![]()
Abstract
Studying abroad is a dream of many individuals all around the world. It provides exposure, enhances one's personality, and fosters cultural interaction, opening doors to new experiences and academic excellence. It is a great opportunity to learn from people with diverse backgrounds. But where to start from? Finding and selecting the right university is not an easy task. Many students struggle with university admissions research, specifically while searching for universities abroad. They face multiple challenges, from navigating different university ranking websites to manually extracting admission details from official university pages while exploring their programs of interest. UniQuestAI utilizes the power of Agentic AI to automate and simplify the university search process tailored to each student's preferences. Not just finding universities, it brings and compiles all the essential information required for admissions and applications to those universities. It addresses a real-world problem with Agentic AI, transforming the process of university admissions research, making it faster, more efficient, and accessible for students worldwide.
Introduction
The world has become a global village, thanks to the widespread availability and connectivity of the internet. Access to information has made it possible for anyone, anywhere, to explore educational opportunities across the globe. With hundreds of thousands of universities offering diverse programs, students have endless possibilities to pursue their academic goals. While university websites provide detailed information about their programs, navigating through them to find relevant details is a daunting task.
University ranking websites, such as US News Rankings, QS Rankings, and Times Higher Education Rankings, help narrow down choices based on university reputation and subject rankings. However, even after shortlisting universities, students must manually visit each university's official website to gather crucial admission-related details - ranging from program requirements and application deadlines to standardized test scores and tuition fees. This process can take weeks or even months, making university admissions research overwhelming and time-consuming.
This is where UniQuestAI comes in. It is an AI-powered multi-agent system designed to automate and streamline the entire university search and admissions research process. By intelligently fetching and compiling accurate, up-to-date admission details, UniQuestAI saves students countless hours of manual work - allowing them to focus on what truly matters - preparing strong applications and securing their dream university.
Technologies Used
- Streamlit - Frontend: Streamlit is an open-source Python library to build minimalist user interfaces for web applications. It helps build interactive data apps quickly.
- FastAPI - Backend: FastAPI is a modern, high performance, web framework for building APIs with Python.
- Agno - Agentic AI Framework: Agno is an open-source framework to build high performance multimodal agentic systems with memory, knowledge, and tools.
User Inputs
- Discipline (Field of Study)
- Education Level (Bachelors | Masters | PhD)
- Location (Country, Default: Worldwide)
- Maximum Number of Universities
Output
Universities information organized in an Excel format, including:
General Information
- University Name
- Location (City, Country)
- Status (Public | Private)
- Founded (Year)
Rankings
- US News Ranking
- QS Ranking
- Times Higher Education Ranking
Program Details
- Program (Bachelors, Masters, PhD)
- Program Begins (Month, Year)
- GRE Requirement
- Minimum TOEFL Score
- Minimum IELTS score
- Duolingo Accepted? (Yes/No)
- English Proficiency Waiver Availability
Application & Fees
- Application Fee ($)
- Application Fee Waiver Availability
- Tuition | Stipend Details
Important Dates
- Application Opens
- Application Deadline
Additional Information
- Office Contact and Email (Graduate/Undergraduate Admissions)
- Acceptance Rate
- Required Documents
- Number of Letters of Recommendation (LoRs)
- Additional Notes
- Program Link
All the above information is essential for the applicants to effectively prepare and submit their applications for different universities.
System Design
UniQuestAI is a multi-agent collaborative system where four specialized agents work together in a structured, agentic workflow. Each agent is designed with a specific goal, ensuring it operates in a focused and efficient manner without unnecessary distractions. The workflow is sequential, meaning the output of one agent serves as the input for the next, enabling a smooth and systematic execution of tasks.
