vRD-OCR Multi-Head Long Text Recognition in Low Quality Images
Abstract
Although state-of-the-art Optical Character Recognition (OCR) systems are highly accurate on most usecases, their performance depends on certain key factors; image quality, clarity of the text, and most importantly length of the text and/or image width. Most sophisticated models are unreliable when tested on highly compressed images with faded text containing more than 50 characters, and are unsuitable for accuracy-sensitive tasks such as text-based forgery detection. In this work, we present vrdOCR, a text recognition model which specializes on long sentences and achieves a character-level recognition accuracy of
Introduction
OCR’s detection capabilities go beyond basic text recognition. Modern OCR systems can analyze the positioning, formatting, and spacing of characters to uncover irregularities that would be challenging for a human inspector to spot. For example, an altered invoice might replace a period with a comma, subtly changing an amount due, or adjust character spacing to insert unauthorized text. OCR systems, especially those enhanced with AI-driven anomaly detection, are trained to identify such inconsistencies. By flagging even minute variations in text and punctuation, OCR allows for a level of scrutiny that ensures minor alterations, which could have major implications, are not missed. This precision is crucial in high-stakes fields like finance, law, and government, where document integrity is paramount.
In addition to accuracy, OCR’s processing power and scalability set it apart from human inspection. While a person might carefully examine a few documents, an AI-enhanced OCR engine like vRD-OCR can process thousands of pages in a fraction of the time, maintaining a consistent level of precision and thoroughness.
Methodology
This section outlines the methodology implemented in developing vRD-OCR, a robust framework for optical character recognition (OCR). The pipeline addresses challenges such as noisy backgrounds, diverse fonts, and varying document qualities by leveraging advanced feature extraction and a dual-head decoding architecture. The components of the pipeline include preprocessing, training with multi-loss mechanisms, and postprocessing.
Preprocessing
Preprocessing ensures that the input images are normalized and resized for consistent feature extraction. Specifically, the following steps are performed:
-
Normalization: The input images are normalized with a mean and standard deviation of (0.5, 0.5, 0.5) for each channel.
-
Resizing: Images are resized to a fixed height (H=64) and width (W=640) to maintain a consistent aspect ratio suitable for OCR.
These steps prepare the data for efficient feature extraction and training, ensuring that the model remains robust to variations in input.
Training
vrdOCR is trained on a single NVIDIA GeForce RTX 3060 Ti system running \textbf{Ubuntu 20.04.6} on an 11th Gen Intel i5-11400F (12) @ 4.400GHz processor. We use Python 3.8.19 and PyTorch 2.3.1 for our experiments. The training process employs a multi-loss strategy to optimize the performance of the dual decoding heads: Connectionist Temporal Classification (CTC) and NRTR. This design ensures that the strengths of both mechanisms are utilized, providing a balance between sequence alignment and context modeling.
The following table summarizes the key hyperparameters used during the training process:
| Hyperparameter 1 | Value |
|---|---|
| Learning Rate | 1 x |
| Batch Size | 4 |
| Maximum Characters | 150 |
Loss Functions
The vRD-OCR framework implements a multi-loss approach: CTC loss and NRTR loss. Each loss is weighted to optimize different aspects of the OCR task. The total loss in the multi-loss framework is computed as:
CTC Loss
Connectionist Temporal Classification (CTC) loss is utilized for unsegmented sequence labeling, which is essential in OCR tasks where explicit alignment between input and output sequences is unavailable. The CTC loss function aims to find the most probable alignment between the predicted sequence and the ground truth sequence .
