine-tune the model on your data, adjust its behavior, pin a specific version, or even swap out the backbone entirely as new open models emerge.
The downside? You’ll need to make a few more decisions. Which model do you use? How do you host it? Who manages the infrastructure?
That brings us to the next layer of the decision.
Once you decide to go with an open-weight model, you’ve got one more choice to make:
Do you host the model yourself, or let someone else do it for you?
You can spin up your own infrastructure — using GPUs on AWS, GCP, or even on-prem — and run models directly. This gives you total control over the stack, from latency tuning to custom model adapters.
Or you can use a managed service like Amazon Bedrock, Fireworks, Hugging Face Inference Endpoints, or Together.ai. These let you run open-weight models inside a private, secure VPC — without managing the servers yourself.
Here’s the key idea:
This isn’t about privacy anymore. Either path can be compliant and secure.
This is about who owns the infrastructure — and how much you want to customize.
Self-hosting gives you the most flexibility but also demands the most engineering effort. Managed services offer convenience, autoscaling, and monitoring — but you trade away some of the deep stack control.
Either way, the good news is: you’re still using open models on your own terms. And that’s a big leap from relying entirely on black-box APIs.
This matters, especially when you're thinking about licensing, deployment, or customization.
In most applied cases — like building a research assistant or AI chatbot — open-weight is enough. You don’t need to re-train or re-publish the model. You just need to run it, and maybe fine-tune it.
If you’re building internal tools or privacy-sensitive systems, the key question isn’t “Is it open-source?”
It’s: “Can I run this model privately, securely, and cost-effectively?”
📜 Some open-weight licenses (e.g. Meta's LLaMA) permit commercial use below certain usage thresholds (which are quite generous). Always check the license terms before deploying in production or revenue-generating environments.
There’s no universally “correct” way to use LLMs — there’s only the right choice for your system, your team, and your constraints.
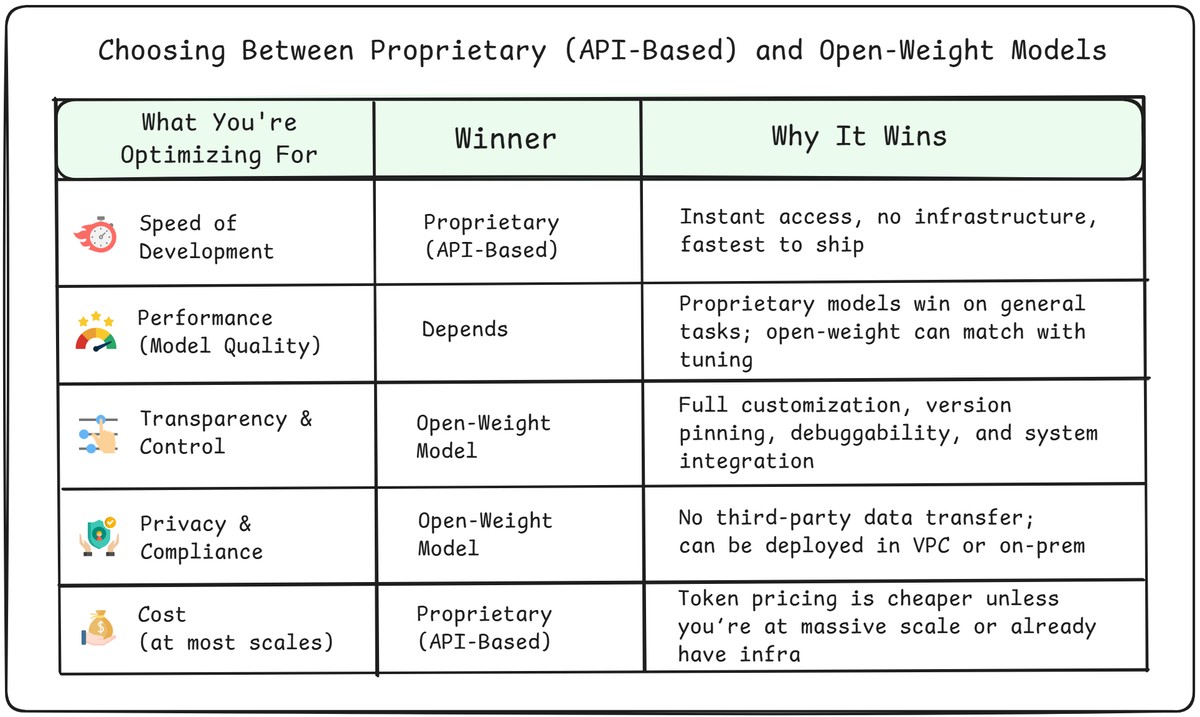
The tradeoff isn’t just between OpenAI and LLaMA. It’s about what you’re optimizing for:
Let’s not pretend this doesn’t matter.