Here is a high level architectural diagram of this multi-agent collaborative system:
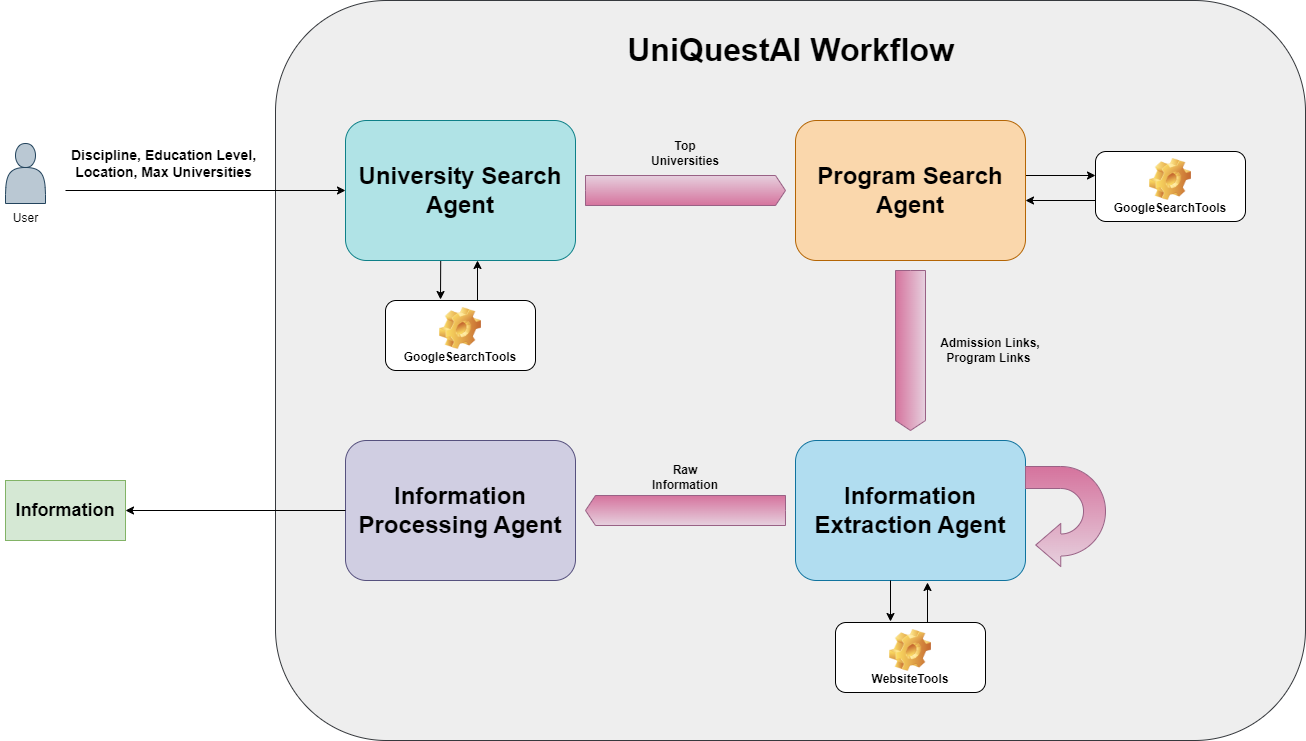
Agents
1. University Search Agent
This agent searches a list of top universities based on their rankings from the world university ranking websites (US News Ranking, QS Ranking, and Times Higher Education Ranking) based on the following four user preferences:
- Discipline
- Education level
- Location
- Maximum universities
LLM
It uses Llama 3.3 70B Instruct Turbo Free from Together API as a large language model.
Tools
It uses GoogleSearchTools in the Agno Toolkit to search for the top universities from ranking websites.
2. Program Search Agent
This agent searches for the links to admission requirements and program information pages on official university websites for the universities shortlisted by the University Search Agent. It makes sure that the links are authentic, latest, and are according to the user preferences.
LLM
It uses Llama 3.3 70B Instruct Turbo Free from Together API as a large language model.
Tools
It uses GoogleSearchTools in the Agno Toolkit to search for the required links from official university websites.
3. Information Extraction Agent
This agent searches and extracts real time information from the admissions and program specific page links found for each university by the Program Search Agent.
LLM
It uses Llama 3.3 70B Instruct Turbo Free from Together API as a large language model.
Tools
It uses WebsiteTools from the Agno Toolkit to crawl and extract information from the admission requirements and program information pages on an official university website.
4. Information Processing Agent
This agent organizes and processes the information extracted by the Information Extraction Agent, and converts it into JSON format for displaying at the frontend and saving into an Excel file.
LLM
It uses Llama 3.3 70B Instruct Turbo Free from Together API as a large language model.
Implementation
We'll use the Agno Framework to build this multi-agent collaborative system. The project structure is as follows:
Project Structure
uniquest-ai/ # Main project folder │── frontend/ # Frontend directory │ ├── app.py # Streamlit application │ │── backend/ # Backend directory │ ├── main.py # FastAPI backend │ ├── utils.py # Utility functions │ │ ├── agents/ # Agents folder │ │ ├── university_search_agent.py │ │ ├── program_search_agent.py │ │ ├── information_extraction_agent.py │ │ ├── information_processing_agent.py │ │ │ ├── workflows/ # Workflows folder │ │ ├── uniquest_workflow.py │ │── requirements.txt # Dependencies │── .env # Environment variables │── LICENSE # License file │── README.md
Setting up the environment
Create a new virtual environment and install the dependencies using requirements.txt file.
- requirements.txt
fastapi uvicorn streamlit pandas openpyxl agno requests beautifulsoup4 googlesearch-python pycountry sqlalchemy
- .env
Create a .env file and add your API key.
