This system leverages a timestamped YouTube video Retrieval-Augmented Generation (RAG) approach to transform video content into an interactive and accessible knowledge source. By combining automatic transcription with precise timestamps and integrated chat memory, it enables contextual search, concise summarization, and intelligent assistance. Chat memory enhances user interactions by remembering preferences and maintaining context across sessions, delivering more personalized and relevant responses. This allows users to locate specific moments, generate insights, and retrieve answers directly from videos. Ideal for educators, researchers, and content creators, this tool maximizes engagement with video-based resources, turning hours of footage into actionable knowledge at your fingertips.
LangChain is the backbone of the system, handling the entire pipeline for Retrieval-Augmented Generation (RAG). It facilitates transcription processing, timestamp alignment, contextual search, and summarization. LangChain’s modular design allows the integration of various components, such as the YouTube Transcript API for transcription and memory modules for maintaining chat context. This ensures efficient data flow and robust handling of complex queries, enabling the system to generate precise and relevant insights from video content.
LangGraph plays a central role in managing the flow of retrieval and LLM (Large Language Model) calls within your YouTube RAG application. It orchestrates the interactions between the retrieval system and the language model by controlling when and how data is retrieved and processed. LangGraph handles the decision-making process for when to invoke the retriever to fetch relevant video segments transcripts based on the user's query and when to trigger the LLM to generate accurate responses. LangGraph supports complex workflows, such as sequential or multi-agent interactions, ensuring the system dynamically adapts to complex queries and efficiently handles video-based data retrieval and language generation.
The YouTube Transcript API is used to extract accurate and timestamped transcriptions from videos. This API forms the foundation of the system by converting spoken video content into searchable text. The timestamps ensure that every piece of information can be linked back to the exact moment in the video, allowing users to jump to specific sections instantly.
Below is a detailed explanation of implementation of the system.
!pip install --upgrade -q lark langchain-chroma youtube-transcript-api langchain_openai langchain-community langgraph langsmith pytube
from langchain_community.document_loaders import YoutubeLoader import getpass import os from youtube_transcript_api import YouTubeTranscriptApi import json from langchain_community.document_loaders import TextLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_chroma import Chroma from langchain_core.vectorstores import InMemoryVectorStore from langchain_core.documents import Document from langchain_openai import OpenAIEmbeddings from langchain.retrievers.multi_query import MultiQueryRetriever from langchain_openai import ChatOpenAI from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, PromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from langgraph.graph import StateGraph, START, END from IPython.display import Image, display from langgraph.checkpoint.memory import MemorySaver from langchain_core.tools import tool from langchain_core.messages import SystemMessage from langgraph.prebuilt import ToolNode from langchain_community.document_loaders.youtube import TranscriptFormat from langgraph.graph import END,START from langgraph.prebuilt import ToolNode, tools_condition from langgraph.graph import MessagesState, StateGraph
def _set_env(var: str): os.environ[var] = getpass.getpass(f"{var}: ") _set_env("OPENAI_API_KEY")
Fortunately, LangChain offers built-in support for the YouTube Transcript API, which significantly streamlined the development process. After testing various chunk sizes, including 30 seconds and 15 seconds, I discovered that 60 seconds works best for this system. This also support multilingual transcripts provided the language.
loader = YoutubeLoader.from_youtube_url( "https://youtu.be/j3IhNBzpSjE", transcript_format=TranscriptFormat.CHUNKS, chunk_size_seconds=60, ) all_splits=loader.load()
I used GPT-4o-mini for development because it offers a great balance of cost-effectiveness and efficiency.
Chroma is an AI-native, open-source vector database designed to enhance developer productivity.
llm = ChatOpenAI(model="gpt-4o-mini") embeddings = OpenAIEmbeddings() vector_store = Chroma.from_documents(documents=all_splits, embedding=embeddings)
The MultiQueryRetriever automates the process of prompt tuning by using an LLM to generate multiple queries from different perspectives for a given user input query. For each query, it retrieves a set of relevant documents and takes the unique union across all queries to get a larger set of potentially relevant documents. By generating multiple perspectives on the same question, the MultiQueryRetriever might be able to overcome some of the limitations of the distance-based retrieval and get a richer set of results.
In LangChain, the tool abstraction links a Python function to a schema that specifies the function's name, description, and expected arguments.
Tools can be provided to chat models that support tool calling, enabling the model to request the execution of specific functions with designated inputs.
This feature is particularly useful in agentic systems, where function execution is directed by the LLMs.
def format_docs(docs): formatted_docs = [] for doc in docs: metadata_str = ", ".join(f"{key}: {value}" for key, value in doc.metadata.items()) formatted_docs.append(f"{doc.page_content}\nMetadata: {metadata_str}") return "\n\n".join(formatted_docs) @tool(response_format="content_and_artifact") def retrieve(query: str): """Retrieve information related to a query.""" retriever_from_llm = MultiQueryRetriever.from_llm( retriever=vector_store.as_retriever(), llm=llm) retrieved_docs = retriever_from_llm.invoke(query) serialized = format_docs(retrieved_docs) return serialized, retrieved_docs
The query_or_respond function decides if the system should:
Use a retrieval tool (via a retriever) to fetch relevant context.