If you're racing to ship a demo, test an idea, or get your agent into users' hands fast, there's no faster path than calling a commercial API. No infrastructure. No hosting. No DevOps. You hit the endpoint and you're done.
Open-weight models — even if you use a managed service — add a bit of friction. You’ll need to pick a model, configure inference, and possibly deal with tokenization quirks or resource limits.
And if you're hosting locally for development, you’ll need a beefy GPU-enabled machine — ideally with an A100, 4090, or Apple M-series chip — to run even quantized models smoothly. That’s not always available to every team.
APIs let you move fast today.
Open-weight models help you move freely tomorrow.
Closed APIs typically offer the highest raw performance on general tasks. Models like GPT-4 or Claude Opus are heavily optimized and fine-tuned across broad domains — and they often outperform open-weight models out of the box.
Open-weight models have improved dramatically and can match or even surpass APIs on certain tasks — especially with domain tuning or prompt engineering. But out of the box, they still tend to lag behind top proprietary models in general-purpose reasoning and instruction following.
APIs win on default model quality. Open models can catch up — with work.
Closed APIs are black boxes. You can’t see how the model was trained, what changed in the last update, or why it produced a certain output. You’re also locked into their defaults — from tokenization quirks to rate limits to behavior updates.
Open-weight models flip the script. You choose the model version. You host it where and how you want. You can fine-tune it, inspect intermediate steps, log everything, and debug it when things go wrong. You can also run adversarial or edge-case testing without hitting rate limits, moderation filters, or ToS violations.
That level of transparency and control becomes essential when building agentic workflows, evaluating safety, or pushing model boundaries in regulated domains.
Open models give you agency and sovereignty.
If your system touches regulated data — think patient records, legal briefs, financial reports, or internal company docs — then closed APIs raise tough questions.
Even with data encryption and enterprise agreements, you're still transmitting user content to a third party. You don’t own the pipe, and you don’t fully control where the data lands.
Open-weight models, by contrast, can be run entirely within your infrastructure — or within your Virtual Private Cloud (VPC) using services like Bedrock. Either way, you eliminate the external transmission risk.
Want a clean answer in a security review? “No data leaves our environment” is hard to beat.
In 2025, API-based models are more cost-effective for most workloads — even at moderate or high scale. With optimized offerings from OpenAI, Anthropic, and Google priced between $0.15 per million tokens (for cheaper models) and $15 per million tokens (for higher-end models), you can serve tens of millions of messages per month for just a few hundred dollars.
Self-hosting open-weight models introduces significant overhead:
Even with quantization and batching, it’s hard to match the efficiency and pricing of mature API services — unless you’re operating at massive scale, or already have infrastructure in place.
For most teams, APIs win on cost until you’re deep into enterprise-scale volumes.
So What’s the Right Call?
There isn’t one.
But here’s the north star:
Your system will evolve. Your needs will grow. Your risks will change.
This lesson isn’t about picking a side.
It’s about understanding the stakes — so you can make smart, confident tradeoffs.
Let's take a look at some of the most prominent open-source LLMs as of mid-2025, their key features, and application areas:
| Model | Developer | Parameters | Features | Notable Uses | License |
|---|---|---|---|---|---|
| Llama 3.1 | Meta AI | 8B–405B | High multilingual, long context (128k), chat/coding | General NLP & Coding | Permissive |
| Mistral Large | Mistral AI | 7B–22B+ | Efficient attention, group-query, MoE variants | Chat, task-specific bots | Apache 2.0 |
| DeepSeek R1 | DeepSeek AI | 9B–67B+ | Superior reasoning, 128k context, scientific focus | Advanced reasoning, tech | Permissive |
| Qwen 2.5 | Alibaba DAMO | Up to 72B | Top open coding, 20+ languages, massive context | Coding, chat, Q&A | Permissive |
| Falcon 180B | TII | Up to 180B | Multilingual, code, long context, high performance | Multilingual, code | Apache 2.0 |
| OLMo | Allen Institute for AI | 7B+ | Full stack open, easy research, reproducibility | Research | Apache 2.0 |
| K2 | LLM360/Petuum/MBZUAI | 65B | Fully open, rigorous benchmarks, transparent | Reference, custom AI | Apache 2.0 |
| BLOOM | BigScience | 176B | 46 languages, 13 programming languages | Multilingual NLP | RAIL |
| MPT | MosaicML | 7B–30B | Modular, cost-efficient, tuned for deployments | SaaS/NLP backbone | Apache 2.0 |
| h2oGPT | H2O.ai | 7B–40B | Multi-resolution decoder, hierarchical encoder | Conversational AI | Apache 2.0 |
| Phi-2 | Microsoft | 2.7B | Lightweight, next-word prediction, efficient | Small-scale, research | MIT |
*As of July 2025
You just saw a high-level comparison of popular open-weight models. Now let’s narrow it down to a few that work particularly well in agentic AI systems, and explain when to use each.