TOGETHER_API_KEY="your_api_key_here"
FRONTEND
The frontend of UniQuestAI looks like this:
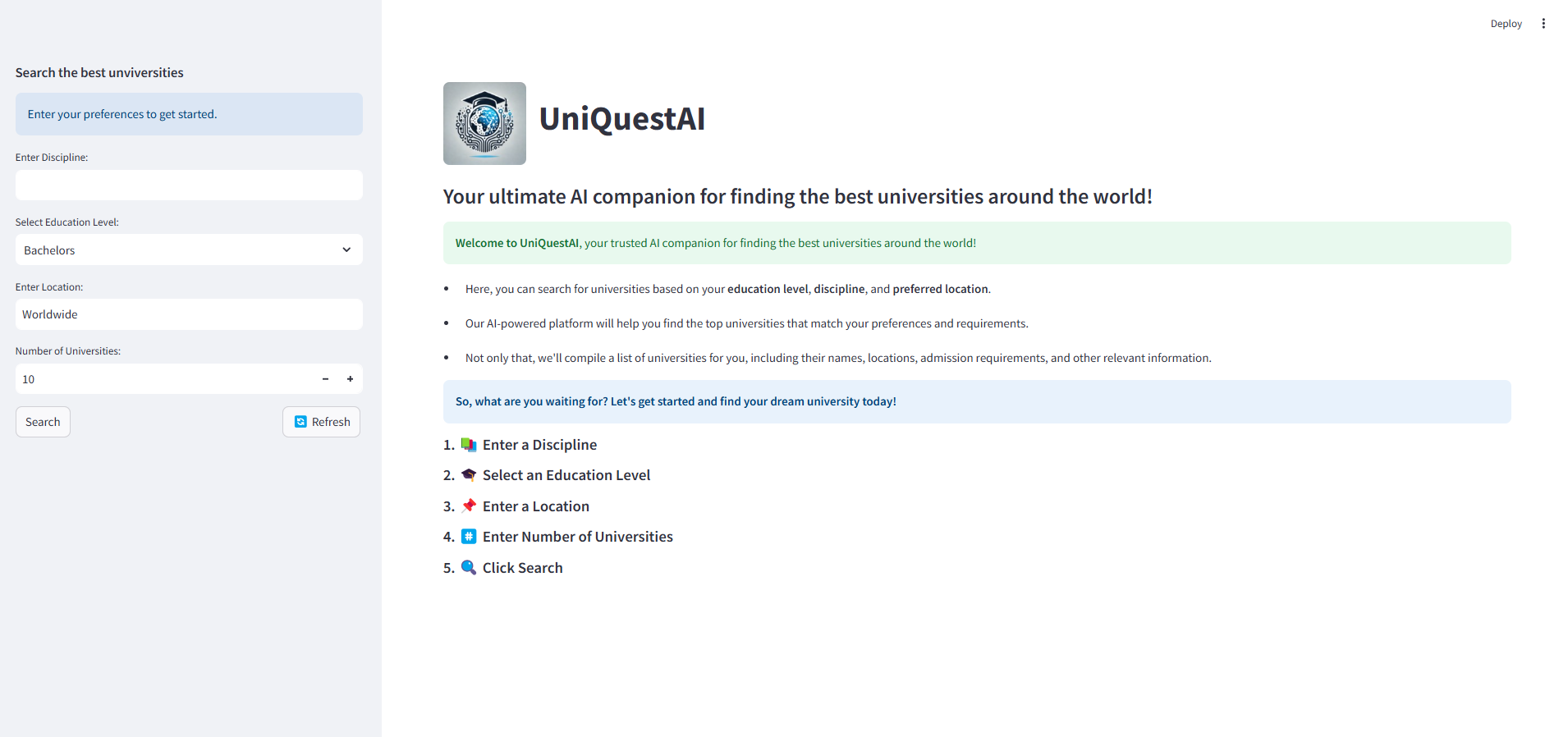
- app.py
This is the main interface of the application built using Streamlit. It provides the user input fields in the sidebar at the left. The list of top universities would be displayed at the right in a tabular format along with their detailed information as shown below.

