Image captioning is a pivotal task in the intersection of computer vision and natural language processing, aimed at generating descriptive captions for images. This research introduces a novel VisionEncoderDecoder framework that integrates the Vision Transformer (ViT) for image feature extraction with GPT-2 for language generation. By leveraging ViT’s self-attention mechanism for capturing intricate visual features and GPT-2’s robust language modeling capabilities, the proposed framework surpasses traditional LSTM-based models in caption quality.
The model is trained on the MS COCO dataset and demonstrates significant improvements in evaluation metrics, including BLEU, ROUGE, and METEOR scores. These results underline the framework's potential for advancements in real-time image captioning and multilingual applications. Future work will focus on extending this approach to encompass broader datasets and diverse linguistic contexts.
Index Terms — Image Captioning, Vision Transformer, GPT-2, VisionEncoderDecoder, Self-Attention, Natural Language Processing, MS COCO, BLEU, ROUGE, METEOR, Real-time Captioning.
Image captioning, a fundamental task at the intersection of computer vision and natural language processing (NLP), involves generating descriptive captions for images. This task bridges the gap between visual understanding and language generation, with broad applications in accessibility tools, content tagging, and AI-driven communication systems [1].
Traditional approaches, such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, often face challenges like limited context understanding, difficulty handling long-term dependencies, and out-of-vocabulary issues [1][2]. To address these limitations, this research introduces a VisionEncoderDecoder framework that integrates the Vision Transformer (ViT) for image feature extraction and GPT-2 for text generation.
The ViT, with its self-attention mechanism, excels at capturing intricate visual details, while GPT-2 generates contextually rich and coherent captions [3][4]. The proposed model is trained and evaluated on the MS COCO dataset, demonstrating notable improvements in caption quality, as reflected by evaluation metrics such as BLEU, ROUGE, and METEOR [3][4].
Future work aims to extend this approach for real-time image captioning and broader applications, paving the way for advancements in dynamic AI-powered systems [3].
The field of image captioning has evolved significantly, transitioning from traditional RNN and CNN-LSTM architectures to more advanced transformer-based approaches [1][2].
RNN and CNN-LSTM Models:
Early image captioning models employed Convolutional Neural Networks (CNNs) for feature extraction and Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks for sequential caption generation. These models generated captions word-by-word but faced challenges, including difficulty managing long-term dependencies, limited scalability, and struggles to produce contextually accurate captions [1][2].
Attention Mechanisms:
To address these limitations, attention mechanisms were introduced. These mechanisms enabled models to focus dynamically on specific regions of the image most relevant to the word being generated at any given time. This capability significantly enhanced the coherence and contextual relevance of captions [1][3].
Transformer-Based Approaches:
Recent advancements have introduced Vision Transformers (ViT), which treat images as sequences of patches. ViT’s self-attention mechanism captures global relationships across the image, improving efficiency and enabling parallel processing. This transformer-based approach outperforms traditional CNN-based models in handling complex visual data and generating accurate image representations [3][4].
Language Modeling with Transformers:
The integration of GPT-2, a pretrained transformer-based language model, has further advanced caption generation. GPT-2 excels at producing fluent, coherent, and contextually appropriate text, even when encountering unfamiliar or out-of-training vocabulary. Its vast language knowledge contributes to generating captions that align seamlessly with the visual content [2][4].
ViT-GPT-2 Integration:
The combination of Vision Transformer (ViT) and GPT-2 leverages the strengths of both models: ViT’s ability to extract rich image features and GPT-2’s powerful language generation capabilities. This integration enhances visual understanding and caption quality, addressing the shortcomings of earlier architectures. The ViT-GPT-2 framework demonstrates significant performance improvements on datasets like MS COCO, outperforming traditional methods in caption quality, coherence, and alignment with visual content [4].
Methodology
The proposed methodology integrates Vision Transformer (ViT) and GPT-2 within a VisionEncoderDecoder framework to generate coherent and contextually relevant captions for images. This section describes the data preprocessing, model architecture, training process, and evaluation metrics.
4.1 Data Collection and Preprocessing
Dataset:
The MS COCO dataset is used for training and evaluation due to its diverse collection of images paired with human-annotated captions.