The CTC loss is defined as:
where
Additionally, an optional focal loss mechanism is integrated into the CTC loss to prioritize harder-to-classify samples, especially when the model encounters ambiguous or difficult text. The weighted focal loss is given by:
where
NRTR Loss
The NRTR (Non-Recurrent Transformer) loss is designed for the transformer branch of the network. It employs a cross-entropy loss function to calculate the difference between predicted logits (\mathbf{p}) and the ground truth labels (\mathbf{t}). The NRTR loss with label smoothing is defined as:
where
where
Additionally, the NRTR loss function considers padding tokens by masking out the loss for zero entries in the target sequence using the following mask
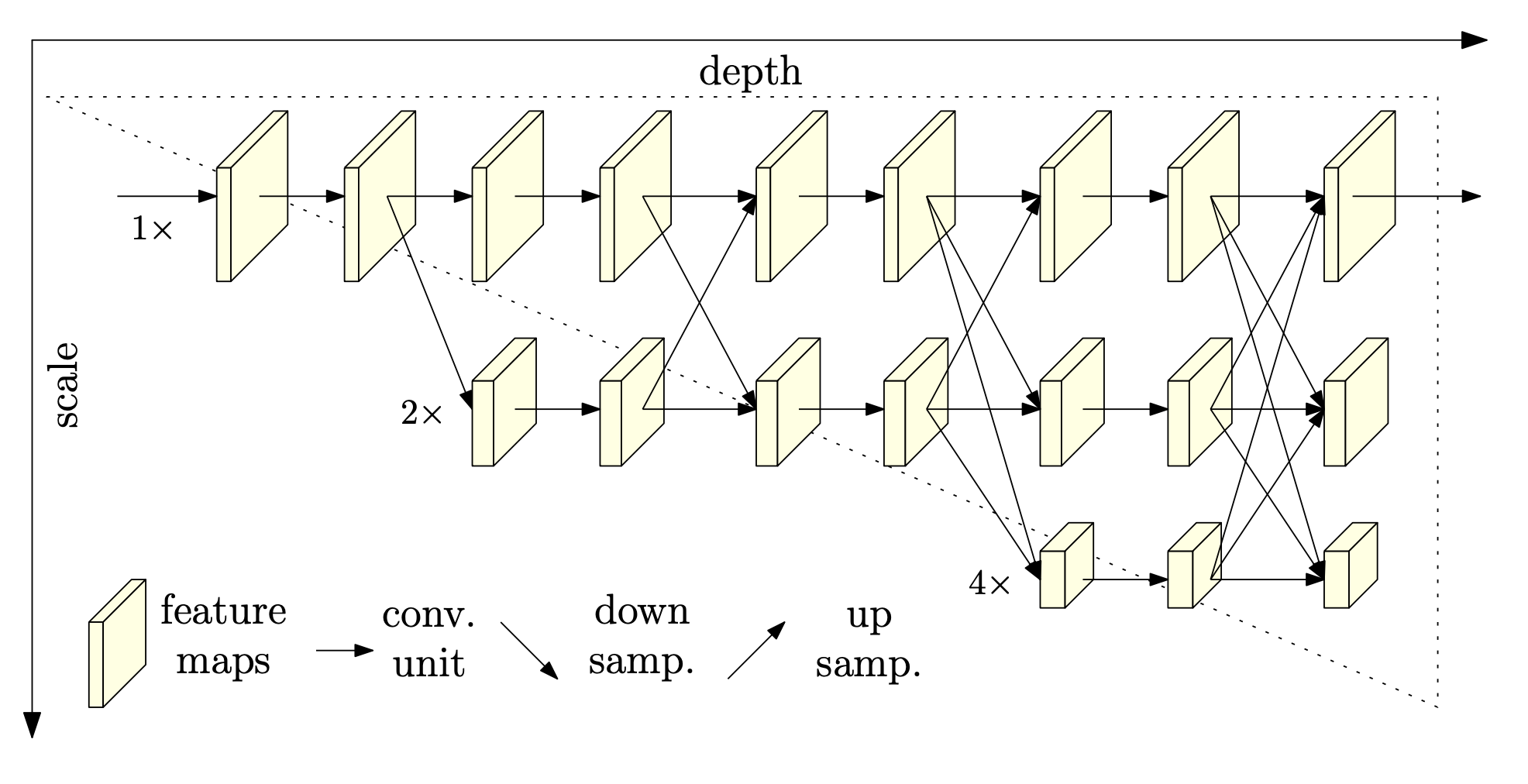
Backbone: High-Resolution Network (HRNet32)
The backbone of the vRD-OCR framework is HRNet [2], a network that preserves high-resolution representations throughout its structure. Unlike conventional CNNs, HRNet retains high-resolution feature maps across all stages. Moreover it fuses multi-resolution representations to capture fine-grained details and global context. This design ensures that spatial information is preserved, which is essential for recognizing complex text layouts and long sentences.