import streamlit as st import requests import json import pandas as pd import os API_URL = "http://127.0.0.1:8000" st.set_page_config(page_title="UniQuestAI", layout="wide") # Inject custom CSS to set the width of the sidebar st.markdown( """ <style> section[data-testid="stSidebar"] { width: 500px !important; } </style> """, unsafe_allow_html=True, ) # Initialize session state for results if "result_json" not in st.session_state: st.session_state.result_json = None # Initialize session state for research topic if "discipline" not in st.session_state: st.session_state.discipline = "" # Initialize session state for max papers if "education_level" not in st.session_state: st.session_state.education_level = "" # Initialize session state for selected paper if "location" not in st.session_state: st.session_state.location = "Worldwide" # Initialize session state for chat history if "max_universities" not in st.session_state: st.session_state.max_universities = 10 # Create a two-column layout col1, col2 =st.columns([1, 11]) with col1: st.image("../images/uniquest_logo.png", width=150) with col2: st.title("UniQuestAI") # Display the main title and search form in the sidebar with st.sidebar: st.subheader("Search the best unviversities") st.info("Enter your preferences to get started.") # User input fields discipline = st.text_input("Enter Discipline:") education_level = st.selectbox("Select Education Level:", ["Bachelors", "Masters", "PhD"]) location = st.text_input("Enter Location:", "Worldwide") max_universities = st.number_input("Number of Universities:", 5, 50, 10) col_btn1, col_btn2 = st.columns([3, 1]) with col_btn1: if st.button("Search"): if discipline: st.session_state.discipline = discipline st.session_state.education_level = education_level st.session_state.location = location st.session_state.max_universities = max_universities try: with st.spinner("Searching for top universities..."): st.warning("It may take a few minutes for the search to complete. Please be patient!") response = requests.post(API_URL+"/search/", json={"discipline": discipline, "education_level": education_level, "location": location, "max_universities": max_universities}) if response.status_code != 200: st.error("Error: Invalid response from server.") st.stop() result_decoded = response.content.decode("utf-8") st.session_state.result_json = json.loads(result_decoded) # Store in session state except json.JSONDecodeError: st.error("Error: Received an unreadable response from the server.") st.stop() except requests.exceptions.RequestException: st.error("Error: Could not connect to the server.") st.stop() with col_btn2: if st.button("🔄 Refresh"): st.session_state.result_json = None # Clear stored results st.session_state.discipline = "" # Clear stored discipline st.session_state.education_level = "" # Clear stored education level st.session_state.location = "Worldwide" # Clear stored location st.session_state.max_universities = 10 # Reset max universities st.rerun() # Force a full page refresh # Display results if available if st.session_state.result_json: st.title(f"Top Universities for {discipline} ({education_level}) in {location if location else 'the World'}") # Display the results # st.write(st.session_state.result_json.get("response", "No results to display.")) # If an excel path is provided in the response, display download option if "excel_path" in st.session_state.result_json: excel_path = st.session_state.result_json["excel_path"] excel_path = os.path.join("../backend", excel_path) filename = f"Top_Universities_{education_level}_{discipline}_{location}.xlsx" # Create a row layout for success message + download button col_success, col_download = st.columns([11, 1]) with col_success: st.success("Top Universities Found!") with col_download: st.download_button(label="📥 Download", data=open(excel_path, "rb").read(), file_name=filename, mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet") # Display universities information response = st.session_state.result_json.get("response") processed_info = response["processed_info"] json_info = json.loads(processed_info) universities = json_info.get("universities", []) if universities: # Convert the list of university dictionaries into a Pandas DataFrame df = pd.DataFrame(universities) df.rename(columns={"name":"University Name", "location":"Location", "status":"Status", "founded":"Founded", "us_news_ranking":"US News Ranking", "qs_ranking":"QS Ranking", "times_ranking":"THE Ranking", "program":"Program", "program_begins":"Program Begins", "gre_requirement":"GRE Requirement", "toefl_score":"TOEFL Score", "ielts_score":"IELTS Score", "duolingo_accepted":"Duolingo Accepted?", "english_proficiency_waiver":"English Proficiency Waiver", "application_fee":"Application Fee", "application_deadline":"Application Deadline", "office_contact_and_email":"Office Contact & Email", "acceptance_rate":"Acceptance Rate", "required_documents":"Required Documents", "number_of_lors":"Number of LORs", "additional_notes":"Additional Notes", "link":"Program Link"}, inplace=True,) st.dataframe(df) for i, university in enumerate(universities): st.subheader(f"🎓 {i+1}. {university['name']}") st.markdown(f"**📍 Location:** {university['location']}") st.markdown(f"**📚 Status:** {university['status']}") st.markdown(f"**📆 Founded:** {university['founded']}") st.markdown(f"**📈 US News Ranking:** {university['us_news_ranking']}") st.markdown(f"**📈 QS Ranking:** {university['qs_ranking']}") st.markdown(f"**📈 Times Higher Education Ranking:** {university['times_ranking']}") st.markdown(f"**📚 Program:** {university['program']}") st.markdown(f"**📅 Program Begins:** {university['program_begins']}") st.markdown(f"**📝 GRE Requirement:** {university['gre_requirement']}") st.markdown(f"**📝 TOEFL Score:** {university['toefl_score']}") st.markdown(f"**📝 IELTS Score:** {university['ielts_score']}") st.markdown(f"**📝 Duolingo Accepted?:** {university['duolingo_accepted']}") st.markdown(f"**📝 English Proficiency Waiver:** {university['english_proficiency_waiver']}") st.markdown(f"**💸 Application Fee:** {university['application_fee']}") st.markdown(f"**💸 Application Fee Waiver:** {university['application_fee_waiver']}") st.markdown(f"**💸 Tuition|Stipend:** {university['tuition_stipend']}") st.markdown(f"**📅 Application Opens:** {university['application_opens']}") st.markdown(f"**📅 