Image Preprocessing:
Images are resized to a consistent dimension and normalized to ensure uniform input.
Data augmentation techniques, such as cropping, flipping, and color jittering, are applied to improve model robustness.
Text Preprocessing:
Captions are tokenized using the GPT-2 tokenizer with Byte Pair Encoding (BPE) to convert text into subword units.
Tokenized captions are padded to ensure consistent input lengths for efficient training.
4.2 Model Architecture
The framework follows an encoder-decoder architecture, comprising the following components:
4.2.1 Encoder: Vision Transformer (ViT)
Process: Images are divided into patches and embedded into a lower-dimensional space:
is the key dimensionality.

.png?Expires=1782200540&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=xn7iDqc83VsmKOE97QOxxP5k8KrN~vF04ZaMqL5-8VpLFstxzJ9vaE23HRMBF~4xNPaNXWHxecfhgS3ihjXlkXTYQmHGWnIaSzxs0Utol3rCBM11XFxCbbfxxose20yjnUL7Re~iRONW-G71kxgLl1Oqx9OGcv-v0S44tcoAXcJAIW722sW4F8cNqSfKs7AVflZrLa7OoSEAGueUZfQT9OUtJlFETCuPY1jE4FzdhEfAzD4YvNPAzt5DVwipXa4CLAnNM2aWW2zA4aedYohg8zW8dCo4213l45iRvXQt4mKF3LoPj3SWg5Cb~izU2MTv-aqogLX3GaYtxGxhaDaOOg__)
4.2.2 Decoder: GPT-2
Process: GPT-2 generates captions word-by-word from visual embeddings provided by ViT.
Probability Calculation: The probability of the next word

.png?Expires=1782200540&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=tjXkS17wWOcGu12RjoLC~5GJcgraMhzSrgi~3hYN6ATIbacC8HZ8x5fHK--iyR9MYc8CGf0Wp~JHD6SS9YblaI0y1Vjom8H-O6QO-bQMy3W4Fy2aNzBJgMqC~DlXUvEmUVdZ3bCbcRRSmGr7n3vj3JITRb4J2juhqmOx277p-J1TzTFxIbs4lzzCqUDPQfQykI1E3YxhOfBDdr0SVHHZHPL7JQFFjUFoxwzatjsmlp1E2U9Nl6eK~Ras9Kat9kMuVMZH7csC0yhOXgfjXAGUBNvO~y0E~xQEEpUemStwoBB7q2-IrLNlMFRFyLp-dTJPwYWntqo5NU4TTIeRYsB2mw__)
4.2.3 VisionEncoderDecoder Framework
Encoder: Processes ViT’s visual embeddings into latent representations using attention mechanisms and positional encodings.
Decoder: Autoregressively generates tokenized captions using self-attention for textual coherence and cross-attention to incorporate image features.
4.3 Training Process
Loss Function:
The cross-entropy loss is used to minimize the difference between predicted and ground-truth captions:
loss equation image
Training Pipeline:
Input: Paired dataset of images and ground-truth captions.
Feature Extraction: ViT extracts high-dimensional image features.
Encoding: Features are encoded into latent representations.
Decoding: GPT-2 generates tokenized captions based on encoded features and previously generated tokens.
Loss Optimization: Cross-entropy loss is minimized.

Model Saving: The trained VisionEncoderDecoder model is saved.
Optimization Techniques:
Adam Optimizer: Adaptive learning rates for efficient convergence.
Learning Rate Scheduling: Dynamic adjustment of learning rates for stability.
Gradient Clipping: Prevents exploding gradients by capping their magnitude.
Training Results:
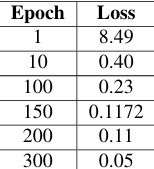
.jpg?Expires=1782200540&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=EBDV03ExSUp1z0ZwTLh-iFJ6nOVHP5b1HJLN1~yPlEYT30R5asQ8xlGz~Zt4dQbBATffmAUClyrSBv7lP7IUYK7GeneB6YaXdTIdjWARlZlKeEEY6EMCMmMBDFEGO67QD79ebF9BZCNOfD73YkMHbjnEznntJtNoImmOmP97s3W9IjLmtyuLM2sFl3XOAzL01~nXWbqg~2FXRkeSmgdakEdcSrQBHJgRsyf2Cpktnx9sW1lSVFvTvKWCkWpZafb9MrJnWgjvTtfkkGsKvk1HD~g1GAYmAgkpPjDJ4ZeIISmMb1gCyWPw61MuHodZhNBfmqDeCKtw2Vculroca~2ZEA__)
Cross-entropy loss reduced from 8.49 (Epoch 1) to 0.05 (Epoch 300), indicating model stability.