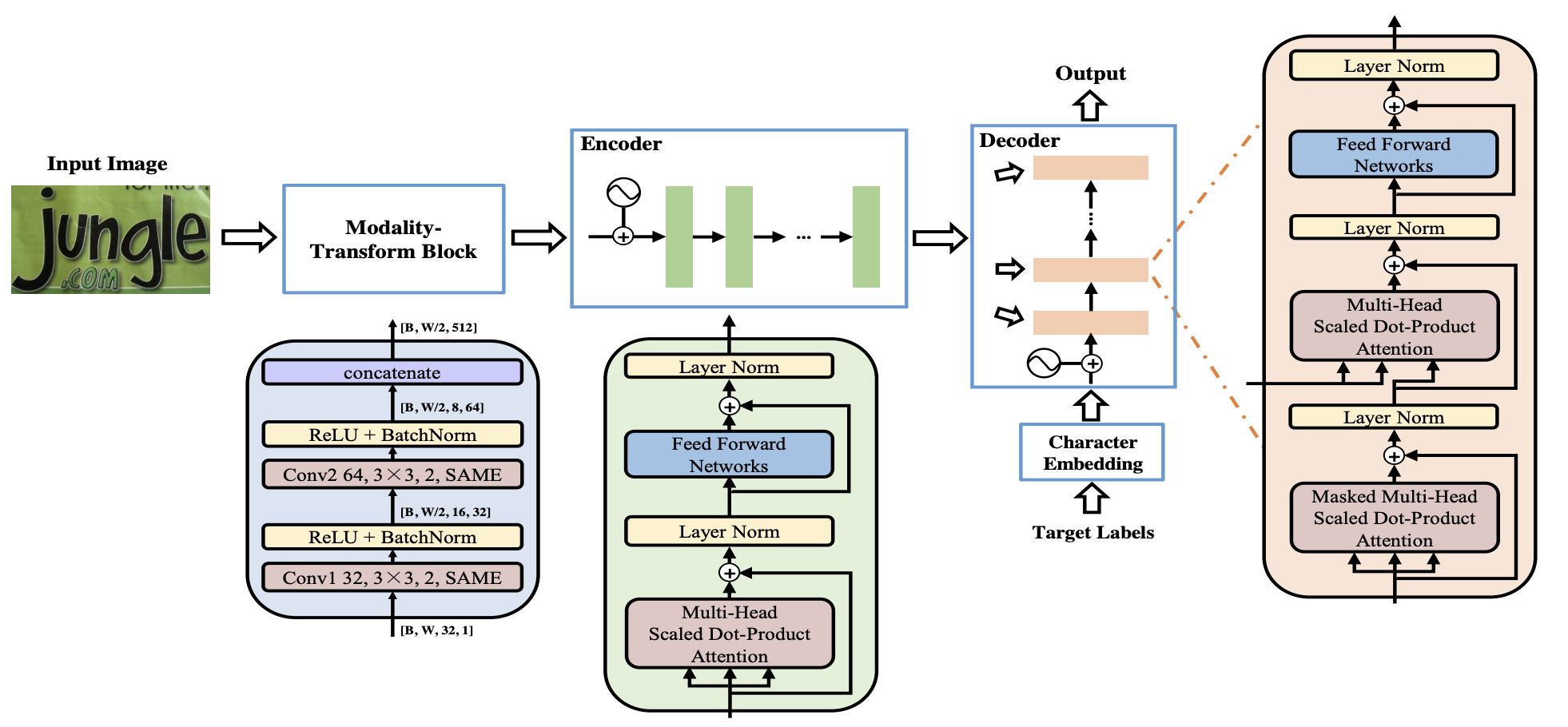
Decoding Heads
CTC Head
The CTC [1] decoding head is optimized for variable-length sequence alignment, making it particularly effective for text recognition tasks. By predicting the most probable alignment between input features and the target text, the CTC head accommodates sequences of varying lengths, ensuring robust performance across diverse document layouts.
.png?Expires=1781588690&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=egM1kW1-~v~WkxqF32dKbJhXSjgySJzdK40l6mWVvfRh3-1PK~ZO9s~4zGsL1vGhN1dZCxG5eRphcAkfZXMq4BH5z8OY86339WJAZwvA9oqvOSIR03SMGjJ9iIyXLJOEBRxFMz3IZ0NV10Fc6lG5BbhEvtMXC-cnF-C3FqZkBaDtzP0D9dnHJXnLM-7GEPQmIslQ8FQ979oak5eb7JnUtlf-mdBxMIGBVrVjKF-R83ur17vVUpGNrt8GOLJqMI-Vb-mWkKUv8k~1xYy4K~4ZXGLMo~8s9vxkY7aS9vxFhLKlwEZ5HzT356g~CI9dVmORhsnokXVqebxgY5DatQ7YaA__)
NRTR Head
The NRTR [4] decoding head leverages a self-attention mechanism to capture long-range dependencies in the text. Its architecture includes a modality-transform block to convert 2D visual features into 1D sequences. It also employs a stacked self-attention layers for parallel processing of text sequences. This design enables the NRTR head to process complex textual structures efficiently, achieving faster training and competitive recognition performance.