Application Deadline:** {university['application_deadline']}") st.markdown(f"**📞 Office Contact and Email:** {university['office_contact_and_email']}") st.markdown(f"**📝 Acceptance Rate:** {university['acceptance_rate']}") st.markdown(f"**📝 Required Documents:** {university['required_documents']}") st.markdown(f"**📝 Number of LoRs:** {university['number_of_lors']}") st.markdown(f"**📝 Additional Notes:** {university['additional_notes']}") st.markdown(f"**📝 Link to the Program:** {university['link']}") st.divider() else: st.error("No universities found!") else: st.subheader("Your ultimate AI companion for finding the best universities around the world!") st.success("**Welcome to UniQuestAI**, your trusted AI companion for finding the best universities around the world!") st.markdown("- Here, you can search for universities based on your **education level**, **discipline**, and **preferred location**.") st.markdown("- Our AI-powered platform will help you find the top universities that match your preferences and requirements.") st.markdown("- Not only that, we'll compile a list of universities for you, including their names, locations, admission requirements, and other relevant information.") st.info("**So, what are you waiting for? Let's get started and find your dream university today!**") todo = ["📚 Enter a Discipline", "🎓 Select an Education Level", "📌 Enter a Location", "#️⃣ Enter Number of Universities", "🔍 Click Search"] st.markdown("\n".join([f"##### {i+1}. {item}" for i, item in enumerate(todo)]))
BACKEND
-
main.py
-
search- This endpoint searches for the top universities through Uniquest workflow and saves the response in an Excel file.
from fastapi import FastAPI from pydantic import BaseModel from agno.agent import RunResponse from workflows.uniquest_workflow import uniquest_workflow from utils import save_info_to_excel app = FastAPI() class SearchRequest(BaseModel): discipline: str education_level: str location: str max_universities: int = 5 @app.post("/search/") async def search_universities(request: SearchRequest): # Execute the workflow # Returns a RunResponse object containing the generated content response: RunResponse = uniquest_workflow.run(discipline=request.discipline, education_level=request.education_level, location=request.location, max_universities=request.max_universities) if response: print("Response:", response.content) # Save the universities info to an Excel file excel_path = save_info_to_excel(response.content["processed_info"], request.discipline, request.education_level, request.location) return {"message": "Top universities found!", "response": response.content, "excel_path": excel_path} else: return {"error": "No universities found"}
- utils.py
This file contains a helper function to save universities information into an Excel file.
import json import pandas as pd import os def save_info_to_excel(json_data, discipline, education_level, location): """ Save information about universities to an Excel file." Args: json_data (dict): A dictionary containing information about universities. discipline (str): The discipline searched for. education_level (str): The education level searched for. location (str): The location searched for. Returns: str: The name of the saved Excel file. """ save_dir = "excel_files" if not os.path.exists(save_dir): os.makedirs(save_dir) file_path = os.path.join(save_dir, f"Top_Universities_{education_level}_{discipline}_{location}.xlsx") # Ensure json_data is a dictionary if isinstance(json_data, str): data = json.loads(json_data) else: data = json_data # Convert to a DataFrame df = pd.DataFrame(data["universities"]) # Save to an Excel file df.to_excel(file_path, index=False) print(f"Information saved successfully to {file_path}") return file_path
- university_search_agent.py
This is the first agent in the workflow. It searches for the top universities based on user preferences from university ranking websites using GoogleSearchTools.
from agno.agent import Agent, RunResponse from agno.models.together import Together from agno.tools.googlesearch import GoogleSearchTools from agno.utils.pprint import pprint_run_response from dotenv import load_dotenv import os load_dotenv() # Define the university search agent university_search_agent = Agent( name="university-search-agent", model=Together(id="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=os.getenv("TOGETHER_API_KEY")), tools=[GoogleSearchTools()], description= ''' You are a university search agent that will search for the top universities based on a given discipline from top university ranking websites. You will generate a list of universities with their names, rankings, and official website links based on the given preferences. ''', instructions=[ "Search the following university ranking websites one by one based on the given preferences:", "Preferences include discipline, education level, location, and maximum number of universities.", "US News Rankings: https://www.usnews.com", "QS Rankings: https://www.topuniversities.com", "Times Higher Education Rankings: https://www.timeshighereducation.com", "If the location is not specified, consider all locations.", "Search for the best universities for the given discipline and education level from each ranking website.", "The rankings MUST be according to the latest information available on the ranking websites", "Select the top ranked universities from the extracted information from each ranking website.", "The response MUST be in the following JSON format:", "{", '"universities": [', '"https://university1.com",', '"https://university2.com",', '"https://university3.com",', '"https://university4.com",', '"https://university5.com",', "]", '"discipline": [DISCIPLINE],', '"education_level": [EDUCATION_LEVEL],', "}", "The response MUST NOT include ranking websites as universities.", "The response MUST only include top universities found from the ranking websites.", "The response MUST be in proper JSON format with keys and values in double quotes.", "The final response MUST not include any other text or anything else other than the JSON response." ], markdown=True, show_tool_calls=True, debug_mode=True )
- program_search_agent.py
This is the second agent in the workflow which searches for the admission and program page links for each university found by the university search agent using GoogleSearchTools.
from agno.agent import Agent, RunResponse from agno.models.together import Together from agno.tools.googlesearch import GoogleSearchTools from agno.utils.pprint import pprint_run_response from dotenv import load_dotenv import os load_dotenv() # Define the link browsing agent program_search_agent = Agent( name="program-search-agent", model=Together(id="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=os.getenv("TOGETHER_API_KEY")), tools=[GoogleSearchTools()], description= ''' You are a program search agent that will search for the admission and program page links for a given list of universities based on the given preferences. You will generate a list of universities with their admission and program page links in JSON format. ''', instructions=[ "Search the given university websites one by one based on the given preferences", "For each university, search for the admission page link based on the given education level.", "For each university, search for the program page link based on the given discipline and education level.", "Do NOT generate links. Instead, search them directly from the official university website.", "The links MUST depict the latest admissions and program information available on the university website.", "Do NOT retrieve links having old or outdated admissions and program information.", "If you don't find a specific program in a university, search for the most similar or closest related program page link.", "Validate the links by ensuring they do NOT return 404 errors or redirects to unrelated pages.", "Double-check that the links are correct and functional.", "The response MUST be in the following JSON format:", "{" " 'links': [", " {", " 'university': '[Official website link]',", " 'admission': '[Admission page link]',", " 'program': '[Program page link]'", " }", " {...}", " ]", "}", "The response MUST be in proper JSON format with keys and values in double quotes.", "The final response MUST not include any other text or anything else other than the JSON response." ], markdown=True, show_tool_calls=True, debug_mode=True )
- information_extraction_agent.py
This is the third agent in the Uniquest workflow which works in a loop. The workflow calls this agent iteratively to extract information for each link found through the Program Search Agent. This agent uses WebsiteTools to extract the content from each link.
from agno.agent import Agent, RunResponse from agno.models.together import Together from agno.tools.website import WebsiteTools from agno.utils.pprint import pprint_run_response from dotenv import load_dotenv import os load_dotenv() # Define the information extraction agent info_extraction_agent = Agent( name="info-extraction-agent", model=Together(id="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=os.getenv("TOGETHER_API_KEY"), max_tokens=500), tools=[WebsiteTools()], description= ''' You are an information extraction agent that will search and extract information from a given link. ''', instructions=[ "Search the given link for admissions and program related information:", "Find whichever of the below information is available in the given link.", "University Name: [Name of the University]", "Location: [City, Country]", "Public/Private: [Public/Private]", "Founded (Year): [Year of Foundation]", "US News Ranking: [Ranking by US News]", "QS Ranking: [Ranking by QS]", "Times Higher Education Ranking: [Ranking by Times Higher Education]", "Program: [Program Name]", "Program Begins: [Month and Year]", "GRE Requirement: [GRE Required/Not Required]", "Min TOEFL Score: [Min TOEFL Score]", "Min IELTS Score: [Min IELTS Score]", "Duolingo Accepted?: [Yes/No]", "English Proficiency Waiver: [Waiver Available/Not Available]", "Application Fee: [Application Fee]", "Application Fee Waiver: [Waiver Available/Not Available]", "Tuition|Stipend: [Tuition|Stipend Available/Not Available]", "Application Opens: [Month and Year]", "Application Deadline: [Deadline]", "Office Contact and Email (Graduate | Undergraduate): [Contact and Email]", "Acceptance Rate: [Acceptance Rate]", "Required Documents: [List of Required Documents]", "Number of LoRs: [Number of LoRs]", "Additional Notes (if any): [Notes of any additional important information]", "Link to the Program: [Link to the Program - MUST be a correct link to the program page]", "Do NOT generate information. Only extract information from the given link." ], markdown=True, show_tool_calls=True, debug_mode=True )
- information_processing_agent.py
This is the fourth and the last agent in the workflow which processes the information extracted by the Information Extraction Agent into JSON format to be displayed at frontend and saved as an Excel file for downloading.
from agno.agent import Agent, RunResponse from agno.models.together import Together from agno.utils.pprint import pprint_run_response from dotenv import load_dotenv import os load_dotenv() # Define the information processing agent info_processing_agent = Agent( name="info-search-agent", model=Together(id="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=os.getenv("TOGETHER_API_KEY")), description= ''' You are an information processing agent that structures the information about universities' admissions and programs in JSON format. ''', instructions=[ "Structure the information received about universities' admissions and programs in JSON format.", "Important: Your final response MUST be in JSON format with the following structure:", "{" "universities: [" "{" " 'name': 'Name of the University'," " 'location': 'Location[City, Country] of the University'," " 'status': 'Public or Private'," " 'founded': 'Year of Foundation'," " 'us_news_ranking': 'Ranking by US News'," " 'qs_ranking': 'Ranking by QS'," " 'times_ranking': 'Ranking by Times Higher Education'," " 'program': 'Program Name'," " 'program_begins': 'Month and Year'," " 'gre_requirement': 'GRE Required/Not Required'," " 'toefl_score': 'Min TOEFL Score'," " 'ielts_score': 'Min IELTS Score'," " 'duolingo_accepted': 'Yes/No'," " 'english_proficiency_waiver': 'Waiver Available/Not Available'," " 'application_fee': 'Application Fee'," " 'application_fee_waiver': 'Waiver Available/Not Available'," " 'tuition_stipend': 'Tuition/Stipend Available/Not Available'," " 'application_opens': 'Month and Year'," " 'application_deadline': 'Deadline'," " 'office_contact_and_email': 'Contact and Email'," " 'acceptance_rate': 'Acceptance Rate'," " 'required_documents': 'List of Required Documents'," " 'number_of_lors': 'Number of LoRs'," " 'additional_notes': 'Notes of any additional important information'," " 'link': 'Link to the Program'" "}," "{...}" "]" "}", "The response MUST be in proper JSON format with keys and values in double quotes.", "The final response MUST not include anything else other than the JSON response." ], markdown=True, show_tool_calls=True, debug_mode=True )
- uniquest_workflow.py
This is the main workflow of the agentic AI application. It calls the agents one by one feeding the output of one into the input of the other agent to achieve its end goal.
from agno.agent import Agent from agno.workflow import Workflow, RunResponse, RunEvent from agno.storage.workflow.sqlite import SqliteWorkflowStorage from agno.utils.pprint import pprint_run_response from agno.utils.log import logger import json from agents.university_search_agent import university_search_agent from agents.program_search_agent import program_search_agent from agents.information_extraction_agent import info_extraction_agent from agents.information_processing_agent import info_processing_agent class UniquestWorkflow(Workflow): university_search_agent: Agent = university_search_agent program_search_agent: Agent = program_search_agent info_extraction_agent: Agent = info_extraction_agent info_processing_agent: Agent = info_processing_agent def run(self, discipline: str, education_level: str, location: str, max_universities: int = 5) -> RunResponse: logger.info(f"Generating a list of top {max_universities} universities for a {education_level} in {discipline}") # Step 1: Generate a list of top universities for the given education level, discipline and location prompt = f"Search for {max_universities} top universities for a {education_level} in {discipline} based in {location}." top_universities: RunResponse = self.university_search_agent.run(prompt) # If no universities are found, end the workflow if top_universities is None: return RunResponse( event=RunEvent.workflow_completed, content=f"Sorry, could not find any universities for {education_level} in {discipline}", ) print("Top universities:", top_universities.content) # Step 2: Find the admission and program links for each university prompt = f"Search for the admission and program page links for a {education_level} in {discipline} for the following universities: {top_universities.content}" links: RunResponse = self.program_search_agent.run(prompt) if links is None: return RunResponse( event=RunEvent.workflow_completed, content="Sorry, could not find the admission and program links for the universities.", ) print("Links:", links.content) links_content = json.loads(links.content) links = links_content["links"] # Step 3: Extract the information from each admission and program link for each university information = [] for link in links: logger.info(f"Extracting information for {link['university']}") # Initialize with default values admission_info_content = "No information found" program_info_content = "No information found" try: prompt = f"Search for the admission and program related information of {link["university"]} from the following link: {link['admission']}." admission_info: RunResponse = self.info_extraction_agent.run(prompt) admission_info_content = admission_info.content except Exception as e: logger.error(f"Error extracting admission information for {link['university']}: {e}") try: prompt = f"Search for the admission and program related information of {link['university']} from the following link: {link['program']}." program_info: RunResponse = self.info_extraction_agent.run(prompt) program_info_content = program_info.content except Exception as e: logger.error(f"Error extracting program information for {link['university']}: {e}") information.append({"university":link["university"], "admission_info": admission_info_content, "program_info": program_info_content}) print("Information:", information) # Step 4: Process the information and structure it in JSON format. prompt = f"Process the following information: {information}" processed_info: RunResponse = info_processing_agent.run(prompt) if processed_info is None: return RunResponse( event=RunEvent.workflow_completed, content="Sorry, could not process the information.", ) print("Processed information:", processed_info.content) return RunResponse( event=RunEvent.workflow_completed, content={"universities": top_universities.content, "links": links, "information": information, "processed_info": processed_info.content}, ) # Initialize the Uniquest workflow uniquest_workflow = UniquestWorkflow( session_id="find-top-universities", storage=SqliteWorkflowStorage( table_name="generate_uniquest_workflows", db_file="workflows/db/workflows.db", ), )
DEMO - UniQuestAI
Here is a demonstration of using UniQuestAI:
Note: The whole agentic workflow takes a few minutes to complete, therefore, the demo only shows the output generated after the search has been completed.