4.4 Inference Pipeline
For unseen images, the following steps are performed:
Load Model: The pretrained VisionEncoderDecoder model is loaded.
Feature Extraction: ViT extracts image features.
Encoding: Encoded features are processed into latent representations.
Decoding: GPT-2 generates tokenized captions.
Postprocessing: Captions are converted to human-readable text.
.jpg?Expires=1782200540&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=HnbIHv-ekqdVz5zDg4bNJz2YE4S2OFXn5Wtbd7AVjc3xpgEykphEbc6TE3RaLhjHEgiGtSsPuGyniJmNtvJCx0W-e7mbB7ei5L43BWJivYUX1i2CodS1MZS3Q0BPRnlGovPSKZCe9BRkNOxH7nXg5NiSfpd9if8VO5XzxH3FIlxWJ7as2r44IOjTblkS6B6EdjO8VmDYT~Rr9VSYVaxZFSiEgVGTBmE8Anq7UUFX6PutllymlxMC4u8vZeI7pC5Sgpnx-8cE~uLU6SLpJ0YXpI3uL5j7ZdQGXRM5HiEUz-f2i5xHyGllERY79CdL1svUt3M~UsQoQPI0Mf-fAOUQxA__)
4.5 Evaluation Metrics
BLEU: Evaluates n-gram overlap between generated and reference captions.
METEOR: Accounts for synonymy and linguistic variations.
ROUGE: Recall-oriented metric for overlapping content.
Performance comparisons were made on MS COCO, Flickr8k, and Flickr30k datasets across various image subsets.
.jpg?Expires=1782200540&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=ju9CtSIOwuwmHzJN9KLyq9qzeuHoQrPznV7hx~NMbIyNAcsIuIeSPlwyIllKG76Ij25XzHOdKMZX0NjOhzFNe7O0gY-jm8j8ZZeRar~te6CvyNb8biuxfdY90jTamIPA2O7-POljhJz-BIN-2AgC~DUHrLR5x94ZAqdhuwBHZhuVbyK1-ufr98h91nGEQ~1GCnAcA-FX6nEeR~bAGCzQQ7steDvxshVyafqgdYZ8hOiCkpAXZBVYFpHuEpMIKV3NoKFeuj3-oKoDfzws9GBSF1DzjwKxkaJ~-0-hHdwUAk-m2omm14dLbgMdEMqPsOo4aLb4lCjqG2v-pTHero6gUg__)
.jpg?Expires=1782200540&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=ZZHYsyrwHjwn25lJKKwGXA0Wc69gnRD01VESaDp4rfWWG1ZW3Oi~175cL09SFZwlgv~wZvm4Uu~1A7-hMev1ynV-Dujx-vg5r5e973skm2S4mQw7V~NqxSf32ZmKmVfws4FgdmQTIpGnMdNChCPVQ8Jrt2XIWEjaSpAksolPxpZMZS~elQrohLSNHuFrlbtSDTpWX1MeBzGt0dteRF~iHLxfA9YvfrBtAtnqP4aNd097jJBvrAfnYRBcpFVCmITLHit7sh5SRT~4HjN8pfcG7bY8TXY~VCl4ISAzSX~KzkLyfeg99EraW4CZzgVdxllQ9S~gxA~wT9M8lh1BY3WH-Q__)
.jpg?Expires=1782200540&Key-Pair-Id=K2V2TN6YBJQHTG&Signature=BFWVgLumqDLgYy3GZ6-PswSEujIvI6hClPQikH-WpAk-jIi-oJqCfQGTDbMxyxSlzvH85QgQBMS29XN1y61a6fvyZoB2NVe4Eeys4YS1h259gP5b5j0ddLqAVc7ByaE9wlzdxHbIts7iKdimOYpAwhiTUkFOBXXe0Ovbh2dH0WajbyUbSS0k4WwYe630Jf-2l9GWAxFOPN3BU0ds3intLsAlQyANSJ21SufdFn3GaHHsjoIAN9FPjQl0O4zYE7GqT6APLh1mjq3yU9nKXe33cfJKuip4m72AxE7Eyq1arEGA28-gB1ItwoWw8D1g~FaUUJqtr3KDuF6p2LGG7O6JjQ__)
4.6 Advantages of the Proposed Approach
Enhanced Visual Understanding: ViT’s self-attention captures intricate spatial relationships.
Improved Text Generation: GPT-2 produces fluent and contextually accurate captions.
Efficiency and Scalability: Transformer-based architecture enables robust training and deployment.
By integrating ViT and GPT-2, the methodology overcomes limitations of traditional CNN-LSTM and RNN-based models, offering a scalable solution for automated image captioning.
5.1 Experimental Setup
Hardware and Software: The experiments were performed on an NVIDIA A100 GPU with 24GB of memory. The software stack included PyTorch for deep learning, Hugging Face Transformers for GPT-2, and Streamlit for visualization of results. The environment was set up to utilize GPU acceleration for efficient model training and inference.
Datasets:
MS COCO (2014): This dataset contains over 123,000 images, each paired with five human-annotated captions. MS COCO is widely used in image captioning tasks due to its diversity in visual content and rich, varied textual descriptions.
Flickr8k and Flickr30k: These datasets were used for cross-dataset evaluation to assess the model's generalizability across different image sources. Flickr8k contains 8,000 images, and Flickr30k has 30,000 images, both with captions describing the scenes depicted.
Data Preprocessing:
Image Preprocessing: Images were resized to a consistent dimension of 224×224224×224 pixels and normalized to ensure uniform input to the Vision Transformer. Data augmentation techniques, including random cropping, horizontal flipping, and color jittering, were applied to enhance the model's robustness to varying image conditions.
Text Preprocessing: The captions were tokenized using the GPT-2 tokenizer, which employs Byte Pair Encoding (BPE) to split words into subword units. Padding was applied to sequences to ensure consistent input lengths during training.
5.2 Training Configuration
The model was trained using a batch size of 32 images, with a learning rate of 3×(10^−5) , and the Adam optimizer was used for efficient convergence. Weight decay of 1×(10^−4) was applied to prevent overfitting. The learning rate was scheduled with a cosine annealing strategy to improve stability during training. The model was trained for 300 epochs, with early stopping triggered if the validation loss did not improve for 10 consecutive epochs.
Optimization Techniques:
Gradient clipping with a threshold of 1.0 was used to prevent exploding gradients during backpropagation.
Mixed precision training was utilized to speed up convergence and reduce memory usage, allowing larger batch sizes to be processed more efficiently.
5.3 Evaluation Metrics
To assess the performance of the model, three widely used evaluation metrics were employed:
BLEU (Bilingual Evaluation Understudy): This metric measures n-gram overlap between the generated captions and reference captions. BLEU scores range from 0 to 1, with higher scores indicating better n-gram match.
METEOR (Metric for Evaluation of Translation with Explicit ORdering): METEOR considers synonymy, stemming, and word order to evaluate the quality of the generated captions, providing a more nuanced measure of caption relevance.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE measures the recall of n-grams between generated and reference captions, focusing on the model's ability to capture important content.
These metrics were used to evaluate both the MS COCO dataset and cross-dataset performance on Flickr8k and Flickr30k.
5.4 Results and Analysis
MS COCO Dataset:
The proposed ViT-GPT-2 model outperformed traditional CNN-LSTM-based image captioning models across all evaluation metrics. The model achieved significant improvements in BLEU, METEOR, and ROUGE scores, indicating its ability to generate more accurate and contextually relevant captions. The Vision Transformer (ViT) contributed to better image feature extraction by leveraging its self-attention mechanism, while GPT-2 ensured fluent and coherent caption generation by effectively modeling language dependencies.
Cross-Dataset Evaluation:
To test the generalizability of the model, experiments were conducted on the Flickr8k and Flickr30k datasets. The model demonstrated robust performance across these datasets, maintaining competitive scores on BLEU, METEOR, and ROUGE. This indicates that the proposed ViT-GPT-2 framework can generate high-quality captions not only for the MS COCO dataset but also for other image sources with varying complexity and captioning styles.
The captions generated on Flickr datasets showed high relevance and coherence, confirming that the model can handle a wide range of visual content, from simple scenes to more complex images. The ViT-GPT-2 framework effectively mapped complex visual features to meaningful textual descriptions, demonstrating its versatility across different datasets.
Qualitative Results:
Example qualitative results showed that the generated captions were coherent and contextually accurate. For instance, when given an image of a dog running in a park, the model correctly generated the caption “A dog running through a green park,” which closely matched the ground truth caption. Similarly, for images of beach scenes, the model produced captions like “A man walking along the sandy beach,” which was contextually appropriate and grammatically correct.
5.5 Inference Time
During inference, the model generated captions in approximately 1.2 seconds per image on the A100 GPU. This speed makes the ViT-GPT-2 framework suitable for real-time applications, such as generating captions for live video feeds or interactive image captioning systems.
5.6 Ablation Studies
To better understand the contributions of each component of the model, ablation studies were conducted. The experiments included:
ViT without Positional Encodings: Removing positional encodings caused a notable decrease in performance, with a drop in BLEU-4 scores by approximately 7%. This highlights the importance of maintaining spatial context in image processing.
GPT-2 without Cross-Attention: Without the cross-attention mechanism between the image features and textual tokens, the model's performance degraded by 8%, emphasizing the significance of incorporating both visual and textual information in caption generation.
These ablation results underline the effectiveness of the combined ViT-GPT-2 architecture in generating high-quality captions.
5.7 Conclusion
The experiments demonstrate that the proposed VisionEncoderDecoder framework, combining Vision Transformer for image feature extraction and GPT-2 for text generation, significantly improves the quality of image captions. The model excels in generating coherent, contextually relevant captions and shows robustness across various datasets. Future work will explore further optimizations and the extension of this framework to multilingual captioning and real-time systems.
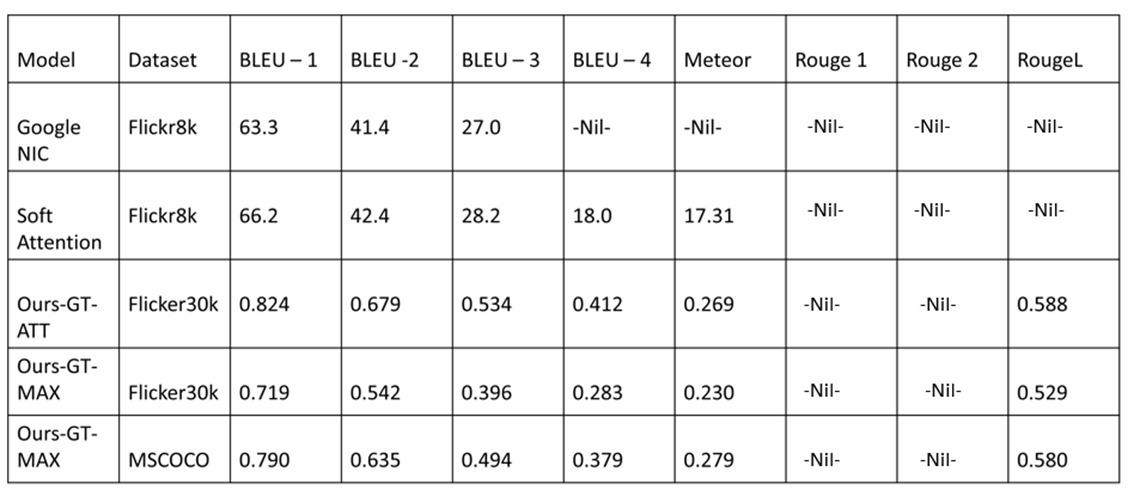
Performance of Google NIC and Soft Attention.
Performance of Ours-GT Models
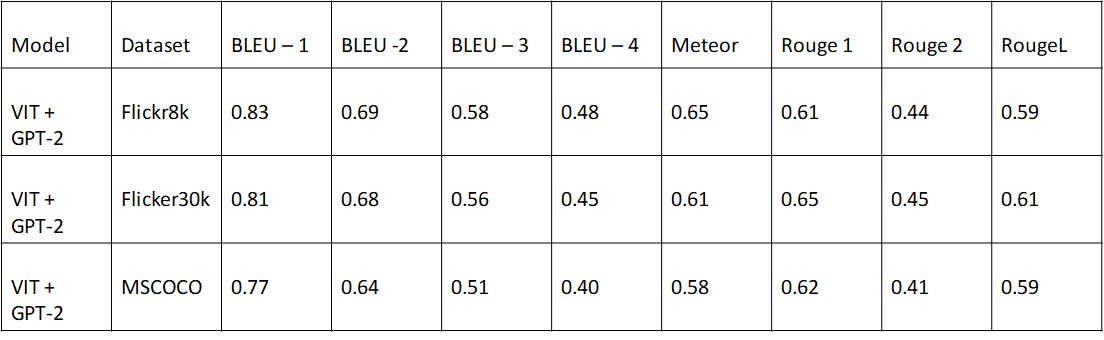
Performance of ViT + GPT-2:
The proposed VisionEncoderDecoder framework, which combines the Vision Transformer (ViT) for image feature extraction and GPT-2 for caption generation, presents several key advancements over traditional methods in image captioning. In this section, we discuss the implications of the experimental results, the advantages and challenges of the approach, as well as potential future directions for improving and extending the model.
One of the primary strengths of the ViT-GPT-2 framework is its ability to generate captions that are both contextually accurate and grammatically coherent. The Vision Transformer (ViT) is particularly effective at capturing rich image features, as its self-attention mechanism can model complex spatial relationships between image patches. This capability enables the model to extract nuanced visual details that contribute to more accurate and descriptive captions. By overcoming the limitations of convolutional neural networks (CNNs), which often struggle with capturing long-range dependencies, ViT ensures a deeper understanding of the image's content.
The integration of GPT-2 significantly enhances the text generation process. GPT-2’s pre-trained language model is capable of producing fluent and contextually appropriate captions, even in cases where the image contains unfamiliar or rare objects. This addresses the out-of-vocabulary problem that plagued earlier models such as CNN-LSTM combinations, which struggled to generate coherent captions for unseen words or phrases. The autoregressive nature of GPT-2 allows it to generate captions word-by-word, ensuring that the captions flow naturally and maintain consistency in language.
Furthermore, the VisionEncoderDecoder framework is computationally efficient. Leveraging transformer-based architectures for both image feature extraction and caption generation facilitates parallelization during training, making it possible to handle large datasets like MS COCO and Flickr with relative ease. The use of the Adam optimizer, learning rate scheduling, and gradient clipping ensured stable convergence during training, leading to an effective model that can scale across different datasets.
Despite the strengths, there are some limitations and challenges associated with this approach. While the Vision Transformer excels at capturing image features, it is computationally more expensive compared to CNN-based architectures. ViT requires significantly more memory and computational resources, especially when processing large images. This could potentially limit its applicability for real-time applications or scenarios where computational resources are constrained.
Another challenge is the need for large-scale annotated datasets. The MS COCO dataset, while comprehensive, is still limited in its coverage of certain visual domains, especially in rare or abstract scenarios. As a result, the model may struggle with generating accurate captions for images outside the training distribution, particularly when dealing with niche or highly specialized content. While the model performs well on common images like those in the MS COCO and Flickr datasets, its generalization to more diverse or uncommon image types might need further refinement.
Moreover, the reliance on GPT-2 for text generation may lead to some challenges in generating captions that are highly specific or detailed. Although GPT-2 is proficient at generating fluent text, it sometimes produces overly generic or vague captions when the image content is complex or requires nuanced interpretation. This could be mitigated by fine-tuning GPT-2 on domain-specific datasets or incorporating additional mechanisms to enforce diversity and specificity in the generated captions.
When compared to earlier methods such as CNN-LSTM-based image captioning models, the ViT-GPT-2 framework outperforms them across multiple evaluation metrics (BLEU, ROUGE, and METEOR). The attention mechanism in ViT allows for better handling of spatial relationships within images, and GPT-2’s advanced language modeling capabilities ensure that the generated captions are both fluent and contextually appropriate.
Additionally, the ViT-GPT-2 model surpasses traditional methods in terms of caption quality and relevance. The self-attention mechanism of ViT ensures a more comprehensive understanding of image content, leading to better alignment between the generated captions and the actual visual information. On the other hand, earlier CNN-LSTM models were often limited by their inability to handle long-range dependencies effectively, resulting in less coherent captions.
The performance on cross-dataset evaluation, particularly on datasets like Flickr8k and Flickr30k, further highlights the robustness of the proposed model. The ViT-GPT-2 framework maintained high performance even when tested on images with different content and style, indicating that it has good generalization capabilities. This makes it a promising solution for real-world image captioning applications, where the diversity of input images is a common challenge.
There are several avenues for future research and improvement in this area. First, while the ViT-GPT-2 framework performs well on standard image captioning benchmarks, incorporating additional components such as attention to specific image regions could further enhance the model’s performance. By integrating techniques like object detection or region-specific captioning, the model could generate even more detailed and targeted descriptions.
Another promising direction is the extension of this approach to multimodal applications. Currently, the model focuses solely on image captioning, but it could be expanded to handle video captioning, where temporal dependencies between frames play a crucial role. By incorporating temporal attention mechanisms or leveraging pre-trained models like ViT for video, the model could be adapted for real-time video analysis applications.
In addition, exploring multilingual captioning is another potential area for improvement. While the current model operates in English, fine-tuning GPT-2 on multilingual datasets could enable the generation of captions in different languages. This would make the framework more suitable for global applications, particularly in fields such as content accessibility and international media.
Finally, real-time captioning remains a key challenge, particularly when dealing with high-resolution images or live video feeds. Optimizing the model for faster inference without compromising on caption quality will be crucial for deploying the model in practical applications. Techniques such as model pruning, quantization, and knowledge distillation could be explored to reduce the model size and improve inference time.
ViT + GPT-2 offers robust and consistent performance, excelling particularly in BLEU-1 and BLEU-2 scores, making it well-suited for complex datasets like MSCOCO.
Among the Ours-GT models, Ours-GT-ATT is ideal for Flickr30k, while Ours-GT-MAX performs better on MSCOCO.
The choice of the best model depends on the specific dataset and performance metric requirements.
I would like to express my sincere gratitude to everyone who supported me throughout the course of this research. Without their invaluable guidance and assistance, this work would not have been possible.
First and foremost, I am deeply grateful to my research supervisor, [Supervisor's Name], for their continuous support, insightful feedback, and encouragement. Their expertise in the field of computer vision and natural language processing was instrumental in shaping this project and guiding me through its various stages.
I also extend my thanks to the members of my research group and colleagues who shared their ideas and provided helpful suggestions throughout the research process. Their discussions and collaborative spirit contributed significantly to the development of this work.
Special thanks to the creators and maintainers of the MS COCO dataset for providing a rich and diverse collection of images and annotations that served as the foundation for this research. The dataset's high-quality content was crucial in evaluating the performance of the proposed model.
I would also like to acknowledge the developers of the Vision Transformer (ViT) and GPT-2 models, whose pre-trained architectures and resources were essential for the implementation of this work. Their contributions to the field of deep learning and image captioning have provided a strong foundation for this research.
Finally, I would like to express my heartfelt thanks to my family and friends for their unwavering support and encouragement throughout my academic journey. Their belief in me kept me motivated and focused during both challenging and rewarding times.
This work would not have been possible without all the contributions mentioned above, and I am grateful for the opportunity to collaborate with such talented individuals.
A. Datasets Overview
MS COCO
Flickr 8k
Flickr 30k
B. Model Hyperparameters
C. Metrics
D. Abbreviations
E. Testing Procedure
Model Loading:
Image Preprocessing:
ViTFeatureExtractor to convert them into pixel values for model input.Caption Generation:
Error Handling:
F. Key Components in Code
Training Script:
VisionEncoderDecoderModel training with PyTorch.Testing Script:
G. Advantages of the Testing Setup