But first, two important caveats:
The open-weight model landscape changes fast.
What’s “state-of-the-art” today could be obsolete next month. New checkpoints, fine-tunes, and architectures drop every week.
Check recent leaderboards like Hugging Face’s Open LLM Leaderboard or LMSYS Chatbot Arena.
Benchmarks don’t tell the whole story.
Just because a model ranks high doesn’t mean it will work best for your agent. You need to test models on your own tasks, prompts, and workflows.
YMMV — and in agentic systems, “best” often means “best for your setup.”
That said, if you’re wondering where to start — here’s a shortlist of open-weight models that have proven reliable across many agentic use cases in 2025.
The 1B and 3B variants of LLaMA 3.2 work well for lightweight chatbots. But if you're building a serious agentic system, LLaMA 3.3–70B is the new open-weight standard.
Think of it as the open-source Codex — but smarter and multilingual.
Ideal for critique loops or knowledge synthesis agents.
Great for enterprise-scale agents serving global users.
These are the go-to models for fast prototypes and low-latency use cases.
Let’s bring it all together.
By now, you’ve seen the tradeoffs between closed APIs and open-weight models. So… which path should you take?
Here’s a quick cheatsheet based on your goals and constraints:
Think: MVPs, early-stage agents, R&D projects, small team tools, non-regulated / low-risk applications
Think: regulated environments, specialized domains (e.g. medical, legal), internal copilots, multi-agent systems
Use open-weight models as your default inference stack (e.g. via Bedrock or a self-hosted endpoint), and fall back to a closed API for high-complexity tasks or overflow capacity.
This is often the most practical setup for real-world systems — balancing control, coverage, and resilience.
Decided to go open-weight? Great — now let’s make it efficient.
You don’t need racks of GPUs or a PhD in ML infra to run a model like LLaMA 3 or Mistral. But you do need to be smart about optimization and deployment.
Here’s how to host without burning your GPU budget.
Running a model in 8-bit or 4-bit precision dramatically reduces memory usage and cost — often with little to no loss in quality.
Start with tools like:
bitsandbytes for 8-bitGGUF or QLoRA for 4-bitQuantized models can run on a single A100 or even consumer GPUs like the 4090.
Use optimized serving stacks built for high-throughput inference. Top options include:
These support batching, token streaming, and low-latency serving.
You’ve got three common options:
Local Dev / Prototyping:
Use tools like Ollama or LM Studio to run quantized models locally.
Cloud Hosting:
Rent A100s or 4090s from RunPod, Lambda Labs, or your cloud provider (AWS, GCP, Azure). Build autoscaling around peak load.
Inference-as-a-Service:
Services like Amazon Bedrock, Together.ai, and Fireworks let you run open models in a VPC — without managing infra.
Don’t stop at loading the model. Tune your:
And don’t forget to monitor cost, uptime, and failure patterns — just like you would with any production service.
Hosting open-weight models in 2025 is no longer a DevOps nightmare. With the right tools and a bit of setup, you can build scalable, compliant, and cost-effective agentic systems — all on your terms.
There’s no universal best practice when it comes to LLM deployment — only the best fit for your specific needs.
Some teams need speed and simplicity. Others need control, privacy, or cost predictability. And some need all of it — which is why hybrid architectures are on the rise.
But here’s what’s non-negotiable: you should know exactly why you’re choosing what you’re choosing.
Instead, understand the tradeoffs. Talk to your security and infra teams. Test a few options. And make the decision that actually serves your users and your system.
⬅️ Previous - Data Privacy and Compliance in Agentic AI
➡️ Next - Agentic System Architect's Blueprint