Skip retrieval and directly generate a response based on the chat's current state.
This is achieved using LangChain's tool-calling mechanism. The function sends the message state to a language model that can invoke the appropriate tool if needed.
Tools, like ToolNode, are explicitly defined for retrieval tasks. This ensures that when the decision involves retrieval, the tool handles it efficiently.
The generate function is used to create the final response based on retrieved context.
It collects tool-generated messages (retrieved documents), formats them into a concise prompt, and queries the LLM to produce an answer.
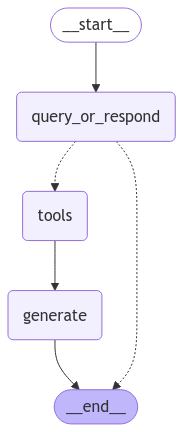
# Function1: Generate an AIMessage that may include a tool-call to be sent. def query_or_respond(state: MessagesState): """Generate tool call for retrieval or respond.""" llm_with_tools = llm.bind_tools([retrieve]) response = llm_with_tools.invoke(state["messages"]) # MessagesState appends messages to state instead of overwriting return {"messages": [response]} # Function2: Execute the retrieval. tools = ToolNode([retrieve]) # Function3: Generate a response using the retrieved content. def generate(state: MessagesState): """Generate answer.""" # Get generated ToolMessages recent_tool_messages = [] for message in reversed(state["messages"]): if message.type == "tool": recent_tool_messages.append(message) else: break tool_messages = recent_tool_messages[::-1] # Format into prompt docs_content = "\n\n".join(doc.content for doc in tool_messages) system_message_content = ( "You are an assistant for question-answering tasks. " "Use the following pieces of retrieved context to answer " "the question. If you don't know the answer, say that you " "don't know. Use three sentences maximum and keep the " "answer concise. Also return accurate timestamps from where" "you are extracting the answer in this format (start_seconds:----)" "\n\n" f"{docs_content}" ) conversation_messages = [ message for message in state["messages"] if message.type in ("human", "system") or (message.type == "ai" and not message.tool_calls) ] prompt = [SystemMessage(system_message_content)] + conversation_messages # Run response = llm.invoke(prompt) return {"messages": [response]}
graph_builder = StateGraph(MessagesState) graph_builder.add_node(query_or_respond) graph_builder.add_node(tools) graph_builder.add_node(generate) graph_builder.add_edge(START,"query_or_respond") graph_builder.add_conditional_edges( "query_or_respond", tools_condition, {END: END, "tools": "tools"}, ) graph_builder.add_edge("tools", "generate") graph_builder.add_edge("generate", END)
Used LangGraphs inbuilt memory functionality.
memory = MemorySaver() graph = graph_builder.compile(checkpointer=memory) # Specify an ID for the thread config = {"configurable": {"thread_id": "abc123"}}
def process_input_message(input_message): """ Processes the input message using the global graph and config. Args: input_message (str): The input message to process. Returns: None """ for step in graph.stream( {"messages": [{"role": "user", "content": input_message}]}, stream_mode="values", config=config, ): step["messages"][-1].pretty_print()
input_message = "What is this presentation about?" process_input_message(input_message)
input_message = "What are its advantages?" process_input_message(input_message)
input_message = "What is its tech stack and how its made?" process_input_message(input_message)
input_message = "What is the conclusion?" process_input_message(input_message)
In this workflow, the system determines its response strategy based on the user's query:
Direct LLM Response: If the user's question relates to the existing chat history, the system utilizes the Language Learning Model (LLM) to generate a response without additional context retrieval.
Context Retrieval: If the user's question introduces a new topic not covered in the chat history, the system employs a retriever to fetch relevant external information before generating a response.
This approach optimizes efficiency by avoiding unnecessary retrievals when the required information is already present in the conversation context.
from IPython.display import Image, display display(Image(graph.get_graph().draw_mermaid_png()))
Another method I explored for video transcription was using Whisper models via the openai-whisper library. Whisper allows you to utilize various models for transcribing YouTube videos, offering flexibility and accuracy. However, compared to the YouTube Transcript API, this approach was slightly more compute-intensive since it requires running a model for transcription. Due to this, I preferred using the YouTube Transcript API for its efficiency.
If you'd like to explore Whisper, you can find more information here.
The overall cost of running the system is primarily limited to the cost of the OpenAI API key, as we utilized the GPT-4o-mini model, which is one of the most cost-efficient options. Additionally, the system's efficiency is further optimized through the retrieval process with tools, minimizing unnecessary computations. Since the model is not run locally, the associated compute costs are virtually zero.
For more detailed information on OpenAI's pricing, you can refer to their pricing analysis.
In summary, this system effectively transforms YouTube videos into an interactive and accessible knowledge resource through a combination of timestamped transcriptions, advanced retrieval-augmented generation (RAG), and memory-based interactions. By leveraging powerful tools like LangChain, LangGraph, and the YouTube Transcript API, the system enhances the user experience by providing contextually relevant answers and seamless navigation through video content. With cost-efficient methods and an optimized retrieval process, this tool offers a robust and scalable solution for educators, researchers, and content creators to maximize engagement with video-based knowledge.