Postprocessing
Postprocessing involves decoding the outputs of the CTC head to generate the final recognized text. The decoding process maps the predicted sequences to readable text using dynamic programming.
By combining preprocessing, advanced training techniques, and efficient postprocessing, the vRD-OCR framework delivers state-of-the-art performance in optical character recognition, setting a strong foundation for future advancements in the field.
Dataset
First, a generalized recognition network is trained on synthetic data, created using the open-source tool TextRecognitionDataGenerator [5]. We generate a total of 500,000 images containing random strings from Wikipedia, 400,000 of which are used for training and 100,000 are used for validation. The dataset also consists of images that are randomly skewed and distorted, occurring with probabilities of 0.3 and 0.4, respectively.
The final network is finetuned on
Results
We conducted extensive experimentation using multiple backbone architectures to evaluate their effectiveness in the vRD-OCR model. Each backbone was trained and validated on the same dataset to ensure a fair comparison. The results, presented in Table below, highlight the significant impact of backbone selection on model accuracy. While PP-LCNetv4 and vRD-OCR with Resnet50 backbone provided reasonable performance, HRNet32 backbone emerged as the most effective backbone, achieving an impressive accuracy of
| Model | Backbone | Accuracy |
|---|---|---|
| PP-LCNetV4 | ResNet50 | 63.20% |
| vRD-OCR | ResNet50 | 85.09% |
| vRD-OCR | HRNet | 97.36% |
Discussion
vRD-OCR surpasses several pre-existing OCR technologies by achieving higher accuracy in recognizing long sentences, even in complex layouts or noisy environments. This capability is a result of robust feature extraction architectures, and flexible decoding mechanisms. The combined use of CTC and NRTR losses, provides a scalable solution for OCR. By employing this multihead comprehensive loss strategy, the vRD-OCR model achieves superior performance in recognizing long sentences and complex text layouts, addressing challenges posed by noisy data and document variability. The Connectionist Temporal Classification (CTC) layer allows for precise sequence decoding without explicit character alignment. This feature is particularly advantageous for processing documents with irregular character spacing or variable-length sentences.
The model's accuracy and robustness rely heavily on the availability of large, diverse training datasets. Insufficient or biased data can lead to reduced performance when encountering unseen text styles or formats. To address these limitations and build upon the system's strengths, one avenue that can be explored is Integration of Text Detectors. Incorporating a robust text detector component would allow for end-to-end processing, seamlessly identifying and recognizing text regions in a unified architecture.
Conclusion
In this work, we introduced vRD-OCR, a robust and efficient OCR framework designed to tackle the challenges of recognizing long and complex text in low-quality images. By leveraging state-of-the-art feature extraction backbones such as HRNet32 and employing a dual-head decoding mechanism with CTC and NRTR, the system demonstrated significant improvements in accuracy and adaptability. Extensive experimentation with various backbone architectures validated the effectiveness of our approach, with HRNet32 achieving an impressive accuracy of 97.36%.
References
-
Graves, Alex, Santiago Fern{'a}ndez, Faustino Gomez, and J{"u}rgen Schmidhuber.
"Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks."
Proceedings of the 23rd international conference on Machine learning, 2006, pp. 369–376. -
Sun, Ke, Bin Xiao, Dong Liu, and Jingdong Wang.
"Deep High-Resolution Representation Learning for Human Pose Estimation."
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. -
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
"Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification."
Proceedings of the IEEE International Conference on Computer Vision (ICCV), December 2015. -
Sheng, Fenfen, Zhineng Chen, and Bo Xu.
"NRTR: A No-Recurrence Sequence-to-Sequence Model for Scene Text Recognition."
2019 International Conference on Document Analysis and Recognition (ICDAR), 2019, pp. 781–786. DOI: 10.1109/ICDAR.2019.00130. -
Belval, Claude. "TextRecognitionDataGenerator." 2018. Available at https://github.com/Belval/TextRecognitionDataGenerator. Accessed: 2024-12-30.