Running UniQuestAI
- Clone the repository from GitHub. The link has been provided in the References section.
- Navigate to the backend folder and start the FastAPI server:
cd backend uvicorn main:app --reload
- Navigate to the frontend folder and start the Streamlit application:
cd frontend streamlit run app.py
Access the application through the following link.
http://localhost:8501
Challenges Faced
1. Selecting Top Universities
- Challenge - University ranking websites have strict protocols due to which we cannot directly scrape information from them. Many of these sites actively block automated requests. It is also ethically not correct to scrape information without the consent of these websites. This posed a challenge to extract the top universities ranked in specific disciplines.
- Soluion - We used GoogleSearchTools available in the Agno toolkit. This allowed us to retrieve ranking data from top university ranking websites without violating ethical guidelines.
2. Finding Correct Programs Links
- Challenge - Scanning entire university websites for admissions and program details is impractical and inefficient. We needed a way to find relevant pages without extracting unnecessary data.
- Solution - Instead of scraping the entire websites, we focused on finding and extracting URLs specifically related to admissions and program details. GoogleSearchTools from the Agno Toolkit helped us efficiently retrieved these targeted links, significantly improving the accuracy and efficiency of data extraction.
3. Verification of Links
- Challenge - Large language models (LLMs) tend to hallucinate and generate incorrect links.
- Solution -To prevent this, we explicitly instructed the LLMs not to generate links themselves. Additionally, we instructed them to perform link validation checks to ensure that all retrieved URLs are correct and functional.
4. Token Usage Limit
- Challenge - The API we use has a strict token limit, making it impossible to extract all information simultaneously.
- Solution: To address this, we optimized our system by iteratively processing links - extracting information one link at a time and then aggregating the results before feeding them into the information processing agent. This approach allowed us to stay within the token limits while maintaining efficiency.
5. Model and Tool Selection
- Challenge - Selection of the right models and tools was critical for this application. We couldn't use paid models because of cost constraints. Free models often come with token limitations. Additionally, extracting structured content from websites required specialized tools.
- Solution - After trying and testing various APIs available in the Agno framework, we selected Together API for LLM-based tasks, as it provided the best balance between performance and token usage. For content extraction, we utilized WebsiteTools from the Agno framework, which effectively handled data retrieval from university websites.
6. Ensuring Correct Information
- Challenge - LLMs are not always reliable in retrieving factual, real-time data. We needed to minimize errors and prevent hallucinations while extracting university admission details.
- Solution - We implemented Reflection and ReAct patterns to guide the LLMs in verifying and cross-checking extracted data before presenting it. These techniques helped ensure that the information retrieved was accurate, up-to-date, and directly sourced from university websites.
Important Considerations
- In a multi-agent system, each agent should remain focused on a single task to maximize efficiency and avoid unnecessary complexity.
- Human-in-the-loop is essential - while UniQuestAI streamlines the search process, applicants are strongly advised to visit the official university websites and verify the information from the provided links before making any decisions.
- Effective prompt engineering is crucial for optimizing agent performance. Clearly defining an agent's role, description, and instructions ensures accurate and relevant outputs.
Future Work
- Currently, UniQuestAI retrieves top-ranked universities based on user preferences. Future iterations can introduce more options to further narrow down the searches based on specific needs.
- Support for mid-tier and lower-ranked universities can be added, allowing a broader range of institutions to be explored.
- Filtering universities by status (Public vs. Private) can be incorporated, giving users more control over their selections.
Conclusion
UniQuestAI is an agentic AI application designed to help students worldwide find top universities based on their preferences. It serves as an excellent starting point for those exploring global academic opportunities. The system provides tailored recommendations for both undergraduate and graduate applicants. It leverages the agentic patterns and workflows to automate the whole process of information extraction and compilation - a task that is otherwise time consuming and tedious. With this system, students can focus on preparing strong university applications and gathering essential documentation instead of spending their precious time searching for requirements.