Abstract
Object detection has become a pivotal technology in a wide range of applications, with YOLO (You Only Look Once) emerging as one of the most popular and effective real-time deep learning algorithms. YOLO utilizes a convolutional neural network (CNN) architecture combined with a custom-defined loss function to deliver high performance. Fascinated by the innovative approach, I implemented YOLO based on the original paper using PyTorch.
Introduction
In this project, I explored the inner workings of YOLO and implemented it from scratch using PyTorch. This gave me a strong understanding of the core components of YOLO, delving into the broader concepts of convolutional neural networks and the techniques that power real-time object detection systems. Through this implementation, I gained valuable hands-on experience in deep learning and object detection, furthering my understanding of these cutting-edge technologies. This knowledge can be used for further improvement in the field of computer vision and object detection.
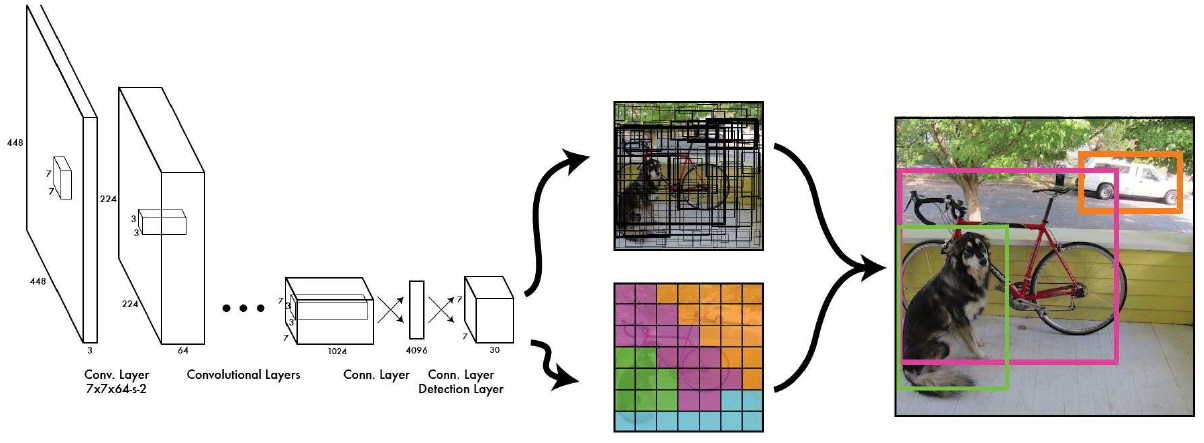
Methodology
Data Extraction and Preprocessing
-
Data Sources:
- Images and corresponding annotations are sourced from directories (
train_imagesandtrain_maps) containing labeled datasets for object detection tasks. - The target classes include
bicycle,car,motorbike, andperson.
- Images and corresponding annotations are sourced from directories (
-
Preprocessing:
- Annotations are parsed from
.txtfiles using a custom function (preprocess_txt). - A bounding box generator (
generate_output) converts annotation data into a tensor format compatible with YOLOv1 output (grid-based labeling with bounding box parameters and class probabilities). - Images are resized to
(224x224)and normalized usingtorchvision.transforms.
- Annotations are parsed from
Model Architecture
-
Base Network:
A pre-trained ResNet-50 model is utilized as a feature extractor. Its fully connected layers are removed, and parameters are frozen to prevent updates during training. -
Changes made in the Network:
Additional convolutional layers are added to adapt the ResNet backbone for YOLO's grid-based detection mechanism. These layers output predictions in a tensor shape representing bounding box coordinates, confidence scores, and class probabilities for each grid cell.
Loss Function
- YOLO Loss:
A custom loss function combines multiple sub-losses:- Object Loss: Penalizes incorrect confidence scores for grid cells containing objects.
- No-Object Loss: Penalizes high confidence scores for grid cells without objects.
- Bounding Box Loss: Measures differences in predicted and true bounding box coordinates.
- Class Probability Loss: Ensures accurate class predictions.
Training and Results
The RESNET50 architecture was used as the backbone for the model, which was trained over 50 epochs, batch size being 32 on the PASCAL VOC Dataset. The final loss after the 50th epoch was 6.9583.
The model demonstrated high computational efficiency—an essential factor for real-time object detection algorithms—with an average inference time of less than 300 milliseconds per image for object prediction.
Evaluation Metrics
The model was evaluated using Intersection over Union (IoU), a standard metric in object detection tasks that measures the overlap between the predicted bounding box and the ground truth bounding box. IoU is defined as:
The model achieved an overall IoU of 58%, with notable variations across object categories:
- Worst performance: Car images, likely due to the limited representation of cars in the training dataset.
- Best performance: Bike and bicycle images, likely due to their greater representation in the dataset.
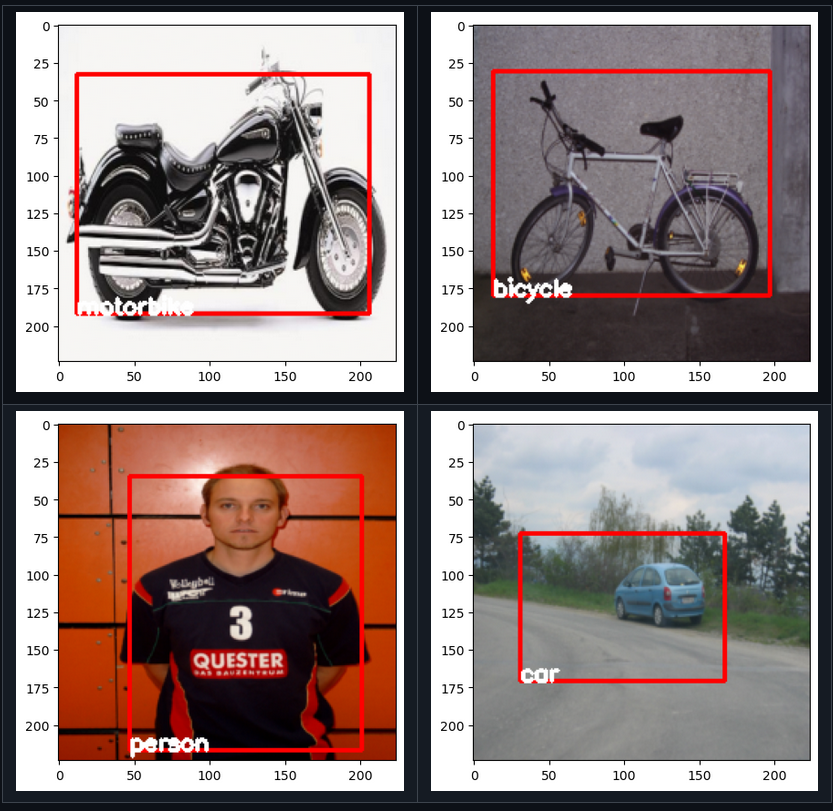
Some predictions
Hardware
The model was trained and evaluated on NVIDIA RTX 4060 GPU.
Conclusion
YOLO’s key strength lies in its ability to perform detection in a single forward pass of a neural network, making it faster and more suitable for real-time applications compared to traditional methods. By leveraging a convolutional neural network (CNN) architecture and a custom loss function, YOLO achieves high accuracy while maintaining speed, which has made it a go-to solution for many object detection tasks.
This project demonstrates a comprehensive implementation of object detection pipeline using YOLOv1 principles, with the strengths being built on top of transfer learning, a custom loss function, and an end-to-end data processing, training, and inference workflow.
References
You Only Look Once: Unified, Real-Time Object Detection Research Paper: https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf