Abstract
Earth vision research typically focuses on extracting geospatial object locations and categories but neglects the exploration of relations between objects and comprehensive reasoning. Based on city planning needs, we develop a multi-modal multi-task VQA dataset (EarthVQA) to advance relational reasoning-based judging, counting, and comprehensive analysis. The EarthVQA dataset contains 6000 images, corresponding semantic masks, and 208,593 QA pairs with urban and rural governance requirements embedded. As objects are the basis for complex relational reasoning, we propose a Semantic OBject Awareness framework (SOBA) to advance VQA in an object-centric way. To preserve refined spatial locations and semantics, SOBA leverages a segmentation network for object semantics generation. The object-guided attention aggregates object interior features via pseudo masks, and bidirectional cross attention further models object external relations hierarchically. To optimize object counting, we propose a numerical difference loss that dynamically adds difference penalties, unifying the classification and regression tasks. Experimental results show that SOBA outperforms both advanced general and remote sensing methods. We believe this dataset and framework provide a strong benchmark for Earth vision's complex analysis.
Introduction
High-spatial resolution (HSR) remote sensing images can assist us in quickly obtaining essential information (Zvonkov et al. 2023; Xiao et al. 2023). Most research focuses on the perception of object categories and locations, deriving related tasks such as semantic segmentation (Liu et al. 2023), species detection (Zhao et al. 2022), and urban understanding (Shi et al. 2023). However, the existing methods and datasets ignore the relations between the geospatial objects, thus limiting their ability to knowledge reasoning in complex scenarios. Especially in city planning (Bai, Shi, and Liu 2014), the relations between the transportation hubs and schools, water situations around the farmland, and greenery distributions in residential areas are also significant and urgent to be analyzed. Hence, it is necessary to go beyond object perception and explore object relations, bridging the gap between information and comprehensive knowledge (Li and Krishna 2022).
Visual question answering (VQA) aims to answer customized questions by searching for visual clues in the provided image. Since linguistic questions determine the task properties, the algorithms are flexible and can be developed for reasoning required answers. Recently, preliminary VQA datasets and methods have emerged in the remote sensing field (Lobry et al. 2020; Zheng et al. 2021; Rahnemoonfar et al. 2021). However, most of these researches have the following drawbacks: 1) As for most datasets, QA pairs are
automatically labeled based on existing data, such as Open Street Map (OSM) and classification datasets. Most tasks are simple counting and judging questions with no relational reasoning required. The automatic QA pairs do not match actual needs, limiting their practicalities. 2) The development of the remote sensing VQA model lags, and most research directly fuses the global visual and language features to predict the final answers. They ignore the local semantics and relations, which are unsuitable for the complex reasoning of multiple geospatial objects. To this end, we propose a multi-modal multi-task VQA dataset and a semantic object awareness framework to advance complex remote sensing VQA tasks. The main contributions are as follows:
- We propose the EarthVQA dataset with triplet samples (image-mask-QA pairs). The 208,593 QA pairs encompass six main categories. EarthVQA features diverse tasks from easy basic judging to complex relation reasoning and even more challenging comprehensive analysis. Specifically, the residential environments, traffic situations, and renovation needs of waters and unsurfaced roads are explicitly embedded in various questions.
- To achieve relational reasoning-based VQA, we propose a semantic object awareness framework (SOBA). SOBA utilizes segmentation visual prompts and pseudo masks to generate pixel-level features with accurate locations. The object awareness-based hybrid attention models the relations for object-guided semantics and bidirectionally aggregates multi-modal features for answering.
- To add distance sensitivity for regression questions, we propose a numerical difference (ND) loss. The dynamic ND penalty is seamlessly integrated into cross-entropy loss for the regression task. ND loss introduces the sensitivity of numerical differences into the model training.
Related Work
General Visual Question Answering
The vanilla VQA model (Antol et al., 2015) includes three parts: a convolutional neural network (CNN), a long-short term memory (LSTM), and a fusion classifier. Specifically, CNN extracts visual features for input images, and LSTM embeds the language features for the questions. Global features are interacted in the fusion classifier and finally generate the answer. Based on this architecture, more powerful encoders and fusion modules were proposed.
To obtain local visual features, the bottom-up top-down attention (BUTD) mechanism (Anderson et al., 2018) introduced objectness features generated by Faster-RCNN (Ren et al., 2015) pretrained on Visual Genome (Krishna et al., 2017) data. For computational efficiency, a recurrent memory, attention, and composition (MAC) cell (Hudson & Manning, 2018) was designed to explicitly model the relations between image and language features. Similarly, the stacked attention network (SAN) (Yang et al., 2016) located the relevant visual clues guided by questions layer-by-layer. By combining objectness features with attention, the modular co-attention network (MCAN) (Yu et al., 2019) adopted a transformer to model intra- and inter-modality interactions.
To alleviate language biases, D-VQA ](Wen et al., 2021) applied a unimodal bias detection module to explicitly remove negative biases. BLIP-2 (Li et al., 2023) and Instruct-BLIP (Dai et al., 2023) bridge large pre-trained vision and language models using the Q-Former, addressing VQA as a generative task. Additionally, many advanced VQA methods (Marino et al., 2021) eliminate statistical bias by accessing external databases.
Remote Sensing Visual Question Answering
The remote sensing community has some early explorations, including both datasets and methods. The QA pairs of the RSVQA dataset (Luca et al., 2020) are queried from OSM, and images are obtained from Sentinel-2 and other sensors. RSIVQA dataset (Zheng et al., 2021) is automatically generated from existing classification and object detection datasets, i.e., AID (Xia et al., 2017), HRRSD (Zhang et al., 2019), etc. The FloodNet dataset (Rahnemoonfar et al., 2021) was designed for disaster assessment, mainly concerned with the inundation of roads and buildings.
Compared with these datasets, the EarthVQA dataset has two advantages:
- Multi-level annotations. The annotations include pixel-level semantic labels, object-level analysis questions, and scene-level land use types. Supervision from different perspectives advances a comprehensive understanding of complex scenes.
- Complex and practical questions. The existing datasets focus on counting and judging questions, which only involve simple relational reasoning about one or two types of objects. In addition to counting and judging, EarthVQA also contains various object analysis and comprehensive analysis questions. These promote complex relational reasoning by introducing spatial or semantic analysis of more than three types of objects. Only basic judging and counting answers are auto-generated from the LoveDA masks. Other reasoning answers (Figure 1) are manually annotated (reasoning distances, layouts, topologies, sub-properties, etc.) for city planning needs.
Remote sensing algorithms are mainly modified from general methods. For example, RSVQA is based on vanilla VQA (Antol et al., 2015). RSIVQA (Zheng et al., 2021) designed a mutual attention component to improve interactions for multi-modal features. CDVQA (Yuan et al., 2022) introduced VQA into the change detection task. We novelly introduce pixel-level features for the guidance of VQA tasks, making it suitable for scenes with compact objects.
EarthVQA Dataset
The EarthVQA dataset was extended from the LoveDA dataset (Wang et al., 2021), which encompasses 18 urban and rural regions from Nanjing, Changzhou, and Wuhan. LoveDA dataset provides 5,987 HSR images and semantic masks with seven common land-cover types. There are three significant revisions:
- Quantity expansion. Eight urban and five rural samples are added to expand capacity to 6,000 images (WorldView-3 0.3m).
- Label refinement. A
playgroundclass was added as an important artificial facility, and some errors in semantic labels were revised. - Addition of QA pairs. We added 208,593 QA pairs to introduce VQA tasks for city planning. Each urban image has 42 QAs, and each rural image has 29 QAs.
Following the balanced division (Wang et al., 2021), the dataset is split as follows: Train set: 2,522 images with 88,166 QAs , Validation set: 1,669 images with 57,202 QAs ,Test set: 1,809 images with 63,225 QAs .

Figure 1. Urban and rural samples (image-mask-QA pairs) from the EarthVQA dataset. The QA pairs are designed to based on city planning needs, including judging, counting, object situation analysis, and comprehensive analysis types.
This multi-modal and multi-task dataset poses new challenges, requiring object-relational reasoning and knowledge summarization.
 (a) Annotation procedure of relational-based QA. |
 (b) Statistics of questions. |
 (c) Distributions of 15 most frequent answers. |
Figure 2. Details of questions and answers in the EarthVQA dataset. Each urban image has a set of 42 questions, and each rural image has a set of 29 questions, ensuring a relatively balanced distribution for each question. However, the imbalanced distribution of answers presents challenges when applied to real-world Earth environments.
Annotation Procedure
EarthVQA currently does not involve ambiguous questions such as geographical orientations. For example, the question Are there any intersections near the school? in Figure 2(a) is answered by judging topology. The recognized Road#1 and Road#2 first form Intersection#5. Similarly, Ground#4 and Building#3 jointly form the scene of School#6. Using the ArcGIS toolbox, the polygon-to-polygon distance between School#6 and Intersection#5 is calculated as 94.8m < 100m, resulting in the answer Yes. Each step in the annotation process has fixed thresholds and conditions.
Statistics for Questions
As shown in Figure 2(b), urban and rural scenes have both common and unique questions based on city planning demands. The number of questions for urban and rural scenes is balanced, eliminating geographical statistical bias.
- Basic questions involve statistics and inferences about a certain type of object, e.g.,
What is the area of the forest?. - Relational-based questions require semantic or spatial relational reasoning between different objects.
- Comprehensive analysis focuses on more than three types of objects, including a summarization of traffic facilities, water sources around agriculture, and land-use analysis, etc.
Statistics for Answers
As shown in Figure 2(c), we selected the top 15 most frequent answers from 166 unique answers in the dataset. Similar to the common VQA datasets, the imbalanced distributions of answers bring more challenges when faced with
the actual Earth environment.
Semantic Object Awareness Framework
To achieve efficient relational reasoning, we design the SOBA framework for complex city scenes. SOBA includes a two-stage training process:
- Semantic segmentation network training for generating visual features and pseudo masks.
- Hybrid attention training for reasoning and answering.
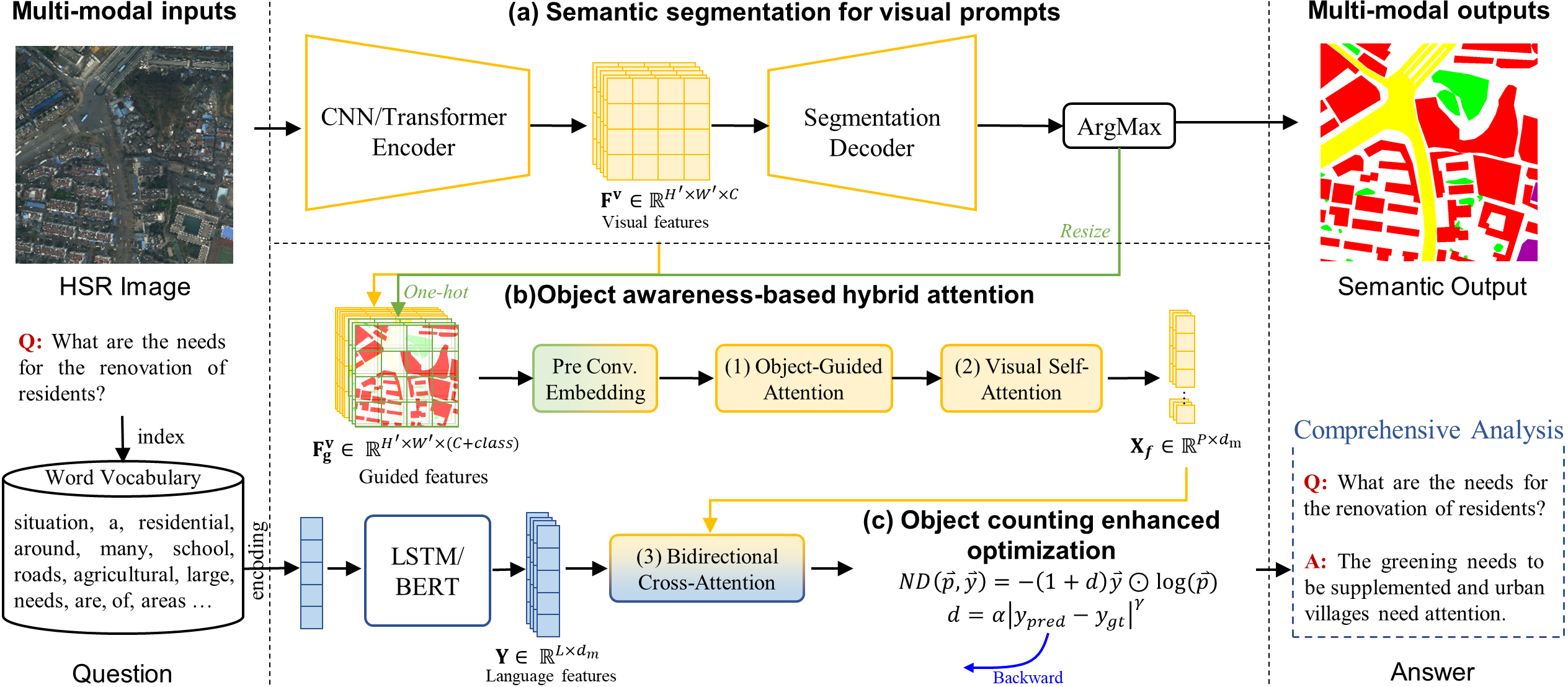
Figure 3. The architecture of SOBA includes (a) deep semantic segmentation for visual features, (b) object-awareness-based hybrid attention, and (c) object-counting enhanced optimization.
Semantic Segmentation for Visual Features
Faced with HSR scenes containing multiple objects, we novelly adopt a segmentation network for refined guidance. For an input image
Compared with the existing Faster-RCNN-based algorithms [Yu et al., 2019; Anderson et al., 2018], which average box features in one vector, the pixel-level visual features preserve the locations and semantic details inside objects. This contributes to the modeling of various compact objects in HSR scenes.
Object Awareness-Based Hybrid Attention
Guided by questions and object masks, object awareness-based hybrid attention reasons visual cues for final answers. As shown in Figure 1, there are three components:
- Object-guided attention (OGA)
- Visual self-attention (VSA)
- Bidirectional cross-attention (BCA)
OGA for Object Aggregation.
Because the segmentation output
VSA for Feature Enhancement.
To capture long-distance relations between geospatial objects, VSA [Dosovitskiy et al., 2020] hierarchically transforms the refined features. VSA includes
At each block
where
MSA repeats the attention operation
where
where
BCA for Multi-Modal Interaction.
BCA advances the interaction with visual and language features via a bidirectional fusion mechanism. BCA consists of two series of
Finally, the fused
Object Counting Enhanced Optimization.
VQA tasks include both classification and regression (object counting) questions. However, existing methods regard them as a multi-classification task, which is processed with cross-entropy (CE) loss. CE loss is defined as:
where
To introduce a difference penalty for the regression task, we add a modulating factor:
Here,
ND loss unifies classification and regression objectives into one optimization framework. The parameter
Experiments
Evaluation Metrics. Following common settings (Yu et al., 2019), we adopt the classification accuracy and root-mean-square error (RMSE) as evaluation metrics. Especially, RMSE is used to evaluate counting tasks. We use mean Union over Intersection (mIoU) to report semantic segmentation performance. All experiments were performed under the PyTorch framework using one RTX 3090 GPU.
Experimental Settings. For comparison, we selected eight general (SAN (Yang et al., 2016), MAC (Hudson et al., 2018), BUTD (Anderson et al., 2018), BAN (Kim et al., 2018), MCAN (Yu et al., 2019), D-VQA (Wen et al., 2021), BLIP-2 (Li et al., 2023), Instruct-BLIP (Dai et al., 2023)) and two remote sensing (RSVQA (Luca et al., 2020), RSIVQA (Zheng et al., 2021)) VQA methods.
Because MCAN, BUTD, BAN, and D-VQA need object guidance, we adopt visual features from Semantic-FPN (Kirillov et al., 2019) fairly. All VQA models were trained for 40k steps with a batch size of 16. We set the two-layer LSTM with the hidden size of 384 and ResNet50 as default. As for large vision-language models, BLIP-2 and Instruct-BLIP trained Q-Former following their original settings. The vision encoder adopts ViT-g/14, and the language decoder is FlanT5XL. Following (Wang et al., 2021), Semantic-FPN was trained for 15k steps using the same batch size, generating visual features and semantic masks. Segmentation augmentations include random flipping, rotation, scale jittering, and cropping for
Comparative Experiments
Main Comparative Results
Thanks to the diverse questions, EarthVQA can measure multiple perspectives of VQA models. Table 1 shows that all methods achieve high accuracies on basic judging questions. The models with pixel-level visual features obtain higher accuracies, especially for the counting tasks. This is because the semantic locations provide more spatial details, which benefit the object statistics. Compared with advanced methods, SOBA achieves the best overall performance with similar or lower complexity.
Table 1. Compared results with other VQA methods on EarthVQA test set.
| Method | Promp. | Bas Ju | Rel Ju | Bas Co | Rel Co | Obj An | Com An | ↑OA(%) | ↓RMSE (Bas Co) | ↓RMSE (Rel Co) | ↓OR | Param. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SAN | ✗ | 87.59 | 81.79 | 76.26 | 59.23 | 55.00 | 43.25 | 75.66 | 1.136 | 1.318 | 1.160 | 32.30 |
| MAC | ✗ | 82.89 | 79.46 | 72.53 | 55.86 | 46.32 | 40.50 | 71.98 | 1.407 | 1.337 | 1.398 | 38.64 |
| BUTD | ✓ | 90.01 | 82.02 | 77.16 | 60.95 | 56.29 | 42.29 | 76.49 | 0.890 | 1.292 | 0.950 | 34.95 |
| BAN | ✓ | 89.81 | 81.87 | 77.58 | 63.71 | 55.67 | 45.06 | 76.74 | 0.819 | 1.241 | 0.883 | 58.73 |
| MCAN | ✓ | 89.65 | 81.65 | 79.83 | 63.16 | 57.28 | 43.71 | 77.07 | 0.816 | 1.230 | 0.879 | 55.17 |
| D-VQA | ✓ | 89.73 | 82.12 | 77.38 | 63.99 | 55.14 | 43.20 | 76.59 | 0.916 | 1.238 | 0.962 | 37.79 |
| BLIP-2 | ✗ | 88.13 | 81.92 | 70.26 | 58.58 | 42.72 | 28.34 | 71.07 | 1.879 | 1.320 | 1.818 | ≈4B |
| Instruct-BLIP | ✗ | 89.67 | 79.69 | 76.96 | 63.34 | 59.72 | 45.68 | 75.25 | 0.799 | 1.217 | 0.862 | ≈4B |
| RSVQA | ✗ | 82.43 | 79.34 | 70.68 | 55.53 | 42.45 | 35.46 | 70.70 | 1.733 | 1.359 | 1.691 | 30.21 |
| RSIVQA | ✗ | 85.32 | 80.44 | 75.01 | 56.63 | 51.55 | 39.25 | 73.71 | 1.718 | 1.346 | 1.676 | 41.41 |
| SOBA (ours) | ✓ | 89.63 | 82.64 | 80.17 | 67.86 | 61.40 | 49.30 | 78.14 | 0.785 | 1.145 | 0.839 | 40.46 |
Object Guided Attention
OGA introduces object semantics into visual features, and we compare it with related variants. Table 2 shows comparative results for spatial, channel, and combined attentions (e.g., SA (Woo et al., 2018), SCSE (Roy et al., 2018), CBAM (Woo et al., 2018), SE (Hu et al., 2018) GC (Cao et al., 2019)). Channel attentions bring more stable improvements than spatial attentions. Because pseudo masks and visual features are concatenated dimensionally, spatial attentions are hard to calibrate the subspaces of visual features and object masks. Channel attentions enhance key object semantics and weaken uninterested background features. Hence, our OGA abandoned spatial attention and achieved the best accuracies.
Table 2. Compared results with other attention mechanisms. C and S denote channel and spatial attention.
| Object Guidance | Att. Type | ↑OA(%) | ↓OR |
|---|---|---|---|
| Only Concat | - | 77.61 | 0.856 |
| +SA | S | 77.72 | 0.861 |
| +SCSE | C&S | 77.89 | 0.854 |
| +CBAM | C&S | 77.95 | 0.857 |
| +SE | C | 78.02 | 0.853 |
| +GC | C | 78.03 | 0.847 |
| +OGA (ours) | C | 78.14 | 0.839 |
One-Way vs. Bidirectional Cross-Attention.
Existing transformer-based methods (Yu et al., 2019; Cascante et al., 2022) utilize one-way (vanilla) attention to perform interactions, where visual features are only treated as queries. In contrast, we further gather enhanced visual features via the keywords (language features as queries), simulating the human process of finding visual cues. As cross-attention consists of six transformer blocks, we compare the different combinations. Table 3 shows that in one-way attention, querying visual features outperforms querying the language features. This is because visual features are more informative, and their enhancement brings more improvements. Bidirectional attention outperforms the one-way structure due to more comprehensive interactions.
Table 3. Compared results between one-way (vanilla) and bidirectional cross-attention. V and L denote visual and language features, respectively.
| Cross-Attention | Query | ↑OA(%) | ↓OR |
|---|---|---|---|
| One-way (vanilla) | LLLLLL | 77.11 | 0.977 |
| VVVVVV | 77.53 | 0.880 | |
| Bidirectional | LLL-VVV | 77.57 | 0.867 |
| VVV-LLL | 78.14 | 0.839 |
Module Analysis
Architecture of SOBA
SOBA was disassembled into five sub-modules: 1. VSA 2. BCA 3. Semantic features 4. OGA 5. ND loss.
Table 4 shows that each module enhances the overall performance in distinct ways. BCA produces a more significant improvement than VSA, and they complement each other (jointly obtaining OA = 74.91%). OGA further improves the OA by explicitly adding the objectness semantics. ND loss significantly boosts the counting performance from the aspect of optimization. All modules are compatible with each other within the SOBA framework.
Table 4. Architecture ablation study.
| VSA | BCA | Promp. | OGA | ND | ↑OA (%) | ↓OR |
|---|---|---|---|---|---|---|
| ✓ | 72.55 | 1.509 | ||||
| ✓ | 73.78 | 1.520 | ||||
| ✓ | ✓ | 74.91 | 1.128 | |||
| ✓ | ✓ | ✓ | 77.30 | 0.866 | ||
| ✓ | ✓ | ✓ | ✓ | 77.54 | 0.859 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 78.14 | 0.839 |
Encoder Variants
Table 5 shows the effects brought by segmentation networks with advanced CNN and Transformer encoders, such as HRNet (Wang et al., 2020), Swin Transformer (Liu et al., 2021), Mix Transformer (Xie et al., 2021), and ConvNeXt (Liu et al., 2022). SOBA is compatible with the mainstream encoders, and VQA performance is stable at a high level (OA > 77.22%). Although MiT-B3 achieves lower segmentation accuracies than HR-W40, their features provide similar VQA performances. For similar segmentation architectures, larger encoders (Swin-S and ConvX-S) outperform smaller encoders (Swin-T and ConvX-T) in both segmentation and VQA tasks. With Wikipedia's external knowledge, pretrained BERT-Base [Kenton et al., 2019] brings stable improvements. With abundant computing power and time, larger encoders are recommended.
Table 5. Encoder variants analysis.
| Img Enc | Lan Enc | ↑mIoU(%) | ↑OA(%) |
|---|---|---|---|
| HR-W40 | LSTM | 57.31 | 77.92 |
| MiT-B3 | LSTM | 56.44 | 77.43 |
| Swin-T | LSTM | 56.89 | 77.22 |
| Swin-S | LSTM | 57.44 | 78.01 |
| ConvX-T | LSTM | 57.17 | 78.24 |
| ConvX-S | LSTM | 57.34 | 78.43 |
| Swin-T | BERT-Base | 56.89 | 77.63 |
| Swin-S | BERT-Base | 57.44 | 78.23 |
| ConvX-S | BERT-Base | 57.34 | 78.65 |
Bidirectional Cross-Attention Variants
We explored BCA variants with different orders of query, where V (visual features) and L (language features) were processed alternately, in cascade, and in parallel. Table 6 shows that the cascade structure VVV-LLL achieves the best accuracies. VVV hierarchically aggregates language features to enhance visual features, and LLL compresses the visual features to supplement language features. Compared with LLL, first considering VVV retains the most information. Hence, VVV-LLL represents the integration process from details to the whole, which conforms to human perception (Savage et al., 2019). The parallel structure obtains a sub-optimal accuracy, and frequent alternation of cross-attentions may lead to feature confusion.
Table 6. BCA Variants
|
Table 7. Optimization Analysis
|
Optimization Analysis
We compare ND loss with similar optimization algorithms designed to address the sample imbalance problem, including: 1. Dynamic inverse weighting (DIW) (Rajpurkar et al., 2017), 2. Focal loss (Lin et al., 2017), 3. Online hard example mining (OHEM) (Shrivastava et al., 2016), 4. Small object mining (SOM) (FactSeg, 2020). In Table 7, Focal loss obtains better performance by adaptively balancing weights of easy and hard examples. DIW failed to exceed CE due to its extreme weighting strategies. OHEM dynamically focuses on hard samples during the training, slightly improving OA (+0.31%).
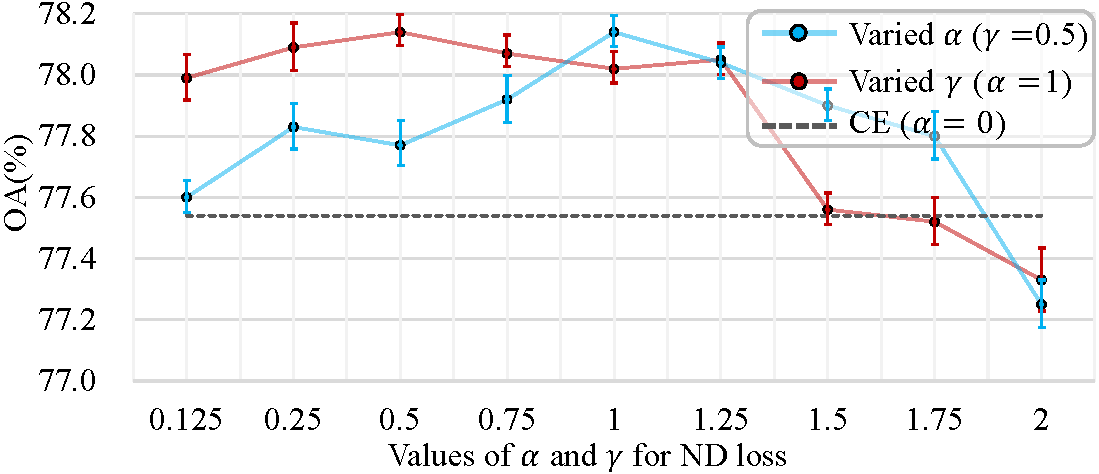
Figure 4. Experimental results with varied
These optimization algorithms only address sample imbalances but are not sensitive to numerical distances, inherently limiting their contribution to regression tasks. In contrast, ND loss demonstrates excellent performance on both classification and regression tasks.
Hyperparameter Analysis for ND Loss
As ND loss introduces two hyperparameters:
- The suitable range for
is 0.125 to 1.25, with the highest OA achieved at . For , performance drops due to instability during training. - With
fixed at 1, the optional range for is also 0.125 to 1.25, where OA fluctuates between 77.99% and 78.14%. - When
, the influence curve changes from concave to convex, increasing the difference penalty significantly.
The model performance is not highly sensitive to these hyperparameters, reflecting high fault tolerance and robustness. Overall, ND loss outperforms the CE baseline with a wide range of hyperparameter selection.
 (a) Classification loss (γ=0.5) |
 (b) Regression loss (γ=0.5) |
 (c) Classification loss (α=1.0) |
 (d) Regression loss (α=1.0) |
Figure 5. The training losses of classification and regression tasks with different
ND loss comprises two components: 1. The original classification loss. 2. An enhanced regression loss. Figure 5 illustrates the effects of varying
Results
 (a) How many `intersections' are in this scene? |
 (b) What are the needs for the renovation of `residents'? |
 (c) What are the `water' types in this scene? |
Figure 6. Visualization of attention maps in BCA with language features as queries. From left to right are the intersections', residents', and `water'.
To analyze the mechanism of multi-modal feature interaction, we visualize the attention maps in each layer of BCA according to different queries.
Example 1: Intersection Query
The question in Figure 3(a) is "How many intersections are in this scene?", where intersections is selected as the query word.
- Early layers: The first attention map shows some incorrect activations on scattered roads and playground tracks.
- Deeper layers: As the layer deepens, BCA successfully reasons the correct spatial relation for the key roads, and the attention map focuses on the intersection in the upper-left corner.
Example 2: Residential Area Query
Figure 3(b) shows another example with the query word residential.
- The visualization displays the process of gradually attending to the residential area as layers progress.
Example 3: Water Query in Rural Scene
The third example in Figure 3(c) shows a rural scene with the query word water.
- Early layers: The attention map initially focuses on trees and waters due to their similar spectral values.
- Later layers: The correct water regions are enhanced, while uninterested trees are filtered out.
Conclusion
To go beyond information extraction, we introduce VQA into remote sensing scene understanding, enabling relational reasoning. Based on city planning needs, we designed a multi-modal and multi-task VQA dataset named EarthVQA. In addition, we proposed a two-stage semantic object awareness framework (SOBA) to enhance VQA tasks effectively. Extensive experiments demonstrated the superiority of SOBA. Future work will focus on exploring the interactions between segmentation and VQA tasks.
References
[1] Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; and Zhang, L. 2018. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 6077–6086.
[2] Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C. L.; and Parikh, D. 2015. VQA: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, 2425–2433.
[3] Bai, X.; Shi, P.; and Liu, Y. 2014. Society: Realizing China’s urban dream. Nature, 509(7499): 158–160.
[4] Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.-J.; Shamma, D. A.; et al. 2017. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 123(1): 32–73.
[5] Li, F.-F.; and Krishna, R. 2022. Searching for computer vision north stars. Daedalus, 151(2): 85–99.
[6] Li, J.; Li, D.; Savarese, S.; and Hoi, S. C. H. 2023. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. In Proceedings of the International Conference on Machine Learning (ICML 2023), 19730–19742.
[7] Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; and Dollár, P. 2017. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, 2980–2988.
[8] Liu, Y.; Zhong, Y.; Ma, A.; Zhao, J.; and Zhang, L. 2023. Cross-resolution national-scale land-cover mapping based on noisy label learning: A case study of China. International Journal of Applied Earth Observation and Geoinformation, 118: 103265.
[9] Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; and Guo, B. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10012–10022.
[10] Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; and Xie, S. 2022. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11976–11986.
[11] Lobry, S.; Marcos, D.; Murray, J.; and Tuia, D. 2020. RSVQA: Visual Question Answering for Remote Sensing Data. IEEE Transactions on Geoscience and Remote Sensing, 58(12): 8555–8566.
[12] Ma, A.; Wang, J.; Zhong, Y.; and Zheng, Z. 2022. FactSeg: Foreground Activation-Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery. IEEE Transactions on Geoscience and Remote Sensing, 60: 1–16.
[13] Marino, K.; Chen, X.; Parikh, D.; Gupta, A.; and Rohrbach, M. 2021. Krisp: Integrating implicit and symbolic knowledge for open-domain knowledge-based VQA. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14111–14121.
[14] Rahnemoonfar, M.; Chowdhury, T.; Sarkar, A.; Varshney, D.; Yari, M.; and Murphy, R. R. 2021. FloodNet: A high-resolution aerial imagery dataset for post flood scene understanding. IEEE Access, 9: 89644–89654.
[15] Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. 2017. ChexNet: Radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv preprint arXiv
.05225.[16] Cao, Y.; Xu, J.; Lin, S.; Wei, F.; and Hu, H. 2019. GCNet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 0–0.
[17] Cascante-Bonilla, P.; Wu, H.; Wang, L.; Feris, R. S.; and Ordonez, V. 2022. SimVQA: Exploring simulated environments for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5056–5066.
[18] Dai, W.; Li, J.; Li, D.; Tiong, A. M. H.; Zhao, J.; Wang, W.; Li, B.; Fung, P.; and Hoi, S. 2023. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. arXiv
.06500.[19] Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; and Houlsby, N. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations.
[20] Hu, J.; Shen, L.; and Sun, G. 2018. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7132–7141.
[21] Ren, S.; He, K.; Girshick, R.; and Sun, J. 2015. Faster RCNN: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 28.
[22] Roy, A. G.; Navab, N.; and Wachinger, C. 2018. Recalibrating fully convolutional networks with spatial and channel “squeeze and excitation” blocks. IEEE Transactions on Medical Imaging, 38(2): 540–549.
[23] Savage, N. 2019. How AI and neuroscience drive each other forwards. Nature, 571(7766): S15–S15.
[24] Shi, S.; Zhong, Y.; Liu, Y.; Wang, J.; Wan, Y.; Zhao, J.; Lv, P.; Zhang, L.; and Li, D. 2023. Multi-temporal urban semantic understanding based on GF-2 remote sensing imagery: From tri-temporal datasets to multi-task mapping. International Journal of Digital Earth, 16(1): 3321–3347.
[25] Shrivastava, A.; Gupta, A.; and Girshick, R. 2016. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 761–769.
[26] Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. 2020. Deep high-resolution representation learning for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence.
[27] Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; and Zhong, Y. 2021. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1.
[28] Wen, Z.; Xu, G.; Tan, M.; Wu, Q.; and Wu, Q. 2021. Debiased visual question answering from feature and sample perspectives. Advances in Neural Information Processing Systems, 34: 3784–3796.
[29] Woo, S.; Park, J.; Lee, J.-Y.; and Kweon, I. S. 2018. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), 3–19.
[30] Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; and Lu, X. 2017. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing, 55(7): 3965–3981.
[31] Xiao, Y.; Yuan, Q.; Jiang, K.; He, J.; Wang, Y.; and Zhang, L. 2023. From degrade to upgrade: Learning a self-supervised degradation guided adaptive network for blind remote sensing image super-resolution. Information Fusion, 96: 297–311.
[32] Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J. M.; and Luo, P. 2021. SegFormer: Simple and efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems, 34: 12077–12090.
[33] Yang, Z.; He, X.; Gao, J.; Deng, L.; and Smola, A. 2016. Stacked attention networks for image question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 21–29.
[34] Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; and Tian, Q. 2019. Deep modular co-attention networks for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6281–6290.
[35] Yuan, Z.; Mou, L.; Xiong, Z.; and Zhu, X. X. 2022. Change detection meets visual question answering. IEEE Transactions on Geoscience and Remote Sensing, 60: 1–13.
[36] Zhang, Y.; Yuan, Y.; Feng, Y.; and Lu, X. 2019. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Transactions on Geoscience and Remote Sensing, 57(8): 5535–5548.
[37] Zhao, H.; Zhong, Y.; Wang, X.; Hu, X.; Luo, C.; Boitt, M.; Piiroinen, R.; Zhang, L.; Heiskanen, J.; and Pellikka, P. 2022. Mapping the distribution of invasive tree species using deep one-class classification in the tropical montane landscape of Kenya. ISPRS Journal of Photogrammetry and Remote Sensing, 187: 328–344.
[38] Zheng, X.; Wang, B.; Du, X.; and Lu, X. 2021. Mutual attention inception network for remote sensing visual question answering. IEEE Transactions on Geoscience and Remote Sensing, 60: 1–14.
[39] Zvonkov, I.; Tseng, G.; Nakalembe, C.; and Kerner, H. 2023. OpenMapFlow: A Library for Rapid Map Creation with Machine Learning and Remote Sensing Data. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, 14655–14663.